
Ein diese Woche veröffentlichtes Update zu einem Patent verrät uns, wie Google die Ergebnisse für ein Snippet bewerten kann.
Wenn eine Suchmaschine eine Rangfolge von Suchergebnissen als Antwort auf eine Suchanfrage erstellt, kann sie eine Kombination aus anfrageabhängigen und anfrageunabhängigen Rankingsignalen verwenden, um diese Rankings zu ermitteln.
Ein von einer Suchanfrage abhängiges Signal kann von einem Begriff in einer Suchanfrage abhängen und davon, wie relevant ein Suchergebnis für diesen Suchbegriff sein kann. Ein von einer Abfrage unabhängiges Signal würde von etwas anderem als den Begriffen in einer Abfrage abhängen, z. B. von der Qualität und Quantität der Links, die auf ein Ergebnis verweisen.
Antworten auf Fragen in Suchanfragen können auf der Grundlage einer Kombination aus suchanfrageabhängigen und suchanfrageunabhängigen Signalen in eine Rangfolge gebracht werden, die die Bewertung eines bestimmten Snippet-Antwort-Scores bestimmen könnte. Ein aktualisiertes Patent über textuelle Antwortpassagen gibt Aufschluss darüber, wie diese kombiniert werden können, um aus den Antworten auf Fragen, die in Suchanfragen erscheinen, Feature-Snippet-Antwort-Scores zur Auswahl zu generieren.
Vor eineinhalb Jahren schrieb ich über Antworten auf Featured Snippets in dem Beitrag Does Google Use Schema to Write Answer Passages for Featured Snippets? Das Patent, um das es in dem Beitrag ging, war das Patent Candidate answer passages, das ursprünglich am 12. August 2015 angemeldet und am 15. Januar 2019 als Fortsetzungspatent bestätigt wurde.
Bei diesem Patent handelte es sich um ein Fortsetzungspatent zu einem ursprünglichen Patent über Antwortpassagen, indem es darum geht, dass Google nach Textantworten auf Fragen suchen würde, die in der Nähe strukturierte Daten mit verwandten Fakten befinden. Dies könnte so etwas wie eine Datentabelle oder möglicherweise sogar ein Schema-Markup sein. Dies bedeutete, dass Google eine textbasierte Antwort auf eine Frage liefern und viele verwandte Fakten für diese Antwort einbeziehen könnte.
Eine weitere Fortsetzungsversion der ersten Version des Patents wurde erst vor kurzem veröffentlicht. Sie bietet mehr Informationen und einen anderen Ansatz für die Einstufung von Antworten für vorgestellte Ausschnitte, und es lohnt sich, die Kriterien in diesen beiden Versionen des Patents zu vergleichen.
Die neue Version des Patents findet man hier:
Scoring candidate answer passages
Erfinder: Steven D. Baker, Srinivasan Venkatachary, Robert Andrew Brennan, Per Bjornsson, Yi Liu, Hadar Shemtov, Massimiliano Ciaramita und Ioannis Tsochantaridis
Bevollmächtigter: Google LLC
US-Patent: 10,783,156
Gewährt: 22. September 2020
Eingereicht: 22. Februar 2018
Kurzfassung:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for scoring candidate answer passages. In one aspect, a method includes receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query; for a subset of the resources: receiving candidate answer passages; determining, for each candidate answer passage, a query term match score that is a measure of similarity of the query terms to the candidate answer passage; determining, for each candidate answer passage, an answer term match score that is a measure of similarity of answer terms to the candidate answer passage; determining, for each candidate answer passage, a query dependent score based on the query term match score and the answer term match score; and generating an answer score that is a based on the query dependent score.
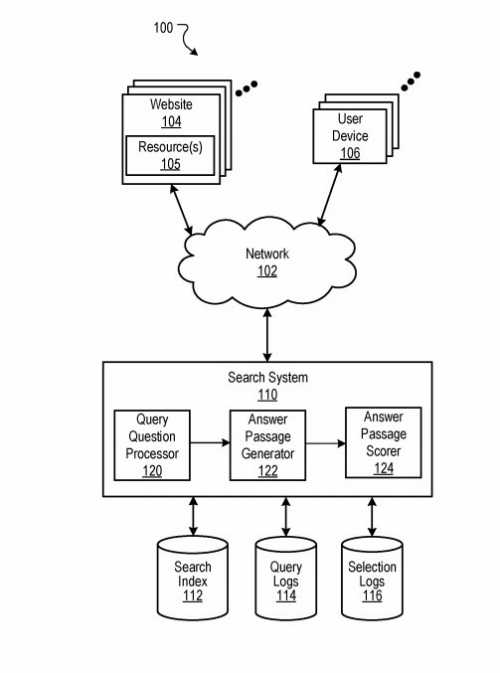
Inhaltsverzeichnis
- 1 Die aktualisierten Kriterien für Kandidat-Antwort-Passagen
- 2 Suchanfragenabhängige und Suchanfragenunabhängige Bewertungen für Featured Snippets
- 3 Suchanfragenabhängige Bewertung für die Bewertung der Featured Snippet Snippet Kandidaten
- 4 Bewertung von Antwortpassagen nach abfrageunabhängigen Merkmalen
Die aktualisierten Kriterien für Kandidat-Antwort-Passagen
Es gibt Änderungen am Patent, die eine genauere Analyse der potenziellen Antworten erfordern, die sowohl auf abfrageabhängigen als auch abfrageunabhängigen Bewertungen für potenzielle Antworten auf Fragen basieren. Die Patentbeschreibung enthält Einzelheiten über abfrageabhängige und abfrageunabhängige Scores. Die Kriterien aus dem ersten Patent decken die von der Suchanfrage abhängigen Punktzahlen für Antworten ab, nicht aber die von der Abfrage unabhängigen Punktzahlen wie in der neuesten Version.
Sie enthält mehr Details sowohl über die von der Abfrage abhängigen als auch über die von der Abfrage unabhängigen Ergebnisse in den Kriterien, aber die neuere Version scheint sowohl die von der Abfrage abhängigen als auch die von der Abfrage unabhängigen Ergebnisse wichtiger zu machen.
Das geht aus der 2015-Version des Patents Scoring Answer Passages hervor:
1. A method performed by data processing apparatus, the method comprising: receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query and ordered according to a ranking, the query having query terms; for each resource in a top-ranked subset of the resources: receiving candidate answer passages, each candidate answer passage selected from passage units from content of the resource and being eligible to be provided as an answer passage with search results that identify the resources determined to be responsive to the query and being separate and distinct from the search results; determining, for each candidate answer passage, a query term match score that is a measure of similarity of the query terms to the candidate answer passage; determining, for each candidate answer passage, an answer term match score that is a measure of similarity of answer terms to the candidate answer passage; determining, for each candidate answer passage, a query dependent score based on the query term match score and the answer term match score; and generating an answer score that is a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score.
Der Rest der Ausführungen gibt Auskunft sowohl über die von der Abfrage abhängigen als auch über die abfrageunabhängigen Antwortwerte, aber die Ansprüche aus der neueren Version des Patents scheinen den von der Abfrage abhängigen und den abfrageunabhängigen Antwortwerten die gleiche Bedeutung beizumessen. Das hat mich davon überzeugt, dass ich dieses Patent in einem Beitrag erneut prüfen und beschreiben sollte, wie Google die Antwortpunktzahlen auf der Grundlage der von der Suchanfrage abhängigen und der von der Suchanfrage unabhängigen Punktzahlen berechnen kann.
Die Ausführungen in dem neuen Patent verraten es uns:
1. A method performed by data processing apparatus, the method comprising: receiving a query determined to be a question query that seeks an answer response and data identifying resources determined to be responsive to the query and ordered according to a ranking, the query having query terms; for each resource in a top-ranked subset of the resources: receiving candidate answer passages, each candidate answer passage selected from passage units from content of the resource and being eligible to be provided as an answer passage with search results that identify the resources determined to be responsive to the query and being separate and distinct from the search results; determining, for each candidate answer passage, a query dependent score that is proportional to a number of instances of matches of query terms to terms of the candidate answer passage; determining, for each candidate answer passage, a query independent score for the candidate answer passage, wherein the query independent score is independent of the query and query dependent score and based on features of the candidate answer passage; and generating an answer score that is a measure of answer quality for the answer response for the candidate answer passage based on the query dependent score and the query independent score.
Wie es in diesem neuen Ausführungen heißt, ist die Antwortpunktzahl von „einem Maß für die Qualität der Antwort für die Kandidatenantwortpassage auf der Grundlage der von der Anfrage abhängigen Punktzahl“ (aus dem ersten Patent) zu „einem Maß für die Qualität der Antwort auf der Grundlage der von der Anfrage abhängigen Punktzahl und der von der Anfrage unabhängigen Punktzahl“ (aus dieser neueren Version des Patents) übergegangen.
Diese Zeichnung stammt aus beiden Versionen des Patents, aber sie zeigt die Suchanfragenabhängige und die Suchanfragenunabhängige Punktzahl, die beide eine wichtige Rolle bei der Berechnung der Feature-Snippet-Antwort-Punktzahlen spielen:
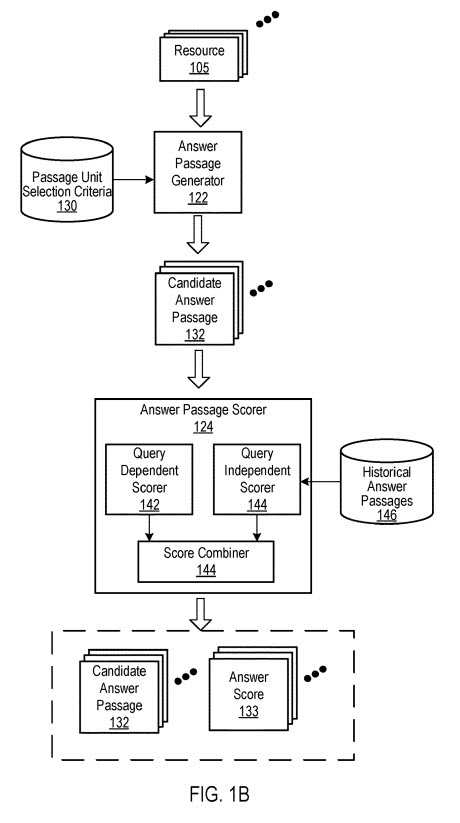
Suchanfragenabhängige und Suchanfragenunabhängige Bewertungen für Featured Snippets
Beide Versionen des Patents sagen uns, wie ein von der Suchanfrage abhängiger Score und ein von der Suchanfrage unabhängiger Score für eine Antwort berechnet werden könnten. In der ersten Version des Patents hieß es in den Ausführungen nur, dass ein Antwortpunktwert den von der Suchanfrage abhängigen Punktwert verwendet, und diese neuere Version sagt uns, dass sowohl der von der Anfrage abhängige als auch der von der Anfrage unabhängige Punktwert kombiniert werden, um einen Antwortpunktwert zu berechnen (um zu entscheiden, welche Antwort die beste Wahl efür ein Featured Snippet ist).
Bevor im Patent erörtert wird, wie Suchanfragenabhängige und Suchanfragenunabhängige Signale verwendet werden können, um einen Antwort-Score zu erstellen, erfahren wir in dem Patent dies über den Antwort-Score:
The answer passage scorer receives candidate answer passages from the answer passage generator and scores each passage by combining scoring signals that predict how likely the passage is to answer the question.
In some implementations, the answer passage scorer includes a query dependent scorer and a query independent scorer that respectively generate a query dependent score and a query independent score. In some implementations, the query dependent scorer generates the query dependent score based on an answer term match score and a query term match score.
Suchanfragenabhängige Bewertung für die Bewertung der Featured Snippet Snippet Kandidaten
Suchanfragenabhängige Bewertungen basieren auf den Term-Eigenschaften einer Textpassage.
Die antwortabhängigen Fragestellungen in Suchen beschreiben nicht, wonach ein Suchender sucht, da die Antwort dem Suchenden zum Zeitpunkt der Suche unbekannt ist.
Der Suchanfrageabhängige Bewertungs-Prozess beginnt mit der Suche nach einer Zusammenstellung wahrscheinlicher Antwortbegriffe und vergleicht diese Zusammenstellung mit einer Antwortpassage des möglichen Featured-Snippet-Kandidaten, um einen Trefferwert für den Antwortbegriff zu generieren. Die Zusammenstellung wahrscheinlicher Terme wird wahrscheinlich aus den Ergebnissen der ersten N Rangfolge entnommen, die für eine Suchanfrage zurückgegeben werden.
Der Prozess erstellt eine Liste von Termen aus Begriffen, die in der bestplatzierten Teilmenge der Ergebnisse für eine Abfrage enthalten sind. Das Patent sagt uns, dass jedes Ergebnis geparst wird und jeder Begriff in einem Begriffsvektor enthalten ist (siehe dazu den Glossar-Beitrag zu Vektorraumanalysen). Stoppwörter können aus dem Termvektor weggelassen werden.
Für jeden Begriff in der Liste kann eine Termgewichtung für den Begriff generiert werden. Das Term-Gewicht für jeden Term kann auf vielen Ergebnissen in der ranghöchsten Teilmenge der Ergebnisse basieren, in der der Term vorkommt, multipliziert mit einem IDF-Wert (Inverse Document Frequency) für den Term. Der IDF-Wert kann aus einem großen Korpus von Dokumenten abgeleitet und dem abfrageabhängigen Bewerter zur Verfügung gestellt werden. Oder der IDF-Wert kann aus den ersten N Dokumenten in den zurückgegebenen Ergebnissen abgeleitet werden. (mehr zu TF-IDF-Analysen beim Kollegen Kai Spriestersbach). Das Patent sagt uns, dass auch andere geeignete Term-Gewichtungstechniken verwendet werden können.
Der Bewertungsprozess für jeden Term der Kandidatenantwortpassage bestimmt, wie oft der Term in der Textpassage eines möflichen Featured-Snippet-Kandidaten vorkommt. Wenn also der Begriff „Apogäum“ zweimal in einer Textpassage des Kandidaten vorkommt, ist der Begriffswert für „Apogäum“ für diese Antwortpassage des Kandidaten 2; wenn derselbe Begriff jedoch dreimal in einer anderen Antwortpassage des Kandidaten vorkommt, ist der Begriffswert für „Apogäum“ für die andere Antwortpassage des Kandidaten 3.
Der Bewertungsprozess multipliziert für jeden Term der Kandidaten-Antwortpassage dessen Term-Gewichtung mit der Anzahl, wie oft der Term in der Antwortpassage vorkommt. Nehmen Sie also an, das Term-Gewicht für „Apogäum“ beträgt 0,04. Für die erste Antwortpassage des Kandidaten beträgt der auf dem „Apogäum“ basierende Wert 0,08 (0,08.mal.2); für die zweite Antwortpassage des Kandidaten beträgt der auf dem „Apogäum“ basierende Wert 0,12 (0,04.mal.3).
Es können auch andere Merkmale verwendet werden, um einen Bewertungs-Score zu bestimmen. Beispielsweise kann der abfrageabhängige Bewertungs-Prozess einen Entitätstyp für eine Antwort auf die Suchanfrage bestimmen. Der Entitätstyp kann durch die Identifizierung von Begriffen bestimmt werden, wie z. B. Personen, Orte oder Dinge und durch die Auswahl der Terme mit der höchsten Bewertung. Die Entität kann auch aus der Suchanfrage ermittelt werden (z. B. für die Suchanfrage „wer ist der schnellste Mann“, der Entitätstyp für eine Antwort ist „Mann“. Für jeden Antwortkandidaten identifiziert der Bewertungs-Prozess dann Entitäten, die im möglichen Kandidaten beschrieben sind. Wenn die Entitäten keine Übereinstimmung mit dem identifizierten Entitätstyp enthalten, wird der Bewertungs-Score für die Kandidaten-Antwortpassage reduziert.(Mehr zum Thema Entitätstypen im Beitrag Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest).
Angenommen, die folgende Kandidat-Antwortpassage wird zur Bewertung als Antwort auf die Frage [wer ist der schnellste Mann] bereitgestellt: Olympische Sprinter haben während der Olympischen Spiele oft Weltrekorde für Sprintwettkämpfe aufgestellt. Die beliebteste Sprintveranstaltung ist der 100-Meter-Sprint.
Der von der Abfrage abhängige Punkteverwalter wird mehrere Entitäten identifizieren – Olympische Spiele, Sprinter usw. – aber keine von ihnen ist vom Typ „Mann“. Der Begriff „Sprinter“ ist geschlechtsneutral. Dementsprechend wird der Antwortbegriff Score reduziert. Die Punktzahl kann eine binäre Punktzahl sein, z.B. 1 für das Vorhandensein des Begriffs des Entitätstyps und 0 für das Fehlen des Begriffs des richtigen Typs; alternativ kann es sich auch um ein Maß für die Wahrscheinlichkeit handeln, dass der richtige Begriff in der Passage des Antwortkandidaten vorkommt.
Bewertung von Antwortpassagen nach abfrageunabhängigen Merkmalen
Kandidaten-Antwortpassagen können aus den N bestplatzierten Ressourcen generiert werden, die für eine Suche als Antwort auf eine Anfrage identifiziert wurden. N kann die gleiche Zahl sein wie die Anzahl der Suchergebnisse, die auf der ersten Seite der SERPs zurückgegeben werden (z.B. 10)
Der Bewertungsprozess kann eine Positionsbewertung der Textpassage verwenden. Die Bewertung könnte die Position eines Ergebnisses sein, aus dem eine Passage einer Kandidatenantwort stammt. Je höher die Position ist, desto höher ist die Punktzahl.
Der Bewertungsprozess kann eine Punktzahl aus dem Natural Language Processing verwenden. Die NLP-Punktzahl wird auf der Grundlage der Antwortpassagen des Kandidaten generiert.
Das kann auf Satz- und Grammatikstrukturen basieren. Dies könnte bedeuten, dass Kandidaten-Antwortpassagen mit Teilsätzen möglicherweise eine niedrigere Punktzahl erhalten als Kandidaten-Antwortpassagen mit vollständigen Sätzen. Das Patent sagt uns auch, dass, wenn strukturierter Inhalt in der Antwortpassage des Kandidaten enthalten ist, der strukturierte Inhalt nicht der Bewertung durch Natural Language Processing unterliegt. Zum Beispiel kann eine Zeile aus einer Tabelle eine sehr niedrige Bewertung gemäß NLP haben, kann aber sehr informativ sein. (mehr dazu im Beitrag Data Mining für den Knowledge Graph und Suchmaschinen über Natural Language Processing oder dem Glossar-Beitrag zu Natural Language Processing).
Ein anderer Bewertung-Prozess, der verwendet werden kann, berücksichtigt, ob der Text aus einer Antwortpassage des Kandidaten dem Antworttext im Allgemeinen ähnlich erscheint.
Ein abfrageunabhängiger Bewertungs-Prozess greift auf ein NLP-Modell mit vorherigen Antwortpassagen zu, wobei die historischen Antwortpassagen Antwortpassagen sind, die für alle Suchanfragen zugestellt wurden. Ausgelieferte Antwortpassagen haben im Allgemeinen eine ähnliche n-Gramm-Struktur, da Antwortpassagen dazu neigen, erklärende und deklarative Aussagen zu enthalten.
Eine Suchanfragenunabhängige Bewertung könnte ein Tri-Gram-Modell verwenden, um die Trigramme der Antwortpassage des Kandidaten mit den Trigrammen der historischen Antwortpassagen zu vergleichen. Eine qualitativ hochwertigere Antwortpassage des Kandidaten hat in der Regel mehr Trigramm-Übereinstimmungen mit den historischen Antwortpassagen als eine qualitativ schlechtere Antwortpassage des Kandidaten. (Mehr Infos zu Trigrammen und N-Grammen bei Wikipedia)
Ein weiterer Schritt umfasst eine Bewertung der Abschnittsgrenzen. Eine Antwortkandidatenpassage könnte bestraft werden, wenn sie Text enthält, der Formatierungsgrenzen überschreitet, wie z.B. Absätze und Abschnittsumbrüche.
Der Bewertungsprozess bestimmt eine Fragebewertung. Der abfrageunabhängige Bewertungs-Prozess durchsucht die Antwortkandidaten-Passage nach Fragewörtern. Eine potenzielle Antwortpassage, die eine Frage oder einen Fragebegriff enthält, z.B. „Wie weit ist der Mond von der Erde entfernt?„, ist für einen Suchenden, der nach einer Antwort sucht, im Allgemeinen nicht so hilfreich wie eine Kandidaten-Antwortpassage, die nur deklarative Aussagen enthält, z.B. „Der Mond ist etwa 238.900 Meilen von der Erde entfernt„.
Der Bewertungsprozess bestimmt auch die Punktzahl für die Position des Diskursgrenzbegriffs. Ein Diskursgrenzterm ist ein Begriff, der eine Aussage oder Idee einführt, die im Widerspruch zu einer gerade gemachten Aussage oder Idee steht oder diese modifiziert. Zum Beispiel „umgekehrt„, „jedoch„, „auf der anderen Seite“ und so weiter.
Eine Antwortpassage eines Kandidaten, die mit einem solchen Begriff beginnt, erhält eine relativ niedrige Punktzahl, was die Antwortpunktzahl senkt.
Eine Antwortpassage, die einen solchen Begriff enthält, aber nicht damit beginnt, erhält eine höhere Punktzahl, als wenn sie mit diesem Begriff beginnen würde.
Eine Antwortpassage, die einen solchen Begriff nicht enthält, erhält eine hohe Punktzahl.
Der Bewertungsprozess bestimmt die Ergebnisbewertungen für die Ergebnisse, aus denen die Antwortkandidatenpassage erstellt wurde. Diese könnten einen Ranking-Score, eine Reputations-Score und einen Score für die Website-Qualität (Anmerkung des Verfassers: z.B. basierend auf dem E-A-T Ansatz ) umfassen. Je höher diese Punktzahlen sind, desto höher wird die Bewertung bezüglich eines Featured Snippets sein.
Eine Ranking-Score basiert auf der Ranking-Position des Ergebnisses, aus dem die Antwortpassage des Kandidaten extrahiert wurde. Es kann die Bewertung des Ergebnisses für die Suchanfrage sein und wird auf alle Antwortpassagen der Kandidaten aus den ersten Ergebnissen aus den SERPs angewendet.
Ein Ranking-Score zeigt die Vertrauenswürdigkeit und/oder die Wahrscheinlichkeit an, dass das Thema der Ressource der Anfrage gut dient.
Eine Website-Qualitätsbewertung gibt ein Maß für die Qualität einer Website an, die das Ergebnis hostet, aus dem die Antwortpassage des Kandidaten extrahiert wurde.
Die oben beschriebenen, von den Komponenten der Abfrage unabhängigen Bewertungen können auf verschiedene Weise kombiniert werden, um die von der Suchanfrage unabhängige Bewertung zu ermitteln. Sie können summiert, miteinander multipliziert oder auf andere Weise kombiniert werden.
Dies ist eine Übersetzung des Orginal-Beitrags Featured Snippet Answer Scores Ranking Signals. Mit freundlicher Genehmigung von Bill Slawski.

- Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index - 6. April 2021
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise - 15. Dezember 2020
- Personalisierte Knowledge Graphen: Dahin kann die Reise gehen! - 24. November 2020
- Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann - 2. November 2020
- Wie Google Ergebnisse für ein Featured Snippet auswählen kann - 29. September 2020

























2 Kommentare
Sie helfen viel. Vielen Dank für den informativen Artikel!