Dieser Beitrag beschäftigt sich mit einem Google Patent aus Dezember 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Entitäten in einem Video z.B. bei Youtube erkennen kann. Aufgrund von Features, die man bereits in der Google-Suche und bei Youtube vorfindet ist es sehr wahrscheinlich, dass diese oder ähnliche Methoden bereits in der Google-Suche zum Einsatz kommen. Viel Spass beim Lesen!
Inhaltsverzeichnis
Zusammenfassung des Patents „Feature based Video Annotation“
Das Patent mit dem Titel „Feature based Video Annotation“ mit der Patent-Nummer US11200423B2 wurde am 14.12.2021 von Google gezeichnet. Es beschreibt Methoden wie ein Computer-System Entitäten in einem Video bzw. den einzelnen Abschnitten des Videos erkennt und eine Wahrscheinlichkeit ermittelt, dass es in dem Video um diese Entität(en) geht. Diese Ermittlung findet über bestimmte Eigenschaften des Videos statt.
Der Prozess zur Entitäten-Ermittlung in Videos im Detail
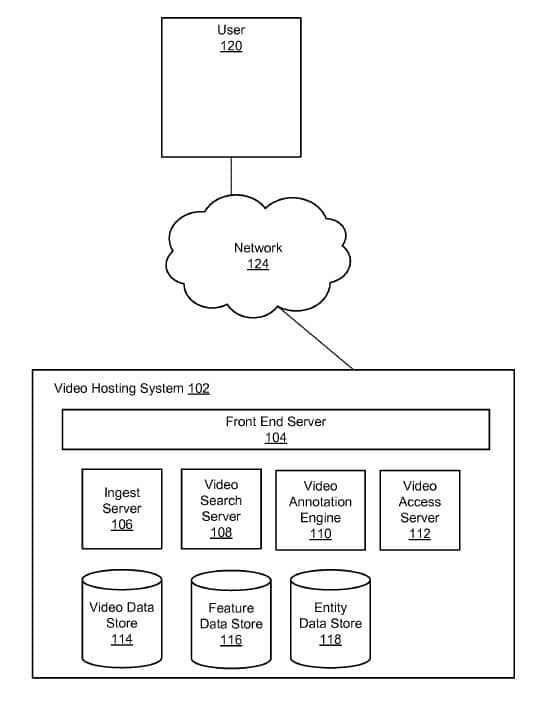
Abbildung 1
Ein Nutzer hat Zugriff über einen Browser auf ein Video das auf einem Server bzw. einer Plattform (z.B. Youtube) ausgeführt wird. Teil dieser Plattform sind neben dem Front End ein Ingest Server, Video Search Server, eine Video Annotation Engine und ein Video Access Server. Zur Anreicherung der Videos mit Anmerkungen wird auf einen Speicher für die Video-Daten, Features und Entitäten zurückgegriffen.
In dem Patent wird der Aufbau des Front Ends sehr ähnlich beschrieben wie wir es heutzutage bei Youtube vorfinden. Deswegen kann man davon ausgehen, dass es in diesem Patent explizit um das Youtube-Front-End geht.
The front end server 104 handles all communication with the user via the network 124. The front end server receives requests from users and communicates with the other servers of the video hosting system 102 in order to process the requests. The front end server 104 is further configured to monitor user interactions with the video hosting system 102. For example, if a user clicks on a web page, views a video, makes a purchase, opens a document, fills a web-based form, the front end server 104 monitors these interactions. The front end server 104 may be further configured to transmit and present the requested video and related video links to the user on a webpage. The requested video is streamed by the front end server 104 to the user. One or more related video links appear on the webpage where the requested video is playing, such that the related video link can be selected by a user 120 in order to view the related videos.
Der Ingest Server ist für den Upload, Speicherung und Anreicherung des Videos mit Titel, Beschreibung, Thumbnail, Tags … durch den Besitzer bzw. Uploader des Videos zuständig. Im Video-Daten-Speicher können Videos mit Merkmalen aus dem Feature-Speicher verknüpft werden. Diese Verknüpfung findet bereits bei der Bearbeitung des Videos über den Ingest Server statt. Merkmale können einzelne Begriffe oder Terme z.B. aus dem Titel oder der Description des Videos sein.
Über den Ingest Server kann das System zusätzlich Entitäten, die im Zusammenhang mit dem Video stehen identifizieren und im Entitäten-Speicher erfassen. Entitäten werden in dem Patent als „Text-Descriptors“ beschrieben, die es erlauben Video-Eigenschaften dem Video zuzuordnen und als Meta-Daten im Video-Daten-Speicher erfasst zu werden. Diese Entitäten werden einzelnen Video Abschnitten zugeordnet. Wenn in einem Abschnitt z.B. ein Mops ein Croissant im Golden Gate Park betrachtet können diesem Video-Abschnitt die Entitäten „hund“, „croissant“, „san francisco“, „golden gate park“, „hungrig“ automatisiert vom System zugeordnet werden. Erste Anhaltspunkte für mögliche im Video vorkommende Entitäten können durch den Uploader z.B. über Tags und die Beschreibung mitgegeben werden. Das klingt erst einmal nicht neu.
Zusätzlich wird aber auch erwähnt, dass weitere Informationen zu verbundenen Entitäten aus der Audio-Spur des Videos, über die Transkription in Untertiteltext extrahiert werden können. Die weitere Interpretation wird dann durch verschiedene Methoden der Text-Analyse wie TF-IDF-Analysen, Natural Language Processing und weiteren semantischen Analysen durchgeführt. Ich hatte es schon länger vermutet, dass Google auch Audio Spuren z.B. in Videos oder Podcasts analysiert, mir fehlte bisher aber eine konkrete Google-seitige Quelle dazu.
The set of potential entities that can be associated with media content items may be derived from tags or other descriptive information provided by a user. For videos, entities may be derived from textual descriptions and metadata accompanying the videos, as well as closed captioning text present in the video, or by converting audio to text and then extracting entities from the text. For textual documents (e.g., web pages, emails, etc.), entities may be determined using term frequency analysis, semantic analysis, natural language processing, or other methods. An index is maintained in the video data store 114 that associates each entity with the set of content items to which the entity is identified.
Im Patent wird auch darauf eigegangen, dass diese Methode nicht nur für Video-Content, sondern auch alle weiteren Formen von Medien wie z.B. Audio-Formate genutzt werden kann.
Thus, the operations of the video annotation engine 110 described herein for annotating video files can be applied to any type of media content item, not only videos; other suitable type of content items include audio files (e.g. music, podcasts, audio books, and the like), documents, multimedia presentations, digital purchases of goods and services, and so forth.
Hier einige Quellen, in denen ich diese Vermutung schon geäußert habe:
Der Video Search Server greift die Suchanfragen bei Youtube aufbezie, ht sich beim Ranking in der Video-Suche auf die durch die Entitäten-Informationen angereicherten Meta-Daten und gibt die Ergebnisse an das Front End aus. Die Video Annotation Engine verknüpft die Informationen aus dem Entitäten-Speicher und den Video-Daten-Speicher mit den Videos bzw. den Video Abschnitten.
The video annotation engine 110 annotates video files stored in the video data store 114. For a video file, the video annotation engine 110 may annotate each video file according to the features associated with the video file stored in the feature data store 116 and the entity data store 118. For each video file stored in the video data store 114, the video annotation engine 110 annotates each video frame of the video file with entities that exist in that frame.
Die Wahrscheinlichkeit, dass ein Video-Abschnitt sich mit einer Entität beschäftigt wird durch einen Korrelations-Abgleich zwischen den Merkmalen im jeweiligen Video-Abschnitt und den Informationen im Video-Daten-Speicher und Entitäten-Speicher durchgeführt. Es wird überprüft ob diese Informationen zusammenpassen. Bei einer hohen Korrelation ist die Wahrscheinlichkeit hoch, dass es sich in diesem Video-Abschnitt auch wirklich um die Entität dreht. Über diesen Weg lassen sich z.B. auch manipulative Methoden wie Clickbaiting und Keyword-Stuffing unterbinden. Über diese Methode lassen sich auch einzelne Video-Abschnitte identifizieren, die zu einer Suchanfrage passen. Sprich das Ranking von relevanten Video-Abschnitten in den Suchergebnissen wäre möglich. Auch die Gestaltung von alternativen Video-Titel und -Beschreibungen wäre möglich, wie wir das auch schon vom „Title-Update“ in der normalen Google-Suche kennen.
The method can identify video frames within video content items that are most relevant to search queries containing one or more keywords, e.g., showing those frames in search results as representations of the video content items. The method can further rank a set of video content items retrieved responsive to a search query according to the probabilities of existence of the entities labeled for video frames of each video content items. The method can further use the labeled entities and associated probabilities of existence to identify video frames within video content items that are relevant to information describing the video content items, such as the title of the video.
Die Anreicherung von Videos mit Anmerkungen bezüglich Entitäten und die Ermittlung der Korrelation für die Wahrscheinlichkeit wird über Machine Learning durchgeführt. So wird die Beziehungsnähe zwischen Entitäten und Merkmalen über einen Wahrscheinlichkeits-Score bzw. Confidence-Score ermittelt, der über das Lernen mit Trainingsdaten verfeinert wird.
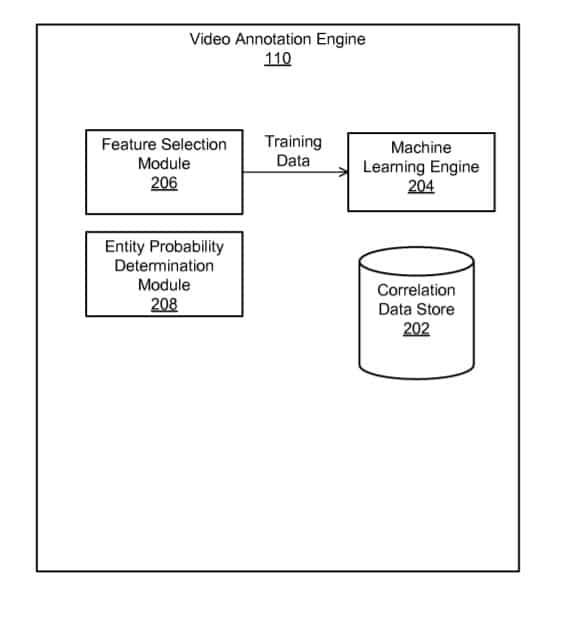
Fazit: Zusammenhang dieses Google-Patents mit MUM
Dieses Google-Patent weist deutliche Verbindungen zu den im Rahmen von MUM vorgestellten Features auf. Die hier beschriebenen Methoden könnten die Grundlage dafür sein neben Text auch Video- und Audio-Formate besser hinsichtlich der Relevanz also das Ranking von Videos und anderen Medienformaten bei Youtube und der Google-Suche bewerten zu können und zusätzliche Datenquellen für den Aufbau von semantischen Datenbanken zu erschließen.
Dass diese oder ähnliche Methoden bereits bei Google im Einsatz sind zeigen die beiden folgenden Beispiele. Beide Videos habe ich selbst beim Hochladen nicht mit Zeitstempeln versehen oder Informationen zu Entitäten versehen. Google erkennt diese Eigenständigkeit basierend auf der Audio-Spur als auch dem Text der auf den Präsentationsfolien abgebildet ist. Im ersten Beispiel übernimmt Google die Folien-Titel für die Markierung der Zeitstempel. Im zweiten Beispiel werden die in der Ton-Spur erwähnten Entitäten Zalando, Adidas und Amazon als Abschnitt-Markierungen genutzt, was nicht besonders sinnvoll ist aber zeigt, dass Google diese Entitäten aus der Tonspur raus identifizieren kann.
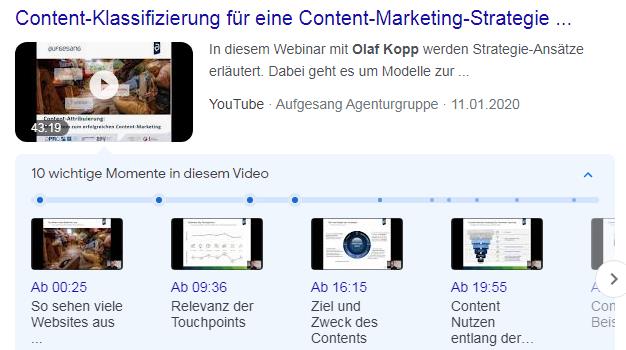
Beispiel 1
Beispiel 2
Als Schlussfolgerung aus diesem Google Patent kann man sich bei der Gestaltung / Optimierung von Videos auf Youtube folgende Gedanken machen:
- Wie strukturiere ich das Video in eine sinnvolle Struktur / Abschnitte
- Auf welche Keywords und Entitäten soll das Video bzw. einzelne Abschnitte ausgerichtet sein? Diese Entitäten und Begriffe sollten sowohl auf der Tonspur, als auch der Darstellung, Titel, Beschreibung, Tags … die relevanten Terme nutzen.
- Auf Methoden, die nur auf Keyword Stuffing und Clickbaiting aus sind sollte verzichtet werden
Seht Euch dazu gerne zur Vertiefung das bereits in diesem Beitrag aufgeführte Website-Boosting-Interview mit Mario Fischer an oder lest die Titelstory der zugehörigen Website-Boosting-Ausgabe zur semantische Suche und MUM durch.


- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.