
Die größte Herausforderung für Google mit Blick auf eine semantische Suche stellt das Identifizieren und Extrahieren von Entitäten und deren Attributen aus Datenquellen wie Websites dar. Die Informationen sind meistens nicht strukturiert und nicht fehlerfrei. Der aktuelle Knowledge Graph als Googles semantisches Zentrum basiert in großen Teilen auf den strukturierten Inhalten aus Wikidata und den semistrukturierten Daten aus der Wikipedia bzw. Wikimedia.
In diesem Beitrag meiner Beitragsreihe möchte ich einen genaueren Blick auf die Verarbeitung der Daten aus semistrukturierten Daten-Quellen wie der Wikipedia werfen.
Die Verarbeitung strukturierter Daten habe ich hier bereits kurz behandelt.
Eine ausführliche Beitragssammlung zum Thema Knowledge Graph, semantische SEO und Entitäten findest Du in der zugehörigen Artikelreihe.
Inhaltsverzeichnis
- 1 Verarbeitung semistrukturierter Daten
- 2 Die Verarbeitung semistrukturierter Daten am Beispiel Wikipedia
- 3 Wie Google Spezialseiten der Wikipedia nutzen kann
- 4 Datenbanken basierend auf Wikipedia: DBpedia & YAGO
- 5 Kategorisierung von Entitäten aufgrund von Schlüssel-Attributen
- 6 Attribute sammeln mit Wikipedia als Startpunkt
- 7 Wie werden Informationen zu Entitäten zusammengetragen?
- 8 Informationen aus der Wikipedia in Featured Snippets und Knowledge Panel
- 9 Wikipedia als „Proof of Entity“
- 10
- 11 Wikipedia und Wikidata aktuell (noch) die wichtigsten Datenquellen
Verarbeitung semistrukturierter Daten
Semistruktierte Daten sind Informationen, die nicht nach allgemeinen Auszeichnungs-Standards wie z.B. nach RDF, schema.org … explizit ausgezeichnet sind, aber eine implizite Struktur aufweisen. Aus dieser impliziten Struktur lassen sich i.d.R. über Workarounds strukturierte Daten gewinnen.
Die Extrahierung der Informationen aus Datenquellen mit semistrukturierten Daten kann über einen Template-Based Extractor durchgeführt werden. Dieser kann aufgrund einer immer wiederkehrenden gleichen Struktur von Beiträgen Inhaltsabschnitte identifizieren und aus Ihnen Informationen extrahieren.
Die Verarbeitung semistrukturierter Daten am Beispiel Wikipedia
Wikipedia oder andere Quellen stellen aufgrund der in jedem Beitrag ähnlichen Struktur und stetigen Prüfung durch Editoren wie z.B. die Wikipedianer eine sehr attraktive Quelle für Informationen dar. Zudem basiert Wikipedia auf dem MediaWiki-CMS. Dadurch sind die Inhalte mit rudimentären Mark-Ups versehen und können einfach via XML-, SQL-Dumps oder als html downgeloadet werden. Man kann hier auch von semistrukturierten Daten sprechen.
Die Struktur eines typischen Wikipedia-Beitrags ist eine Template-Vorlage für die Klassifizierung von Entitäten nach Kategorien, Identifikation von Attributen und das Extrahieren von Informationen für Featured Snippets und Knowledge Panels. Der sehr ähnliche bzw. identische Aufbau der einzelnen Wikipedia-Beiträge in z.B.
- Titel (1)
- Lead Section (2)
- Einführung (2a)
- Infobox (2b)
- Einleitungs-Text (2c)
- Inhaltsverzeichnis (3)
- Haupttext (4)
- Ergänzungen (5)
- Fußnoten und Quellen (5a)
- Weiterführende Links (5b)
- Kategorien (5c)
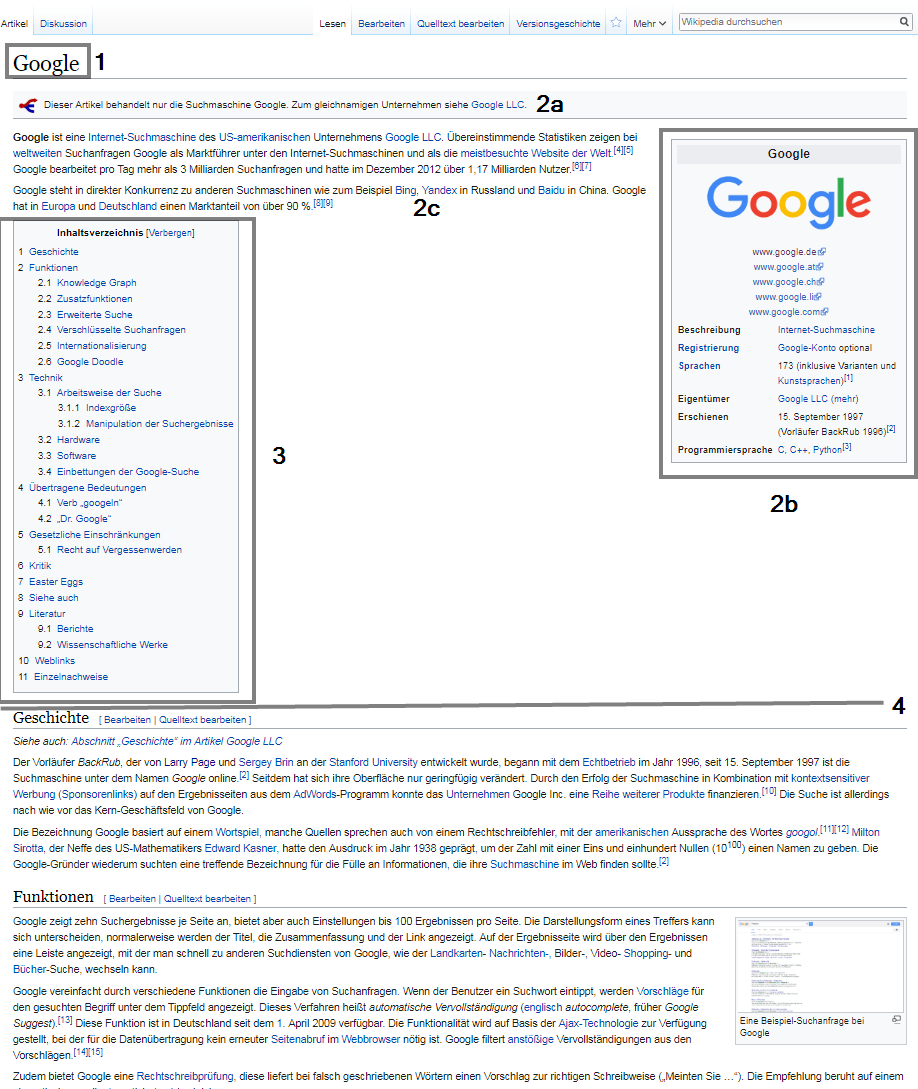
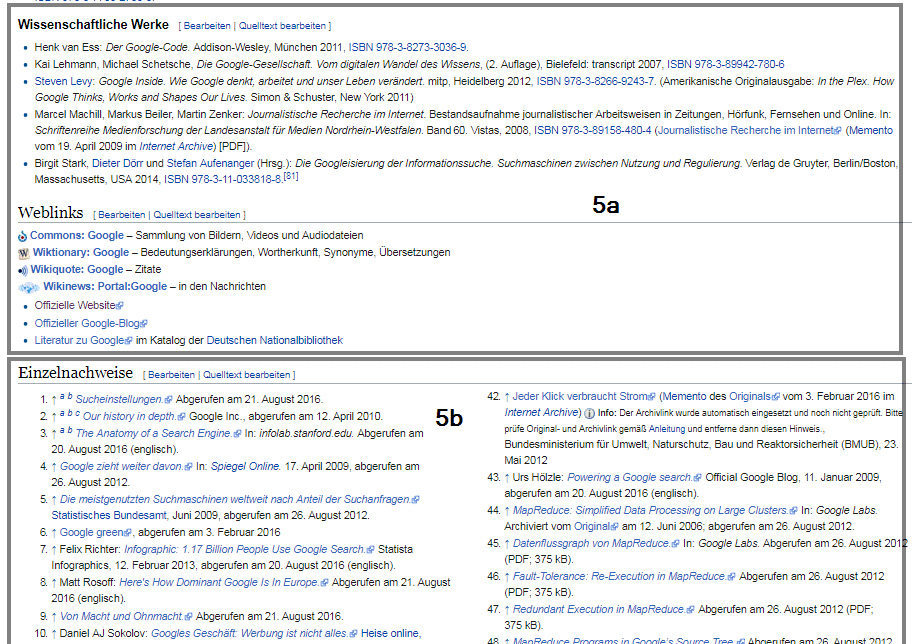

Beispiel Ergänzungen in der Wikipedia am Beispiel der Entität „Google“
Der Titel eines jeden Wikipedia-Beitrags gibt den Entitäts-Namen wieder. Bei mehrdeutigen Titeln wird zur klareren Abgrenzung zu den anderen Entitäten mit gleichen Namen der Typ im Titel mit angehängt, wie beim Zeichner Michael Jordan. Dort lautet der Titel Michael Jordan (Zeichner) um ihn von der populäreren Entität des Basketballspielers Michael Jordan abzugrenzen.
Die Info-Box (2b) rechts oben eines Wikipedia-Beitrags stellt strukturierte Daten zur jeweiligen Entität bereit. Den Einleitungstext (2c) findet man häufig im Knowledge Panel zu der jeweiligen Entität wieder. Dazu weiter unten in diesem Beitrag mehr.
Die internen Verlinkungen innerhalb der Wikipedia geben Google einen Aufschluss dazu welche weiterführenden Themen bzw. andere Entitäten im semantischen Zusammenhang mit der jeweiligen Entität stehen. Deswegen nutzen wir in der Agentur bereits seit über 4 Jahren ein eigenes Wikipedia-Script welches die internen Verlinkungen von relevanten Wikipedia-Beiträgen analysiert.
Wie Google Spezialseiten der Wikipedia nutzen kann
Die Wikipedia bietet eine Reihe an Spezialseiten, die Google helfen können Entitäten besser zu verstehen, zu gruppieren und zu klassifizieren.
Listen- & Kategorie-Seiten für die Einordnung nach Entitäts-Typen und -Klassen
Die Kategorien, die eine Entität in der Wikipedia zugeordnet ist findet man immer am Ende eines Beitrags (siehe 5c). Auf den Kategorie-Seiten selber findet man eine Übersicht aller Oberkategorien, Unterkategorien und Entitäten, die dieser Kategorie zugeordnet sind.
Listen-Seiten (z.B. hier ) geben ähnlich wie Kategorie-Seiten eine Übersicht aller Elemente, die mit dem Listen-Thema in Verbindung stehen.
Über diese beiden Seiten-Typen könnte Google die jeweilige Entität den Entitäts-Typen und -Klassen zuordnen.
Wikipedia verfügt verglichen mit den anderen großen Wissens-Datenbanken über die meisten Typen-Klassen.
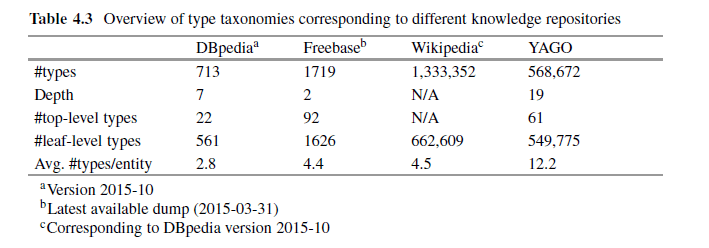
Quelle: Entity Oriented Search von Krisztian Balog
Welche zentrale Rolle die Wikipedia bei der Identifikation von Entitäten und deren thematischen Kontext spielen kann, zeigt das wissenschaftliche Papier Using Encyclopedic Knowledge for Named Entity Disambiguation.
Beziehungen zwischen Entitäten könnte Google u.a. über Annotationen bzw. Verlinkungen innerhalb der Wikipedia herstellen.
“An annotation is the linking of a mention to an entity. A tag is the annotation of a text with an entity which captures a topic (explicitly mentioned) in the input text.”
Weiterleitende Spezialseiten für die Identifikation von Synonymen
Weiterleitende Spezialseiten wie z.B. diese hier zum Thema Internet Marketing leiten Nutzer der Wikipedia weiter zum Hauptbegriff. In diesem Beispiel ist Internet Marketing ein Synonym für den Hauptbegriff Online Marketing. Über diese weiterleitenden kann Google synonyme Bezeichnungen für eine Entität identifizieren und sie der Hauptbezeichnung zuordnen. Dies funktioniert ähnlich einem Canonical Tag in der Suchmaschinenoptimierung.
Begriffserklärungs-Seiten für die Erkennung von mehrfachen Bedeutungen
Begriffserklärungsseiten wie z.B. diese hier zu Michael Jordan geben einen Überblick über alle Entitäten, die den Namen Michael Jordan enthalten. Hier gibt es 5 verschiedene Entitäten auf die es zutrifft. Man beachte, dass die Titel aller 5 Entitäten unterschiedlich formuliert sind, um sie klar voneinander abzugrenzen.
Dadurch bekommt Google einen Überblick bei welchen Namen es mehrdeutige Entitäten gibt.
Datenbanken basierend auf Wikipedia: DBpedia & YAGO
DBpedia ist eine mehrsprachige Datenbank basierend auf Inhalten aus der Wikipedia bzw. Wikimedia, die regelmäßig aktualisiert wird. Die Daten sind als Linked-Data für jeden via Browser, RDF-Browser oder direkt via SPARQL-Clients zugänglich . Mit dem Modul DBpedia Live wird die Datenbank seit 2016 in Echtzeit aktualisiert. Hier findest Du ein Beispiel eines DBpedia-Datensatz für die Entität Audi A4.
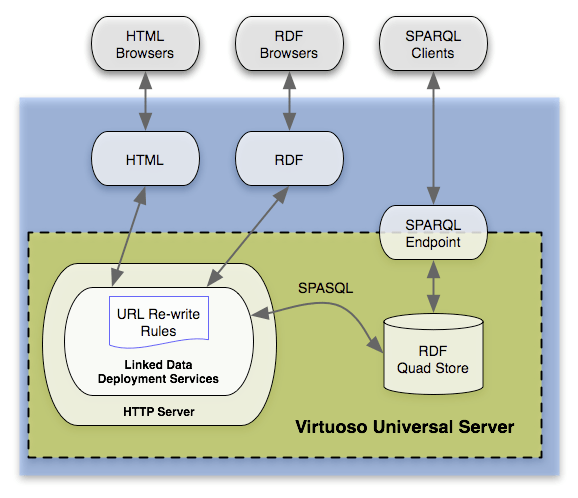
Quelle: https://wiki.dbpedia.org/about
In der DBpedia Ontology werden Entitäten in Beziehung zueinander gesetzt bzw. als Knowledge Graph dargestellt. In dem folgenden Auszug aus DBpedia Ontology werden Entitäts-Typen (abgerundete Rechtecke) via aufsteigenden Pfeilen mit übergeordneten Entitäts-Klassen in Beziehung gesetzt. Z.B. sind die Entitäts-Typen Athlet und Rennfahrer der Entitäts-Klasse „Person“ zugeordnet. Typen- und Klassen-verbindende Attribute sind mit den gestrichelten Pfeilen dargestellt.
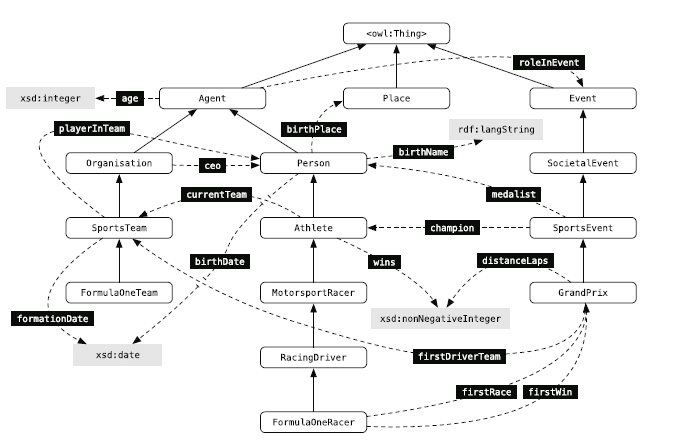
Auszug aus DBpedia Ontology; Quelle: Entity-Oriented Search – Krisztian Balog
Das Ganze stellt dann eine Ontologie dar, die die Beziehungen zwischen den Klassen, Typen und somit auch Entitäten abbildet. Die Extrahierung der Daten aus der Wikipedia funktioniert über DBpedia Extraction Framework. Als Quellen für die Extrahierung werden die die oben aufgeführten Elemente eines Wikipedia-Beitrags genutzt.
YAGO ist enebenfalls eine semantische Datenbak, die auf den Inhalten von Wikipedia beruht. Bei dieser Datenbank liegt der Fokus mehr auf die Erstellung von Entitäts-Typen und Ontologien. Dafür gleicht YAGO, die Wikipedia-Kategorien mit den hierarchisch sortierten Klassen von WordNet ab. Da die Wikipedia-Kategorien keine hierarchisch gegliederte Struktur vorweisen stellt YAGO in Sachen Struktur einen zusätzlichen Mehwert dar.
Die Elemente von DBpedia und YAGO sind über „same-as-Links“ miteinander verknüpft. Somit können beide Datenbanken von Google parallel genutzt werden, ohne dass Duplikate oder Redundanzen entstehen. Über diesen Weg können hunderte weitere semantische Datenbanken als Quellen nebenher genutzt werden.
YAGO und DBpedia gehören neben Wikidata zu den wichtigsten.
Kategorisierung von Entitäten aufgrund von Schlüssel-Attributen
Neben den Kategorie- und Listen-Seiten gibt es weitere Möglichkeiten, wie Google Entitäten bestimmten Entitäts-Typen und Entitäts-Klassen zuordnen kann. So beschreibt das etwas ältere Google-Patent Object categorization for information extraction, wie das funktionieren kann. Die in dem Patent beschriebenen Objekte können Entitäten sein.
In dem Patent wird beschrieben wie Objekte aufgrund identifizierter Schlüssel-Attribute einer Kategorie bzw. Klasse oder einem Typ zugeordnet werden können. Sobald ein Objekt einen Schwellenwert von für eine Kategorie charakteristischen Schlüssel-Attribute besitzt kann es dieser Kategorie zugeordnet werden.
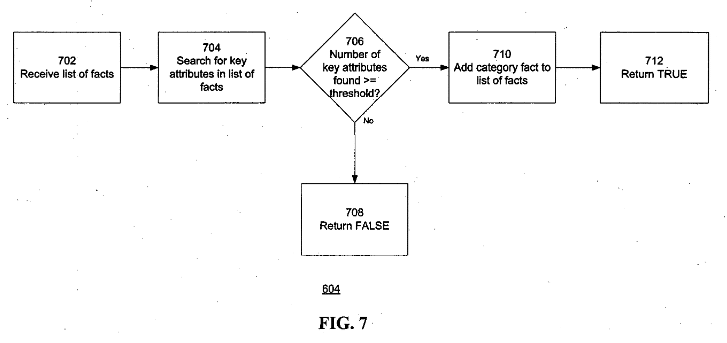
Quelle: Google Patent Object categorization for information extraction, US20070203868A1
Z.B. für die Entitäts-Klasse „Buch“ wären eine ISBN-Nummer, Autor, Publisher und Titel typische Schlüssel-Attribute. Für ein Bilder-Album wären Album-Name, Datei-Größen, Bild-Adresse, Maße, Auflösung … charakteristische Attribute.
Diese Methode lässt sich sowohl auf unstrukturierte Daten als auch strukturierte Daten anwenden.
Welche Attribute bzw. welche Attribut-Werte-Paare relevant für eine Entität oder einen Entitäts-Typ sind könnte durch eine Methodik ermittelt werden, die im Google-Patent Attribute-value extraction from structured documents beschrieben wird.
„In general, one aspect of the subject matter described in this specification can be embodied in methods that include the actions of obtaining an initial attribute whitelist, the initial attribute whitelist including one or more initial attributes; extracting a plurality of candidate attributes from a first collection of documents; grouping the candidate attributes according to both a particular document from which each candidate attribute was extracted and a corresponding structure of that document; calculating a score for each unique attribute in the candidate attributes, where the score reflects a number of groups containing the unique attribute and an attribute on the initial attribute whitelist; generating an expanded attribute whitelist, the expanded attribute whitelist including the initial attributes and each unique attribute having a respective score that satisfies a threshold; and using the expanded attribute whitelist to identify valid attribute-value pairs. „
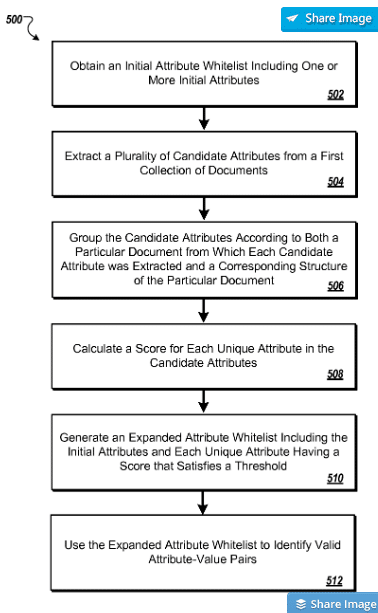
Quelle: Google Patent Attribute-value extraction from structured documents
Durch diese Methodik ließe sich zudem die Richtigkeit bestimmter Werte prüfen, um die jeweilige Datenbank valide zu halten.
Die angesprochenen ersten Dokumente als Quelle für eine inititale Auswahl an Attributen, könnten strukturierte Daten aus Wikidata und semistrukturierte Daten aus der Wikipedia sein.
Attribute sammeln mit Wikipedia als Startpunkt
Im Google-Patent Unsupervised extraction of facts wird eine Methode erläutert, die es ermöglicht stetig neue Fakten bzw. Attribute zu einer Entität in einem Fact Repository zu sammeln.
Diese Methodik beginnt bei einem Start-Dokument aus dem ein Attributs-Wert-Paar oder Entitäts-Typ extrahiert wird wie z.B. „Alter (Attribut): 43 Jahre (Wert)“ oder Schauspieler. Aus dem Attribut Alter oder Typ Schauspieler lässt sich schon mal die Klasse Mensch oder Person ableiten.
Bei der Extrahierung der Seed-Fakten über einen Importer-Modul aus dem Startdokument findet keine qualitative Prüfung statt. Sprich das Dokument muss von hoher Qualität bzw. Richtigkeit sein. Die Validität der gesammelten Informationen hängt entscheiden von den Basis-Daten ab. Hier sollte nur auf vertrauenswürdige Quellen von hoher Validität, wie z.B. die Wikipedia zurückgegriffen werden.
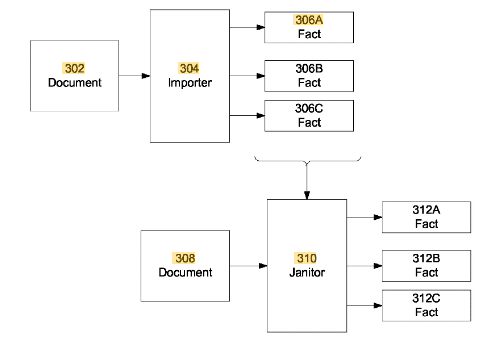
Quelle: Google Patent Unsupervised extraction of facts, US9558186B2
Von nun an können weitere Dokumente analysiert werden, die kontextuell sich z.B. mit Schauspielern oder der Entität selbst beschäftigen. Dort können weitere kontextuell passende Attribut-Wert-Paare extrahiert werden und im Fact Repository der Entität zugeordnet werden. Über diesen Weg ließen sich auch weitere Schlüssel-Attribute zu Entitäts-Typen oder -Klassen stetig neu ergänzen.
Diese geschieht neben einem Importer-Modul auch über ein Janitor-Modul, das sich um die Duplikats-Bereinigung, Daten-Zusammenführung, Normalisierung oder Daten-Sauberkeit kümmert.
Die Quelle für die Start-Recherche können Wikipedia-Beiträge sein.
Wie werden Informationen zu Entitäten zusammengetragen?
Der aktuelle Stand bei Google scheint noch zu sein, dass i.d.R. alle Informationen zu Entitäten aus Daten-Quellen mit RDF-konform strukturierten Daten und semistrukturierten Daten wie der Wikipedia aggregiert sind.
Um Informationen zu Entitäten wie Attribute, Entitäts-Typen, Entitäts-Klassen und Beziehungen zu benachbarten Entitäten zusammenzutragen, muss zuerst ein Entitäten-Profil angelegt werden. Dieses Profil ist wie bereits im Beitrag Was ist eine Entität ? zuvor erläutert mit einem Entitäts-Namen und URI ausgezeichnet, die eine eindeutige Zuordnung ermöglicht.
Dieses Profil wird dann aus verschiedenen Datenquellen mit Informationen zu dieser Entität versorgt. Hier ein Beispiel, wie so etwas aussehen könnte für die Entität Audi A4:
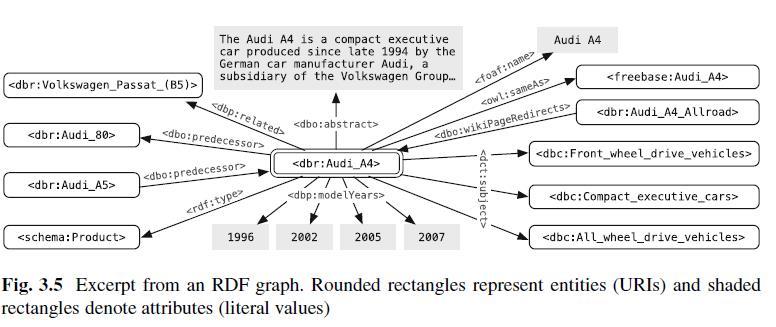
In diesem Beispiel stammen die Informationen aus Wikipedia bzw. DBpedia und die Entität ist verknüpft mit der gleichen Entität bei Freebase.
Informationen aus der Wikipedia in Featured Snippets und Knowledge Panel
Gerade bei der steigenden Bedeutung von gesprochenen Suchanfragen bzw. Voice Search versuchen moderne Suchmaschinen Antworten sofort zu liefern, ohne, dass sich der Nutzer durch 10 blaue Links auf der ersten Suchergebnisseite navigieren muss. Dafür muss die Bedeutung des Suchterm identifiziert werden und zum anderen relevante Informationen aus strukturierten und unstrukturierten Datenquellen extrahiert werden. Die Lösung dafür ist Entity Retrieval.
Die Aufgabe von Entity Retrieval ist es auf eine geschriebene oder gesprochene Suchanfrage relevante Entitäten aus einem Katalog zu identifizieren und nach Relevanz zur Suchanfrage sortiert in einer Liste auszugeben. Zur Ausgabe einer Antwort bedarf es eines Auszugs, der kurz und knapp die Entität erklärt.
Diese Art der Beschreibung kennen wir zum einen aus den Featured Snippets als auch den Entitäten-Beschreibungen in den Knowledge Panels, die meistens aus Wikipedia bzw. DBpedia extrahiert werden. Bei den Featured Snippets werden auch Informationen aus unstrukturierten Quellen wie Magazinen, Glossaren oder Blogs extrahiert. Allerdings scheint Google hier die Beschreibungen aus unstrukturierten Quellen aktuell nur als Notlösung zu nutzen und Beschreibungen aus Wikipedia vorzuziehen.
Nachfolgend eine Auswertung von Malte Landwehr aus dem März 2019 zur Frage wie sich die Informations-Quellen für Featured Snippets zum Thema Online Marketing verteilen.
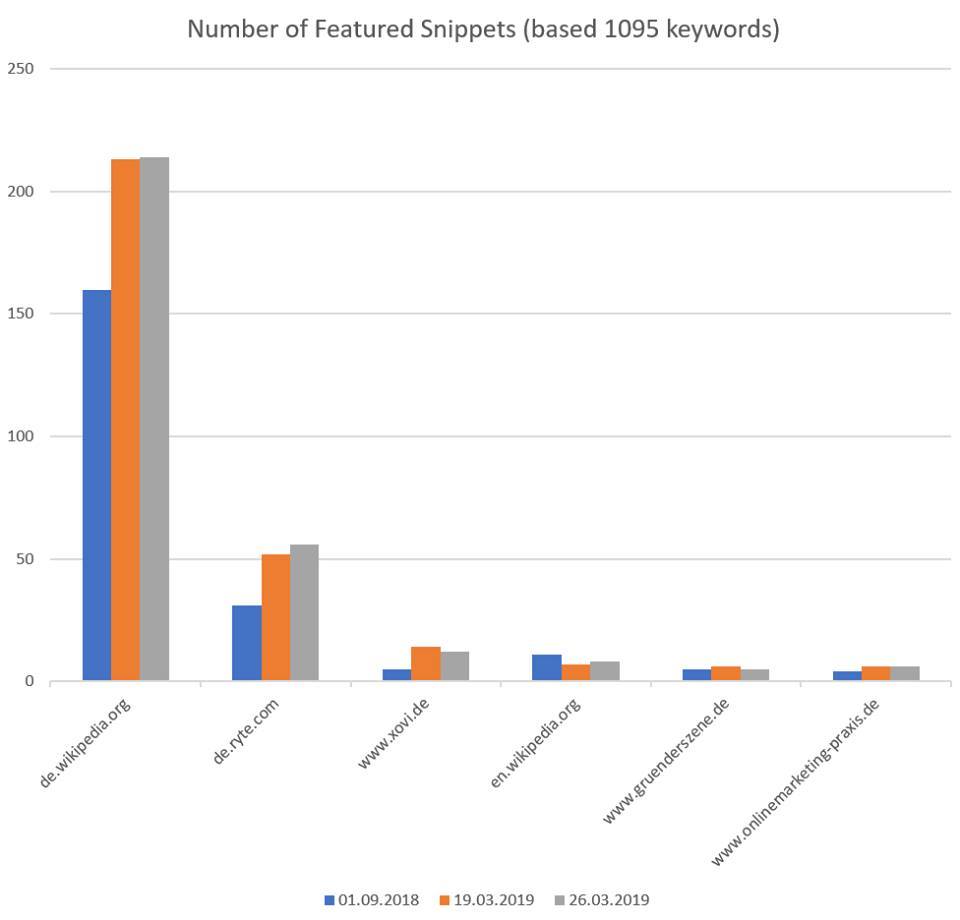
Verteilung der Quellen für Featured Snippets für 1095 Suchterme aus dem Online Marketing, Quelle: Malte Landwehr (Searchmetrics)
Nur vereinzelt findet man noch Informationen, die nicht aus der Wikipedia kommen wie hier am Beispiel der Suchanfrage „redirect„. Sobald Wikipedia Informationen zu einem Begriff bereitstellt werden diese häufig bevorzugt. In diesem Fall scheint Google zum Glück für die Kollegen von Ryte die Entitäten Redirect und Weiterleitung noch nicht miteinander „verlinkt“ zu haben, obwohl in der Wikipedia bereits eine Weiterleitende Spezialseite vorhanden ist.
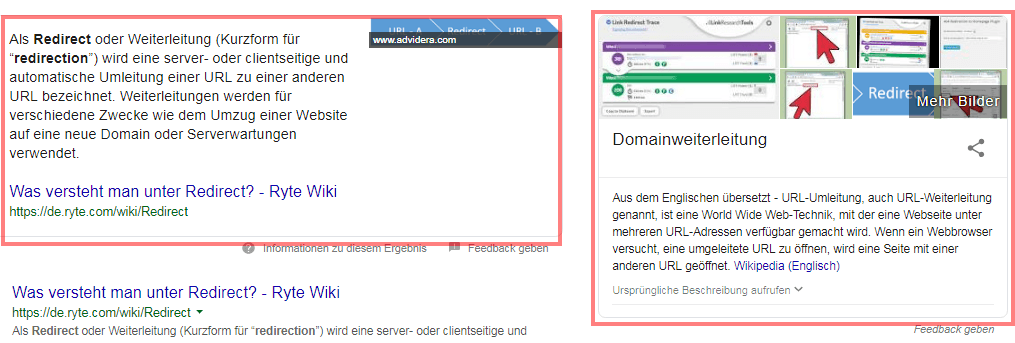
Beispiel: Featured Snippet und Knowledge Panel zur Suchanfrage „redirect“
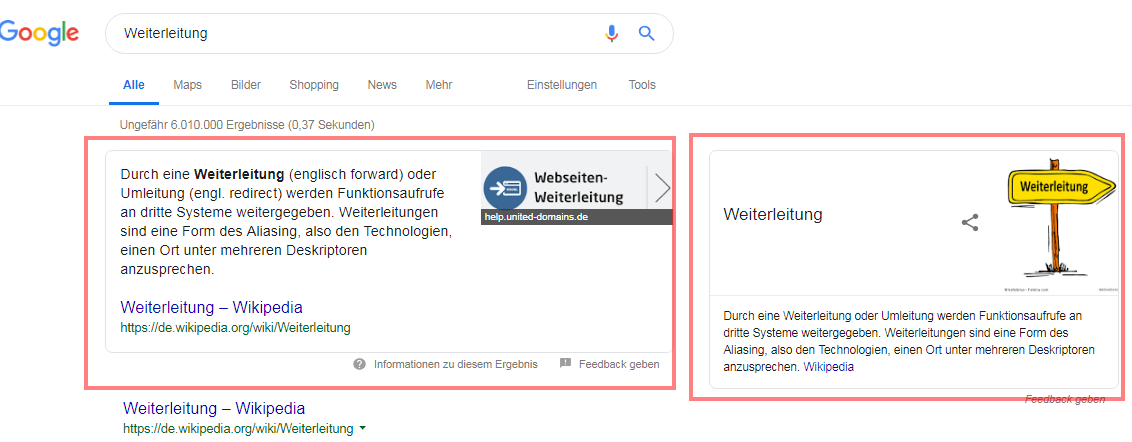
Beispiel Featured Snippet und Knowledge Panel zur Suchanfrage „weiterleitung“
Google traut aktuell am häufigsten den Informationen aus der Wikipedia, um Featured Snippets zu bestücken. Da kann man mehrere Gründe haben. Zum einen ist es aufgrund der eindeutigen Struktur von Wikipedia einfach den Einleitungstext eine Beitrags zu extrahieren. Dieser beschreibt das Thema kurz und knapp.
Wie genau Google Informationen aus unstrukturierten Website-Texten für das Featured Snippets extrahiert ist Spekulationen. Die Vermutungen sind vielfältig. Ich glaube, dass es in erster Linie mit im Abschnitt vorkommenden Tripeln aus Objekt, Prädikat und Subjekt zusammenhängen. Dazu aber im nächsten Beitrag meiner Beitragsreihe mehr.
Die Häufigkeit der vorkommenden Wikipedia-Informationen in den Featured Snippets lässt eine Vermutung zu, dass Google noch nicht mit den Ergebnissen der Extrahierung unstrukturierter Daten zufrieden ist und/oder die Manipulations-Versuche bisher nicht unter Kontrolle bekommen hat.
Wikipedia als „Proof of Entity“
Der sicherste Weg als Entität wahrgenommen zu werden ist ein Eintrag bei Wikipedia, Wikidata oder die Einreichung bei Google selbst. Dazu mehr in dem interessanten Selbstversuch vom Kollegen Artur Kosch .
Aber Google behält sich vor die Einträge zu prüfen und wieder aus den Datenbanken zu löschen, wenn man nicht genug referenzierende Quellen im Wikidata-Eintrag angibt. Um Manipulation vorzubeugen muss ein Eintrag aus mindestens einer dritten Quelle verifiziert sein. So scheint es zumindest. Eine Wikipedia-Seite oder Wikimedia-Eintrag scheint hier eine wichtige Quelle zu sein.
Während in Wikidata eher stichpunkartig Attribute einer Entität zugeordnet werden beschreibt Wikipedia die Entität in einem ausführlichen Text. Ein Wikipedia-Beitrag ist damit die ausführliche Beschreibung einer Entität und stellt als externes Dokument eine wichtige Quelle für den Knowledge Graph dar.
For example, a unique identification reference may be stored within the node, a short information string may be stored in a terminal node as a literal, and a long description of an entity may be stored in an external document linked to by a reference in the knowledge graph. Quelle: „https://patents.google.com/patent/US20140046934A1/en“
In einem wissenschaftlichen Projekt, an dem auch ein Google-Mitarbeiter beteiligt war, wird eine Entität gleich gesetzt mit einem Wikipedia-Beitrag.
“An entity (or concept, topic) is a Wikipedia article which is uniquely identified by its page-ID.”
Wikipedia-Beiträge spielen bei vielen Knowledge Graph Boxen eine übergeordnete Rolle als Quelle der Informationen und werden von Google neben den Wikidata-Einträgen als Proof für die Relevanz einer Entität genutzt. Ohne Eintrag bei Wikipedia oder Wikidata keine Entitäten-Box bzw. Knowledge Panel.
Ein Eintrag bei Wikipedia bleibt allerdings den meisten Unternehmen und Personen verwährt, da ihnen die gesellschaftliche Relevanz in den Augen der Wikipedianer fehlen. Ob Dein Unternehmen oder Du selbst relevant genug für Wikipedia bist erfährst du im Beitrag Ist mein Unternehmen relevant für Wikipedia? oder unserem ausführlichen Leitfaden Kommunikaton in der Wikipedia.
Eine sinnvolle Alternative ist die Einrichtung eines Profils bei Wikidata. Die Häufigkeit immer wiederkehrender konsistenter Daten über verschiedene vertrauenswürdigen Quellen hinweg erleichtern es Google Entitäten eindeutig zu erkennen.
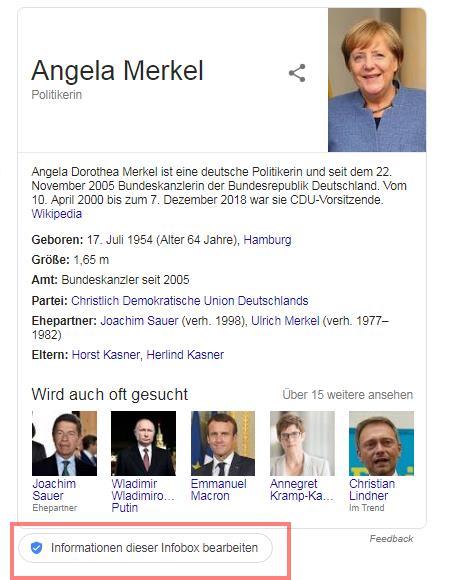
Button zur Beanspruchung eines Knowledge Panel
Bei von Google oder den Autoren bei Wikipedia oder Wikidata erstellten Entitäts-Einträgen ist es möglich die eigene Entität zu beanspruchen wie in dem Beitrag Wie man seine Entität bei Google beanspruchen kann erläutert.
Sobald ein Knowledge Panel eingeblendet wird ist es möglich diesen als Entitäts-Verantwortlicher in Anspruch zu nehmen (siehe Abbildung links).
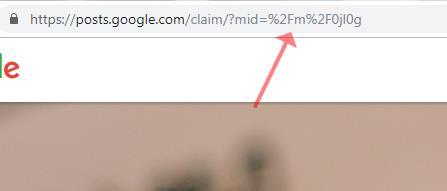
Dabei spielt die Card-ID eine besondere Rolle. Diese findet man im Quelltext des Knowledge Panel.

Card-ID des Knowledge Panel von Angela Merkel
Sobald man auf den Button klickt gelangt man auf die eine Google-Seite auf der man das Knowledge Panel zu Entität beanspruchen kann und die Card-ID wird als Parameter an die URL angehängt.
Wikipedia und Wikidata aktuell (noch) die wichtigsten Datenquellen
Google ist seit über 10 Jahren sehr bestrebt darin eine Wissensdatenbank wie den aktuellen Knowledge Graph größer und größer werden zu lassen. Das zeigen die unzähligen Patente. Auch die gesamte Netz-Gemeinde zeigt ein großes Interesse daran das menschliche Wissen zu archivieren, zu vernetzen und möglichst vollständig abzubilden, was die vielen meist ehrenamtlich gepflegten Wissens-Datenbanken zeigen. Diese Datenbanken sind inzwischen das, was die Menschheit früher in riesigen Bibliotheken gesammelt und gepflegt haben.
Und Google möchte der Gatekeeper Nummer eins zu diesem Wissen sein.
Doch gerade mit Blick auf die Vollständigkeit ist es noch ein langer Weg. Datenbanken und Portale wie Wikidata und Wikipedia haben sich zu enormen Wissens-Datenbanken mit strukturierten und semistrukturierten Daten entwickelt. Dienste wie DBpedia und YAGO bilden eine Art Schnittstelle für Google und andere verarbeitende Instanzen.
Wikipedia stellt als Basis eine sehr gute zugängliche und vertrauenswürdige Wissens-Datenbank rund um Entitäten dar.
Der große Nachteil: Nur ein Bruchteil aller benannten Entitäten und Konzepte ist in Wikipedia und Wikidata beschrieben.
Um annähernd einen Überblick über alle Entitäten, Konzepte und Themen zu erhalten reichen diese in großen Teilen manuell von Menschen gepflegten Datenbanken als Basis nicht aus.
Die Erfassung des gesamten iim Internet abgebildeten Wissen muss das Ziel sein. Mit diesen Ziel befindet man sich in dem Spannungsfeld zwischen Validität und Vollständigkeit. Zudem muss der Manipulation Einhalt geboten werden.
Es müssen technische Verfahren entwickelt werden, die diese Punkte berücksichtigen. Hier geht an der automatisierten Verarbeitung unstrukturierter Datenquellen kein Weg vorbei. Auch das ist ein Grund warum Google das Engagement hinsichtlich Machine Learning weiter vorantreibt.
Deswegen wird es in meinem nächsten Beitrag um die Verarbeitung unstrukturierter Daten gehen.
Ich hoffe dieser Beitrag konnte Euch hinsichtlich semistrukturierter Daten, Wikipedia in Bezug auf Entitäten und den Knowledge Graph weiterhelfen. Spread the Word!
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.