Dieser Beitrag ist eine Übersetzung des Originals THE WEB AS A DATA GRAPH IS A NEW DIRECTION FOR SEO von Bill Slawski.
Viele der Artikel, die Leute über SEO schreiben, haben mit Webseiten und Links zwischen Seiten zu tun, aber in diesem Beitrag geht es um
- Entitäten und Beziehungen zwischen Entitäten und Fakten
- über die auf Webseiten geschrieben wird
- Antworten auf Abfragen von Datendiagrammen im Web über Fakten und Attribute, die sich auf Entitäten beziehen, die auf Webseiten gefunden werden.
Inhaltsverzeichnis
- 1 Über das Google-Patent
- 2 Aufbau von Gewissheit über dir Richtigkeit über die Beziehung zwischen Daten und Fakten
- 3 Ausliefern von Suchergebnissen aus einem Datengraph für gesprochene Suchanfragen
- 4 Vorteile dieser Methodik
- 5 Besseres Verständnis eines Datengraphen
- 6 Warum ist die beschriebene Methodik so interessant?
Über das Google-Patent
Vor kurzem bin ich auf der WIPO-Seite (World Intellectual Property Organization) auf eine Patentanmeldung gestoßen, von der ich dachte, dass sie es wert ist, darüber zu schreiben. Das Patent beginnt mit diesem Satz:
Large data graphs store data and rules that describe knowledge about the data in a form that provides for deductive reasoning.
Der Titel des Patents beschreibt, dass es im Idealfall darum geht, Anfragen an eine Suchmaschine in natürlicher Sprache zu stellen (die Art und Weise, wie Menschen sprechen und Computer versuchen, sie zu verstehen).
Das Patent zeigt uns ein Beispiel, das sich auf einen Datengraphen bezieht, Entitäten, wie Menschen, Orte, Dinge, Konzepte usw., die als Knoten gespeichert werden können und die Kanten zwischen diesen Knoten können die Beziehung zwischen den Knoten anzeigen (Fakten, die Menschen über diese Entitäten herausfinden können). In der Suchmaschinenoptimierung sind wir es gewohnt, von Webseiten als Knoten und Links zwischen diesen Seiten als Kanten zu sprechen. Diese Herangehensweise an Entitäten ist eine andere Art, Knoten und Kanten zu betrachten, und wir haben in letzter Zeit gesehen, dass man von Erwähnungen von Entitäten anstelle von Links spricht, die Seiten erwähnen. Es ist eine Möglichkeit für SEO, über reale Objekte wie Entitäten nachzudenken, wenn man über eine große Datenbank wie das Web spricht. Das zweite Patent von Google aus dem Jahr 1999 (ein vorläufiges), das mir bekannt ist, handelt von Fakten und einer solch großen Datenbank. Ich habe darüber in Google’s First Semantic Search Invention was Patented geschrieben.
Ich habe auch über ein neueres Patent von Google geschrieben, das beschreibt wie die Suchmaschine das Web lesen und Entitätsinformationen daraus extrahieren kann, und das Web als große verstreute Datenbank nutzen kann. Dieser Beitrag ist Entity Extractions for Knowledge Graphs at Google.
Man findet viele Informationen über Pre-Trainingsprogramme wie BERT, die Wörter in einem Dokument mit Wortteilen markieren und Entitäten identifizieren und erkennen können, so dass sie aus den Seiten extrahiert und von der Suchmaschine gelernt werden können.
Dazu auch folgende Beiträge hier im Blog:
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten? (Premium)
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen (Premium)
Dieses neueste Patent beschreibt, dass in einem solchen Datengraphen Knoten wie „Maryland“ und „Vereinigte Staaten“ durch die Kanten von „im Land“ und/oder „hat Staat“ verbunden sein können. Man erfährt auch, dass die Grundeinheit eines solchen Datengraphen ein Tupel ist, das zwei Entitäten und eine Beziehung zwischen den Entitäten enthält. Diese Tupel können reale Fakten darstellen, wie z. B. „Maryland ist ein Bundesstaat der Vereinigten Staaten.“ Das Tupel kann auch andere Informationen enthalten, z. B. Kontextinformationen, statistische Informationen, Prüfungsinformationen usw.
Das Hinzufügen von Entitäten und Beziehungen zu einem Datengraphen war bisher in der Regel ein manueller Prozess, was die Erstellung großer Datengraphen schwierig und langsam macht. Und die Schwierigkeit bei der Erstellung großer Datengraphen kann zu vielen „fehlenden“ Entitäten und „fehlenden“ Beziehungen zwischen Entitäten führen, die zwar als Fakten existieren, aber dem Graphen noch nicht hinzugefügt wurden. Solche fehlenden Entitäten und Beziehungen verringern die Nützlichkeit von Datengraphen. Einige Methoden extrahieren syntaktisches und semantisches Wissen aus Text, z. B. aus dem Web, und kombinieren dieses mit semantischem Wissen aus Datengraphen.
Aufbau von Gewissheit über dir Richtigkeit über die Beziehung zwischen Daten und Fakten
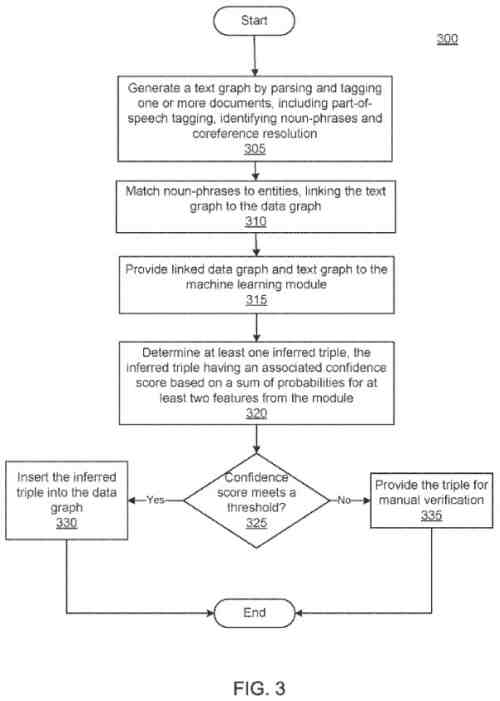
Das aus dem Text und dem Datengraphen extrahierte Wissen wird als Input verwendet, um einen Machine-Learning-Algorithmus zu trainieren, der Tupel für den Datengraphen vorhersagt.
Der trainierte Machine-Learning-Algorithmus kann mehrere gewichtete Merkmale für eine bestimmte Beziehung erzeugen, wobei jedes Merkmal eine Schlussfolgerung darüber darstellt, wie zwei Entitäten miteinander in Beziehung stehen könnten.
Der absolute Wert der Gewichtung eines Merkmals kann die relative Wichtigkeit bei der Entscheidungsfindung darstellen. Google hat in anderen Patenten darauf hingewiesen, dass sie wahrscheinliche Richtigkeit zwischen solchen Beziehungen messen und diese Gewichtungen „Assoziations-Scores“ nennen.
Der trainierte Machine-Learning-Algorithmus kann dann verwendet werden, um aus der Analyse von Dokumenten in einem großen Korpus und den vorhandenen Informationen im Datengraphen zusätzliche Tupel zu erstellen.
Diese Methode liefert eine große Anzahl zusätzlicher Tupel für den Datengraphen, wodurch dieser Datengraph stark erweitert werden kann.
In einigen Methoden kann jedes vorhergesagte Tupel mit einem Konfidenzwert verknüpft werden und nur Tupel, die einen Schwellenwert erfüllen, werden automatisch zum Datengraphen hinzugefügt.
Mehr dazu auch in den bereist erwähnten Beiträgen hier im Blog.
Die Fakten, die durch die restlichen Tupel repräsentiert werden, können manuell verifiziert werden, bevor sie dem Datengraphen hinzugefügt werden.
Einige Methoden ermöglichen die Beantwortung von Suchanfragen in natürlicher Sprache aus dem Datengraphen.
Das Machine-Learning-Modul kann trainiert werden, um Merkmale auf Abfragen abzubilden, und die Merkmale werden verwendet, um mögliche Suchergebnisse zu liefern.
Das Training kann die Verwendung von positiven Beispielen aus Suchdatensätzen oder Suchergebnissen beinhalten, die von einer dokumentenbasierten Suchmaschine erhalten werden.
Das trainierte Machine-Learning-Modul kann mehrere gewichtete Merkmale erzeugen, wobei jedes Merkmal eine mögliche Antwort darstellt, die durch einen Pfad im Datengraphen repräsentiert wird.
Der absolute Wert der Gewichtung des Merkmals stellt die relative Wichtigkeit bei der Entscheidungsfindung dar.
Sobald das Machine-Learning-Modul mit den mehrfach gewichteten Merkmalen richtig trainiert wurde, kann es zur Beantwortung von natürlichsprachlichen Anfragen unter Verwendung von Informationen aus dem Datengraphen verwendet werden.
Ein Verfahren umfasst den Einsatz eines Machine-Learning-Moduls, das so trainiert ist, dass es ein Modell mit mehreren gewichteten Merkmalen für eine Suchanfrage erzeugt, wobei jedes gewichtete Merkmal einen Pfad in einem Datengraphen darstellt.
Das Verfahren umfasst auch das Empfangen einer Suchanfrage, die einen ersten Suchbegriff enthält, das Abbilden der Suchanfrage auf die Abfrage, das Abbilden des ersten Suchbegriffs auf eine erste Entität in dem Datengraphen, und das Identifizieren einer zweiten Entität in dem Datengraphen unter Verwendung der ersten Entität und mindestens eines der mehrfach gewichteten Merkmale.
Das Merkmal kann auch das Bereitstellen von Informationen in Bezug auf die zweite Entität in einer Antwort auf die Suchanfrage umfassen.
Die Abfrage kann eine gesprochene Suchanfrage sein.
Als weiteres Beispiel kann das Verfahren das Trainieren des Maschine-Learning-Moduls umfassen, um das Modell zu erzeugen, das im Mittelpunkt dieses Patents steht.
Ausliefern von Suchergebnissen aus einem Datengraph für gesprochene Suchanfragen
Das Trainieren des Machine-Learning-Moduls kann das Erzeugen unklarer Abfrage-Ergebnissen und das Erzeugen positiver und negativer Trainingsbeispiele aus den unklaren Abfrage-Ergebnissen beinhalten.
Das Erzeugen der unklaren Abfrage-Ergebnissen kann das Ausliefern von Suchergebnissen von einer Suchmaschine aus einen Dokumentenkorpus beinhalten, wobei jedes Ergebnis eine Validitäts-Bewertung hat, und das Erzeugen der Trainingsbeispiele kann das Auswählen einer vorbestimmten Anzahl von Dokumenten mit der höchsten Bewertung als positive Trainingsbeispiele und das Auswählen einer vorbestimmten Anzahl von Dokumenten mit einer Bewertung unter einem Schwellenwert als negative Trainingsbeispiele beinhalten.
Das Ausliefern von Suchergebnissen kann das Auslesen von Suchergebnissen aus Suchdatensätzen für vergangene Suchanfragen beinhalten.
Das Erzeugen von positiven und negativen Trainingsbeispielen kann das Durchführen von Entity-Matching auf den Abfrageantworten und das Auswählen von Entitäten, die am häufigsten vorkommen, als positive Trainingsbeispiele beinhalten.
Das Verfahren kann auch das Bestimmen eines Konfidenzwertes (wie die oben erwähnten Assoziationswerte) für die zweite Entität basierend auf dem Gewicht mindestens eines gewichteten Merkmals umfassen.
Das Identifizieren der zweiten Entität in dem Graphen kann auch das Auswählen der zweiten Entität auf der Grundlage des Konfidenzwerts umfassen. Die Bestimmung des Konfidenzwerts für die zweite Entität kann umfassen, dass zwei oder mehr Merkmale mit der zweiten Entität in Verbindung stehen und das Verwenden einer Kombination der Bewertungen der zwei oder mehr Merkmale als den Konfidenzwert für die zweite Entität genutzt werden.
Ein Verfahren umfasst das Trainieren eines Machine-Learning-Moduls, um mehrere gewichtete Merkmale für eine Suchanfrage zu erzeugen sowie das Empfangen einer Suchanfrage,
Das Verfahren umfasst auch die Identifikation einer ersten Entität aus der Suchanfrage, wobei die erste Entität in einem Datengraphen existiert und das Bereitstellen der ersten Entität an das Machine Learning-Modul.
Das Verfahren kann auch das Empfangen einer Teilmenge der mehrfach gewichteten Merkmale von dem Machine-Learning-Modul und das Erzeugen einer Antwort umfassen, die Informationen enthält, die unter Verwendung der Teilmenge der mehrfach gewichteten Merkmale enthalten sind.
Diese können eines oder mehrere der folgenden Merkmale enthalten. Das Trainieren des Moduls kann zum Beispiel Folgendes beinhalten:
- Auswählen von positiven und negativen Beispielen aus dem Datengraphen für die Suchanfrage
- Ausliefern der positiven Beispiele, der negativen Beispiele und des Datengraphen an das Machine-Learning-Modul zum Trainieren.
- Empfangen der mehrfach gewichteten Merkmale von dem Modul, wobei jedes Merkmal eine Verbindung in dem Datengraphen darstellt
- Speichern mindestens eins der mehrfach gewichteten Merkmale in einem der Abfrage zugeordneten Modell
Einige der Merkmale, denen dieser Prozess folgt, können die Begrenzung einer Pfadlänge für die Merkmale auf eine vorbestimmte Länge beinhalten. Die Pfadlänge ist die Anzahl der Kanten bzw. Verbindungen, die im Pfad für ein bestimmtes Merkmal durchlaufen werden. Zudem können die positiven und negativen Beispiele aus den Suchdatensätzen generiert werden.
Die mehrfach gewichteten Merkmale können Merkmale ausschließen, die unter einem Schwellenwert hinsichtlich der Häufigkeit in dem Datengraphen vorkommen.
Das Erzeugen der Antwort auf die Suchanfrage kann die Identifikation einer zweiten Entität im Datengraphen mit der höchsten Gewichtung und das Einfügen von Informationen aus der zweiten Entität in die Antwort beinhalten.
Die Gewichtung der zweiten Entität kann die Summe jedes Merkmals sein, das der zweiten Entität zugeordnet ist.
Außerdem kann das Computersystem einen Speicher beinhalten, der aus einem kantenbeschrifteten Datengraphen und Tupel konstruiert ist. Jedes Tupel stellt zwei Entitäten dar, die durch eine Beziehung verbunden sind.
Diese einzelnen Arbeitsschritte können umfassen:
- Empfangen einer Suchanfrage
- Ausliefern von Suchergebnissen für die Abfrage
- Erzeugen von positiven und negativen Trainingsbeispielen aus den Suchergebnissen
- Bereitstellen der Positivbeispiele, der Negativbeispiele an ein Machine-Learning-Modul
Die Arbeitsschitte können auch den Empfang einer Vielzahl von Merkmalen vom Modul für die Abfrage und das Speichern der Vielzahl von Merkmalen als ein der Abfrage zugeordnetes Modell im Modul umfassen.
Die Anzahl der Features kann auch Features ausschließen, die weniger als eine vorbestimmte Anzahl von Malen im Datengraphen vorkommen.
Vorteile dieser Methodik
- Über dieses Verfahren kann ein Datengraph automatisch erweitert werden, indem sie relative Informationen aus einem großen Textkorpus auslesen. Quellen können z. B. über das Internet verfügbare Dokumente oder andere Korpusse sein. Diese Informationen können mit vorhandenen Informationen aus dem Datengraphen kombiniert werden.
- Über solch ein Verfahren können Millionen von neuen Tupeln für einen Datengraphen mit hoher Genauigkeit erstellt werden.
- Es können auch Abfragen in natürlicher Sprache auf Pfade im Datengraphen abgebildet werden, um Suchergebnisse aus dem Datengraphen zu erzeugen.
- Die Schwierigkeit bei gesprochenen Abfragen besteht darin, eine Übereinstimmung zwischen den Beziehungen oder Kanten im Datengraphen und der Abfrage zu finden.
- Das Verfahren kann ein Machine-Learning-Modul trainieren, so dass die Interpretation natürlichsprachlicher Abfragen ohne eine manuell eingegebene Synonymtabelle möglich ist, die nur schwer vollständig zu befüllen, zu pflegen und zu überprüfen wäre.
Das besprochene Patent ist hier nachzulesen:
Querying a Data Graph Using Natural Language Queries
Inventors Amarnag Subramanya, Fernando Pereira, Ni Lao, John Blitzer, Rahul Guptag
Applicants GOOGLE LLC
US20210026846
Patent Filing Date October 13, 2020
Patent Number 20210026846
Granted: January 28, 2021
Besseres Verständnis eines Datengraphen
In diesem Patent wird eine syntaktisch-semantisches Inferenzsystem beschrieben inkl. eines Beispiels.
Dieses System könnte verwendet werden, um ein Machine-Learning-Modul zu trainieren, um mehrere gewichtete Merkmale oder Pfade im Datengraphen zu erkennen, um neue Tupel für den Datengraphen zu generieren, die auf Informationen basieren, die bereits im Graphen vorhanden sind und/oder auf geparsten Textdokumenten basieren.
Das System kann so arbeiten, dass es Suchergebnisse aus dem Datengraphen anhand einer natürlichsprachlichen Suchanfrage generiert.
Dieses Patent beschreibt ein System, das über das Internet verfügbare Dokumente verwendet.
Es wird aber beschrieben, dass auch andere Konfigurationen und Anwendungen verwendet werden können.
Diese können Dokumente umfassen, die aus einem anderen Dokumentenkorpus stammen, wie z. B. interne Dokumente, die nicht über das Internet verfügbar sind, oder aus einem anderen privaten Korpus, aus einer Bibliothek, aus Büchern, aus einem Korpus wissenschaftlicher Daten oder einem anderen großen Korpus.
Das syntaktisch-semantische Inferenzsystem kann ein Computer sein, der die Form von mehreren verschiedenen Geräten annimmt, z. B. ein Standard-Server, eine Gruppe solcher Server oder ein Rack-Server-System.
Das syntaktisch-semantische Inferenzsystem kann einen Datengraphen enthalten. Der Datengraph kann ein kantenbeschrifteter Graph sein. Ein solcher Datengraph speichert Knoten und Kanten.
Die Knoten im Datengraphen repräsentieren eine Entität, wie z. B. eine Person, einen Ort, einen Gegenstand, eine Idee, ein Thema, ein abstraktes Konzept, ein konkretes Element, eine andere geeignete Sache oder eine beliebige Kombination davon.
Die Entitäten im Datengraphen können durch Kanten miteinander verbunden sein, die Beziehungen zwischen den Entitäten darstellen.
Beispielsweise kann der Datengraph eine Entität haben, die dem Schauspieler Kevin Bacon entspricht, und der Datengraph kann eine Beziehung zwischen der Entität Kevin Bacon und Entitäten haben, die Filme repräsentieren, in denen Kevin Bacon mitgewirkt hat.
Ein Datengraph mit einer großen Anzahl von Entitäten und sogar einer begrenzten Anzahl von Beziehungen kann Milliarden von Verbindungen aufweisen.
Mehr dazu im Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index (Premium) oder Google Knowledge Graph einfach erklärt.
In einigen Umsetzungen können Datengraphen in einem externen Speichergerät gespeichert werden, auf das vom System aus zugegriffen werden kann.
In einigen Verfahren kann der Datengraph über mehrere Speichergeräte und/oder mehrere Rechengeräte, z. B. mehrere Server, verteilt sein.
Das Patent liefert weitere Details über die Vertrauensbewertung von Fakten, das Tagging von Wortteilen in einem Korpus und die Entitätsextraktion.
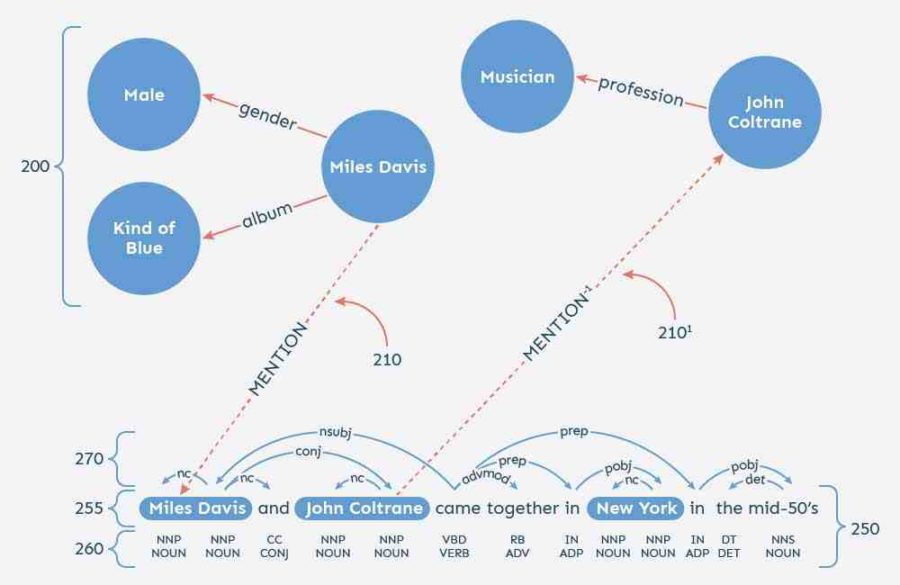
Konkret geht es um Entitäten wie Miles Davis, John Coltrane und New York sowie um die Verwendung der Koreferenzauflösung zum besseren Verständnis von Pronomen in Dokumenten.
Ein Text-Graph, der gemäß dem Patent erzeugt werden könnte, kann auch mit dem Datengraph verknüpft werden.
Das Patent beschreibt, dass die Verknüpfung durch Entitäts-Auflösung erfolgen kann oder durch die Bestimmung, welche Entität aus dem Datengraphen, falls vorhanden, mit einer Substantiv-Phrase in einem Dokument übereinstimmt.
Mit Aussagen wie dieser aus dem Patent sind wir wieder bei der Idee, Erwähnungen für die SEO zu verwenden:
Matches may receive a mention link between the entity and the noun phrase, as shown by links and 210′ of FIG. 2.
Dies ist anders als HTML-Links, aber es lohnt sich, ein Auge darauf zu werfen. Das Patent informiert uns über die Beziehungen zwischen Knoten und Kanten wie hier in einem Datendiagramm:
Edge represents an edge from the data graph entity to the noun-phrase in the document. Edge′ represents the reverse edge, going from the noun-phrase to the entity.
Thus, as demonstrated in FIG. 2, the edges that link the data graph to the text graph may lead from the entity to the noun-phrase in a forward direction, and from the noun-phrase to the entity in a reverse direction.
Of course, forward Edge may have a corresponding reverse edge, and reverse Edge′ may have a corresponding forward edge, although these edges are not shown in the figure.
Das Patent beschreibt die Verwendung von Konfidenz-Scores und Merkmalsgewichtung für das Vertrauen in die Entitäten anhand von Abfragen wie dieser, in der uns über das Training mit diesem System bekannt ist:
In some implementations, the training engine may be configured to use a text graph generated by the syntactic-semantic parsing engine from crawled documents that are linked to the data graph to generate training data for the machine learning module.
The training engine may generate the training data from random, path-constrained walks in the linked graph.
The random walks may be constrained by a path length, meaning that the walk may traverse up to a maximum number of edges.
Using the training data, the training engine may train a machine learning module to generate multiple weighted features for a particular relationship, or in other words to infer paths for a particular relationship.
A feature generated by the machine learning module is a walk-in-the-data graph alone or the combination of the data graph and text graph.
For instance, if entity A is related to entity B by edge t1, and B is related to entity C by edge t2, then A is related to C by the feature {t1, t2}.
The feature weight may represent confidence that the path represents a true fact.
Das Patent zeigt uns ein positives Trainingsbeispiel, das dem Machine-Learning-Algorithmus beibringt, den Beruf einer Personenentität anhand der Berufe anderer Personen, die in Verbindung mit der angefragten Person erwähnt werden, abzuleiten.
Das Patent sagt uns, dass ein solches Feature als {Mention, conj, Mention -1, Profession} erscheinen kann, wobei die Mentions die erwähnte Kante darstellen, die den Datengraphen mit dem Textgraphen verbindet, conj eine Kante im Textgraphen ist, Mention -1 die erwähnte Kante darstellt, die den Textgraphen mit dem Datengraphen verbindet, und Profession eine Kante im Datengraphen ist, die eine Entität für eine Person mit einer Entität verbindet, die einen Beruf darstellt.
If a person entity in the data graph is linked to a profession entity in the data graph by this path, or feature, the knowledge discovery engine can infer that the data graph should include a profession edge between the two entities.
The feature may have a weight that helps the knowledge discovery engine decide whether or not the edge should exist in the data graph.
Wir erfahren auch von Beispielen, bei denen das Modul darauf trainiert wird, die Abfragen für „Ehepartner“, „Ehefrau“, „Ehemann“, „Lebensgefährte“ und „verheiratet mit“ auf der Grundlage der Trainingsdaten auf verschiedene Pfade im Datengraphen abgebildet werden.
Diese Abfragen können geclustert sein, so dass das maschinelle Lernmodul für ein Cluster von Abfragen trainiert werden kann.
Und die Abfragen können sich auf ein Cluster von Abfragen mit ähnlichen Bedeutungen beziehen.
Das Patent liefert viele Beispiele dafür, wie ein Datengraph über mehrere Entitäten anhand von Beispielen wie den oben genannten angelernt werden kann. Ein solches Training kann dann verwendet werden, um Abfragen aus dem Datengraphen zu beantworten. Das Patent beschreibt, dass es Informationen aus anderen Quellen als dem Internet, wie z. B. einem dokumentenbasierten Index, verwenden kann und die Ergebnisse aus dem Datengraphen mit den Ergebnissen aus dem dokumentenbasierten Index kombinieren kann.
Dieses Patent hat auch einen großen Abschnitt darüber, wie Google einen Datengraphen erweitern kann. Der Prozess klingt sehr ähnlich wie der, den ich beschrieben habe, als ich über die Entitäten-Extraktion geschrieben habe (verlinkter Beitrag s.o.).
Das Patent hat auch einen Abschnitt über die Verknüpfung von abgeleiteten Tupeln mit Konfidenzwerten unter Verwendung des Moduls für maschinelles Lernen. Es wird auch beschrieben, wie der Konfidenzwert für die abgeleiteten Tupel gegen einen Schwellenwert geprüft wird.
Warum ist die beschriebene Methodik so interessant?
In diesem Patent wird beschrieben, wie ein Datengraph erstellt werden könnte, um Entitäten und mit diesen assoziierte Tupel zu identifizieren und einen Datengraph zu erstellen, der Konfidenzwerte zwischen diesen Entitäten und mit ihnen verbundenen Fakten versteht. Zudem ähnliche Entitäten mit ähnlichen Attributen versteht. Dadurch lassen sich Abfragen zu viel Entitäten über den Datengraphen beantworten. Ein Vorteil dieses Ansatzes wäre, dass man durch das Crawling des Webs Informationen über Entitäten und Fakten sammeln kann. II diesem Beitrag wollte ich klar machen, wie Google es aus dem Web lernen und Wissen aufbauen kann.
Ich vermute, dass wir auf viele weitere Patente stoßen werden, die ähnliche Ansätze beschreiben, die eine Suchmaschine verwenden könnte, um die Welt besser zu verstehen.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.