
Dies ist ein übersetzter Beitrag von Bill Slawski. Das Original befindet sich hier .
Inhaltsverzeichnis
- 1 Klassifizierung von Websites nach E-A-T
- 2 Suchanfragen verlangen Ergebnisse aus ausgewiesenen Wissens-Quellen
- 3 Vorteile bei der Nutzung von Vektorraumanalysen
- 4 Wie Daten aus dem Klassifikations-System verwendet werden können
- 5 Wie Website-Klassifikationen generiert werden?
- 6 Bei der Website-Klassifizierung verwendete Labels
- 7 Takeaways aus dem Patent
Klassifizierung von Websites nach E-A-T
Google schreibt in einem Patent, dass es möglicherweise Vektorraumanalysenverwendet, um Websites anhand von Merkmalen zu klassifizieren, die auf diesen Websites gefunden wurden.
In diesem Beitrag geht es um eine neue Google-Patentanmeldung, die im August 2018 eingereicht und Anfang 2020 Woche bei der Weltorganisation für geistiges Eigentum (WIPO) veröffentlicht wurde.
Die Patentanmeldung verwendet Neuronale Netzwerke, um Muster und Merkmale hinter Websites zu verstehen und diese Websites zu klassifizieren.
Dieses Website-Klassifizierungssystem bezieht sich auf einen Vektor, für eine Website-Klassifizierung innerhalb einer bestimmten Wissensdomäne.
Bei diesen Wissensdomänen kann es sich um Themen wie Gesundheit, Finanzen und andere handeln. Sites, die in bestimmten Wissensdomänen klassifiziert sind, können einen Vorteil beim Ranking haben.
Diese Website-Klassifikationen können vielfältiger sein als die Kategorien von Websites innerhalb von Wissensdomänen. Das Patent bricht Kategorien viel weiter auf:
For instance, the website classifications may include the first category of websites authored by experts in the knowledge domain, e.g., doctors, the second category of websites authored by apprentices in the knowledge domain, e.g., medical students, and a third category of websites authored by laypersons in the knowledge domain.
Ich erinnere mich an Diskussionen in der SEO-Branche über die Google-Quality-Rater-Guidelines und die darin enthaltenen Verweise auf E-A-T oder Expertise, Autorität und Vertrauenswürdigkeit. Die QRG verweisen auf Gesundheitswebsites mit verschiedenen Stufen von E-A-T , ähnlich wie die Klassifizierungen aus dieser neuen Google-Patentanmeldung über Website-Darstellungsvektoren:
Medizinische Ratschläge mit hohem E-A-T sollten von Personen oder Organisationen geschrieben oder erstellt werden, die über entsprechende medizinische Expertise verfügen. Medizinische Ratschläge oder Informationen mit hohem E-A-T sollten in einem
professionellen Stil geschrieben und sollten regelmäßig redigiert, überprüft und aktualisiert werden.
Aus den Richtlinien geht hervor, dass es Sites gibt, die von Personen mit weniger Fachwissen zu Themen erstellt wurden:
It’s even possible to have everyday expertise in YMYL topics. For example, there are forums and support pages for people with specific diseases. Sharing personal experience is a form of everyday expertise. Consider this example.
Here, forum participants are telling how long their loved ones lived with liver cancer. This is an example of sharing
personal experiences (in which they are experts), not medical advice. Specific medical information and advice (rather
than descriptions of life experiences) should come from doctors or other health professionals.
Die Klassifikationen umfassen eine Experten-Level, ein Lehrlings-Level und ein Laien-Level.
Diese Klassifikationen basieren auf unterschiedlichen Experten-Leveln und im Patent steht, dass es auch Seiten auf der Grundlage von Autorität einordnet, sagt aber nichts über die Vertrauenswürdigkeit aus, so dass es keine vollständige Einstufung von Websites auf der Grundlage von E-A-T berücksichtigt. Dieses Verfahren erfasst zwei Aspekte von E-A-T, so dass es einen Teil des Ziels der Richtlinien für Qualitätsbewertungen erfüllen kann, indem es menschlichen Bewertern erlaubt, Seiten zu bewerten, die ein gutes Ranking haben und ein hohes Maß an Autorität und Fachwissen aufweisen.
Wenn dieser Prozess auch die Anzahl der Websites einschränkt, von denen Google Suchergebnisse zurückgeben muss, je nachdem, in welcher Wissensdomäne sie sich befinden, bedeutet dies, dass Google weniger Websites durchsucht, um Ergebnisse zurückzugeben, als der gesamte Web-Index von Google zur Verfügung hat. Schauen wir uns den Prozess hinter dieser Patentanmeldung etwas genauer an.
Der Prozess teilt Websites in bestimmte Wissensdomänen ein und versucht, verschiedene Arten von Websites innerhalb dieser bestimmten Wissensdomänen zu finden:
- Empfang von Darstellungs-Vektoren von Websites und Qualitätsbewertungen, die Qualitätsmessungen von Websites im Vergleich zu anderen Websites darstellen.
- Einstufung von ersten Websites, wobei jede Website eine Qualitätsbewertung unter einem bestimmten Schwellenwert hat, wobei mindestens eine der der Websites eine Qualitätsbewertung unter diesem Schwellenwert hat
- Klassifizierung von zweiten Websites, wobei jede der Websites eine Qualitätsbewertung über einem bestimmten Schwellenwert hat, der höher ist als der erste Schwellenwert, wobei mindestens eine der Websites eine Qualitätsbewertung über dem ersten Schwellenwert hat
- Generierung einer ersten zusammengefassten Muster-Darstellung der als erste Websites klassifizierten Websites
- Erstellen einer zweiten zusammengefassten Muster-Darstellung aus der Gruppe der zweiten klassifizierten Websites
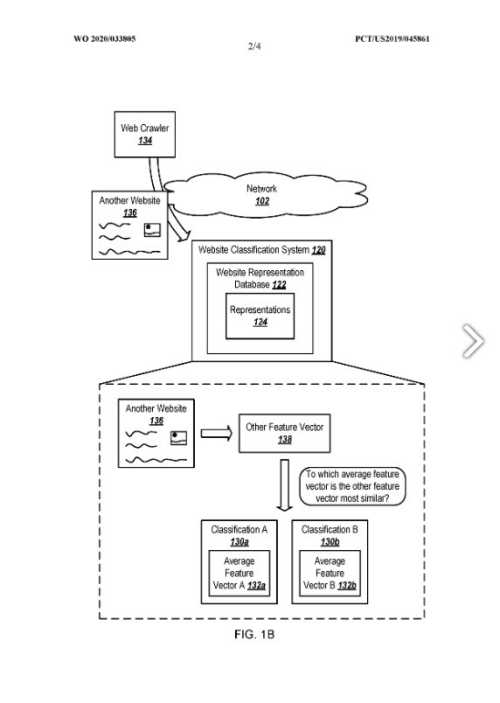
- Empfang einer anderen Website
- Bestimmen eines ersten Maßes für die Differenz zwischen der ersten zusammengefassten Muster-Darstellung und der Darstellung der einzelnen anderen Website
- Bestimmen des zweiten Maßes für die Differenz zwischen der zweiten zusammengefassten Muster-Darstellung und der Darstellung der einzelnen anderen Website
- Klassifizierung der anderen Website auf der Grundlage des ersten Differenz-Messgröße und des zweiten Differenz-Messgröße oder in eine Klasse, die weder zum ersten noch zur zweiten Differenz-Messgröße passt.
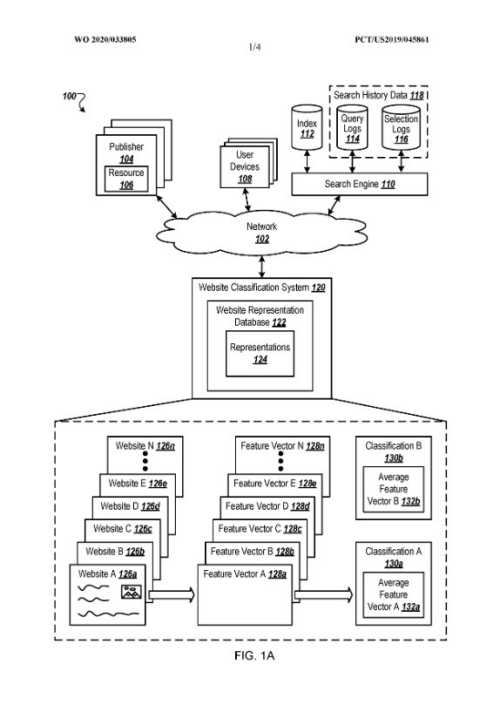
Suchanfragen verlangen Ergebnisse aus ausgewiesenen Wissens-Quellen
Aus der Patentanmeldung geht hervor, dass zu dem Verfahren die Verwendung von Begriffen aus der Suchanfrage gehört, um zu verstehen, dass die Suchanfrage Daten aus einer bestimmten Wissensdomäne erfordert.
Die Suchanfrage kann nach Antworten aus dieser bestimmten Wissensdomäne suchen. Das Verfahren beinhaltet:
- Generierung von vorverarbeiteten Antworten für zukünftige Suchanfgragen aus den Autoritäts-Quellen
- Empfang einer Suchanfrage, die für die bestimmte Wissensdomäne bestimmt ist
- Beantworten der Suchanfrage mit einer der vorverarbeiteten Antworten
Vorteile bei der Nutzung von Vektorraumanalysen
Die Suchmaschine kann Daten nur für Websites mit einer bestimmten Klassifizierung auswählen, durchsuchen oder beides, wodurch die für das Auffinden von Suchergebnissen erforderlichen Rechenressourcen reduziert werden, z.B. indem keine Website ausgewählt oder durchsucht wird, die nicht der Klassifizierung entspricht oder beides. Dies kann:
- den für die Speicherung von Daten für potentielle Suchergebnisse erforderlichen Speicherplatz reduzieren, z.B. kann es sein, dass nur Daten für Websites mit einer bestimmten Klassifizierung gespeichert werden müssen
- Reduzierung der Websites, die vom Suchsystem analysiert werden müssen, z.B. indem Sie eine Suche auf Websites mit der bestimmten Klassifizierung beschränken
- Reduzieren der Bandbreite, die zur Bereitstellung von Suchergebnissen an ein anforderndes Gerät verwendet wird
- Bewältigung potenzieller Probleme mit früheren Systemen, wie z.B. höhere Nutzung von Bandbreite, Speicher, Prozessorzyklen, Leistung oder eine Kombination von zwei oder mehr dieser Faktoren
- Verbesserung der von einem Suchsystem generierten Suchergebnisseiten, indem in die generierten Suchergebnisseiten nur Websites mit einer bestimmten Klassifizierung, z.B. einer qualitativen Klassifizierung, aufgenommen werden
- Verwendung von Mustern bzw. Merkmalen, die von bestehenden Websites gelernt werden, um zuvor ungesehene Websites zu klassifizieren, ohne dass für die Klassifizierung manuelle Nutzer-Ratings oder Signale erforderlich sind
- Erkennen von Websites, die mit größerer Wahrscheinlichkeit zu Suchanfragen für eine Wissensdomäne passen, z.B. die mit größerer Wahrscheinlichkeit für die Wissensdomäne Autoritäten sind, durch Klassifizieren von zuvor ungesehenen Websites
- Verwendung von zusammengefassten-Darstellungen, die auf bestehenden Website-Klassifikationen basieren, was bedeutet, dass die von der Klassifikation verwendeten Merkmale nicht durch menschlich wahrnehmbare Merkmale begrenzt sind unddas durch die Analyse der Website algorithmisch erlernt werden kann.
Man beachte, dass es sagt, dass es dabei hilft, Sites zu identifizieren, die für verschiedene Wissensbereiche maßgebend sind.
Diese Website-Repräsentations-Vektor-Patentanmeldung finden Sie unter
Website Representation Vector to Generate Search Results and Classify Website
Nummer der Veröffentlichung: WO2020033805
Antragsteller: GOOGLE LLC
Erfinder: Jewgenij Tsykynowskij
Veröffentlichungsnummer WO/2020/033805
Eingereicht: 10. August 2018
Veröffentlichungsdatum 13. Februar 2020
Abstrakt:
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for using website representations to generate, store, or both, search results. One of the methods includes receiving data representing each website in the first plurality of websites associated with a first knowledge domain of a plurality of knowledge domains and having a first classification; receiving data representing each website in the second plurality of websites associated with the first knowledge domain and having a second classification; generating a first composite-representation of the first plurality of websites; generating a second composite-representation of the second plurality of websites; receiving a representation of a third website; determining a first difference measure between the first composite-representation and the representation; determining a second difference measure between the second composite-representation and the representation; and based on the first difference measure and the second difference measure, classifying the third website.
Wie Daten aus dem Klassifikations-System verwendet werden können
Die Suchmaschine kann Daten aus diesem Klassifikationssystem der Website-Darstellungsvektoren verwenden, um Suchergebnisse zurückzugeben.
Dieses Klassifizierungssystem kann Darstellungen für jede der vielen Websites A-N verwenden und die Darstellungen dazu verwenden, eine Klassifizierung für jede der vielen Websites A-N zu bestimmen.
Die Suchmaschine beschließt, die Klassifizierung für eine Suchanfrage zu verwenden, um eine Kategorie von Websites mit der gleichen oder einer ähnlichen Klassifizierung auszuwählen.
Sie kann Suchergebnisse aus dieser Kategorie von Websites zurückgeben.
Die Klassifizierungen dieser Websites basieren auf den Muster-Merkmalen, die die Websites enthalten.
Wie Website-Klassifikationen generiert werden?
Dies war der Teil der Beschreibung des Patents, der mich am meisten interessiert hat.
Der Teil beginnt damit, dass dieses Klassifizierungssystem der Website-Darstellungsvektoren jede geeignete Methode zur Erzeugung von Klassifizierungen verwenden könnte, was Google eine große Flexibilität bietet.
Aber dann geht sie noch weiter ins Detail, indem sie uns sagt, dass die Klassifizierung auf dem Inhalt von Websites basieren kann, um Darstellungen dieser Websites zu generieren.
Dieser Inhalt kann beinhalten:
- Text von der Website
- Bilder auf der Website
- Andere Website-Inhalte, z.B. Links
- Oder eine Kombination aus zwei oder mehreren dieser Elemente
Das Patent liefert dann Einzelheiten darüber, wie ein neuronales Netzwerk eingebunden wird:
The website classification system may use a mapping that maps the website content for the website A to a vector space that identifies a representation for website A.
For instance, the website classification system may use a neural network, that represents the mapping, to create a feature vector A that represents the website A using the content of the website A as input to the neural network.
Bei der Website-Klassifizierung verwendete Labels
Die Website-Klassifizierung kann auf der Verwendung von Labels basieren. Die Labels:
- können alphanumerische, numerische oder alphabetische Zeichen, Symbole oder eine Kombination von zwei oder mehr davon sein
- Kann eine Art von Unternehmen angeben, das die entsprechende Website veröffentlicht hat, z.B. ein gemeinnütziges oder gewinnorientiertes Unternehmen
- weist auf eine Branche hin, die auf der Website beschrieben wird, z.B. über künstliche Intelligenz oder Bildung.
- Kann eine Art von Person angeben, die einen Inhalt verfasst hat, z.B. ein Arzt, ein Medizinstudent oder ein Laie
- Könnten auch Bewertungen sein, die eine Website-Klassifizierung darstellen
Die Scores für Klassifikationen könnten verwendet werden:
- Zur Erfüllung verschiedener Schwellenwerte zur Erfüllung von Kategorien
- Kann spezifisch für einen bestimmten Wissensbereich sein
- Kann Websites klassifizieren, die mehr als eine Wissensdomäne abdecken
- kann Websites auswählen, die auf mehrere Suchanfragen für bestimmte Wissensbereiche eine Antwort bereitstellen
- mit der Autorität der jeweiligen Website für die jeweilige Wissensdomäne versehen
- oder beides
Eingabedaten, die zur Klassifizierung von Websites verwendet werden, können z.B. folgende Dinge betreffen:
- Eine Position bestimmter Wörter zueinander, z.B. dass das Wort „künstlich“ im Allgemeinen in der Nähe oder in der Nähe des Wortes „Intelligenz“ liegt.
- Bestimmte in der Website enthaltene Phrasen
- Für jede der Klassifikationen A-B ein Maß für den Unterschied oder ein Ähnlichkeitsmaß, das eine Ähnlichkeit zwischen der jeweiligen Klassifikation und der anderen Website darstellt
- Die Klassifikation A-B, die am ähnlichsten ist
- Die Klassifikation A-B mit dem höchsten Ähnlichkeitsmaß oder mit dem kürzesten Abstand zwischen dem anderen Merkmalsvektor und dem jeweiligen mittleren Merkmalsvektor A-B, um einige Beispiele zu nennen
- Ein Verhältnis zwischen zwei Ähnlichkeitsmaßen zur Auswahl einer Klassifikation für die andere Website
Das Patent bietet mehrere andere Möglichkeiten, wie Eingabedaten während des Klassifizierungsprozesses betrachtet werden können
Qualitätsbewertungen, die für eine Klassifizierung einer Website genutzt werden können folgende Messgrößen sein:
- Autorität
- Responsivität für einen bestimmten Wissensbereich
- Eine weitere Eigenschaft der Website
- Oder eine Kombination aus zwei oder mehreren dieser Elemente
Takeaways aus dem Patent
- Websites können auf der Grundlage von Text, Bildern und Links klassifiziert werden
- Qualitätsbewertungen von klassifizierten Sites können die Autorität oder die Relevanz einer Site für eine bestimmte Wissensdomäne oder beides angeben.
- Labels, die zur Klassifizierung von Sites verwendet werden, könnten Informationen über das Unternehmen hinter einer Site, die in der Site beschriebene Branche und die Art der Person, die einen Inhalt verfasst hat, enthalten.
- Eine Website kann klassifiziert werden, mehr als einen Wissensbereich abzudecken
Wenn Du mehr zu E-A-T wissen willst und wie du die Signale optimierst, die zu einer besseren E-A-T-Einstufung führen empfehle ich Dir den Beitrag E-A-T-Optimierung: Wie optimiert man E-A-T bei Google?

- Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index - 6. April 2021
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise - 15. Dezember 2020
- Personalisierte Knowledge Graphen: Dahin kann die Reise gehen! - 24. November 2020
- Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann - 2. November 2020
- Wie Google Ergebnisse für ein Featured Snippet auswählen kann - 29. September 2020

























Kommentare sind geschlossen.