Zum Anfang des Beitrags, wollte ich einige Whitepaper einbeziehen, an denen Autoren aus dem Hause Google beteiligt sind. Die Autoren des ersten Papiers sind die Erfinder einer Patentanmeldung, die am 28. April 2020 veröffentlicht wurde. Diese Whitepaper sind lesenswert, um einen Eindruck davon zu bekommen, wie Google versucht, Abfragen in „Well-Formed Natural Language Questions“ umzuschreiben.
Inhaltsverzeichnis
- 1 Identifizierung wohlgeformter natürlichsprachlicher Fragen
- 2 Wie stellt man bessere Fragen? Ein groß angelegter Multi-Domain-Datensatz zum Neuschreiben schlecht formulierter Fragen
- 3 Umformung nicht eindeutiger Suchanfragen in gut deutbare Suchanfragen
- 4 Nach dem Neuschreiben einer Abfrage
- 5 Bestimmen, ob eine Abfrage eine eindeutige Suchanfrage ist
- 6 Wie das Klassifizierungsmodell funktioniert
- 7 Eine mögliche Verwendung eines Kanonisierungsmodells
- 8 Fazit und Take Aways
Identifizierung wohlgeformter natürlichsprachlicher Fragen
Hier die Zusammenfassung aus dem Whitepaper:
Understanding search queries is a hard problem as it involves dealing with “word salad” text ubiquitously issued by users. However, if a query resembles a well-formed question, a natural language processing pipeline can perform more accurate interpretation, thus reducing downstream compounding errors.
Hence, identifying whether or not a query is well-formed can enhance query understanding. Here, we introduce a new task of identifying a well-formed natural language question. We construct and release a dataset of 25,100 publicly available questions classified into well-formed and non-wellformed categories and report an accuracy of 70.7% on the test set.
We also show that our classifier can be used to improve the performance of neural sequence-to-sequence models for generating questions for reading comprehension.
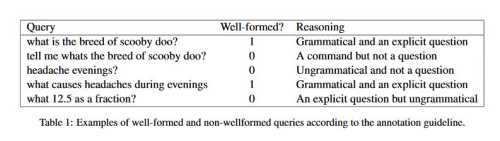
Das Whitepaper enthält Beispiele für gut formulierte und schlecht formulierte Fragen:
Wie stellt man bessere Fragen? Ein groß angelegter Multi-Domain-Datensatz zum Neuschreiben schlecht formulierter Fragen
Das zweite Whitepaper ist vom 21.November 2019: How to Ask Better Questions? A Large-Scale Multi-Domain Dataset for Rewriting Ill-Formed Questions
Auch hier die Zusammenfassung zum Einstieg:
We present a large-scale dataset for the task of rewriting an ill-formed natural language question to a well-formed one. Our multi-domain question rewriting (MQR) dataset is constructed from human contributed Stack Exchange question edit histories.
The dataset contains 427,719 question pairs which come from 303 domains. We provide human annotations for a subset of the dataset as a quality estimate. When moving from ill-formed to well-formed questions, the question quality improves by an average of 45 points across three aspects.
We train sequence-to-sequence neural models on the constructed dataset and obtain an improvement of 13.2%in BLEU-4 over baseline methods built from other data resources. We release the MQR dataset to encourage research on the problem of question rewriting.

Die Patentanmeldung, über die ich schreibe, wurde am 18. Januar 2019 eingereicht. Damit liegt sie zeitlich etwa in der Mitte zwischen diesen beiden Whitepapern, und beide sind empfehlenswert, um ein gutes Gefühl dafür zu bekommen, wie Google versucht Fragen zu beantworten. Das zweite Whitepaper bezieht sich auf das erste Whitepaper und erklärt uns, wie versucht wird die im ersten Whitepaper vorgestellte Methode zu verbessern:
Faruqui and Das (2018) introduced the task of identifying well-formed natural language questions. In this paper, we take a step further to investigate methods to rewrite ill-formed questions into well-formed ones without changing their semantics. We create a multi-domain question rewriting dataset (MQR) from human contributed StackExchange question edit histories.
Umformung nicht eindeutiger Suchanfragen in gut deutbare Suchanfragen
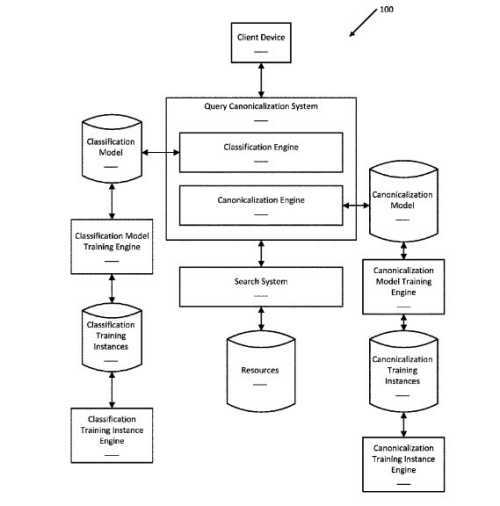
Interessanterweise geht es bei dem Patent auch darum, Suchanfragen umzuschreiben. Es beginnt damit, dass „regelbasierte Verfeinerungen von Suchanfragen bei der Anfrageverarbeitung in Komponenten von Suchsystemen verwendet werden“. Manchmal geschieht dies, indem bestimmte Stoppwörter aus Suchtermen entfernt werden, wie z.B. „das“, „ein“, usw.
Nach dem Neuschreiben einer Abfrage
Sobald eine Anfrage umgeschrieben wurde, kann sie „an das Suchsystem übermittelt und Suchergebnisse zurückgegeben werden, die auf die umgeschriebene Anfrage reagieren“. Das Patent sagt uns auch über „Leute suchen auch nach X“-Abfragen (das erste Patent, in dem ich sie erwähnt sehe). Uns wird gesagt, dass diese ähnlichen Anfragen dazu benutzt werden, zusätzliche Anfragen zu empfehlen, die mit einer eingereichten Anfrage zusammenhängen (z.B. „Leute suchen auch nach X“).
Diese „ähnlichen Abfragen zu einer bestimmten Abfrage werden oft durch navigatorisches Clustering bestimmt“. Als Beispiel wird die Suchanfrage „funny cat pictures“ erwähnt, über die eine ähnliche Suchanfrage von „funny cat pictures with captions“ bestimmt werden kann, weil diese ähnliche Suchanfrage häufig von Suchenden nach Einreichung der Suchanfrage „funny cat pictures“ gestellt wird.
Bestimmen, ob eine Abfrage eine eindeutige Suchanfrage ist
Das Patent beschreibt ein Verfahren, mit dem festgestellt werden kann, ob eine Suchanfrage eindeutig ist. Wenn dies nicht der Fall ist wird ein trainiertes Kanonisierungsmodell verwendet, um eine eindeutige Variante dieser Suchanfrage zu erstellen.
Zunächst wird uns eine Definition von „eindeutig“ gegeben. Dabei wird eine Phrase und/oder ein anderes zusätzliches linguistisches Element geprüft, ob die Suchanfrage den Grammatikregeln einer bestimmten Sprache entspricht“.
Drei Schritte bedarf es dafür:
- grammatikalisch korrekt
- Enthält keine Rechtschreibfehler
- bittet um eine ausdrückliche Frage
Das erste Whitepaper zu diesem Patent sagt uns Folgendes über Suchanfragen:
The lack of regularity in the structure of queries makes it difficult to train models that can optimally process the query to extract information that can help understand the user intent behind the query.
Das ist der wichtigste Take-Away für diesen Beitrag:
Eine eindeutige Suchanfraege ist so strukturiert, dass eine Suchmaschine die Absicht (Suchintention) des Benutzers hinter der Anfrage verstehen kann.
Das Patent gibt uns ein Beispiel:
„Wie lautet die Wegbeschreibung zu einem Café“ ist ein Beispiel für eine eindeutige Version des Suchterms „Café Wegbeschreibungen“
Wie das Klassifizierungsmodell funktioniert
Das Patent beschriebt auch, dass der Zweck hinter dem Verfahren im Patent darin besteht, zu bestimmen, ob eine Suchanfrage mit Hilfe eines trainierten Klassifikationsmodells und/oder einer eindeutigen Variante einer Suchanfrage eindeutig ist und ob diese wohlgeformte Version mit Hilfe eines trainierten Kanonisierungsmodells erzeugt werden kann.
Es kann dieses Modell erstellen, indem es Merkmale der Suchanfrage als Input für das Klassifikationsmodell verwendet und entscheidet, ob die Suchanfrage eindeutig ist.
Zu diesen Merkmalen der Suchanfrage können zum Beispiel gehören:
- Buchstabe(n)
- Wort(e)
- Part of Speech
- In der Suchanfrage enthaltene Entitäten
- und/oder andere sprachliche Repräsentation(en) der Suchanfrage (z.B. Wort-N-Grams, Bag of Words usw.)
Und das Patent beschreibt die Art des Klassifikationsmodells:
The classification model is a machine learning model, such as a neural network model that contains one or more layers such as one or more feed-forward layers, softmax layer(s), and/or additional neural network layers. For example, the classification model can include several feed-forward layers utilized to generate feed-forward output. The resulting feed-forward output can be applied to softmax layer(s) to generate a measure (e.g., a probability) that indicates whether the search query is well-formed.
Eine mögliche Verwendung eines Kanonisierungsmodells
Wenn das Klassifikationsmodell feststellt, dass die Suchanfrage nicht eindeutig ist, wird die Suchanfrage an ein trainiertes Kanonisierungsmodell übergeben, um eine eindeutige Version der Suchanfrage zu erzeugen. Der Suchanfrage können einige ihrer Merkmale aus der ursprünglichen Suchanfrage extrahiert und/oder zusätzliche Eingaben mit Hilfe des Kanonisierungsmodells verarbeitet werden, um eine eindeutige Version zu erzeugen, die mit der ursprünglichen Suchanfrage korreliert.
Das Kanonisierungsmodell kann ein neuronales Netzmodell (Machine Learning) sein. Das Patent enthält weitere Einzelheiten über die Art des verwendeten neuronalen Netzes. Das neuronale Netz kann eine eindeutige Version der ursprünglichen Suchnafrage anzeigen. Es wird auch beschrieben, dass es zusätzlich zur Identifizierung einer eindeutigen Suchanfrage auch „eine oder mehrere verwandte Suchanfragen für eine bestimmte Suchanfrage“ bestimmen kann.
Eine verwandte Suchanfrage kann auf der Grundlage der Tatsache bestimmt werden, dass die verwandte Suchanfrage häufig von Benutzern nach der Einreichung der ursprünglichen Suchanfrage eingereicht wird. Das System zur Kanonisierung von Anfragen kann auch feststellen, ob die verwandte Suchanfrage eindeutig ist. Ist dies nicht der Fall, kann es eine eindeutige Variante der verwandten Suchanfrage bestimmen.
Zum Beispiel kann als Antwort auf die Einreichung der gegebenen Suchanfrage eine wählbare Version der wohlgeformten Variante zusammen mit den Suchergebnissen für die gegebene Anfrage präsentiert werden, und, falls ausgewählt, kann die eindeutige Variante (oder die verwandte Anfrage selbst in einigen Implementierungen) als Suchanfrage eingereicht werden, und die Suchergebnisse für die eindeutige Variante (oder die verwandte Anfrage) zu präsentieren.
Wiederum taucht die Idee der „Absicht“ bzw. Suchintention im Patent in Bezug auf verwandte Anfragen auf („Personen suchten auch nach“).
Der Mehrwert der Ausspielung einer eindeutigen Variante einer verwandten Suchanfrage anstelle der verwandten Suchanfrage selbst besteht darin, dem Suchenden die Absicht der verwandten Suchanfrage leichter und/oder schneller verständlich zu machen.
Das Patent beschreibt, dass dies einen großen Mehwert hat:
Such efficient understanding enables the user to quickly submit the well-formed variant to quickly discover additional information (i.e., result(s) for the related query or well-formed variant) in performing a task and/or enables the user to only submit such query when the intent indicates likely relevant additional information in performing the task.
Hier ein Beispiel für eine verwandte eindeutige Suchanfrage aus dem Patent:
As one example, the system can determine the phrase “hypothetical router configuration” is related to the query “reset hypothetical router” based on historical data indicating the two queries are submitted proximate (in time and/or order) to one another by a large number of users of a search system.
In some such implementations, the query canonicalization system can determine the related query “reset hypothetical router” is not a well-formed query, and can determine a well-formed variant of the related query, such as: “how to reset hypothetical router”.
The well-formed variant “how to reset hypothetical router” can then be associated, in a database, as a related query for “hypothetical router configuration”—and can optionally supplant any related query association between “reset hypothetical router” and “hypothetical router configuration”.
Das Patent sagt uns, dass manchmal eine eindeutige verwandte Anfrage als Link zu den Suchergebnissen präsentiert werden kann. Auch hier ist eines der Merkmale einer eindeutigen Abfrage, dass sie grammatikalisch richtig ist, eine explizite Frage darstellt und keine Rechtschreibfehler enthält.
Die Patentanmeldung findet man hier Canonicalizing Search Queries to Natural language Questions.
Zusammenfassung aus dem Patent:
Techniques are described herein for training and/or utilizing a query canonicalization system. In various implementations, a query canonicalization system can include a classification model and a canonicalization model. A classification model can be used to determine if a search query is well-formed. Additionally, a canonicalization model can be used to determine a well-formed variant of a search query in response to determining a search query is not well-formed. In various implementations, a canonicalization model portion of a query canonicalization system can be a sequence to sequence model.
Fazit und Take Aways
Das war eine grobe Zusammenfassung und wenn Du mehr Einzelheiten erfahren möchtest, kannst Du dir das verlinkte Patent ansehen. Die beiden Whitepaper, mit denen ich den Beitrag begonnen habe, beschreiben Datenbanken mit eindeutigen Fragen, die Mitarbeiter von Google (einschließlich der Erfinder dieses Patents) erstellt haben, und zeigen das Engagement, das Google in die Idee investiert hat, Suchanfragen so umzuschreiben, dass sie eindeutig interpretierbar sind und so die Suchintention bzw. -absicht dahinter von der Suchmaschine besser verstanden werden kann.
Wie wir bei diesem Patent gesehen haben, wird die Analyse, die durchgeführt wird, um kanonische Suchanfragen zu finden, auch dazu verwendet, um „Personen suchten auch nach“ Suchanfragen zu präsnetiren, die ebenfalls kanonisiert und in den Suchergebnissen angezeigt werden können.
Eine gut formulierte Suchanfrage ist grammatikalisch korrekt, enthält keine Rechtschreibfehler und stellt eine explizite Frage dar. Sie macht der Suchmaschine auch klar, was die Absicht hinter der Suchnafrage sein kann.
Dies ist eine deutsche Übersetzung des Original-Beitrags A Well-Formed Query Helps Search Engines Understand User Intent in the Query .

- Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index - 6. April 2021
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise - 15. Dezember 2020
- Personalisierte Knowledge Graphen: Dahin kann die Reise gehen! - 24. November 2020
- Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann - 2. November 2020
- Wie Google Ergebnisse für ein Featured Snippet auswählen kann - 29. September 2020

























Ein Kommentar