
Ein neues Google-Patent aus November 2021 hat meine Aufmerksamkeit erweckt. In ihm wird beschrieben, wie Google in natürlicher Sprache gestellte Fragen basierend auf Entitäten-Referenzen aus unstrukturierten Informationen erkennen und ranken kann. Viel Spass beim Lesen!
Inhaltsverzeichnis
Das Google-Patent
Das Google-Patent was ich hier zusammenfassen möchte wurde im Mai 2019 gezeichnet und im November 2021 veröffentlicht und trägt den Titel „Question answering using entity references in unstructured data„.
Zusammenfassung
In dem Patent geht es um die Beantwortung von Fragen mit einem Entitäten-Bezug, die Nutzer in die Suchmaschine eingeben. Das System erkennt mindestens eine Entität oder einen Entitätstyp in der Suchanfrage und versucht diese Frage basierend auf den rankenden Inhalten, die sich um diese Entität(en) drehen zu beantworten. Die Ausspielung der Antwort erfolgt oberhalb der Suchergebnisse, also ähnlich einem Featured Snippet. Die beschriebene Methodik bezieht sich in erster Linie auf Wer?-, Was?- und Wo?-Fragen.
Aufgrund der Art der W-Frage erkennt das System nach welcher Art von Entitäts-Typ gefragt wird. Wer-Fragen beziehen sich auf Personen-Entitäten. Wo-Fragen beziehen sich auf Ortsbezogene Entitäten. Dabei können auch Suchanfragen, die nicht mit einer W-Frage beginnen als Frage identifziert werden. So wird die Suchanfrage „erster Bergsteiger mount everest“ als „Wer-Frage“ erkannt.
FIG. 2 shows an illustrative example of answering a question in accordance with some implementations of the present disclosure. In the illustrated example, a webpage search engine receives a “who” question, retrieves a number of search results, and provides an answer based on the search results and information associated with the search results. It will be understood that while the illustrated example refers to person entities in response to a “who” question, any suitable type of entity may be identified in response to any suitable type of question. For example, location entities may be identified in response to a “where” question.
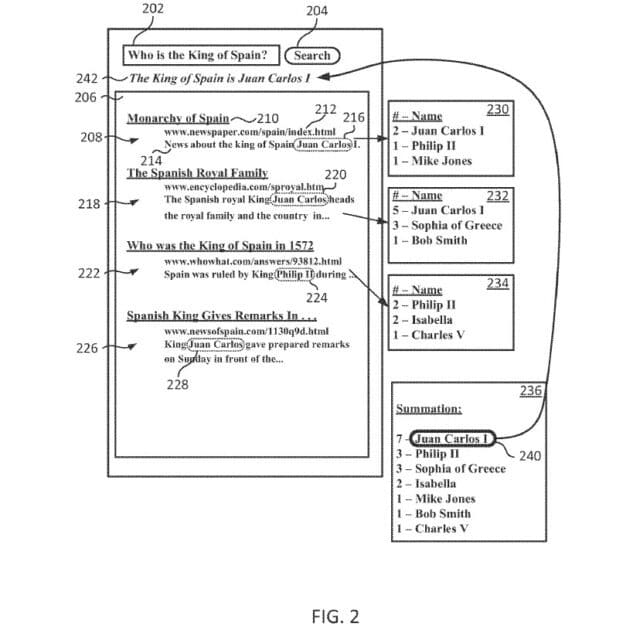
Die Identifikation der passenden Entitäten und die Zusammenstellung der Antwort wird aufgrund der Information in den ersten 10 rankenden Dokumenten durchgeführt. So werden im ersten Schritt nach dem Erhalt der (Suchan)Frage Dokumente zusammengestellt, in denen Teile der Suchanfrage vorkommen. Im nächsten Schritt werden Referenzen zu der oder den nachgefragten Entität(en) in Zusammenhang mit mindestens einem der Suchergebnisse zusammengestellt und nach Relevanz in eine Reihenfolge gebracht. Dieses Ranking der Entitäten-Referenzen basiert zum Einen darauf wie häufig die jeweilige Entitäten-Referenz in den Suchergebnissen vorkommt und zum anderen auf der Aktualität der Informationen. Die bedeutendste Referenz wird dann als Antwort ausgegeben.
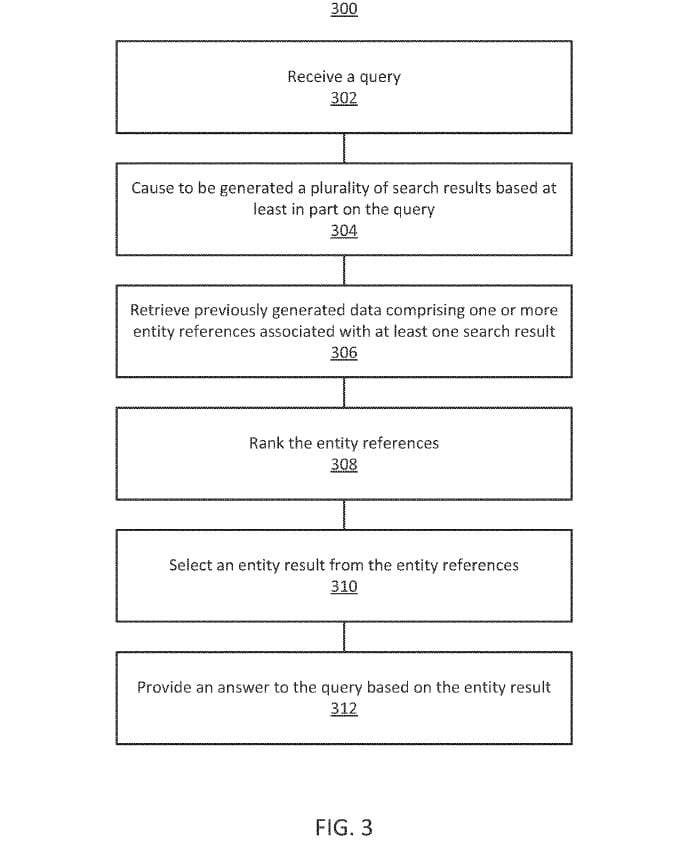
Diese Methodik erlaubt eine stets aktuelle Beantwortung von einfachen Fragen zu Personen, Orten und Dingen. Ein weiterer Vorteil ist, dass Google keine maschinenlesbaren struktierten Informationen benötigt um die Fragen zu beantworten. Zum anderen wird in dem Patent ein Bezug zwischen der Beantwortung der Fragen und dem Ranking von Suchergebnissen hergestellt:
In some implementations, question answering may take advantage of search result ranking techniques.
Ich verstehe es so, dass wenn man die gestellte Fragen adequat im Inhalt beantwortet das jeweilige Suchergebnis einen Ranking-Vorteil erhält. Sprich zum Einen spielt neben einem Relevanz-Score, einem Qualitäts-Score auch die Aktualität bzw. Freshness-Score eine Rolle.
In some implementations, the ranking and/or selecting is based on a quality score, a freshness score, a relevance score, on any other suitable information, or any combination thereof.
Diese Differenzierung finde ich spannend, da sie nach meiner Meinung die drei wichtigsten Rankingfaktor-Bereiche umfasst.
- Relevanz (klassische Information-Retrieval-Signale aus z.B. Text-Analyse (z.B. TF-IDF, Word2Vec …)
- Qualität (E-A-T)
- Aktualität
Im Patent wird auch auf Links als mögliches Signal für Qualität verwiesen:
In an example, a quality score associated with a search result may include the number of links to and from a corresponding webpage.
Weitere interessante Insights aus dem Patent
Zudem wird in dem Patent auch darauf hingewiesen, dass Entitäten in erster Linie Nomen in Rahmen einer grammatikalischen Satzstruktur sind. (Siehe dazu auch meine Beiträge Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten? und Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen).
Desweiteren beschreibt das Patent auch die Rolle von Entitäts-Konzepten mit einem Beispiel.
An entity generally refers to the concept of the entity. In some implementations, an entity reference is a reference, for example a text string, which refers to the entity. For example, the entity reference “New York City” is a reference to the physical city.
Es wird auch noch auf Entitätstypen eingegangen. (Dazu auch mehr in meinem Beitrag Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest.)
In some implementations, an entity is associated with a type of entity. As used herein, a type is a categorization or defining characteristic associated with one or more entities. For example, types may include persons, locations, movies, musicians, animals, and so on. For example, “who” questions may have answers of the person type.
Zu den Entitäts-Referenzen wird noch folgendes geschrieben:
In an example, the information retrieved from entity references 110 associated with a particular webpage is a list of persons appearing in that webpage. For example, a particular webpage may include a number of names of persons, and entity references 110 may include a list of the names included within the webpage. Entity references 110 may also include other information. In some implementations, entity references 110 includes entity references of different types, for example, people, places, and dates. In some implementations, entity references for multiple entity types are maintained as a single annotated list of entity references, as separated lists, in any other suitable format of information, or any combination thereof. It will be understood that in some implementations, entity references 110 and index 108 may be stored in a single index, in multiple indices, in any other suitable structure, or any combination thereof.
Es wird in dem Patent auch auf die Methodik des Clusterings eingegangen, um Beziehungen zwischen Entitäten aus einem Text herzustellen. Dabei spielt die Häufigkeit der Kookkurrenzen bestimmter Begriffe miteinander eine wichtige Rolle.
In some implementations, the system uses clustering techniques to identify entity references in unstructured content. Clustering is a statistical technique that groups similar objects into groups. Clustering can identify natural groupings in data elements. The groups of objects, such as groups of text strings, may be used to identify frequently occurring words and/or phrases in structured and/or unstructured content. For example, a person’s first and last name that appear together repeatedly in unstructured text may be identified as an entity reference.
Zur Bestimmung der passenden Suchergebnisse können folgende Faktoren berücksichtigt werden:
- Aktualitäts-Scoring nach Alter des Dokuments
- Anzahl der Links zu und/oder von dem Dokument ausgehend
- Klickrate des Dokuments in früheren Suchergebnissen bzw. Suchanfragen
- Stärke der Beziehung zwischen dem Dokument und der Suchanfrage
Für die Aktualitäts-Bewertung kann auch die Beziehung zwischen der Inhalts-Art und der Entitäten-Referenz eine Rolle spielen:
In some implementations, a topicality score depends on a relationship between the entity reference and the content within which the entity reference appears. For example, the entity reference [George Washington] may have a higher topicality score on a history webpage than on a current news webpage. In another example, the entity reference [Barak Obama] may have a higher topicality score on a politics website than on a law school website
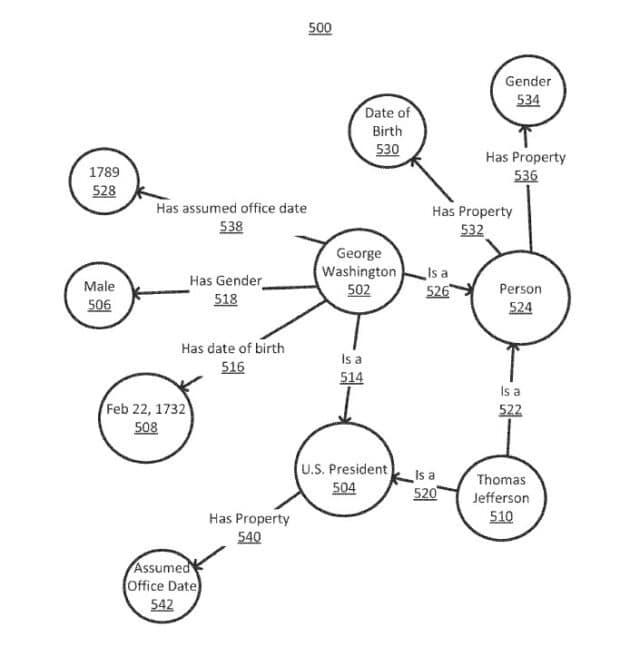
Zum Ende des Patents werden noch viele grundsätzliche Dinge zur Aufbau und Funktion und Knowledge Graphen geschrieben, die du auch in meinem Beitrag Google Knowledge Graph einfach erklärt nachlesen kannst.
Aber es werden auch Aspekte erwähnt, die ich so in meinen bisherigen Beiträgen nicht erwähne. So können die Knoten in einem Knowledge Graph neben Entitäten auch für organisatorische Strukturelemente wie Entitäts-Typen stehen.
Generally, nodes in a knowledge graph can be grouped into several categories. Nodes may represent entities, organizational data such as entity types and properties, literal values, and models of relationships between other nodes. A node of a knowledge graph may represent an entity, as defined above.
Zudem wird noch darauf eingegangen aus welchen Datenquellen der Knowledg Graph gespeist wird. Neben den bereits bekannten Quellen wie diversen externen Quellen, manueller Eingabe … wird auch erwähnt, dass häufig nachgefragte Entitäten, die bisher nicht erfasst sind nachgepflegt werden.
For example, content may be generated by manual user input, by automatic responses to user interactions, by importation of data from external sources, by any other suitable technique, or any combination thereof. For example, if a commonly searched-for term is not represented in the knowledge graph, one or more nodes representing that node may be added. In another example, a user may manually add information and organizational structures.
Fazit
Das Patent ist nicht nur mit Blick auf die Beantwortung von Fragen aus unstrukturierten Daten interessant. Die vielen Informationen, die nebenbei zum Beispiel zum Ranking von Suchergebnissen beschrieben werden zeigen neue Perspektiven auf bzw. bestätigen schon länger bekannte. Das ist ein Grund warum ich mich gerne mit Google Patenten beschäftigen. Mehr zu Google-Patenten, die sich mit der Funktionsweise moderner Suchmaschinen beschäftigen findest Du in meinem Premium-Bereich.
Mehr zur semantischen Suche bei Google in diesem ausführlichen Video:

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.