
Googles Engagement in Sachen in Machine Learning und Articial Intelligence ist beachtlich wie im Beitrag Welche Bedeutung hat ML für Google? erläutert. Auch der Einfluss auf SEO ist deutlich erkennbar wie im Beitrag Welche Bedeutung hat Machine Learning für SEO? Experten wagen den Blick in die Zukunft erläutert.
Dabei spielt die Bilderkennung und auch die Identifikation von Texten und deren Bedeutung eine wichtige Rolle für Google.
Sind die Zeiten der Nicht-Lesbarkeit von Texten in Bildern bald vorbei? Diese Frage stellte ich mir beim Verfolgen der News im Bereich Bild- und Texterkennung aus dem Hause Google.
Am Ende dieses Beitrags habe ich eine Auswahl an Google-Patenten zusammengestellt, die im Zusammenhang mit Bild- und Videoerkennung und Interpretation stehen.
Durch maschinelles Lernen und die Verfügbarkeit von passenden Lerndaten ist die Entwicklung vorhandener Systeme rasant. Die Frage ist also, wie weit fortgeschritten sind Googles Produkte und lässt sich daraus etwas auf den möglichen Einsatz des Google-Crawler ableiten?
Inhaltsverzeichnis
Schwierigkeiten bei der Lesbarkeit von Texten in Bildern
Problematisch bei der Entwicklung hin zur Identifikation und Deutung von Texten in Bildern ist nicht die Machbarkeit oder die Patente, sondern die fehlerfreie Durchführung und die sinnvolle Weiterverarbeitung. Denn es müsste eine intelligente Abstraktionsfähigkeit einbezogen werden, welche Google momentan immer noch trainiert.
Das zu lösende Problem im Fall Texterkennung in Bildern ist das Unterscheiden zwischen wirklichem Text und vermeintlichen Text, wie Strukturen die wie ein Buchstabe oder eine Zahl geformt sind und sich im ungünstigsten Fall noch in unmittelbarer Nähe zu echten Schriftzeichen befinden. Für den Crawler würde es bedeuten, dass er fehlerfrei zwischen Text und Elementen unterscheiden müsste, diese transkribiert und dem Bild als Tag zuordnet bzw. daraus Sitelinks kreiert oder den wahren Urheber des Webauftritts ermittelt. Bei einem Impressum und einem einfachen Bild ist sehr wenig Abstraktion notwendig und die Durchführung klappt schon sehr gut, wie aber die verschiedenen Bild-Typen von einander trennen?
Genau in diesem Punkt wäre es möglich, dies wieder durch maschinelles Lernen zu realisieren und durch den Abgleich mit ähnlichen Bildern, welche schon verifiziert wurden. Ebenfalls wäre es möglich transkribierte Daten mit typischen Keywords oder Adressen abzugleichen, um so z.B. einen Bezug zu Unternehmen herstellen zu können und kleinere Fehler der Erhebung auszubügeln.
Ein weiteres Problem der Texterkennung im Bild ist die Gewichtung des automatisch erstellten Tags und der automatisierten thematischen Einordnung. Dieser Prozess, welcher Generalisierung genannt wird, entscheidet wie relevant der Text im Bezug zum Bildmotiv ist und in welchen semantischen Bezug der Text zum Bild steht. Auch der Vergleich zur Bildbeschriftung und händischer Verschlagwortung müsste in Betracht gezogen werden um ggf. Relevanzen festzulegen. Im schlechtesten Fall würde dein Urlaubsbild am Strand mit dem Namenszug des lokalen Mülleimerherstellers in Verbindung gebracht werden. In der Bilderkennung und automatischen Einordnung gab es bereits dieses Jahr einen brisanten Skandal.
Einfacher wäre es bei Bildern wie ausführlichen Infografiken, die genug Text liefern würden damit Google Einordnungen treffen könnte oder Daten wie Adressen, die eine verhältnismäßig feste Struktur aufweisen. In dieser Problemstellung wird das Web 3.0 eine Schlüsselrolle in Verbindung mit der Bild- und Objekterkennung wie der Cloud Vision API und dem Deep Learning spielen. Die Veröffentlichung von Googles API und den Einsatz in Apps führt wiederum zu noch größeren Datenmengen und multifunktionaler Anwendung. Mit der Bestätigung von berechnetem Scoring und Einordnungen durch den Nutzer kann der Prozess verfeinert werden. Auf diese Art entwickeln sich vorhandene Systeme weiter.
Zusammenfassend stellt sich also nicht nur die Frage der endgültigen Machbarkeit, sondern auch was Google aus den so erhobenen Daten schlussendlich machen wird/kann bzw. was Google als sinnvolle Nutzung der Daten sieht. Schlussendlich geht es darum einen greifbaren Mehrwert für die Nutzer zu generieren und dies funktioniert nur mit Vorlaufzeit und dem ineinandergreifen mehrerer Systeme. Um die theoretischen Gedanken an einem realen Produkt zu testen nachfolgend eine kleine Untersuchung.
Untersuchung: Texterkennung anhand von Stichproben innerhalb der Google Übersetzer App
Um das ausgereifteste Google-Produkt im Bereich Texterkennung aus Bildern zu testen, nahm ich ein Paar Bildvariationen und prüfte die Google-Translate-App bezüglich Entwicklungsstand und gegebener Schwachstellen. Anzumerken ist, der Google Übersetzer ist von mir hier gezielt zweckentfremdet worden, die konforme Nutzung ist natürlich eine andere. Die App greift auf Daten aus dem maschinellen Lernens zurück und verbindet dies in Echtzeit mit einem augmented reality system, was dabei herauskommt seht ihr hier.

Mein erstes Bild ist die Anschrift der Agentur. Hier soll getestet werden in wie weit es möglich ist Adressen in einem relativ klaren Kontext zu erkennen und zu transkribieren.
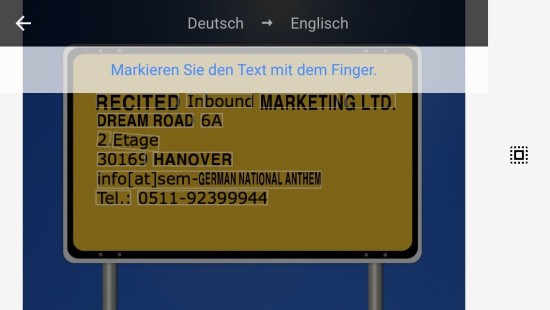
Die App erkennt den Text sofort, markiert die Elemente und fängt an diese zu „übersetzen“. Besonders hervorzuheben ist das Feature gegebenen Text in Echtzeit mit passenden Textfragmenten zu ersetzen. Nicht nur die Texterkennung sondern auch die Weiterverarbeitung der Daten erfolgt blitzschnell.
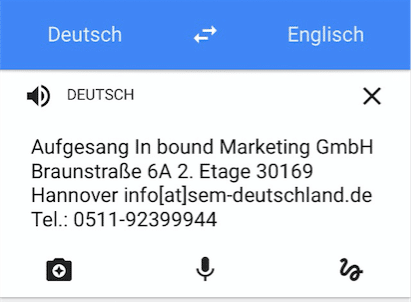
Das Transkribieren erfolgt problemlos. Allerdings ist hier trotz klarer Vorlage zu erkennen, dass im Wort „Inbound“ ein Leerzeichen dazwischen gerutscht ist.
Im nächsten Bild steigerte ich die Schwierigkeit durch Variation des Hintergrunds, Schattierungen, Typographie, Kontrast und Ausrichtung des Textes.
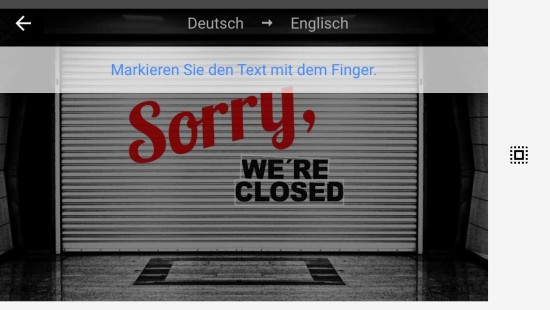
Die Texterkennung erfolgt hier beim Teil „WE’RE CLOSED“, auch die Transkription und der Übersetzungsvorgang funktionieren, allerdings wurde das „Sorry“ nicht erkannt. Die erhöhten Begleitumstände machen der App Schwierigkeiten.
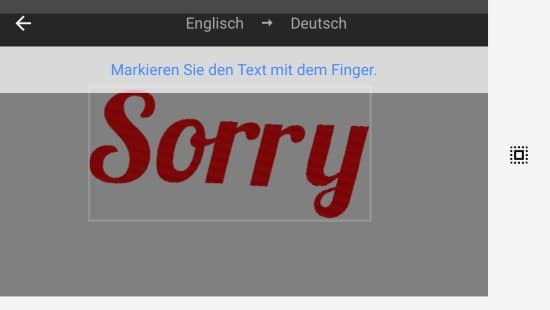
Um auszuschließen, dass es Probleme mit der Erkennung der Typographie des Wortes gibt, sondierte ich den Schriftzug. Die Verarbeitung erfolgt problemlos. Dies zeigt die enormen Fähigkeiten der Texterkennung in der Variation der Schriftarten. Handschriften werden allerdings von Google ausgeschlossen bzw. noch nicht unterstützt. Anzumerken ist das Google durch Google Fonts ein breites Spektrum an Typographie bereitstellt und so ihrer Texterkennung perfekte Lerndaten zur Verfügung stellen kann. Diesbezüglich ist das Ergebnis nicht verwunderlich und sollte auch bei komplexeren Schriftarten gute Ergebnisse liefern.
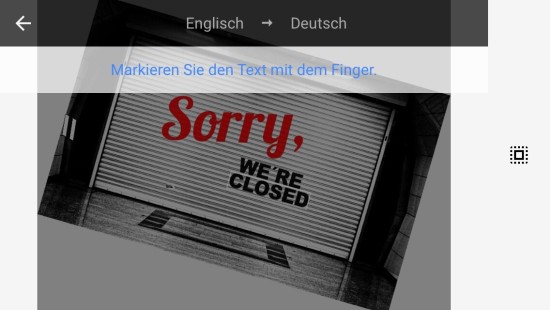
Um zu Überprüfen inwiefern die Ausrichtung des Textes die Erkennung beeinflusst drehte ich das Bild passend zum Wort „Sorry“. Zu erkennen ist das der erkannte Umfang im vorherig erkannten „WE`RE CLOSED“ stagniert und das „Sorry“ immer noch nicht erkannt wird. Dies zeigt auf, dass das Umfeld des Textes enorme Bedeutung hat, die Farbwerte der Typographie, trotz roter Abhebung, in diesem Fall weniger Bedeutung beigemessen wird und eine Veränderung der Ausrichtung in einem komplizierten Bildkontext die Texterkennung stark beeinflussen. Eine weitere Vermutung anhand dieses Beispiels ist das Form bzw. Struktur eine höhere Wichtigkeit beigemessen wird als der Kontrast, da der „Sorry“-Schriftzug trotz vorherigen positiven Ergebnissen nicht erkannt wird. Ebenfalls hat sich ein Artefakt eingeschlichen, unter dem S von „Sorry“ auf Höhe des „Closed“ wurde die Nummer 8 erkannt und eingefügt. Dies zeigt das es auch zu willkürlichen Missverständnissen kommen kann, obwohl dort augenscheinlich nichts ist was der Ziffer 8 ähnelt oder wir als solche wahrnehmen würden.
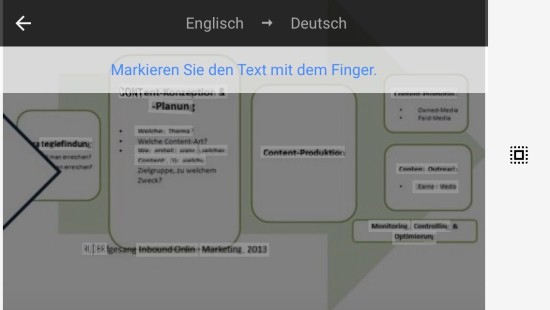
Die letzte Stichprobe ist eine Infografik über den SEO-Prozess unserer Agentur.
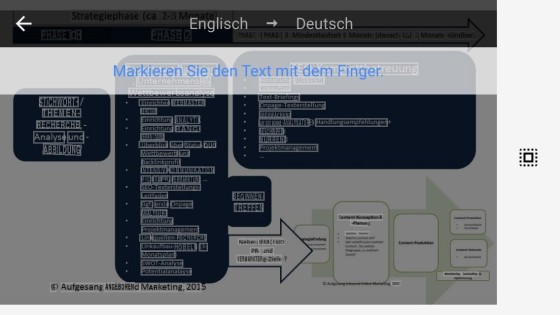
Der Text wird weitestgehend erkannt, allerdings zeigt sich das in der Gesamtheit Probleme durch zu kleinen oder unscharfen Text entstehen können. Hier zeigen sich Schwächen in der Erkennung relevanter Elemente.

Das Transkribieren funktioniert beim Text ganz gut, allerdings erkennt die App natürlich nicht die gegebene Fließrichtung des Textes oder die Unterteilung der verschiedenen Abschnitte. Der Übersetzer unterstützt dieses Feature nicht, moderne OCR-Software ist aber in der Lage Tabellenstrukturen zu erkennen.
Sammlung Google-Patente zu Video- und Bilderkennung
Eine passende Auswahl an Googles Patenten:

- Identifying matching canonical documents in response to a visual query: scannt Bilder, ob Fotografie oder Video und erkennt Gesichter, Objekte, Text, Produkte, Barcode oder Farben und ordnet diese in einen gerankten semantischen Kontext ein
- Automatic large scale video object recognition: hier geht es um ein lernendes System welches Objekte aus Bildern oder Videos erkennt, abspeichert einordnet und für den weiteren Gebrauch und Abgleich sichert
- Database assisted OCR for street scenes and other images: erlaubt es die Texterkennung auf Straßenszenen und andere Bilder anzuwenden um so anhand von gesammelten Daten Informationen über das Bild bereit zu stellen
- System and method for the calibration of a scoring function: klassifiziert anhand von erfassten Beweisen wie z.B. Text oder Objekten Bilder um so ein Ranking bezüglich der Inhalte herzustellen
- User Interface for Presenting Search Results for Multiple Regions of a Visual Query: teilt ein Bild in Teilbereiche auf und führt simultan für jedes einzelne Element eine Suche durch. Das Ergebnis wird dann in einem erweiterten Interface zur Verfügung gestellt
- Query image search: sucht und bewertet ähnliche Bilder
- Method and apparatus for automatically annotating images: verschlagwortet Bilder automatisch anhand ihres Inhalts und ihrer Ähnlichkeit zu anderen Bildern
- Method and Apparatus for Image Searching: das Patent was Googles Bildersuche ermöglicht
- Clustering Queries For Image Search: gruppiert die Bildsuchanfrage anhand von semantischen oder visueller Ähnlichkeiten vor um ein verbessertes Ergebnis bereit zu stellen.
- Presenting translations of text depicted in images: ist das Patent für die augmented reality Funktion des Google Übersetzers. Es erlaubt Zusatzinformationen in Form eines Bildes in Bezug auf Text bereitzustellen

























2 Kommentare
Ein wirklich toller Artikel über die neue Bilderkennung von Google auf die wir alle schon gespannt warten. Besonders die Beispiele wie eine Bilderkennung mit Übersetzung funktionieren könnte haben mir dabei sehr gut gefallen. Im Kontext des maschinellen Lernens finde ich dabei auch Googles RankBrain sehr interessant
Hallo Nina, Danke für die Blumen. Ich habe mir aber erlaubt den Link rauszunehmen, da ihr ja nicht Quelle seid sondern nur die eigentliche Quelle wiedergebt. Ein Link ist ein Verweis zu einer Quelle. Dafür müsst ihr aber schon als Orginalquelle dienen. Bei Kommentaren von Euch ist mir jetzt leider schon öfters dieses Muster aufgefallen und das riecht dann einfach nach Linkaufbau über Blogkommentare …