
Dieser Beitrag beschäftigt sich mit einem Google Patent aus Juni 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Content bestimmten Entitäten / Themen zuordnet und in ein Ranking überführt. Interessant ist dieser Beitrag für fortgeschrittene SEOs, Content-Verantwortliche und Lehrende in diesen Bereichen. Viel Spass beim Lesen!
Inhaltsverzeichnis
Zusammenfassung des Patents „Methods, systems, and media for presenting content organized by category“
Das Patent mit dem Titel „Methods, systems, and media for presenting content organized by category“ mit der Patent-Nummer US11036743B2 wurde am 15.06.2021 von Google veröffentlicht. Es beschreibt Methoden wie eine Suchmaschinen Content aufgrund von Haupt- undDie Nebenentitäten gruppiert, ausliefert und in eine Reihenfolge gemäß eines Scorings bringt.
Die Identifikation von Content passend zu einem Thema bzw. einer Hauptentität basiert auf Nutzerverhalten. Für die Identifikation des Contents werden verschiedene Quellen herangezogen. Diese Quellen können Informationen enthalten, die auf Themen hinweisen, die mit einem Hauptthema semantisch verwandt sind, wobei die Verwandtschaft zweier Themen auf der Grundlage des Benutzerverhaltens abgeleitet wird (z. B. Suchanfragen eines Nutzers, Inhalte, die Benutzer typischerweise in der gleichen Sitzung ansehen und/oder jede andere geeignete Art von Benutzerverhalten). Auch strukturierte Daten, die auf eine Beziehung zum Hauptthema schließen lassen können für die Gruppierung herangezogen werden.
Die Hinweise aus dem Nutzerverhalten und den strukturierten Informationen können kombiniert miteinander für die Gruppierung des Contents genutzt werden.
So können z.B. zwei Filme in Beziehung zueinander stehen, weil sie in ihnen der gleiche Schauspieler mitspielt.
Hier ein Beispiel:
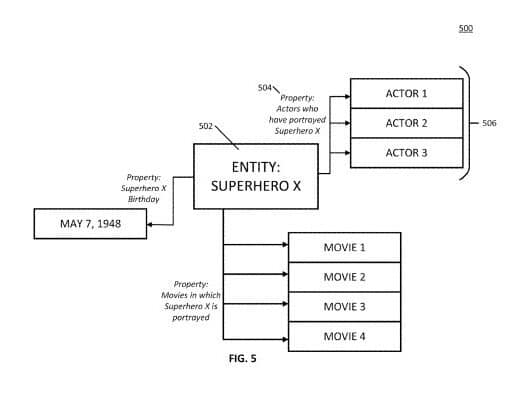
Die Entität eines Superhelden kann durch Attribute, die typisch für Personen-Entitäten aus einer der Entität zugeordneten Quelle bezogen werden. Ferner lassen sich weitere Quellen, die Auskunft über Schauspieler und Filme, die mit dieser Hauptentität in Verbindung stehen in Beziehung gesetzt werden. Das können z.B. verschiedene Schauspieler, die die Rolle James Bond besetzt haben sein oder Filme, in denen James Bond als Rolle mitgespielt hat.
Für die Gruppe der Filme in denen die Hauptfigur eine Rolle gespielt hat können dann in der Ausgabe durch Clips aus den Filmen, Soundtracks aus den Filmen und/oder andere geeignete Inhaltselemente ausgegeben werden. Generell können in Bezug auf die Hauptentität verschiedenste Formen von Content wie Videoinhalte, Audioinhalte, Fernsehprogramme, Filme, Live-Streaming-Inhalte, Hörbücher, Dokumente, Webseiten und/oder andere geeignete Arten von Inhalten gruppiert und ausgegeben werden.
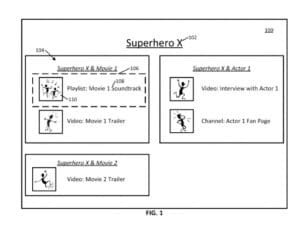
Zusätzlich oder alternativ können die Inhaltselemente Zusammenstellungen und/oder Aggregationen mehrerer Inhaltselemente sein. Das kann beispielsweise eine Wiedergabeliste von Inhaltselementen sein, die in einer bestimmten Reihenfolge präsentiert werden. In einigen Ausführungsformen kann das Inhaltselement auch ein Kanal mit Inhalten sein, die mit einem bestimmten Thema und/oder Inhaltsersteller verbunden sind. Dabei können Kommentare, Shares in sozialen Netzwerken oder die Popularität des Kanals Anhand der Anzahl an Abonnenten in eine Bewertung einfließen.
Als spezielleres Beispiel kann der Inhalt in Fällen, in denen die Eigenschaft einem bestimmten Schauspieler entspricht, einen Kanal enthalten, der einer Fan-Seite für den Schauspieler entspricht, die mehrere Inhaltselemente enthalten kann, die jeweils mit dem Schauspieler verbunden sind (z. B. Videos mit dem Schauspieler, Interviews mit dem Schauspieler und/oder andere geeignete Inhaltselemente). Diese Wiedergabelisten und/oder Kanäle können Inhalte enthalten kann, die von einer beliebigen geeigneten Person und/oder Gruppe zusammengestellt werden.
Entitäten können auch in bestimmte Themen-Kategorien eingeordnet werden, wie z. B. „Italienisches Essen“. Es können auch weitere Attribute oder Kategorien eingeschlossen werden, die mit dem Thema in Zusammenhang stehen. In dem speziellen Beispiel „Italienisches Essen“ können Kategorie-Gruppen wie Köche, die für italienisches Essen bekannt sind, bestimmte italienische Gerichte, Länder, die mit italienischem Essen in Verbindung gebracht werden, und/oder andere geeignete Eigenschaften mit berücksichtigt werden.
Welche Attribute für welchen Entitätstyp für den Nutzer relevant sind und wie Google das ermitteln kann haben ich in dem Beitrag Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest
Der Prozess für Identifikation und Bewertung der Beziehungen zwischen Entitäten, Themen und Kategorien
Ein Prozess für dir Identifikation, Gruppierung und Ausgabe basierend auf dem Thema und/oder einer Hauptentität kann wie folgt aussehen:
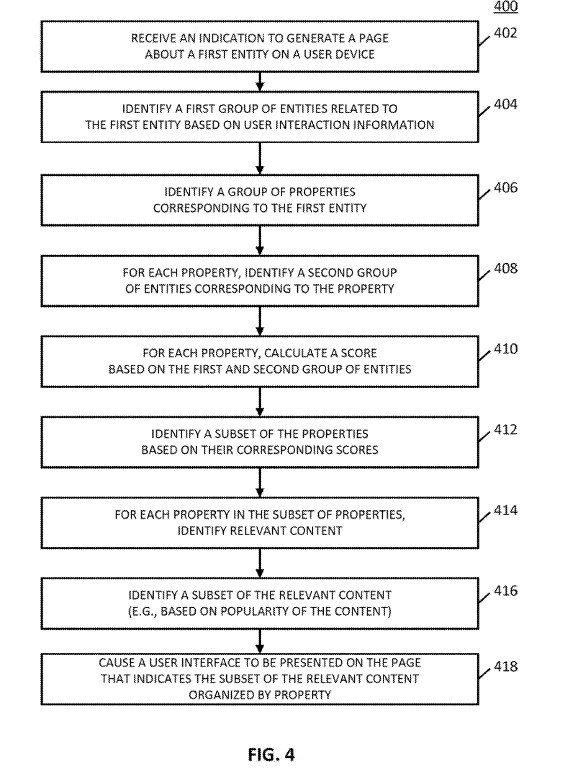
Der Prozess beginnt mit einer Suchanfrage zu einer Entität/Thema. Das System identifiziert eine erste Gruppe von Entitäten, die mit der Hauptentität in Beziehung stehen. (z. B. Namen von Medieninhalten, Namen von Schauspielern, Namen von Orten, Namen von Ereignissen und/oder andere geeignete Namen), Themen (z. B. Interessen, Hobbys und/oder jede andere geeignete Art von Themen) und/oder jede andere geeignete Art von Entitäten. Im Falle des obigen Beispiels des Superhelden können es auch Namen von Büchern, in denen die Figur erschienen ist, Namen von Filmen und/oder Fernsehsendungen, in denen die fiktive Figur dargestellt wurde, einen Namen eines Schöpfers der fiktiven Figur, Namen von Schauspielern, die die Figur in Fernsehsendungen und/oder Filmen dargestellt haben, Namen anderer Figuren, die mit der fiktiven Figur in Verbindung stehen … sein.
Nutzerverhalten zur Identifikation von Beziehungen
Für die Identifikation der Beziehungen zwischen einer Hauptentität und verwandten Neben-Entitäten können wie bereits erwähnt Nutzersignale einbezogen werden. Solche Nutzersignal können sogenannte Kookkurrenzen in Suchanfragen sein. Wird James Bond häufig zusammen mit bestimmten Themen oder Entitäten gesucht ist es ein Hinweis darauf, dass in der Ausgabe solche Nebenentitäten/Themen berücksichtigt werden sollten.
Im Beispiel James Bond können das z.B. Contents des Entitätstyps Film, Trailer, Darsteller … sein.
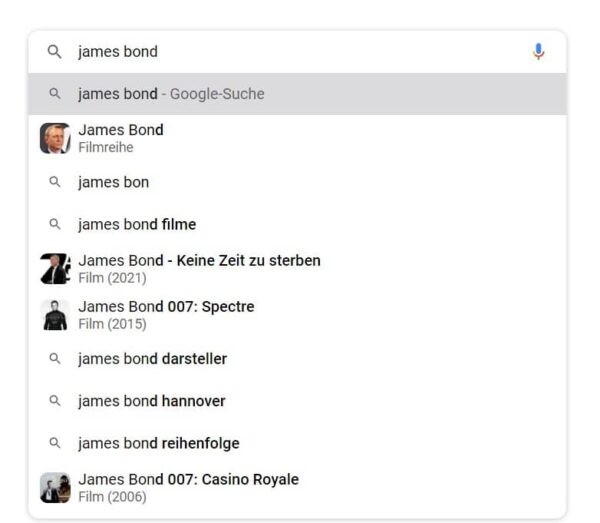
Diese Nutzerinteraktionen, die in Verbindung mit den Entitäten stehen können historisch gespeichert werden bis eine statistisch valide Anzahl an Beziehungsmustern erfasst worden sind. Je häufiger ein bestimmtes Muster an Nutzerverhalten auftaucht desto relevanter ist die Beziehung zwischen Entität und Thema.
- Je häufiger James Bond in Verbindung mit Film oder Darsteller gesucht wird, desto wichtiger scheinen diese Entitätstypen für das Hauptthema bzw. Hauptentität zu sein.
Für die Ausgabe favorisierte Medienformate
Ein zweites Kriterium kann das Medienformat sein, das von Nutzern in Bezug auf die Hauptentität gerne konsumiert werden. Z. B. bestimmte Webseiten, bestimmte Dokumente, bestimmte Videos, bestimmte Filme und/oder andere geeignete Arten von Inhalten, die häufig in Verbindung mit Inhalten angesehen werden, die mit dem ersten Thema oder der ersten Entität in Zusammenhang stehen. Werden bestimmte Medienformate in Verbindung mit der Hauptentität häufiger oder intensiver (Aufenthaltsdauer, Konsumdauer …) angesehen oder häufiger geteilt können diese als relevanter für die Nutzer bewertet werden.
Auch die Menge an bestimmten vorhandenen Medienformaten kann eine Rolle spielen welche als relevant für den Nutzer bewertet werden. Gibt es z.B. zu einer Hauptentität mehr Videos als Bilder oder Dokumente wird diesem Medienformat mehr Fokus bei der Auslieferung gegeben.
Die Nähe der Beziehung wird in einer semantischen Datenbank wie dem Knowledge Graph erfasst. Die relevantesten Entitätstypen bzw. Medienformate werden dann favorisiert in den Suchergebnissen präsentiert.
Kookkurrenzen in Dokumenten zur Identifikation von Beziehungen
Neben dem Nutzerverhalten n können Entitäten, die mit der ersten Entität in Beziehung stehen, auf der Grundlage von Schlüsselwörtern und/oder Metadaten in Dokumenten identifiziert werden, die ein Thema und/oder ein Genre angeben, das den Entitäten entspricht. Als spezielleres Beispiel können in Fällen, in denen die erste Entität ein Name einer fiktiven Figur ist, die Schlüsselwörter und/oder Metadaten ein Genre des Inhalts (z. B. Buch, Fernsehprogramm, Film und/oder ein anderer geeigneter Inhalt), in dem die Figur erscheint (z. B. Krimi, Action, Thriller und/oder ein anderes geeignetes Genre), einen Namen des Inhalts, in dem die Figur erscheint, einen Schöpfer des Inhalts, in dem die Figur erscheint, und/oder eine andere geeignete Information angeben. Die Schlüsselwörter und/oder Metadaten können dann verwendet werden, um andere Entitäten zu identifizieren, die mit ähnlichen Schlüsselwörtern und/oder Metadaten assoziiert sind (z. B. Charaktere, die mit demselben Inhaltsgenre assoziiert sind, Inhalte, in denen derselbe Charakter vorkommt, Inhalte, die von demselben Inhaltsersteller erstellt wurden …
- Je häufiger die Hauptentität im Zusammenhang mit bestimmten Entitätstypen genannt werden desto wichtiger scheinen diese Entitätstypen für das Hauptthema bzw. Hauptentität zu sein.
Die Nähe der Beziehung wird in einer semantischen Datenbank wie dem Knowledge Graph erfasst. Die relevantesten Entitätstypen werden dann favorisiert in den Suchergebnissen präsentiert.
(Semi-)Strukturierte Datenbanken zur Identifikation von Beziehungen
Eine dritte Möglichkeit ist die Identifikation von Beziehungen sind die hierarchischen Informationsstrukturen (semi-) strukturierter Datenbanken wie z.B. Wikipedia. Als spezielleres Beispiel können die strukturierten Daten in einem Fall, in dem das erste Thema oder die Hauptentität „italienisches Essen“ ist, „Essen/Küche/Köche“ (was anzeigt, dass „Köche“ eine Eigenschaft von „italienischem Essen“ ist), „Essen/Küche/Gerichte“ (was anzeigt, dass „Gerichte“ eine Eigenschaft von „italienischem Essen“ ist), „Essen/Küche/Herkunftsregion“ (was anzeigt, dass „Herkunftsregion“ eine Eigenschaft von „italienischem Essen“ ist) und/oder beliebige andere geeignete Daten umfassen. Mögliche weitere Quellen können spezielle Datenbanken wie z.B. Verzeichnisse in den Schauspieler und ihre Filme erfasst sind oder Kataloge, in denen z.B. Gerichte bestimmten Kategorien bereits manuell zugeordnet wurden. In Bezug auf das Beispiel „Italienisches Essen“ und eine Eigenschaft „Essen/Küche/Gerichte“ , können die strukturierten Daten angeben, dass die Entitäten, die mit „Essen/Küche/Gerichte“ korrespondieren, „Lasagne“, „Pizza“, „Gelato“ und/oder beliebige andere geeignete Elemente umfassen. Mehr zum Thema in dem Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?
Schlussfolgerung für die Praxis
Die Erkenntnisse aus dem Patent sind folgende:
Die in dem Patent beschriebenen Methoden und Prozesse zeigen auf, dass Google frei im Netz verfügbare Informationen Entitäten-basiert indexieren, kategorisieren und Beziehungen zwischen Entitäten identifizieren sowie bewerten möchte, um relevantere Suchergebnisse für den Nutzer auszuliefern. Mehr zu Entitäten-basierter Indexierung im Detail im Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index.
Wie bereits teilweise in diesem Blog thematisiert und im Detail beschrieben sind folgende Quellen hierfür wichtig:
- Nutzerverhalten in Form von wiederkehrenden Suchanfrage-Mustern
- Nutzerverhalten in Form von Mustern im Konsum bestimmter Medienformate
- Popularität in Form von Engagement durch Anzahl Abonnenten eines Kanals und Shares in Social Media
- Häufigkeit von Kookkurrenzen in Dokumenten
- Informationsstrukturen in (Semi-)strukturierten Datenbanken
So möchte Google die SERPs, je nach dem favorisierten Nutzer-Präferenzen je nach Hauptentität nutzbringende Ergebnisse präsentieren, die eine hohe Diversität an Medienformaten aufweisen. Dabei spielt die Beziehungsnähe zwischen den Inhalten, den Quellen und der Hauptentität eine entscheidende Rolle.
An den Suggest-Vorschlägen wird auch deutlich, dass die Entitäten-basierte Indexierung bei Google schon weit fortgeschritten ist, zumindest was die Short-Tail-Entitäten angeht. Alle Entitäten, die bereits offiziell im Knowledge Graph erfasst sind und dementsprechend einen Knowledge Panel besitzen werden per Suggest schon explizit vorgeschlagen.
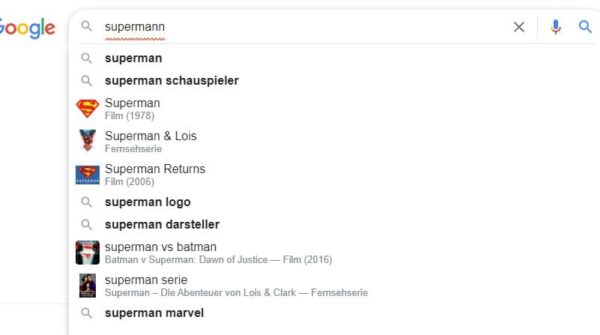
Google Auto Suggest zur Suchanfrage „supermann“
In dem Moment wenn es Google klar ist, dass sich bei einer Suchanfrage direkt um eine bekannte Entität dreht wird eine Entitäten-basierte Auslieferung der SERPs angestoßen zumindest was Universal Search Boxen, Knowledge Panel und Entitäten-nahe Domains und Wikipedia angeht. Dadurch verhindert Google auch, dass sich Entitäten fernere Quellen nach vorne schieben und Brand-Traffic abgreifen zumindest was die klassischen Suchergebnisse angeht.
Betrachtet man die aktuellen SERPs sind diese Tendenzen immer mehr zu erkennen. Hier einige Beispiele:
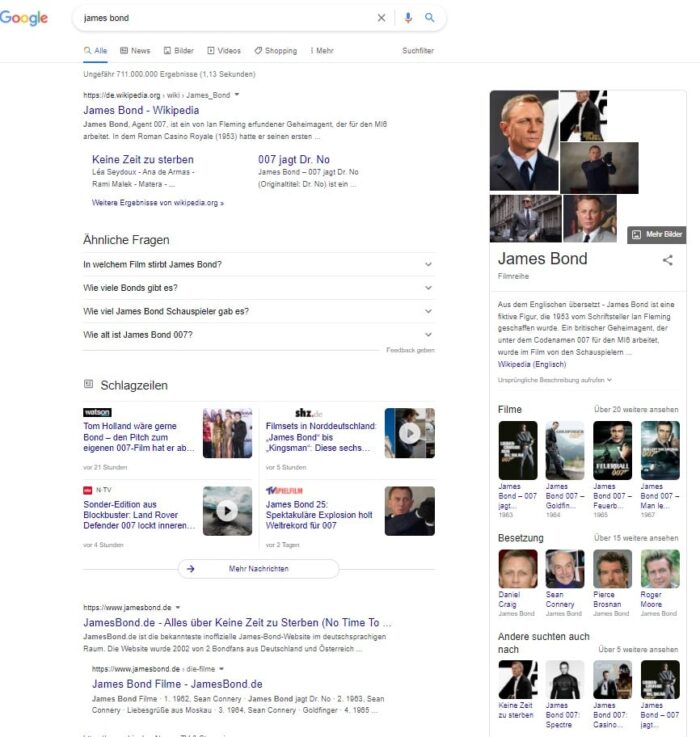
SERPs zu James Bond
Bei den SERPs zur Entität James Bond erkennt man folgendes:
- Wikipedia ist eine favorisierte Quelle zur Hauptentität
- Die Entiäten nahe Quelle jamesbond.de ist eine Entitäten nahe Quelle
- Nutzer wollen in Bezug zur Entität gerne News sehen
- Favorisierte Entitäten-Typen sind Darsteller (Besetzung), Filme …
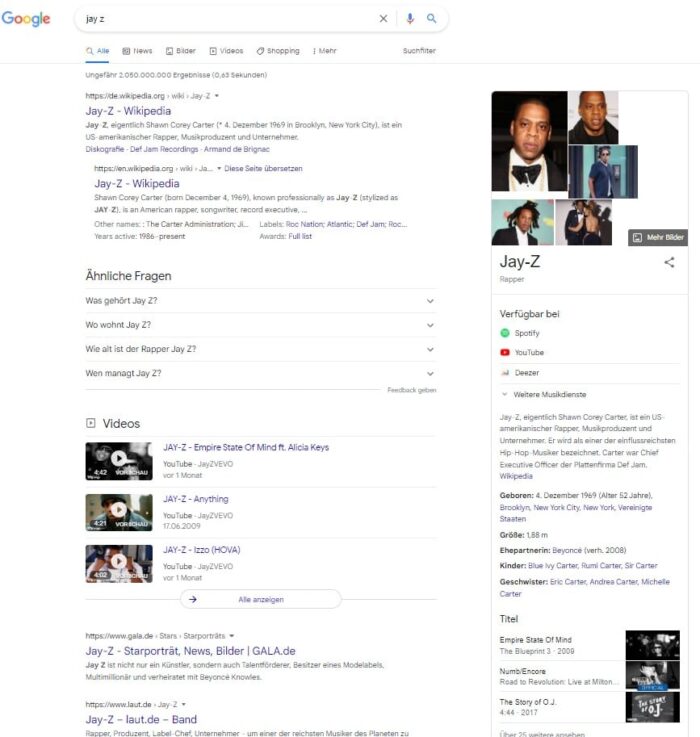
SERPs zu James Bond
Bei den SERPs zur Entität Jay-Z erkennt man folgendes:
- Wikipedia ist eine favorisierte Quelle zur Hauptentität
- Geburtsdatum, Größe, Ehepartnerin, Kinder, Geschwister sind für JAY-Z bzw. den Entitätstype Rapper für den Nutzer interessante Attribute
- Nutzer wollen in Bezug zur Entität gerne Videos sehen
- Favorisierte Entitäts-Typen bzw. Kategorien sind Musiktitel, Alben …
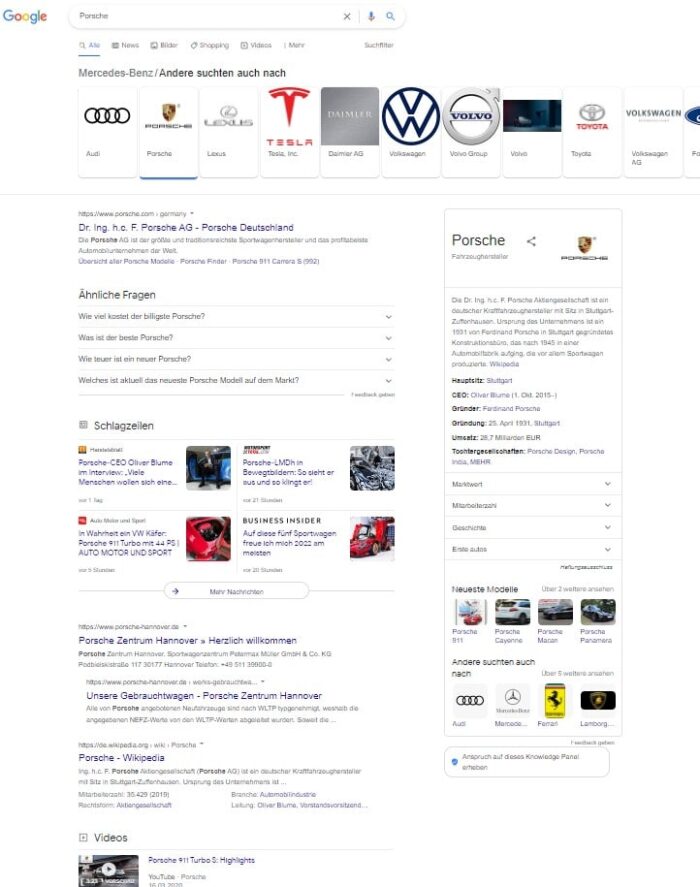
SERPs zu Porsche
Bei den SERPs zur Entität Jay-Z erkennt man folgendes:
- porsche.com, Wikipedia und im regionalen Kontext porsche-hannover.de sind favorisierte Quelle zur Hauptentität
- Hauptsitz, CEO, Gründer, Gründungsdatum, Umsatz, Tochtergesellschaften sind bei Porsche bzw. den Entitätstyp Fahrzeughersteller für den Nutzer interessante Attribute
- Nutzer wollen in Bezug zur Entität gerne Videos und News sehen
- Favorisierte Entitäts-Typen bzw. Kategorien sind Modelle
- Favorisierte Themen zu Porsche sind Marktwert, Geschichte, Mitarbeiterzahl, Erste Autos
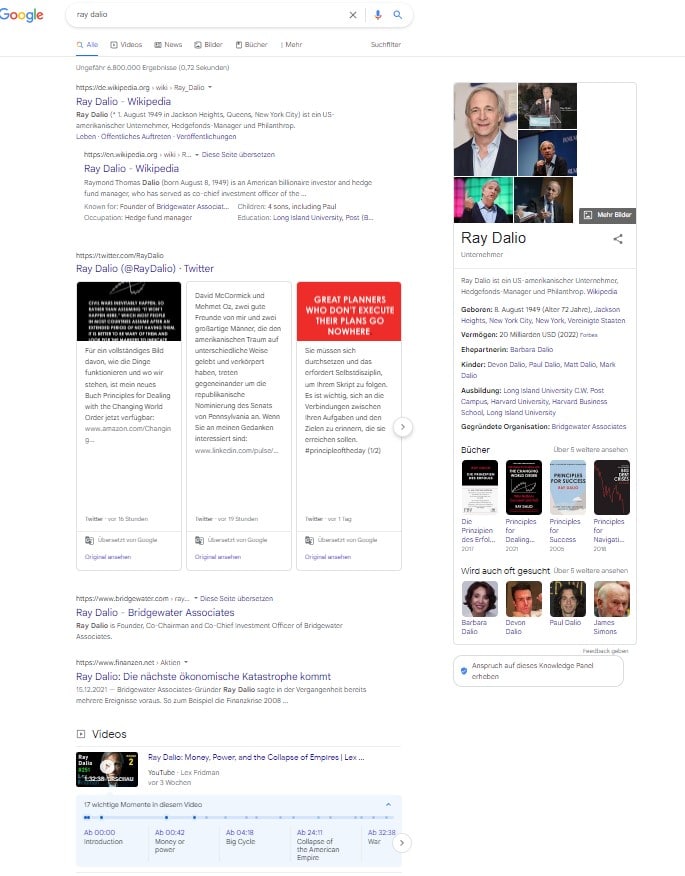
Bei den SERPs zur Entität Ray Diola erkennt man folgendes:
- Wikipedia und bridgewater.com sind favorisierte Quelle zur Hauptentität
- Geburtsdatum, Vermögen, Ehepartnerin, Ausbildung, Kinder, gegründete Organisationen sind für Ray Diola Porsche bzw. den Entitätstyp Unternehmer für den Nutzer interessante Attribute
- Nutzer wollen in Bezug zur Entität gerne Videos und News sehen
- Favorisierter Entitäts-Typ bzw. Kategorie ist Bücher
- Der Twitter-Kanal von Ray Diola scheint bei Nutzern in dem Kontext sehr populär zu sein
Mehr zur Gestaltung von Knowledge Panels im Beitrag Wie erstellt Google Knowledge Panel & Knowledge Cards? und zu SERP-Analysen im Beitrag SERP-Analysen für die nutzerzentrierte Content-Konzeption.
Durch die Fokussierung auf mehr Mediendiversität in den SERPs durch die im Patent beschrieben Prozesse lässt sich eine Verbindung zu MUM ableiten.
Die spannende Frage bleibt inwiefern sich die Entitäten-basierte Suche auch schon auf die restlichen Quellen und Dokumente auswirkt. Ich gehe davon aus, dass Google hier Entitäten-basierte Suche und klassisches Information Retrieval für Suchanfragen-Dokumenten-Matching parallel verwendet. Über die Verknüpfung der Entitäten mit bestimmten Quellen und die Möglichkeiten die Beziehungsnähe zu Themen zu ermitteln lässt sich auch umgekehrt eine Relevanz von Themen zu Entitäten ermitteln, was dann mit Blick auf E-A-T zum Zuge kommen kann. Dazu aber in anderen Beiträgen hier im Blog mehr dazu.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.