Dies ist ein Beitrag von Bill Slawski übersetzt aus dem englischen Original-Beitrag Adjusting Featured Snippet Answers by Context
Inhaltsverzeichnis
- 1 Wie wird über Featured-Snippet-Antworten entschieden?
- 2 Wie Kontextbewertungen für Featured Snippets funktionieren
- 3 Vorteile des Verfahrens im Patent
- 4 Verwendung von Kontextbewertungen zum Anpassen der Antwortbewertungen für Featured Snippets
- 5 Identifizieren von Fragen in Suchanfragen und Antwortpassagen
- 6 Kontextuelle Bewertungsanpassungen für die Antworten der Featured Snippets
- 7 Kontextbezogene Bewertung der Featured Snippet Antworten
- 8 Eine Überschriftenhierarchie zur Bestimmung des Kontexts
- 9 Wo die Dinge unklar werden im Patent
- 10 Steigerung der Punktzahlen auf der Grundlage des Überdeckungsgrads
- 11 Bewertung auf der Grundlage anderer Merkmale
- 12 Das Vorhandensein einer Liste
- 13 Anpassung der Bewertung von Featured Snippets
- 14 Mehr dazu in Kürze
Wie wird über Featured-Snippet-Antworten entschieden?
Ich habe vor kurzem über die Bewertungssignale für Featured Snippet Answer Scores geschrieben. In diesem Beitrag beschrieb ich, wie Google wahrscheinlich Suchanfragenabhängige und Suchanfragenunabhängige Rankingsignale verwendet, um Featured-Snippet-Ergebnisse zu erstellen.
Einer der Erfinder dieses Patents aus diesem Beitrag war Steven Baker. Ich sah mir andere Patente an, die er geschrieben hat, und bemerkte, dass es bei einem davon um den Kontext als Teil von abfrageunabhängigen Rankingsignalen für Featured-Snippet-Antworten ging.
Als ich mich an dieses Patent erinnerte, in dem es um Frage, Antworten und Kontext ging, hielt ich es für sinnvoll, dieses Patent zu überprüfen und darüber zu schreiben.
In diesem Patent geht es um die Verarbeitung von Suchanfragen, die textliche Antworten wünschen, und darum, wie diese Antworten ausgewählt werden können.
Es ist ein kompliziertes Patent und an einer Stelle scheint die Beschreibung dahinter etwas unklar, aber ich beschreibe an welcher Stelle das der Fall ist. Ich denke, die anderen Details geben einen guten Einblick in die Bewertung der von Google angebotenen Featured Snippets. Es gibt ein weiteres ähnliches Patent, auf das ich von hier aus verlinken werde.
Das Patent sagt uns zunächst, dass eine Suchmaschine Quellen für eine Antwort auf Suchanfragen von Nutzern identifizieren und Informationen aus der Quelle in einer für die Nutzer nützlichen Weise bereitstellen kann.
Wie Kontextbewertungen für Featured Snippets funktionieren
Benutzer von Suchmaschinen suchen oft nach einer Antwort auf eine bestimmte Frage und nicht nach einer Auflistung von Eregbnissen, wie in dieser Zeichnung aus dem Patent, in der die Eregbnisse in Form von Boxen dargestellt sind:

Die Benutzer möchten zum Beispiel wissen, wie das Wetter an einem bestimmten Ort ist, den aktuellen Kurs einer Aktie, die Hauptstadt eines Staates usw.
Wenn Suchanfragen in Form einer Frage eingehen, können einige Suchmaschinen spezialisierte Ausgaben als Antwort auf die expliziten Fragen durchführen.
Zum Beispiel können einige Suchmaschinen Informationen als Antwort auf solche Suchanfragen in Form einer konkreten „Antwort“ liefern, wie z.B. Informationen in Form einer „One-Box“, die die Antwort direkt in den SERPs ausliefert.
Einige Suchanfragen werden besser durch erklärende Textpassagen bedient, die auch als „lange Antworten“ oder „Antwortpassagen“ bezeichnet werden.
Zum Beispiel ist für die Frage [warum ist der Himmel blau] eine Antwort, die die Bewegung des Lichts durch die Atmosphäre erklärt, hilfreich.
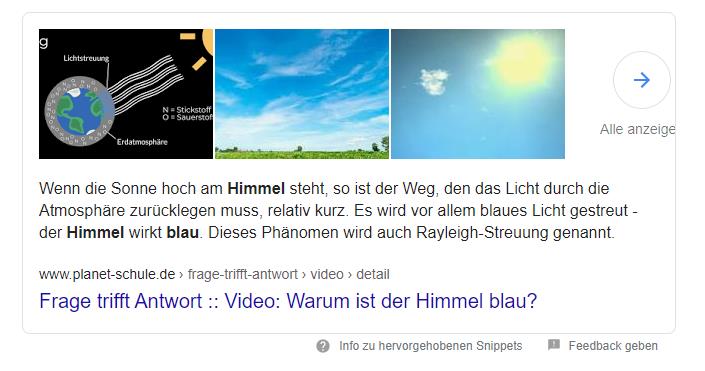
Solche Antwortpassagen können aus Quellen ausgewählt werden, die Text enthalten, wie z.B. Absätze, die in Bezug auf Suchanfrage und die Antwort relevant sind.
Abschnitte des Textes werden bewertet, und der Abschnitt mit der besten Bewertung wird als Antwort ausgewählt.
Im Allgemeinen gibt das Patent einen Aspekt dessen wieder, was es im folgenden Prozess abdeckt:
- Erhalt eine Suchanfrage, die eine explizite Frage ist, die eine direkte Antwort bedarf
- Erhalt von Antwortpassagen von ausgewählten Quellen, wobei jede Passage aus Text besteht, der aus einem Textabschnitt ausgewählt wurde, der einer Überschrift auf einer Quelle untergeordnet ist, mit einer entsprechenden Bewertungspunktzahl.
- Bestimmen einer Hierarchie von Überschriften auf einer Seite, mit zwei oder mehr Überschriftenebenen, die hierarchisch in Eltern-Kind-Beziehungen angeordnet sind, wobei jede Überschriftenebene eine oder mehrere Überschriften hat, eine Unterüberschrift einer jeweiligen Überschrift eine untergeordnete Überschrift in einer Eltern-Kind-Beziehung ist und die jeweilige Überschrift eine übergeordnete Überschrift in dieser Beziehung ist, und die Überschriftenhierarchie eine Wurzelebene enthält, die einer Stammüberschrift entspricht (für jede Antwortkandidatenpassage)
- Bestimmen eines Überschriftenvektors, der einen Pfad in der Hierarchie der Überschriften von der Stammüberschrift bis zu der jeweiligen Überschrift beschreibt, der die Antwortpassage des Kandidaten untergeordnet ist, bestimmen einer Kontextbewertung, die zumindest teilweise auf dem Überschriftenvektor basiert, anpassen der Bewertungspunktzahl je Antwort der ausgewählten Quelle zumindest teilweise durch die Kontextbewertung, um eine angepasste Bewertungspunktzahl zu bilden
- Auswählen einer Antwortpassage aus den Antwortpassagen der Kandidaten auf der Grundlage der angepassten Bewertungspunktzahlen.
Vorteile des Verfahrens im Patent
Lange Abfrageantworten können ausgewählt werden, teilweise auf der Grundlage von Kontextsignalen, die für eine Frage relevante Antworten darstellen. Die Kontextsignale können teilweise Suchanfrageunabhängig sein (d.h. unabhängig von ihrer Beziehung zu Begriffen der Suchanfrage bewertet werden.
Dieser Teil des Bewertungsverfahrens berücksichtigt den Kontext des Dokuments („Quelle“), in dem sich der Antworttext befindet, wobei Relevanzsignale berücksichtigt werden, die sonst bei der Suchanfrageabhängigen Bewertung möglicherweise nicht berücksichtigt werden.
Nach diesem Ansatz erscheinen lange Antworten, die eher das Informationsbedürfnis des Suchenden befriedigen als Featured Snippets.7
Das Patent findest Du unter:
Context scoring adjustments for answer passages
Erfinder: Nitin Gupta, Srinivasan Venkatachary , Lingkun Chu und Steven D. Baker
US-Patent: 9,959,315
Gewährt: 1. Mai 2018
Appl. Nr.: 14/169,960
Eingereicht: 31. Januar 2014
Kurzfassung:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for context scoring adjustments for candidate answer passages.
In one aspect, a method includes scoring candidate answer passages. For each candidate answer passage, the system determines a heading vector that describes a path in the heading hierarchy from the root heading to the respective heading to which the candidate answer passage is subordinate; determines a context score based, at least in part, on the heading vector; and adjusts answer score of the candidate answer passage at least in part by the context score to form an adjusted answer score.
The system then selects an answer passage from the candidate answer passages based on the adjusted answer scores.
Verwendung von Kontextbewertungen zum Anpassen der Antwortbewertungen für Featured Snippets
Eine Abbildung aus dem Patent zeigt verschiedene hierarchische Überschriften, die verwendet werden können, um den Kontext von Antwortpassagen zu bestimmen, die zur Anpassung von Bewertungspunktzahlen für gekennzeichnete Snippets verwendet werden können:

Ich betrachte diese Überschriften und ihre Hierarchie weiter unten. Beachte, dass die Überschriften den Seitentitel als Überschrift (Über den Mond) und auch die Überschriften innerhalb der Überschriftenelemente auf der Seite enthalten. Und diese Überschriften geben den Antworten den Kontext.
Dieser Prozess der Kontextbewertung beginnt mit dem Erhalt der Antwortpassagen der Kandidaten und einer Bewertung für jede der Passagen.
Diese Antwortpassagen der ausgewählten Quellen und ihre jeweilige Punktzahl werden einer Suchmaschine zur Verfügung gestellt, die eine als Frage bestimmte Suchanfrage erhält.
Jede dieser Quellen-Passagen ist Text, der aus einem Textabschnitt unter einer bestimmten Überschrift aus einer bestimmten Quelle (URL) mit einer bestimmten Antwortbewertung ausgewählt wurde.
Für jede Quelle, in der ein Antwortkandidat ausgewählt wurde, bestimmt ein Kontextbewertungsprozess eine Überschriftenhierarchie in der Quelle.
Eine Überschrift ist Text oder andere Daten, die sich auf eine bestimmte Passage in der Quelle beziehen.
Eine Überschrift kann beispielsweise ein Text sein, der einen Textabschnitt zusammenfasst, der unmittelbar auf die Überschrift folgt (die Überschrift beschreibt, worum es in dem Text geht, der auf die Überschrift folgt oder in ihr enthalten ist).
Überschriften können z.B. durch spezifische Formatierungsdaten angegeben werden, wie z.B. Überschriftenelemente unter Verwendung von HTML. (h1, h2, h3 …)
Der nächste Abschnitt aus dem Patent erinnert mich an eine Beobachtung, die Cindy Krum von Mobile Moxie über Sprungmarken auf einer Seite gemacht hat, und wie Google diese indexieren könnte, um eine Frage zu beantworten, zu einer Antwort oder einem Featured Snippet zu führen. Sie schrieb über diese Sprungmarken in What the Heck are Fraggles?
Eine Überschrift könnte auch eine Sprungmarke sein, der auf einen Anker und entsprechenden Text an einer anderen Stelle der Seite verweist.
Eine Überschriftenhierarchie könnte zwei oder mehr Überschriftenebenen haben, die hierarchisch in Eltern-Kind-Beziehungen angeordnet sind.
Die erste Ebene oder die Hauptüberschrift könnte der Titel der Quelle sein.
Jede der Überschriftenebenen kann eine oder mehrere Überschriften haben, und eine Unterüberschrift einer entsprechenden Überschrift ist eine untergeordnete Überschrift und die entsprechende Überschrift ist eine übergeordnete Überschrift in der Eltern-Kind-Beziehung.
Für jede Quellen-Passage kann ein Kontextbewertungsprozess eine Kontextbewertung bestimmen, die zumindest teilweise auf der Beziehung zwischen der Stammüberschrift und der jeweiligen Überschrift basiert, der die Quellen-Passage untergeordnet ist.
Der Kontextbewertungsprozess könnte zur Bestimmung der Kontextbewertung verwendet werden und einen Überschriftenvektor bestimmen, der einen Pfad in der Überschriftenhierarchie von der Hauptüberschrift zur jeweiligen Überschrift beschreibt.
Die Kontextbewertung könnte, zumindest teilweise, auf dem Überschriftenvektor basieren.
Der Kontextbewertungsprozess kann dann die Bewertungspunktzahl der Antwortpassage der Quelle zumindest teilweise durch die Kontextbewertung anpassen, um eine angepasste Bewertungspunktzahl zu bilden.
Der Kontextbewertungsprozess kann dann eine Antwortpassage aus den Antwortpassagen der Quelle auf der Grundlage angepasster Antwortbewertungen auswählen.
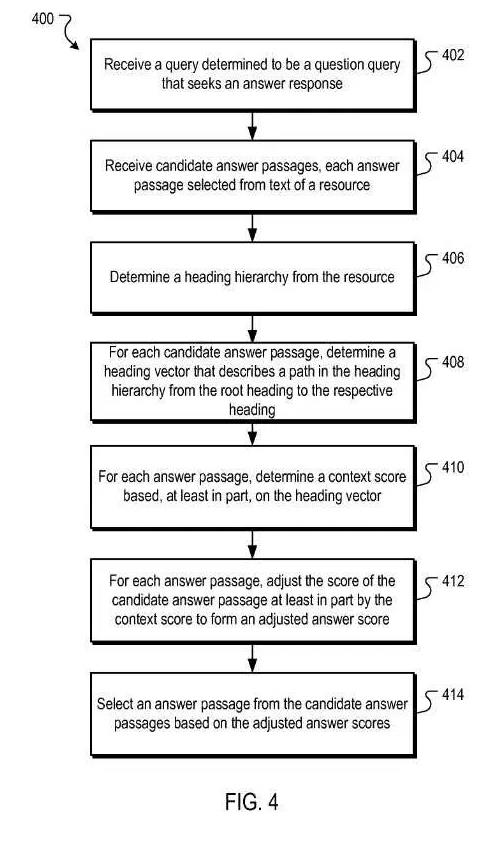
Dieses Flussdiagramm aus dem Patent zeigt den Anpassungsprozess der Kontextbewertung:
Identifizieren von Fragen in Suchanfragen und Antwortpassagen
Ich habe über das Verständnis des Kontexts von Antwortpassagen geschrieben. Das Patent sagt uns mehr über Fragen und Antwortpassagen, die es wert sind, ausführlicher behandelt zu werden.
Einige Fragen sind in Form einer expliziten Frage oder einer impliziten Frage.
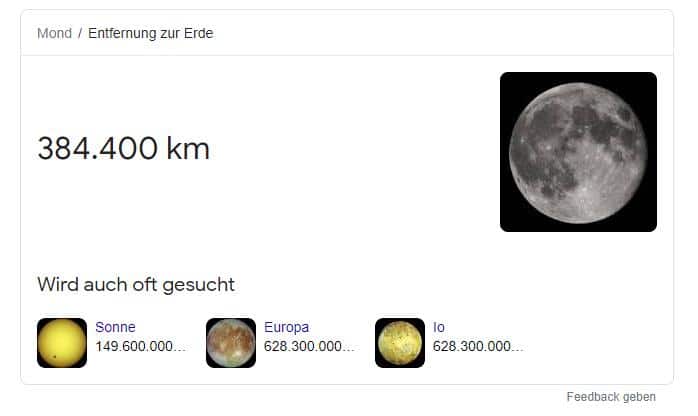
Zum Beispiel ist die Suchanfrage [Entfernung der Erde vom Mond]eine implizite Form der expliziten Frage „Was ist die Entfernung der Erde vom Mond?
Ebenso kann eine Frage explizit sein, wie in der Suchanfrage [Wie weit ist der Mond entfernt].
Die Suchmaschine benutzt einen Query-Prozessor, der Methoden verwendet, die feststellen, ob eine Suchanfrage eine Abfragefrage ist (implizit oder explizit) und wenn ja, ob es Antworten gibt, die auf die Frage antworten.
Der Query-Prozessor kann mehrere verschiedene Algorithmen verwenden, um festzustellen, ob eine Suchanfrage eine Frage ist und ob es bestimmte Antworten gibt, die auf die Frage antworten.
Beispielsweise kann er Fragen und Antworten folgendermaßen ermitteln:
- Sprachmodelle
- Machine Learning Prozesse
- Knowledge Graphen
- Grammatik
- Kombination aus allen
Der Query Prozessor kann die Antwortpassagen der ausgewählten Quelle zusätzlich zu oder anstelle von Fakten auswählen. Zum Beispiel ist für die Frage [wie weit entfernt ist der Mond] ein Fakt 238.900 Meilen. Und die Suchmaschine zeigt möglicherweise nur diese Fakteninformationen an, da dies die durchschnittliche Entfernung der Erde vom Mond ist.
Der Query Prozessor kann sich jedoch auch dafür entscheiden, Textpassagen zu identifizieren, die für die Fragestellung sehr relevant sein können.
Diese Passagen werden Quellenantwortpassagen genannt.
Die Antwortpassagen werden bewertet, und eine Passage wird auf der Grundlage dieser Bewertungen ausgewählt und als Antwort auf die Anfrage bereitgestellt.
Eine Antwortpassage kann bewertet werden, und diese Bewertung kann auf der Grundlage eines Kontextes angepasst werden, was der Kern hinter diesem Patent ist.
Häufig identifiziert Google mehrere Antwortpassagen von Kandidaten, die als Featured-Snippet-Antworten verwendet werden könnten.
Google kann sich die Informationen auf den Seiten, von denen diese Antworten stammen, ansehen, um den Kontext der Antworten besser zu verstehen, z. B. den Titel der Seite und die Überschriften über den Inhalt, in dem die Antwort gefunden wurde.
Kontextuelle Bewertungsanpassungen für die Antworten der Featured Snippets
Der Query-Prozessor sendet einige Antwortpassagen von Quellen, Informationen über die Quelle, aus denen die einzelnen Antwortpassagen stammen, und eine Bewertung für jede der Featured-Snippet-Antworten an einen Kontextbewertungs-Prozessor.
Die Bewertung der Kandidaten-Antwortpassagen könnte auf den folgenden Überlegungen basieren:
- Zuordnung eines Suchbegriffs zum Text der Antwortpassage der Quelle
- Abgleich der Antwortbegriffe mit dem Text der Antwortpassagen der Quelle
- Die Qualität der zugrundeliegenden Quelle, aus der die Antwortpassage des Kandidaten ausgewählt wurde
Das Patent sagt uns, dass der Query-Prozessor bei der Bewertung von Kandidaten-Antwortpassagen auch andere Faktoren berücksichtigen kann, als in dem bereits erwähnten Beitrag von mir.
Quelle-Antwort-Passagen können aus dem Text eines bestimmten Abschnitts der Quelle ausgewählt werden. Und der Query-Prozessor kann mehr als einen Antwortkandidaten aus einem Textabschnitt auswählen.
Folgende Beispiele für verschiedene Antwortpassagen von ein und derselben Seite werden gegeben:
- 1) Es dauert etwa 27 Tage (27 Tage, 7 Stunden, 43 Minuten und 11,6 Sekunden), bis der Mond die Erde in seinem Umlaufbahnabstand umkreist
- (2) Warum verändert sich der Abstand? Der Abstand des Mondes von der Erde ändert sich, weil der Mond auf einer leicht elliptischen Bahn um die Erde kreist. Daher variiert die Entfernung des Mondes von der Erde zwischen 225.700 Meilen und 252.000 Meilen.
- (3) Der Abstand des Mondes von der Erde variiert, weil der Mond auf einer leicht elliptischen Umlaufbahn reist. Daher variiert die Entfernung des Mondes von der Erde zwischen 225.700 Meilen und 252.000 Meilen.
Jede dieser Antworten könnte für Google relevant sein. Dazu im Patent:
More than three candidate answers can be selected from the resource, and more than one resource can be processed for candidate answers.
Wie würde Google zwischen diesen drei möglichen Antworten wählen?
Google könnte auf der Grundlage der Anzahl der Sätze und einer Auswahl von bis zu einer maximalen Zeichenanzahl entscheiden.
Das Patent sagt uns dies über die Wahl zwischen diesen Antworten:
Each candidate answer has a corresponding score. For this example, assume that candidate answer passage (2) has the highest score, followed by candidate answer passage (3), and then by candidate answer passage (1). Thus, without the context scoring processor, candidate answer passage (2) would have been provided in the answer box of FIG. 2. However, the context scoring processor takes into account the context of the answer passages and adjusts the scores provided by the query question processor.
Wir sehen also, dass das, was auf der Grundlage der Antwortpunktzahlen der Featured Snippets ausgewählt werden könnte, auf der Grundlage des Kontexts dieser Antwort von der Seite, auf der sie erscheint, angepasst werden kann.
Kontextbezogene Bewertung der Featured Snippet Antworten
Dieser Prozess beginnt mit einer Frage, die als Frage-Suchamfrage bestimmt ist und auf die eine Antwort gesucht wird.
Als nächstes erhält dieser Prozess Antwortquellenpassagen, wobei jede Antwortquellenpassage aus dem Text einer Quelle ausgewählt wird.
Jede der Antwortquellen-Passagen ist Text, der aus einem Textabschnitt ausgewählt wurde, der einer entsprechenden Überschrift (unter einer Überschrift) in der Quelle untergeordnet ist und eine entsprechende Bewertungspunktzahl aufweist.
Beispielsweise stellt der Query-Prozessor die Antwortquellenpassagen und ihre entsprechenden Bewertungen dem Kontextbewertungs-Prozessor zur Verfügung.
Eine Überschriftenhierarchie zur Bestimmung des Kontexts
Dieser Prozess bestimmt eine Überschriftenhierarchie aus der Quelle.
Die Überschriftenhierarchie würde zwei oder mehr Überschriftenebenen haben, die hierarchisch in Eltern-Kind-Beziehungen angeordnet sind (z.B. ein Seitentitel und ein HTML-Überschriftenelement).
Jede Überschriftenebene hat eine oder mehrere Überschriften.
Eine Unterüberschrift einer entsprechenden Überschrift ist eine untergeordnete Überschrift (eine (h2)-Überschrift könnte eine Unterüberschrift einer (Titel) sein) in der Eltern-Kind-Beziehung, und die entsprechende Überschrift ist eine übergeordnete Überschrift in der Beziehung.
Die Überschriftenhierarchie enthält eine Hauptebene, die einer Hauptüberschrift entspricht.
Der Prozessor für die Kontextbewertung kann Überschriften-Tags in einem DOM-Baum verarbeiten, um eine Überschriftenhierarchie zu bestimmen.
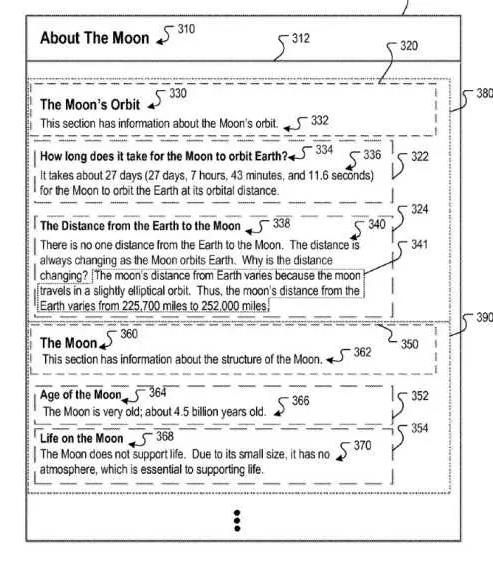
Zum Beispiel kann die Überschriftenhierarchie für die Ressource in der Abbildung über die Entfernung zum Mond sein:
Die Root-Überschrift (Titel) lautet: Über den Mond (310)
Die Hauptüberschrift (H1) auf der Seite
H1: Die Mondumlaufbahn (330)
Eine Sekundärüberschrift (h2) auf der Seite:
H2: Wie lange dauert es, bis der Mond die Erde umkreist? (334)
Eine weitere Sekundärüberschrift (h2) auf der Seite ist:
H2: Die Entfernung von der Erde zum Mond (338)
Eine weitere Hauptüberschrift (h1) auf der Seite
H1: Der Mond (360)
Eine weitere sekundäre Überschrift (h2) auf der Seite:
H2: Alter des Mondes (364)
Eine weitere Sekundärüberschrift (h2) auf der Seite:
H2: Leben auf dem Mond (368)
Im Patent wird diese Überschriftenhierarchie wie folgt beschrieben:
In this heading hierarchy, The title is the root heading at the root level; headings 330 and 360 are child headings of the heading, and are at a first level below the root level; headings 334 and 338 are child headings of the heading 330, and are at a second level that is one level below the first level, and two levels below the root level; and headings 364 and 368 are child headings of the heading 360 and are at a second level that is one level below the first level, and two levels below the root level.
Das Verfahren aus dem Patent bestimmt eine Kontextbewertung, die zumindest teilweise auf der Beziehung zwischen der Root-Überschrift und der jeweiligen Überschrift basiert, der die Antwortpassage des Kandidaten untergeordnet ist.
Die Bewertungspunktzahl kann auf einem Überschriftenvektor basieren.
Das Patent besagt, dass das Verfahren für jede der Quellen-Antwortpassagen einen Überschriftenvektor bestimmt, der einen Pfad in der Überschriftenhierarchie von der Root-Überschrift zur jeweiligen Überschrift beschreibt.
Der Überschriftenvektor würde den Text der Überschriften für die Quellen-Antwortpassage enthalten.
Für die obigen Beispielantwortquellen-Antwortpassagen (1)-(3) darüber, wie lange es dauert, bis der Mond den Orbit umkreist, sind die jeweils entsprechenden Überschriftenvektoren V1, V2 und V3:
V1=<[Root: Über den Mond], [H1: Die Mondumlaufbahn], [H2: Wie lange dauert es, bis der Mond die Erde umkreist?]>
V2=<<[Root: Über den Mond], [H1: Die Mondumlaufbahn], [H2: Die Entfernung von der Erde zum Mond], [H2: Die Entfernung von der Erde zum Mond], [H1: Die Mondumlaufbahn], [H2: Die Entfernung von der Erde zum Mond]>
V3=<<[Root: Über den Mond], [H1: Die Mondumlaufbahn], [H2: Die Entfernung von der Erde zum Mond], [V3=<[Wurzel: Über den Mond], [H1: Die Mondbahn], [H2: Die Entfernung von der Erde zum Mond]>
Da die Antwortpassagen (2) und (3) des Kandidaten aus demselben Textabschnitt 340 ausgewählt wurden, wird uns auch gesagt, dass ihre jeweiligen Überschriftenvektoren V2 und V3 gleich sind (sie stehen beide im Inhalt unter derselben (H2)-Überschrift).
Der Prozess der Anpassung einer Bewertung für jede Antwortpassage verwendet eine Kontextbewertung, die zumindest teilweise auf dem Überschriftenvektor (410) basiert.
Bei dieser Kontextbewertung kann es sich um eine einzelne Bewertung handeln, die zur Skalierung der Bewertung der Antwortpassage der Quelle verwendet wird, oder um eine Reihe von Bewertungen/Boosts, die zur Anpassung der Bewertung der Antwortpassage des Kandidaten verwendet werden können.
Wo die Dinge unklar werden im Patent
Es scheint mehrere verwandte Patente zu geben, die sich auf Antworten in Form von Snippets beziehen, und dieses Patent, das darauf abzielt, mehr über Antworten aus ihrem Kontext zu erfahren, je nachdem, wo sie in eine Überschriftenhierarchie passen..
Aber ich bin verwirrt darüber, wie das Patent uns sagt, dass eine Antwort, die auf dem Kontext basiert, über eine andere angepasst werden würde.
Das erste Problem, das ich habe, ist, dass die Antworten, die sie im gleichen Kontextbereich vergleichen, sich teilweise überschneiden. Hier sind diese beiden:
(2) Warum ändert sich der Abstand? Der Abstand des Mondes von der Erde ändert sich, weil sich der Mond auf einer leicht elliptischen Umlaufbahn bewegt. Daher variiert die Entfernung des Mondes von der Erde zwischen 225.700 Meilen und 252.000 Meilen.
(3) Der Abstand des Mondes von der Erde variiert, weil der Mond auf einer leicht elliptischen Umlaufbahn reist. Daher variiert die Entfernung des Mondes von der Erde zwischen 225.700 Meilen und 252.000 Meilen.
Beachte, dass die zweite Antwort und die dritte Antwort beide die gleiche Zeile enthalten: „So variiert die Entfernung des Mondes von der Erde zwischen 225.700 Meilen und 252.000 Meilen“. Ich bin etwas überrascht, dass die zweite Antwort ein paar Sätze enthält, die nicht in der dritten Antwort enthalten sind, und dass sie ein paar Zeilen aus der dritten Antwort überspringt und dann den letzten Satz enthält, der die Frage beantwortet.
Da sie beide in derselben Überschrift und demselben Unterüberschriftsabschnitt der Seite erscheinen, aus der sie stammen, ist es schwer vorstellbar, dass es eine unterschiedliche Anpassung je nach Kontext gibt. Aber das Patent sagt uns etwas anderes:
The candidate answer score with the highest adjusted answer score (based on context from the headings) is selected, and the answer passage.
Recall that in the example above, the candidate answer passage (2) had the highest score, followed by candidate answer passage (3), and then by candidate answer passage (1).
However, after adjustments, candidate answer passage (3) has the highest score, followed by candidate answer passage (2), and then-candidate answer passage (1).
Accordingly, candidate answer passage (3) is selected and provided as the answer passage of FIG. 2.
Steigerung der Punktzahlen auf der Grundlage des Überdeckungsgrads
Ein Query-Prozessor kann die Antworten der Kandidaten auf eine maximale Länge begrenzen.
Der Prozessor für die Kontextbewertung bestimmt ein Überdeckungsverhältnis, das ein Maß für die Abdeckung der Quellenantwortpassage aus dem Text ist, aus dem sie ausgewählt wurde.
Das Patent beschreibt alternative Antworten:
Alternatively, the text block may include text sections subordinate to respective headings that include a first heading for which the text section from which the candidate answer passage was selected is subordinate, and sibling headings that have an immediate parent heading in common with the first heading. For example, for the candidate answer passage, the text block may include all the text in the portion 380 of the hierarchy; or may include only the text of the sections, of some other portion of text within the portion of the hierarchy. A similar block may be used for the portion of the hierarchy for candidate answer passages selected from that portion.
Ein geringer Überdeckungsgrad kann darauf hinweisen, dass eine Antwortpassage der Quelle unvollständig ist. Ein hoher Überdeckungsgrad kann darauf hindeuten, dass die Kandidaten-Antwortpassage mehr vom Inhalt der Textpassage erfasst, aus der sie ausgewählt wurde. Abhängig von diesem Überdeckungsgrad kann eine Antwortquellenpassage eine Kontextanpassung erhalten.
Ein Überdeckungsgrad für eine Passage ist ein Verhältnis der Gesamtzahl der Zeichen in der Kandidaten-Quellepassage zu dem Verhältnis der Gesamtzahl der Zeichen in der Passage, aus der die Quellen-Antwortpassage ausgewählt wurde.
Das Passagenüberdeckungsverhältnis könnte auch ein Verhältnis der Gesamtzahl von Sätzen (oder Wörtern) in der Quellen-Antwortpassage zum Verhältnis der Gesamtzahl von Sätzen (oder Wörtern) in der Passage sein, aus der die Quellen-Antwortpassage ausgewählt wurde.
Es wird beschrieben, dass auch andere Verhältnisse verwendet werden können.
Von den drei Beispielkandidaten antworten Passagen über die Entfernung zum Mond oben (1)-(3), wobei Passage (1) das höchste, Passage (2) das zweithöchste und Passage (3) das niedrigste Verhältnis hat.
Dieser Prozess bestimmt, ob das Überdeckungsverhältnis unter einem Schwellenwert liegt. Dieser Schwellenwert kann z.B. 0,3, 0,35 oder 0,4 oder ein anderer Bruchteil sein. In unserem Beispiel „Entfernung zum Mond“ erreicht oder überschreitet jedes Überdeckungsverhältnis den Schwellenwert.
Wenn das Überdeckungsverhältnis unter einem Schwellenwert liegt, dann würde der Prozess einen ersten Antwortverstärkungsfaktor auswählen. Der Verstärkungsfaktor für die erste Antwort könnte gemäß einer ersten Beziehung proportional zum Abdeckungsverhältnis sein, oder vielleicht ein fester Wert, oder vielleicht ein nicht verstärkender Wert (z.B. 1,0.)
Wenn das Überdeckungsverhältnis jedoch nicht unter dem Schwellenwert liegt, kann der Prozess einen zweiten Antwortverstärkungsfaktor auswählen. Der zweite Antwortverstärkungsfaktor kann proportional zum Abdeckungsverhältnis gemäß einer zweiten Beziehung sein, oder vielleicht ein fester Wert, oder vielleicht ein Wert, der größer als der nicht verstärkende Wert ist (z.B. 1,1.)
Bewertung auf der Grundlage anderer Merkmale
Der Prozess der Kontextbewertung kann auch das Vorhandensein von Merkmalen zusätzlich zu den oben beschriebenen prüfen.
Drei Beispielmerkmale für die kontextbezogene Bewertung einer Antwortpassage können auf den zusätzlichen Merkmalen des kennzeichnenden Textes, einer vorausgehenden Frage und einem Listenformat basieren.
Herausstechender Text
Herausstechender Text ist der Text, der sich dadurch auszeichnen kann, dass er anders formatiert ist als andere Texte, z.B. durch Fettdruck.
Eine vorausgehende Frage
Eine vorausgehende Frage ist eine Frage im Text, die der Antwortfrage des Kandidaten vorausgeht.
Die Suchmaschine kann verschiedene Textmengen verarbeiten, um die Antwort auf die Frage zu ermitteln.
Es wird nur die Textstelle erkannt, aus der die Quellen-Antwortpassage extrahiert wurde.
Ein Textausschnitt, der Header-Text und anderen Text aus anderen Abschnitten enthalten kann, kann überprüft werden.
Es wird ein Boost-Score berechnet, der umgekehrt proportional zum Textabstand von einer Frage zum Antwortkandidaten ist, und die Prüfung wird beim Auftreten einer ersten Frage abgeschlossen.
Dieser Textabstand kann in Zeichen, Wörtern oder Sätzen oder mit einer anderen Metrik gemessen werden.
Wenn es sich bei der Frage um eine Sprungmarke für einen Textabschnitt handelt und es dazwischenliegenden Text gibt, wie z.B. im Fall einer Sprungmarkenlisten z.B. ein Inhaltsverzeichnis, dann wird bestimmt, dass die Frage nur der Textpassage vorausgeht, auf die sie sich bezieht, nicht aber dem dazwischenliegenden Text.
In der obigen Zeichnung über den Mond gibt es in der Quelle zwei Fragen: „Wie lange dauert es, bis der Mond die Erde umkreist“ und „Warum verändert sich die Entfernung?
Die erste Frage – „Wie lange dauert es, bis der Mond die Erde umkreist?“ – geht der ersten Antwortpassage des ersten Antwortkandidaten um einen Textabstand von null Sätzen voraus, und sie geht der zweiten Antwortpassage des zweiten Kandidaten um einen Textabstand von fünf Sätzen voraus.
Und die zweite Frage – „Warum ändert sich der Abstand?“ – geht der dritten Antwortquellenpassage um null Sätze voraus.
Wenn eine vorangehende Frage erkannt wird, dann wählt der Prozess einen Frageverstärkungsfaktor aus.
Dieser Verstärkungsfaktor kann proportional zum Textabstand sein, unabhängig davon, ob sich der Text in einer Textpassage befindet, die einer Kopfzeile untergeordnet ist, oder ob es sich bei der Frage um eine Header-Zeile handelt, und, falls die Frage in einer Header-Zeile steht, ob die Antwortquellpassage der Header-Zeile untergeordnet ist.
Unter Berücksichtigung dieser Faktoren erhält die dritte Antwortpassage den höchsten Verstärkungsfaktor, die erste Antwortpassage den zweithöchsten Verstärkungsfaktor und die zweite Antwortpassage den kleinsten Verstärkungsfaktor.
Umgekehrt wird das Vorhandensein einer Liste erkannt, wenn der vorhergehende Text nicht erkannt wird oder nachdem der Frageverstärkungsfaktor erkannt wurde.
Das Vorhandensein einer Liste
Eine Liste ist ein Hinweis auf mehrere Schritte, die in der Regel anleitend oder informativ sind. Die Erkennung einer Liste kann davon abhängig gemacht werden, dass die Suchanfragen-Frage eine schrittweise modale Abfrage ist.
Eine schrittweise modale Abfrage ist eine Abfrage, bei der eine auf einer Liste basierende Antwort wahrscheinlich zu einer guten Antwort führt. Beispiele für schrittweise Modellabfragen sind Abfragen wie
- [Wie . . . ]
- [Wie kann ich . . . ]
- [Wie installiere ich einen Türknopf]
- [Wie wechsle ich einen Reifen?]
Der Prozess der Kontextbewertung kann Listen erkennen, die erstellt wurden mit:
- HTML-Tags
- Mikro-Formate
- Semantische Bedeutung
- Aufeinanderfolgende Überschriften auf gleicher Ebene mit gleichen oder ähnlichen Sätzen (z.B. Schritt 1, Schritt 2; oder Erster; Zweiter; Dritter; usw.)
Bei der Kontextbewertung kann auch eine Liste nach Qualität bewertet werden.
Sie würde z.B. folgende Dinge berücksichtigen:
- Eine Liste in der Mitte einer Seite, die keine mehrfachen Links zu anderen Seiten enthält (Hinweis auf Referenzlisten)
- HREF-Link-Text, der keinen großen Teil des Listentextes einnimmt, ist von höherer Qualität als eine Liste am Seitenrand und enthält mehrere Links zu anderen Seiten (die auf Referenzlisten hinweisen) und/oder hat HREF-Link-Text, der einen großen Teil des Listentextes einnimmt
Wenn eine Liste erkannt wird, wählt der Prozess einen Listenverstärkungsfaktor aus.
Dieser Listenverstärkungsfaktor kann fest oder proportional zur Qualitätsbewertung der Liste sein.
Wenn eine Liste nicht erkannt wird oder nachdem der Listenverstärkungsfaktor ausgewählt wurde, wird der Prozess beendet.
In einigen Anwendungen kann der Listenverstärkungsfaktor auch von anderen Merkmalsbewertungen abhängig sein.
Wenn andere Merkmale, wie z. B. Überdeckungsgrad, herausstechender Text usw., relativ hohe Punktzahlen haben, kann der Listenanhebungsfaktor erhöht werden.
Das Patent beschreibt, dass dies darauf zurückzuführen ist, dass „die Kombination dieser Bewertungen bei Vorhandensein einer Liste ein starkes Signal für eine qualitativ hochwertige Antwortpassage ist“.
Anpassung der Bewertung von Featured Snippets
Die Bewertungen für die Antwortpassagen der Kandidaten werden durch Bewertungskomponenten auf der Grundlage von Vektorraumanalysen, Passagenüberdeckungsgrad und anderen oben beschriebenen Merkmalen angepasst.
Der Bewertungsprozess kann den größten Verstärkungswert aus den oben ermittelten Werten auswählen oder eine Kombination der Verstärkungswerte wählen.
Sobald die Antwortbewertungen angepasst sind, wird die Quellen-Antwortpassage mit der höchsten angepassten Antwortbewertung als die Featured Snippet ausgewählt und einem Suchenden angezeigt.
Mehr dazu in Kürze
Ich werde das erste Patent in dieser Serie von Patenten über Quellen-Antwort-Scores besprechen, weil es einige zusätzliche Elemente enthält, die in diesem Beitrag nicht behandelt werden, sowie den Beitrag über abfrageabhängige/unabhängige Rangsignale für Antwort-Scores.
Wenn Du darauf geachtet hast, wie Google Suchanfragen beantwortet, die konkrete Antworten bedürfen, hast Du wahrscheinlich festgestellt, dass sich diese in vielen Fällen verbessert haben. Einige Antworten sind jedoch wirklich schlecht. Es wäre schön, eine möglichst vollständige Vorstellung davon zu bekommen, wie Google auf der Grundlage der im Web verfügbaren Informationen entscheidet, was eine gute Antwort für ein Featured Snippet auf eine Anfrage sein könnte.
Hinzugefügt am 14. Oktober 2020 – Ich habe über ein weiteres Google-Patent zu den Antwortwertungen geschrieben, und es lohnt sich, über alle Patente zu diesem Thema zu lesen. Der neue Beitrag Weighted Answer Terms for Scoring Answer Passages befasst sich mit den Patent Weighted answer terms for scoring answer passages .
Es geht um die Identifizierung von Fragen in Quellen und Antworten auf diese Fragen und beschreibt die Verwendung von gewichteten Antwortbegriffen zur Bewertung von Antwortpassagen (zusammen mit den Bewertungsansätzen, die in den anderen verwandten Patenten, einschließlich dieses Patents, identifiziert wurden).
Hinzugefügt am 15. Oktober 2020 – Ich habe ein paar weitere Beiträge über Antwortpassagen geschrieben, die lesenswert sind, wenn Sie daran interessiert sind, wie Google Fragen auf Seiten und Antworten darauf findet und wie es die Antwortpassagen bewertet, um zu bestimmen, welche als Featured Snippets angezeigt werden sollen. Ich habe zu einigen von ihnen in diesen Beitrags verlinkt. Hier ist ein weiterer:
24. Januar 2019 – Does Google Use Schema to Write Answer Passages for Featured Snippets?

- Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index - 6. April 2021
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise - 15. Dezember 2020
- Personalisierte Knowledge Graphen: Dahin kann die Reise gehen! - 24. November 2020
- Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann - 2. November 2020
- Wie Google Ergebnisse für ein Featured Snippet auswählen kann - 29. September 2020

























4 Kommentare
Hallo Bill. Toller Inhalt wie immer. Die Informationen, die Sie zu Featured Snippets bereitgestellt haben, haben mir sehr gut gefallen.
Ich habe mich immer genau gefragt, wie sie Websites sortieren.
Google wird in Sachen Texterkennung immer besser. Das steht auf jeden Fall fest. Die Zukunft wird spannend.