Du interessierst Dich für das Thema Knowledge Graph Dann bist Du in unserem Glossar für Fachbegriffe aus dem (Online-) Marketing genau richtig. In diesem Beitrag bekommst Du alle wichtigen Informationen zum Thema Knowledge Graph.
Inhaltsverzeichnis
- 1 Was ist ein Knowledge Graph?
- 2 Zusammenfassung
- 3 Wie ist ein Knowledge Graph aufgebaut?
- 4 Wozu werden Graphen eingesetzt?
- 5 Was ist der Knowledge Graph von Google?
- 6 Der Google Knowledge-Graph: Von Keywords zu Entitäten
- 7 Vom Entitäten-Katalog zum Google Knowledge Graph
- 8 Woher bezieht Google die Informationen für den Knowledge-Graph?
- 9 Die Verarbeitung von strukturierten Daten für den Knowledge Graph
- 10 Die Geschichte des Google Knowledge Graph: Von der Hierarchie zum Netzwerk
- 11 Zusammengefasst: Häufige Fragen zum Thema Knowledge Graph
- 12 Bücher zum Thema Knowledge Graph
- 13 Weitere Quellen zum Google Knowledge Graph
- 14 Weitere SEO-Fachbegriffe
Was ist ein Knowledge Graph?
Ein Knowledge Graph ist eine Wissens-Datenbank, in der Informationen so strukturierte aufgearbeitet sind, dass aus den Informationen Wissen entsteht. In einem Knowledge Graph werden Entitäten (Knoten) über Kanten in Beziehung zueinander gestellt, mit Attributen versehen und in thematischen Kontext bzw. Ontologien gebracht.
Zusammenfassung
Du willst nicht alles zum Knowledge Graph lesen? Kein Problem. Hier eine kurze Zusammenfassung:
- Grundlegend bestehen Graphen aus Knoten und Kanten, wobei im Knowledge Graph die Knoten Entitäten und die Kanten Beziehungen zwischen diesen repräsentieren. Entitäten werden durch Namen und Attribute definiert.
- Der Knowledge Graph klassifiziert Entitäten und kommentiert Beziehungen, was die Beantwortung von Suchanfragen ermöglicht.
- Der Graph ist auf drei Ebenen aufgebaut: dem Entitäten-Katalog, dem Knowledge Repository und dem Knowledge Graph selbst, wobei jede Ebene spezifische Aufgaben im Verwalten und Verknüpfen von Entitätsinformationen hat.
- Google bezieht Informationen für den Graphen aus verschiedenen strukturierten, semistrukturierten und unstrukturierten Datenquellen, um die Verbindungen und Attribute der Entitäten kontinuierlich zu erweitern und zu aktualisieren. Dabei spielen strukturierte Daten eine wichtige Rolle als Trainingsdaten für maschinelles Lernen, um auch unstrukturierte Daten verarbeiten zu können.
Wie ist ein Knowledge Graph aufgebaut?
Die grundsätzliche Struktur von Graphen besteht aus sogenannten Knoten und Kanten. Bezogen auf den Knowledge Graph sind die Knoten die Entitäten und die Kanten beschreiben die Art der Beziehung zwischen diesen Entitäten. Entitäten werden beschrieben durch eine Bezeichnung bzw. einem Namen und verschiedenen Attributen bzw. Eigenschaften.
In einem Knowledge Graph werden alle Knoten also Entitäten mit Attributen versehen und nach Entitätstypen klassifiziert. Zudem werden die Kanten zwischen den Entitäten mit der Beziehungsart kommentiert.
Diese Struktur erlaubt es Antworten auf Fragen zu geben, in denen ein Thema oder Entität gesucht wird, die in der Frage nicht genannt wird.
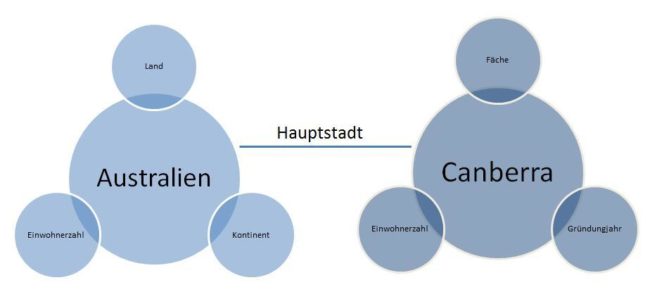
Im folgenden Beispiel sind „Australien“ und „Canberra“ die Entitäten und der Wert „Hauptstadt“ beschreibt die Art der Beziehung.
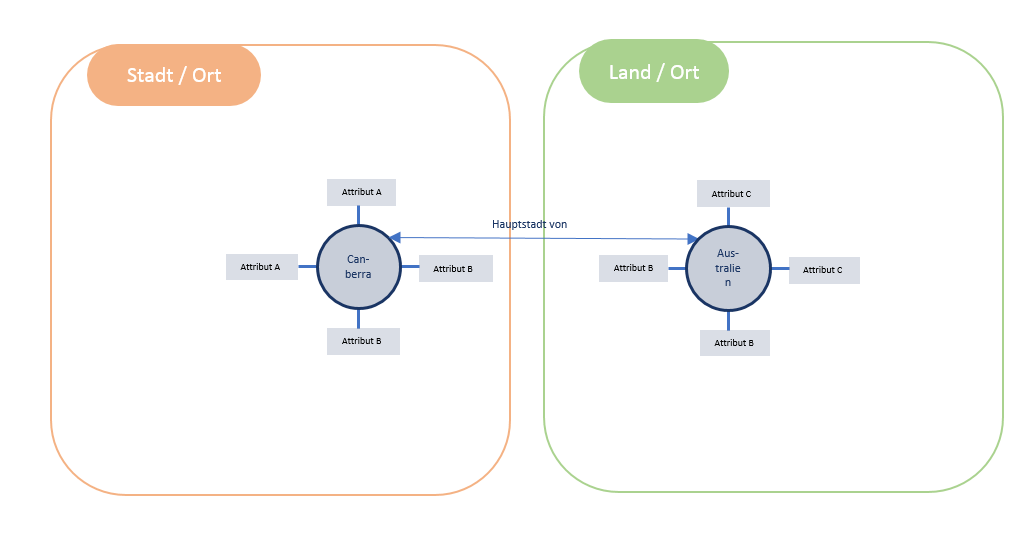
Beispiel für die Kennzeichnung von Entitäten mit Attributen und Beziehungsart, , Quelle: © Olaf Kopp, Aufgesang GmbH
Diese Grafik sagt nichts anderes aus als: „Canberra ist die Hauptstadt von Australien.“ Damit kann Google auf die Frage: „Welche Stadt ist die Hauptstadt von Australien?“ die richtige Antwort geben. Dabei ist es nicht wichtig ob man explizit fragt oder implizit die Frage über den Suchterm „hauptstadt australien“ stellt. Das Ergebnis ist das Gleiche.
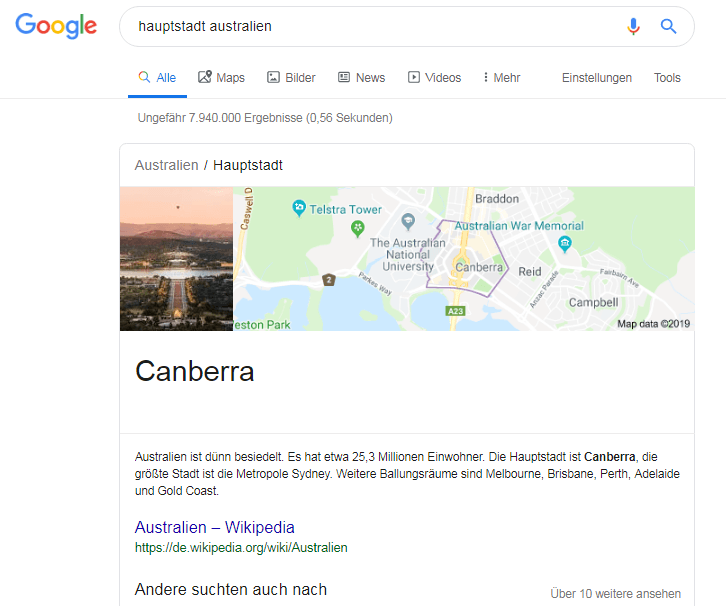
Antwort auf die Frage nach der Hauptstadt von Australien bei Google
Man kann diesen Zusammenhang auch grammatikalisch so darstellen. Canberra ist das Subjekt, Australien das Objekt und (ist die) Hauptstadt ist das Prädikat bzw. Prädikatsphrase.
Die Beziehungsart kann aber auch durch ein Verb beschrieben werden wie „Thomas Müller spielt für Bayern München.“ Objekt und Subjekt sind demnach immer Entitäten. Nomen werden im Natural Language Processing prinzipiell immer als potentielle Entitäten gesehen.
Die Prädikatsphrase kann ein Entitäts-Typ oder -Klasse, ein Attribut ein Verb oder eine Kombination aus allen sein.
Aber der Knowledge Graph ist mehr als eine Darstellung der Beziehung zwischen Entitäten. Er ist eine riesige Datenbank, in der Google das Wissen rund um Entitäten sammelt. Deswegen gibt es noch weitere Informationen, die im Knowledge Graph erfasst werden:
- Attribute (Eigenschaften) von Entitäten
- Relevanz-Scoring der Attribute, also wie nah die Attribute im Vektorraum zu den Entitäten stehen
- Entitätstypen
Als Grundlage für den Knowledge Graph dienen drei Ebenen:
- Entitäten-Katalog: Hier werden alle Entitäten gespeichert, die mit der Zeit identifiziert worden sind.
- Knowledge Respository: Die Entitäten werden in einem Wissens-Depot (Knowledge Repository) mit den Informationen bzw. Attributen aus den verschiedenen Quellen zusammengeführt. Im Knowledge Repository geht es in erster Linie um die Zusammenführung und Speicherung von Beschreibungen und die Bildung semantischer Klassen bzw. Gruppen in Form von Entitäts-Typen. Googles Knowledge Repository ist aktuell der Knowledge Vault.
- Knowledge Graph: Im Knowledge Graph werden die Entitäten mit Attributen ergänzt und Beziehungen zwischen den Entitäten hergestellt .
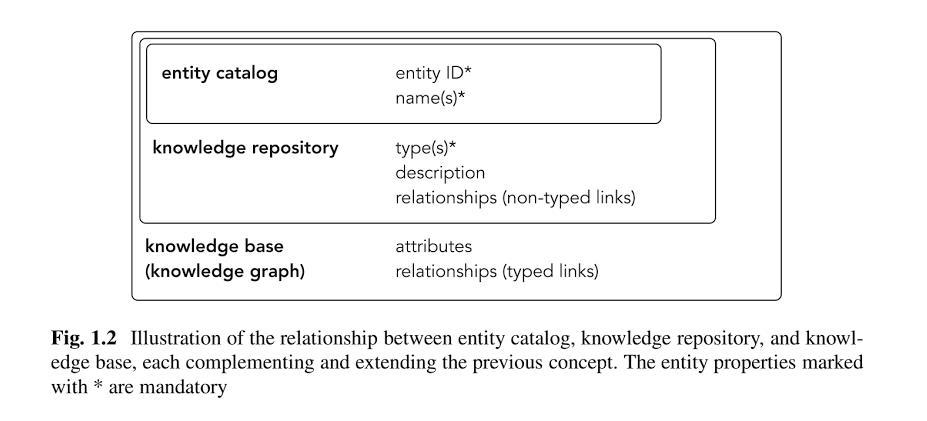
Die drei Ebenen eines Knowledge Graph, Quelle: Entity-Oriented Search – Krisztian Balog
Wozu werden Graphen eingesetzt?
In der Informatik wird die Graphen-Theorie dafür genutzt Beziehungen zwischen Objekten darzustellen und zu analysieren. Graphen sind damit ein wichtiges Instrument in der Netzwerkforschung.
Z.B. Facebook nutzt den Social Graph, um die Beziehungen zwischen Profilen zu analysieren. Google nutzt schon lange den Link-Graph um Beziehungen zwischen Dokumenten und Websites zu analysieren und zu bewerten. Den Knowledge Graph nutzt Google um Beziehungen zwischen Entitäten abzubilden und zu analysieren.
Die Entwicklung des Knowledge Graph durch Google scheint eng mit dem Kauf der semantischen Wissens-Datenbank Freebase in Verbindung zu stehen. Ich bezeichne Freebase auch gerne als Spielplatz, über den Google die ersten Erfahrungen mit strukturierten Daten machen konnte.
Im Jahr 2012 führte Google den Knowledge Graph ein, der anfangs u.a. durch die in Freebase gesammelten Daten und Wikipedia gespeist wurde. Heutzutage bezieht Google auch weitere Quellen heran um Informationen zu den Entitäten zu sammeln.
Das offene Projekt Freebase wurde 2014 beendet und in das geschlossene Projekt Wikidata überführt. Für die Darstellung einer Entitäten-Box prüft Google, ob ein Datensatz in Wikidata oder eine Seite bei Wikipedia vorhanden ist.
Was ist der Knowledge Graph von Google?
Der Knowledge Graph ist Googles semantische Datenbank. Hier werden Entitäten in Beziehung zueinander gestellt, mit Attributen versehen und in thematischen Kontext bzw. Ontologien gebracht.
Mit der Einführung des Hummingbird-Ranking-Algorithmus lieferte Google 2013 den offiziellen Startschuss für den Aufbau einer semantischen Suchmaschine. Die Idee dahinter war, Inhalte jeglichen Formats selbst zu verstehen und auf jede Suchanfrage eine passende und qualitativ hochwertige Antwort zu geben. Die Basis ist eine neue Anordnung von Daten, die nun nicht mehr hierarchisch sondern netzwerkartig, also in Form von Graphen sortiert sind.
Der Google Knowledge-Graph: Von Keywords zu Entitäten
Suchmaschinen brauchen eine Entscheidungsgrundlage, anhand derer sie bestimmen können, in welcher Reihenfolge die Webseiten anzeigt werden sollen. Zu den ursprünglichen Rankingfaktoren bei Google gehörten Keyworddichte (und später auch strategische Positionierung selbiger) und der PageRank, der aufgrund der Anzahl von Links die auf eine Webseite zeigen berechnet wurde. Später wurde die Keyworddichte durch komplexere textanalytische Verfahren wie TF-IDF bzw. WDF*IDF ersetzt.
Neben den Links liegt der Fokus bei der Suchmaschinenoptimierung aber weiterhin auf Keywords. Doch in den letzten Jahren merkt man, dass Humingbird auch durch den Einsatz von Machine Learning immer schlauer wird. Die Rankings orientieren sich nicht mehr ausschließlich um Keywords, die benutzt werden, sondern an Themen und Entitäten.
Ein Grundkonzept ist, dass Google Webseiten weder in Kategorien ordnet, noch anhand von (einzelnen) Keywords indexiert, sondern sie möchte die Seiten im gesamten Kontext verstehen. Google möchte die Hintergedanken einer Seite verstehen und ich vermute, dass sich das auf Domainebene abspielt. Das heißt, dass es nicht mehr (nur) darum geht, einzelne URLs zu besonders rentablen Keywords in den Index zu bringen, sondern dass das Umfeld bzw. die gesamte Domain in ihrer Ganzheit als Ursprungs-Entität zu verstehen ist.
Vom Entitäten-Katalog zum Google Knowledge Graph
Als Grundlage für den Knowledge Graph dienen drei Ebenen:
- Entitäten-Katalog: Hier werden alle Entitäten gespeichert, die mit der Zeit identifiziert worden sind.
- Knowledge Respository: Die Entitäten werden in einem Wissens-Depot (Knowledge Repository) mit den Informationen bzw. Attributen aus den verschiedenen Quellen zusammengeführt. Im Knowledge Repository geht es in erster Linie um die Zusammenführung und Speicherung von Beschreibungen und die Bildung semantischer Klassen bzw. Gruppen in Form von Entitäts-Typen. Googles Knowledge Repository ist aktuell der Knowledge Vault.
- Knowledge Graph: Im Knowledge Graph werden die Entitäten mit Attributen ergänzt und Beziehungen zwischen den Entitäten hergestellt .
Woher bezieht Google die Informationen für den Knowledge-Graph?
Die Informationen zu den Entitäten und deren Beziehungen untereinander kann Google aus folgenden Quellen beziehen:
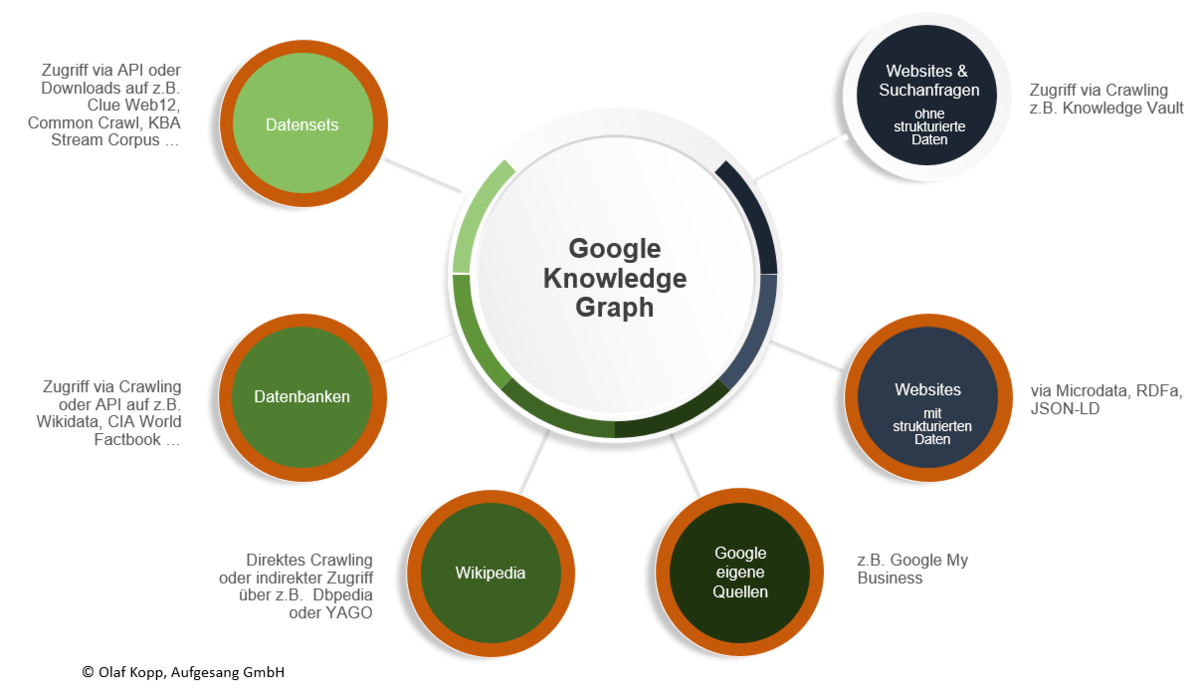
Datenquellen für den Knowledge Graph
Quellen für unstrukturierte Daten
Quellen aus denen Google theoretische unstrukturierte Informationen zu Entitäten extrahieren kann sind
- Normale Web-Seiten via Crawling
- Suchanfragen
- unstrukturierte Datenbanken und Datensets
Dabei spielt der Knowledge Vault eine besondere Rolle. Dazu in einem Folgebeitrag mehr.
Quellen für semistrukturierte Daten
Semistrukturierte Informationen kann Google aus Enzyklopädien wie z.B. Wikipedia, die eine systematische Struktur besitzen. Dazu gehe ich in einem Folgebeitrag detaillierter ein.
Quellen für strukturierte Daten
Über semantische Datenbanken und Datensets kann Google strukturierte Daten direkt z.B. via API übernehmen und für den Knowledge Graph nutzen. Folgende Datenbanken sind dafür möglich:
- Wikidata (ehemals Freebase)
- Google My Business
- CIA World Factbook
- DBpedia
- YAGO
- Webseiten mit strukturierten Daten via Microdata, RDFa und JSON-LD
- Lizensierte Daten
- CIA World Factbook
- Datensets
- ClueWeb09 bis ClueWeb12
- Common Crawl
- KBA Stream Corpus
Die Verarbeitung von strukturierten Daten für den Knowledge Graph
Die Anlaufstelle Nummer Eins für Google um Informationen zu Entitäten zu bekommen sind Quellen über die sie strukturierte Daten bereitgestellt werden.
In diesem Beitrag werde ich mich nur mit dieser Art von Datenquellen beschäftigen. Auf die weitaus komplexere Methodik unstrukturierte Daten und semistrukturierte Daten wie z.B. aus der Wikipedia zu extrahieren werde ich in Folgebeiträgen eingehen.
Die strukturierten Daten kann Google über das Resource Description Framework kurz RDF erfassen. Eine Enität ist eine Zusammenfassung verschiedener RDF-Statements nach dem Muster Objekt-Prädikat-Subjekt. Ein Statement wäre z.B. „Canberra ist die Hauptstadt von Australien.“
Man kann diesen Zusammenhang auch grammatikalisch so darstellen. Canberra ist das Objekt, Australien das Subjekt und (ist die)Hauptstadt ist das Prädikat. Die Beziehungsart kann aber auch durch ein Verb beschrieben werden wie „Thomas Müller spielt für Bayern München.“ Objekt und Subjekt sind demnach immer Entitäten. Das Prädikat kann ein Entitäts-Typ oder -Klasse, ein Attribut ein Verb oder eine Kombination aus allen sein.
Die meisten strukturierten Datenbanken stellen die Informationen im maschinenlesbaren RDF-Format zur Verfügung bzw. lassen eine Übersetzung in dieses Format zu. Google greift auf Datenbanken zu, in die sie Vertrauen haben wie z.B. Wikidata, CIA World Factbook …, strukturierte Datensets oder Übersetzungs-Datenbanken wie z.B. DBpedia oder YAGO, die die Informationen der Wikipedia in maschinenlesbare Daten übersetzen.
Da die Datenbanken und Datensets mit strukturierten Daten verhältnismäßig nur sehr langsam wachsen und aktualisieren wundert es nicht, dass Google Webmaster immer wieder dazu animiert mit strukturierten Daten in ihren Websites zu arbeiten. Je mehr Google strukturierte Daten sammelt und verarbeitet, desto näher kommen sie dem Ziel auch unstrukturierte Daten verarbeiten zu können. Die strukturierten Daten funktionieren als Trainingsdaten für das maschinelle Lernen.
Dazu mehr in meinem Beitrag Warum strukturierte Daten für Google zukünftig überflüssig werden könnten.
Die Geschichte des Google Knowledge Graph: Von der Hierarchie zum Netzwerk
(Dieser Abschnitt wurde von Svenja Hintz verfasst)
Die bisher bekannten Rankingfaktoren verlieren dadurch nicht ihre Gültigkeit, aber ihre Dominanz. Dr. Pete hat versucht diese neue Komplexität mit einer, in seinen Worten, eher schlechten Infografik abzubilden. Inwieweit diese Grafik der Wirklichkeit entspricht, weiß nur Google, aber sie vermittelt einen guten Überblick darüber wie vielschichtig der Prozess ist, der zur Beantwortung einer Suchanfrage führt. Vermutlich darf man sich das nicht als linearen Prozess vorstellen.

Google sammelt Informationen indem sie Webseiten und deren Inhalte crawlt, was nichts weiter bedeutet, als dass kleine Roboter den ganzen Tag damit beschäftigt sind durch das Netz zu krabbeln und alles aufzunehmen was in ihrem Blickfeld liegt. Ein bisschen wie die Google Street View Cars, Bikes und Trekker mit ihren 360° Kameras.
Die Crawler sammeln damit eine unvorstellbar große Datenmenge, die erst mal überhaupt nichts bedeutet bis sie indexiert wird. Google‘s Index ist quasi eine hauseigene Datenbibliothek, die zum Einsatz kommt, sobald ein Nutzer eine Suchanfrage stellt. Crawling und Indexierung sind deswegen die Grundvoraussetzung, um bei Google gefunden zu werden.
Gerade bei großen Plattformen und Shops, bei denen ständig neue Seiten hinzukommen, braucht es allein schon deswegen einen SEO der das im Blick behält, denn können Inhalte nicht gecrawlt werden, dann landen sie nicht im Index. Um allerdings auch bei den gewünschten Suchanfragen zu erscheinen, müssen sie richtig eingeordnet werden.
Erst waren es Kategorien
Um die gewünschten Informationen zu finden bedarf es einer sinnvollen, sauber geführten Ablage und jeder der schon mal einen Aktenschrank sortieren musste weiß, dass dahinter eine ganze Wissenschaft steht. Je mehr Leute diesen Aktenschrank füllen, desto größer die Gefahr, dass Dokumente falsch einsortiert und nie wieder gefunden werden, zumindest bei einer großen Menge. In den Anfängen des Internets, setzte man noch auf eine hierarchische Einordnung in Form von Kategorien.

Vom Grundsatz her ist nicht schlecht, wir sind das von Branchenverzeichnissen und Katalogen im Printformat oder Bibliotheken gewöhnt und das hat gut funktioniert, aber mit steigendem Datenwachstum wird es immer weniger praktikabel, denn um den einzelnen Webseiten und deren Inhalten gerecht zu werden entstehen Unterkategorien, Unterunterkategorien, Unterunterunterkategorien und so weiter.
Je größer der Datenbestand wird, desto unübersichtlicher wird es. Hinzu kommt die Gefahr von unterschiedlichen Auffassungen darüber, wie Dinge am sinnvollsten einsortiert werden. Wer auf der Suche nach einem Baseballschläger in München ist, der hätte in diesem Fall allein schon vier Einstiegsmöglichkeiten, die Sinn machen könnten: „Shopping“, „Regional“, „Recreation“ und „Sports“. Je nach Gehirnwindung des Nutzers macht das eine mehr und das andere weniger Sinn. Um einigermaßen Ordnung zu halten und eine gewisse Konsistenz zu erreichen, bedarf es menschlicher Moderation.
Dann kamen die Keywords
Doch das Internet wächst einfach zu schnell, als dass man es per Hand sortieren könnte. Eine Lösung sind Keywordbasierte Suchmaschinen. Anstatt sich durch mehrere Kategorieebenen zu klicken, gibt man einfach „Baseballschläger München“ in den Suchschlitz ein und bekommt eine Liste mit Links, die wiederum zu Webseiten führen. Der Keywordbasierte Ansatz löst das Problem der Mehrdeutigkeit von Kategorien und ermöglicht eine automatisierte Indexierung, zumindest solange die wichtigen Keywords suchmaschinenfreundlich zur Verfügung gestellt werden.

Da man sich nun vorstellen kann, dass es mehr als eine Webseite gibt, die sich mit dem Thema „Baseballschläger München“ auseinandersetzt, braucht es eine ebenso automatisierte Möglichkeit, um die Informationen zu ranken. Suchmaschinen brauchen also eine Entscheidungsgrundlage, anhand derer sie bestimmen können, in welcher Reihenfolge die Webseiten anzeigt werden sollen. Zu den ursprünglichen Rankingfaktoren bei Google gehörten Keyworddichte (und später auch strategische Positionierung selbiger) und der PageRank, der aufgrund der Anzahl von Links die auf eine Webseite zeigen berechnet wurde. Die Annahme dahinter war, dass sich das Netz dadurch quasi selbst organisiert und Nutzer Links nur dann setzen würden, wenn das Ziel qualitativ hochwertig ist.
Die Idee des PageRank war so gut, dass Google schnell zu einer der beliebtesten Suchmaschinen wurde. Doch die Maschine konnte die Inhalte einer Seite selbst nicht verstehen und die Faktoren Keyworddichte und PageRank waren leicht zu manipulieren. Mit einem künstlich aufgebauten Linknetzwerk, konnte man Google mit einem Text wie dem folgenden also leicht vormachen, dass er das beste Ergebnis für die Anfrage „Fahrrad Berlin“ bzw. „Fahrrad Berlin Schöneberg“ sei, auch wenn der Rest der Seite mit Werbeanzeigen für völlig andere Produkte versehen war. Automatisierter Spam wurde ein ernst zu nehmendes Problem und Google musste reagieren, um ihre Marktmacht zu halten.

Heute geht es um Entitäten
Ein Grundkonzept ist, dass Google Webseiten weder in Kategorien ordnet, noch anhand von (einzelnen) Keywords indexiert, sondern sie möchte die Seiten als Entität verstehen, in meinem letzten Artikel habe ich das als Wesen mit Agenda bezeichnet. Google möchte die Hintergedanken einer Seite verstehen und ich vermute, dass sich das auf Domainebene abspielt. Das heißt, dass es nicht mehr (nur) darum geht, einzelne URLs zu besonders rentablen Keywords in den Index zu bringen, sondern dass sie eine Seite in ihrer Ganzheit betrachten möchte.
Die Entwicklung eines semantischen Verständnisses bei der Deutung von Suchanfragen als auch Dokumenten hängt eng mit der Fähigkeit zusammen Entitäten sowie deren Beziehungen zu anderen Entitäten zu identifizieren und diese in ein Konzept bzw. eine Ontologie einzuordnen. Mit Hilfe von verifizierten Datenquellen wie z.B. die Wikipedia ist dies möglich. Aber für die Menge an Suchanfragen und Dokumenten, die tagtäglich neu erstellt werden ist dieses Verfahren nur bedingt geeignet. U.a. deswegen hat Google seit einigen Jahren die Entwicklung von selbst lernenden Algorithemn bzw. Machine Learning vorangetrieben.
Mehr zum Thema Entitäten >>> Was ist eine Entität ? Was sind Entitäten ?
Zusammengefasst: Häufige Fragen zum Thema Knowledge Graph
Nachfolgend eine Zusammenfassung von häufigen Fragen zum Thema Knowledge Graph.
Wofür wird ein Knowledge Graph genutzt?
Ein knowledge Graph ist eine semantische Datenbank aus Knoten und Kanten. Jeder Knoten steht für eien Entität mit Attributen und Klassifizierung. Die Kanten stellen die Beziehungen zwischen den Entitäten dar. Über einen Knowledge Graph lassen sich semantische Bedeutungen von Begriffen, deren semantischen Kontext und Nähe zu anderen Begriffen identifizieren.
Aus welchen strukturierten Quellen bezieht der Google Knowledge Graph die Informationen?
Google nutzt verschiedene strukturierte und semistrukturierte Daten-Quellen, um den Knowledge Graph zu erweitern. z.B.
- Wikidata (ehemals Freebase)
- Google My Business
- CIA World Factbook
- DBpedia
- YAGO
- Webseiten mit strukturierten Daten via Microdata, RDFa und JSON-LD
- Lizensierte Daten
- CIA World Factbook
- Datensets
- ClueWeb09 bis ClueWeb12
- Common Crawl
- KBA Stream Corpus
Was bedeutet Semantik?
Die Semantik ist ein Begriff aus der Bedeutungslehre für wörter, Phrasen, Bilder oder Symbole. Die Semantik spielt bei der Kategorisierung, Deutung und Auslieferung von Informationen im Internet eine immer größere Bedeutung. Viele Große Online-Plattformen wie Facebook und Google greifen bereits auf semantische Funktionalitäten zurück.
Bücher zum Thema Knowledge Graph
Weitere Quellen zum Google Knowledge Graph
Weitere SEO-Fachbegriffe
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023
Blog-Artikel zu diesem Thema
Googles Weg zur semantischen Suchmaschine
 In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
SEO-Aufgaben: Was macht ein SEO-Manager (m/w/d)?
 Suchmaschinenoptimierung hat sich in den letzten Jahren deutlich verändert. Dadurch auch die Arbeit für SEO-Manager und SEO-Verantwortliche. In diesem Beitrag möchte ich eine Übersicht über die wichtigsten Aufgaben eines(einer) SEO-Managers/in bei der taktischen und strategischen Suchmaschineno... Artikel anzeigen
Suchmaschinenoptimierung hat sich in den letzten Jahren deutlich verändert. Dadurch auch die Arbeit für SEO-Manager und SEO-Verantwortliche. In diesem Beitrag möchte ich eine Übersicht über die wichtigsten Aufgaben eines(einer) SEO-Managers/in bei der taktischen und strategischen Suchmaschineno... Artikel anzeigen
30+ Marketing Infografiken über SEO und Content Marketing
 Wir erstellen diverse Grafiken zu den Themen SEO und Content Marketing. Hier findest Du eine Auswahl der Grafiken. Alle Grafiken lassen sich durch auf die Bilder klicken vergrößern.
Zudem sind die Bezugnehmenden Beiträge zu den Infografiken aufgeführt, die helfen in unsere Content-Welt einzut... Artikel anzeigen
Wir erstellen diverse Grafiken zu den Themen SEO und Content Marketing. Hier findest Du eine Auswahl der Grafiken. Alle Grafiken lassen sich durch auf die Bilder klicken vergrößern.
Zudem sind die Bezugnehmenden Beiträge zu den Infografiken aufgeführt, die helfen in unsere Content-Welt einzut... Artikel anzeigen
Entitäten basierte Ausgabe von Suchergebnissen und Content-Elementen in den SERPs
 Im Februar 2021 hat Google ein Patent veröffentlicht, das beschreibt wie eine kombinierte Ausgabe aus einem Suchergebnis und Content-Elementen passend zu einer Entität/Marke in den SERPs funktionieren kann. In diesem Beitrag fasse ich die wichtigsten Fakten aus dem Patent zusammen.
Zusammenfassun... Artikel anzeigen
Im Februar 2021 hat Google ein Patent veröffentlicht, das beschreibt wie eine kombinierte Ausgabe aus einem Suchergebnis und Content-Elementen passend zu einer Entität/Marke in den SERPs funktionieren kann. In diesem Beitrag fasse ich die wichtigsten Fakten aus dem Patent zusammen.
Zusammenfassun... Artikel anzeigen
Alles was Du als SEO zu Entitätstypen, -Klassen & Attributen wissen solltest
 Es gibt nur wenige Informationen zu den wichtigen Elementen des Google Knowledge Graph wie Entitätstypen, -Klassen und -Attributen und Analyse der Beziehungen zwischen diesen Elementen. Ein Grund mehr im Rahmen meiner Artikelreihe zu semantischer Suchmaschinenoptimierung darauf einzugehen.
Vom Ent... Artikel anzeigen
Es gibt nur wenige Informationen zu den wichtigen Elementen des Google Knowledge Graph wie Entitätstypen, -Klassen und -Attributen und Analyse der Beziehungen zwischen diesen Elementen. Ein Grund mehr im Rahmen meiner Artikelreihe zu semantischer Suchmaschinenoptimierung darauf einzugehen.
Vom Ent... Artikel anzeigen
Wie identifiziert man die Suchintention bzw. den Search Intent?
 Die verschiedenen Keyword-Arten und die Identifikation der Suchintention in englisch Search Intent bzw. die Nutzerintention eines Keywords ist der wichtigste Schritte im Rahmen der Keyword-Analyse. Warum? Weil Landingpages bzw. Zielseiten dem Zweck gemäß der Suchintention entsprechen sollten. N... Artikel anzeigen
Die verschiedenen Keyword-Arten und die Identifikation der Suchintention in englisch Search Intent bzw. die Nutzerintention eines Keywords ist der wichtigste Schritte im Rahmen der Keyword-Analyse. Warum? Weil Landingpages bzw. Zielseiten dem Zweck gemäß der Suchintention entsprechen sollten. N... Artikel anzeigen
Sind Nutzersignale wie CTR, Absprungrate oder Verweildauer ein Rankingfaktor?
 Der große Einfluss der Nutzersignale auf das Ranking ist in der SEO-Branche unumstritten und für die meisten SEO-Experten sind die Nutzersignale der heilige Gral. Doch sind Nutzersignale wirklich ein Rankingfaktor? Dieser Beitrag beschäftigt sich kritisch mit dieser Theorie und soll darüber ... Artikel anzeigen
Der große Einfluss der Nutzersignale auf das Ranking ist in der SEO-Branche unumstritten und für die meisten SEO-Experten sind die Nutzersignale der heilige Gral. Doch sind Nutzersignale wirklich ein Rankingfaktor? Dieser Beitrag beschäftigt sich kritisch mit dieser Theorie und soll darüber ... Artikel anzeigen
Wie versteht Google Suchanfragen durch Search Query Processing?
 Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index
 Die Basis für das Google-Ranking waren bis 2013 Websites, deren Content, Keywords und Backlinks. Mit dem Hummingbird-Update und dem Google Knowledge Graph startete Google die eigene Transformation zur semantischen Suchmaschine. Entitäten spielen bei dieser Transformation mit Blick auf die Indexier... Artikel anzeigen
Die Basis für das Google-Ranking waren bis 2013 Websites, deren Content, Keywords und Backlinks. Mit dem Hummingbird-Update und dem Google Knowledge Graph startete Google die eigene Transformation zur semantischen Suchmaschine. Entitäten spielen bei dieser Transformation mit Blick auf die Indexier... Artikel anzeigen
Indexierung und Darstellung von Medien in einem Entitäten-basierten Index
 Im Juni 2021 hat Google ein interessantes Patent veröffentlicht, in dem ein Konzept vorgestellt wird wie eine Suchmaschine Medieninhalte rund um Haupt- und verwandten Medien-Entitäten in einem Index organisieren kann. Das Patent führt die Ansätze weiter, die ich bereits im Beitrag Entitäten-bas... Artikel anzeigen
Im Juni 2021 hat Google ein interessantes Patent veröffentlicht, in dem ein Konzept vorgestellt wird wie eine Suchmaschine Medieninhalte rund um Haupt- und verwandten Medien-Entitäten in einem Index organisieren kann. Das Patent führt die Ansätze weiter, die ich bereits im Beitrag Entitäten-bas... Artikel anzeigen
Wie schlau ist Google? Echtes semantisches Verständnis oder nur Statistik?
 Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Die semantische Bedeutung von Keywords bei modernen Suchmaschinen
 In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
 In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
Suchhistorie zur Identifikation des Nutzer-Kontext
 Dieser Beitrag erläutert auf der Grundlage einiger Google-Patente und Tests wie Google aufgrund von Verknüpfungen von Suchanfragen aus der Vergangenheit den individuellen Kontext des Nutzers besser verstehen und Suggest-Vorschläge sowie Suchergebnisse besser gestalten kann. Viel Spass beim Lesen!... Artikel anzeigen
Dieser Beitrag erläutert auf der Grundlage einiger Google-Patente und Tests wie Google aufgrund von Verknüpfungen von Suchanfragen aus der Vergangenheit den individuellen Kontext des Nutzers besser verstehen und Suggest-Vorschläge sowie Suchergebnisse besser gestalten kann. Viel Spass beim Lesen!... Artikel anzeigen
Wie erstellt Google Knowledge Panel & Knowledge Cards?
 Die Präsenz von SERP-Features wie Knowledge Panel und Knowledge Cards in den SERPs von Google steigt seit Jahren rasant an. Dadurch bekommen die klassischen Suchergebnisse auch "Blue Links" genannt immer mehr Konkurrenz, wenn es um die Aufmerksamkeit der Suchenden geht. Oder nennen wir es besser di... Artikel anzeigen
Die Präsenz von SERP-Features wie Knowledge Panel und Knowledge Cards in den SERPs von Google steigt seit Jahren rasant an. Dadurch bekommen die klassischen Suchergebnisse auch "Blue Links" genannt immer mehr Konkurrenz, wenn es um die Aufmerksamkeit der Suchenden geht. Oder nennen wir es besser di... Artikel anzeigen
Video: Entitäten basierte Suche – Alles zum Knowledge Graph, NLP, Ranking, E A T und Semantik in der SEO
 Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Aufzeichnung: Semantische Suche bei Google – SEO/SEA World Conference / Internet World
 Aufzeichnung meines Vortrags auf der SEO/SEA World Conference 2021 präsentiert von der Internet World.
Google entwickelt sich seit der Einführung des Knowledge Graph und Hummingbird immer mehr zu einer semantischen Suchmaschine. Die Einführung von DeepRank (BERT) und MUM hat diesen Prozess z... Artikel anzeigen
Aufzeichnung meines Vortrags auf der SEO/SEA World Conference 2021 präsentiert von der Internet World.
Google entwickelt sich seit der Einführung des Knowledge Graph und Hummingbird immer mehr zu einer semantischen Suchmaschine. Die Einführung von DeepRank (BERT) und MUM hat diesen Prozess z... Artikel anzeigen
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
 Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?
 Die größte Herausforderung für Google mit Blick auf eine semantische Suche stellt das Identifizieren und Extrahieren von Entitäten und deren Attributen aus Datenquellen wie Websites dar. Die Informationen sind meistens nicht strukturiert und nicht fehlerfrei. Der aktuelle Knowledge Graph als Goo... Artikel anzeigen
Die größte Herausforderung für Google mit Blick auf eine semantische Suche stellt das Identifizieren und Extrahieren von Entitäten und deren Attributen aus Datenquellen wie Websites dar. Die Informationen sind meistens nicht strukturiert und nicht fehlerfrei. Der aktuelle Knowledge Graph als Goo... Artikel anzeigen
Entitäten & E-A-T: Die Rolle von Entitäten bei Autorität und Trust
 Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
Wie kann Google über Entitäten, NLP & Vektorraumanalysen relevante Dokumente identifizieren und ranken?
 Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO beschäftigt sich damit wie Google für Suchanfragen mit Entitäten-Bezug u.a. über Natural Language Language Processing und Vektorraumanalysen passende Inhalte identifiziert und rankt. Dazu habe ich über 20 Google-Patente un... Artikel anzeigen
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO beschäftigt sich damit wie Google für Suchanfragen mit Entitäten-Bezug u.a. über Natural Language Language Processing und Vektorraumanalysen passende Inhalte identifiziert und rankt. Dazu habe ich über 20 Google-Patente un... Artikel anzeigen
Indexierung und SERP-Auslieferung nach Themen bzw. Entitäten
 Dieser Beitrag beschäftigt sich mit einem Google Patent aus Juni 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Content bestimmten Entitäten / Themen zuordnet und in ein Ranking überführt. Interessant ist dieser Beitrag für fortgeschrittene SEOs, Content-Verantwortliche und Lehr... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google Patent aus Juni 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Content bestimmten Entitäten / Themen zuordnet und in ein Ranking überführt. Interessant ist dieser Beitrag für fortgeschrittene SEOs, Content-Verantwortliche und Lehr... Artikel anzeigen
SERP-Analysen für die nutzerzentrierte Content-Konzeption
 Dieser Beitrag beschäftigt sich mit der SERP-Analyse als Vorbereitung für die Content-Konzeption zur Ermittlung der passenden Suchintention, passender Medienformate und Content-Typen. Der Beitrag richtet sich an Content-Verantwortliche, SEOs und Marketing-Verantwortliche.
Der Weg zu herausragende... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit der SERP-Analyse als Vorbereitung für die Content-Konzeption zur Ermittlung der passenden Suchintention, passender Medienformate und Content-Typen. Der Beitrag richtet sich an Content-Verantwortliche, SEOs und Marketing-Verantwortliche.
Der Weg zu herausragende... Artikel anzeigen
Wie Google Fragen auf Basis unstrukturierter Daten beantworten kann
 Ein neues Google-Patent aus November 2021 hat meine Aufmerksamkeit erweckt. In ihm wird beschrieben, wie Google in natürlicher Sprache gestellte Fragen basierend auf Entitäten-Referenzen aus unstrukturierten Informationen erkennen und ranken kann. Viel Spass beim Lesen!
Das Google-Patent
Das Goo... Artikel anzeigen
Ein neues Google-Patent aus November 2021 hat meine Aufmerksamkeit erweckt. In ihm wird beschrieben, wie Google in natürlicher Sprache gestellte Fragen basierend auf Entitäten-Referenzen aus unstrukturierten Informationen erkennen und ranken kann. Viel Spass beim Lesen!
Das Google-Patent
Das Goo... Artikel anzeigen
Personalisierung und Darstellung von Informationen zu einer Entität
 Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
SMX-Vortrag: Entitäten, Knowledge Graph & Natural Language Processing als Grundpfeiler der Google-Suche
 Im März 2021 habe ich auf der virtuellen SMX einen Vortrag zum Thema "Entitäten, Knowledge Graph, Natural Language Processing und E-A-T als Grundpfeiler der Google-Suche" gehalten. Für meine Premium-Mitglieder habe ich den Vortrag mit Erlaubnis der SMX online gestellt.
... Artikel anzeigen
Im März 2021 habe ich auf der virtuellen SMX einen Vortrag zum Thema "Entitäten, Knowledge Graph, Natural Language Processing und E-A-T als Grundpfeiler der Google-Suche" gehalten. Für meine Premium-Mitglieder habe ich den Vortrag mit Erlaubnis der SMX online gestellt.
... Artikel anzeigen
Das Internet als Datengraph und wie Google daraus Informationen zu Entitäten extrahiert
 Dieser Beitrag ist eine Übersetzung des Originals THE WEB AS A DATA GRAPH IS A NEW DIRECTION FOR SEO von Bill Slawski.
Viele der Artikel, die Leute über SEO schreiben, haben mit Webseiten und Links zwischen Seiten zu tun, aber in diesem Beitrag geht es um
Entitäten und Beziehungen zwisc... Artikel anzeigen
Dieser Beitrag ist eine Übersetzung des Originals THE WEB AS A DATA GRAPH IS A NEW DIRECTION FOR SEO von Bill Slawski.
Viele der Artikel, die Leute über SEO schreiben, haben mit Webseiten und Links zwischen Seiten zu tun, aber in diesem Beitrag geht es um
Entitäten und Beziehungen zwisc... Artikel anzeigen
Personalisierte Knowledge Graphen: Dahin kann die Reise gehen!
 Die ist ein Gastbeitrag von Bill Slawski.
Ich habe einige Beiträge über Patente bei Google zu personalisierten Knowledge Graphen geschrieben (ein Thema, über das es sich lohnt, ernsthaft nachzudenken).
Als Google 2012 den Knowledge Graph einführte, erzählte man uns nur von einem einzigen ... Artikel anzeigen
Die ist ein Gastbeitrag von Bill Slawski.
Ich habe einige Beiträge über Patente bei Google zu personalisierten Knowledge Graphen geschrieben (ein Thema, über das es sich lohnt, ernsthaft nachzudenken).
Als Google 2012 den Knowledge Graph einführte, erzählte man uns nur von einem einzigen ... Artikel anzeigen
Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann
 Dies ist ein Beitrag von Bill Slawski übersetzt aus dem englischen Original-Beitrag Adjusting Featured Snippet Answers by Context
Wie wird über Featured-Snippet-Antworten entschieden?
Ich habe vor kurzem über die Bewertungssignale für Featured Snippet Answer Scores geschrieben. In diesem Beitr... Artikel anzeigen
Dies ist ein Beitrag von Bill Slawski übersetzt aus dem englischen Original-Beitrag Adjusting Featured Snippet Answers by Context
Wie wird über Featured-Snippet-Antworten entschieden?
Ich habe vor kurzem über die Bewertungssignale für Featured Snippet Answer Scores geschrieben. In diesem Beitr... Artikel anzeigen
Eine vertikale Suchmaschine für native Apps bei Google
 Google wurde im Mai 2020 ein Patent erteilt, bei dem es um eine Suchmaschine geht, die Keyword-Suchen (oder das Auffinden einer Entität) in einer vertikalen Suchmaschine für Apps auf mobilen Geräten durchführen kann, die solche Funktionalitäten abdecken kann:
(i) Persönliche Inhalte wie Kon... Artikel anzeigen
Google wurde im Mai 2020 ein Patent erteilt, bei dem es um eine Suchmaschine geht, die Keyword-Suchen (oder das Auffinden einer Entität) in einer vertikalen Suchmaschine für Apps auf mobilen Geräten durchführen kann, die solche Funktionalitäten abdecken kann:
(i) Persönliche Inhalte wie Kon... Artikel anzeigen
Knowledge Graph für alle: Google führt personenbezogene Search Profile Cards ein
 Die semantische Suche hält mit großen Schritten Einzug bei Google. Die Search Profile Cards erlauben unabhängig von Wikipedia und Einträgen bei Wikidata Personen sich als Entität bei Google zu registrieren.
Die Search Cards als Eintritt in den Knowledge Graph für jedermann
Meine Vermutung is... Artikel anzeigen
Die semantische Suche hält mit großen Schritten Einzug bei Google. Die Search Profile Cards erlauben unabhängig von Wikipedia und Einträgen bei Wikidata Personen sich als Entität bei Google zu registrieren.
Die Search Cards als Eintritt in den Knowledge Graph für jedermann
Meine Vermutung is... Artikel anzeigen
Wie man seine Entitäten-Box/Knowledge Panel bei Google beanspruchen kann
 In diesen Beitrag möchte ich eine Entdeckung mir Dir teilen, die ich bei Google gemacht habe. Google möchte wohl zukünftig, dass man seine eigene Entitäten-Box bzw. Knowledge-Panel bearbeiten beanspruchen und bearbeiten kann.
Doch vorher muss man einen Verifizierungsprozess durchlaufen um die... Artikel anzeigen
In diesen Beitrag möchte ich eine Entdeckung mir Dir teilen, die ich bei Google gemacht habe. Google möchte wohl zukünftig, dass man seine eigene Entitäten-Box bzw. Knowledge-Panel bearbeiten beanspruchen und bearbeiten kann.
Doch vorher muss man einen Verifizierungsprozess durchlaufen um die... Artikel anzeigen
Warum strukturierte Daten für Google zukünftig überflüssig werden könnten
 Googles Engagement in Sachen Machine-Learning könnte in der Zukunft dazu führen , dass die Auszeichnung von Informationen mittels strukturierter Daten überflüssig werden könnte. Die Hinweise von Google weisen darauf hin.
Google lernt auch dank der Mithilfe von Webmastern und SEOs
Der Aufbau e... Artikel anzeigen
Googles Engagement in Sachen Machine-Learning könnte in der Zukunft dazu führen , dass die Auszeichnung von Informationen mittels strukturierter Daten überflüssig werden könnte. Die Hinweise von Google weisen darauf hin.
Google lernt auch dank der Mithilfe von Webmastern und SEOs
Der Aufbau e... Artikel anzeigen
Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google
 Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
Die 45 besten Blogs für AdWords, PPC, Analytics & Conversion Optimierung
 Unsere letzte Liste mit lesenswerten PPC-Blogs ist nun schon ziemlich in die Tage gekommen. Ein Grund mehr für ein Update zu sorgen und Euch einen Einblick in unseren Agentur-Feed-Reader zu genehmigen. Diesmal gibt es einen Einblick in unsere Lesequellen zu den Themen Google AdWords, Pay-Per-Click-... Artikel anzeigen
Unsere letzte Liste mit lesenswerten PPC-Blogs ist nun schon ziemlich in die Tage gekommen. Ein Grund mehr für ein Update zu sorgen und Euch einen Einblick in unseren Agentur-Feed-Reader zu genehmigen. Diesmal gibt es einen Einblick in unsere Lesequellen zu den Themen Google AdWords, Pay-Per-Click-... Artikel anzeigen
Das semantische Web (Web 3.0) als logische Konsequenz aus dem Web 2.0
 Die Entwicklung hin zum semantischen Web verändert die Priorisierung und Auslieferung von Informationen durch die wichtigsten Gatekeeper im Netz und damit auch das Online-Marketing. Nachfolgend ein Erklärungsansatz.
Das Web 3.0 als logische Konsequenz aus dem Web 2.0
Das Web 2.0 m... Artikel anzeigen
Die Entwicklung hin zum semantischen Web verändert die Priorisierung und Auslieferung von Informationen durch die wichtigsten Gatekeeper im Netz und damit auch das Online-Marketing. Nachfolgend ein Erklärungsansatz.
Das Web 3.0 als logische Konsequenz aus dem Web 2.0
Das Web 2.0 m... Artikel anzeigen
Semantische Themen finden: Wie identifiziert man semantisch verwandte Keywords?
 Das semantische Web oder auch Web 3.0 genannt hält Einzug bei den wichtigsten Traffic-Verteilern im Netz wie Google und Facebook. Semantische Beziehungen zwischen Themen spielen insbesondere für Google eine wichtige Rolle, um thematische Relevanz von Websites und Dokumenten zu ermitteln. Nachfolg... Artikel anzeigen
Das semantische Web oder auch Web 3.0 genannt hält Einzug bei den wichtigsten Traffic-Verteilern im Netz wie Google und Facebook. Semantische Beziehungen zwischen Themen spielen insbesondere für Google eine wichtige Rolle, um thematische Relevanz von Websites und Dokumenten zu ermitteln. Nachfolg... Artikel anzeigen
SERPs in den SERPs: Die Entitäten-Box bei Google
 Bei der Suchmaschinenoptimierung dreht sich alles um die Sichtbarkeit in den Suchergebnissen. Und da ist seit einigen Jahren eine Menge los. Panda und Pinguin haben die Spielregeln für das Ranking verändert und der Knowledge-Graph hat uns das Konzept der Entitäten gebracht.
Im he... Artikel anzeigen
Bei der Suchmaschinenoptimierung dreht sich alles um die Sichtbarkeit in den Suchergebnissen. Und da ist seit einigen Jahren eine Menge los. Panda und Pinguin haben die Spielregeln für das Ranking verändert und der Knowledge-Graph hat uns das Konzept der Entitäten gebracht.
Im he... Artikel anzeigen
Happy Hash-Tagging bei Google! Semantische Verbindung von Inhalten und Entitäten
 Das #Hashtag ist ein Internetdings mit einer wichtigen Funktion. Es dient der Verschlagwortung von Inhalten und kann als solches ein wenig Ordnung in die digitale Informationsflut bringen. Wobei „Ordnung“ relativ gemeint ist.
Man könnte sie eher als eine Art roten Faden im Informationsch... Artikel anzeigen
Das #Hashtag ist ein Internetdings mit einer wichtigen Funktion. Es dient der Verschlagwortung von Inhalten und kann als solches ein wenig Ordnung in die digitale Informationsflut bringen. Wobei „Ordnung“ relativ gemeint ist.
Man könnte sie eher als eine Art roten Faden im Informationsch... Artikel anzeigen
Branking: Notizen zur SEOptimierung des Selbst
 Der wahre Preis von Anonymität ist Irrelevanz. Diese vielzitierte Aussage von Eric Schmidt klingt im Schatten von Geheimdienstaffären und Datenspeicherungen wie Hohn. Sie verrät uns aber eine Menge über Google und die Zukunft der Optimierung innerhalb der Suchmaschine.
Es geht nicht mehr ... Artikel anzeigen
Der wahre Preis von Anonymität ist Irrelevanz. Diese vielzitierte Aussage von Eric Schmidt klingt im Schatten von Geheimdienstaffären und Datenspeicherungen wie Hohn. Sie verrät uns aber eine Menge über Google und die Zukunft der Optimierung innerhalb der Suchmaschine.
Es geht nicht mehr ... Artikel anzeigen
























