
Im Juni 2021 hat Google ein interessantes Patent veröffentlicht, in dem ein Konzept vorgestellt wird wie eine Suchmaschine Medieninhalte rund um Haupt- und verwandten Medien-Entitäten in einem Index organisieren kann. Das Patent führt die Ansätze weiter, die ich bereits im Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index beschrieben habe. In dem Patent geht es weniger um Ranking, viel mehr um die Organisation von Inhalten.
Inhaltsverzeichnis
Was ist ein Entitäten-basierter Index?
Bevor ich auf die im Patent beschriebenen Prozess der Organisation von Inhalten rund um Entitäten genauer eingehe möchte ich kurz beschreiben, was ein Entitäten-basierter Index überhaupt ist.
Im klassischen Information-Retrieval bzw. Document Retrieval werden Inhalte in thematische Cluster eingeordnet u.a. basierend darauf welche Begriffe in den Inhalten / Dokumenten genutzt werden. Bei bestimmten zum jeweiligen Cluster passenden Suchanfragen werden dann die im Dokumenten-Korpus zusammengefassten Dokumente für ein nachfolgendes Scoring in Betracht gezogen, woraus sich ein Ranking ableiten lässt.
In der semantischen Suche stehen Entitäten an oberster Stelle in der Hierarchie der Organisationsstruktur. Der große Vorteil an einer solchen Index-Organisation ist, dass Google und andere semantische Suchmaschinen neben Attributen, Dokumenten auch weitere Medien-Inhalte wie Bilder, Videos, Audios … rund um alle verwandten Entitäten semantisch einsortieren können.
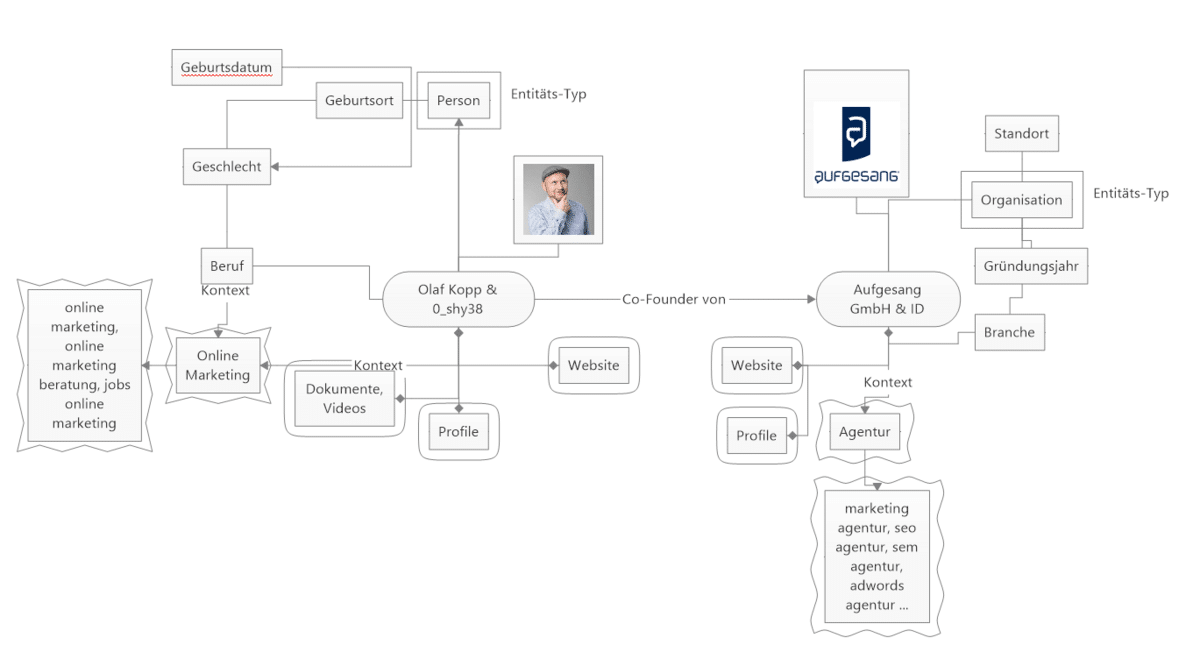
Beispien für den Aufbau eines Entitäten basierten Index, © Olaf Kopp
So können dem Nutzer, der eine Entitäten-relevante Suchanfrage ausführt bei Bedarf weiterführende Inhalte auch zu verwandten Entitäten angezeigt werden.
Prozess für die Organisation Entitäten-relevanter Medien
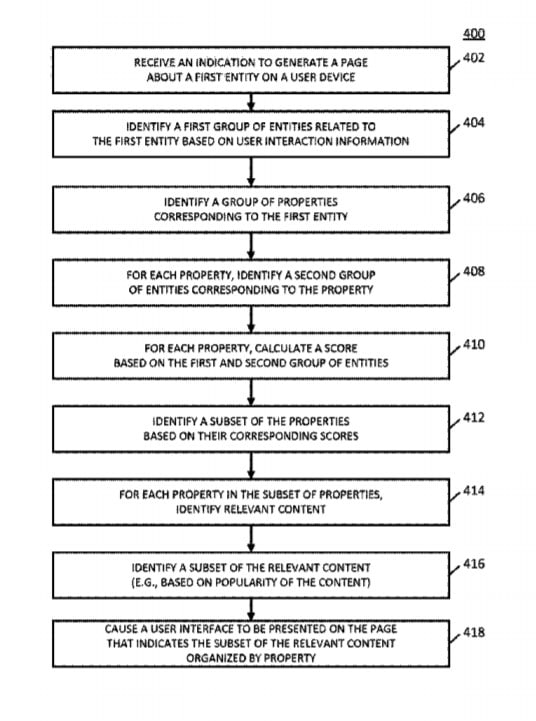
Im besprochenen Google-Patent Methods, systems, and media for presenting content organized by category wird beschrieben wie ein Prozess aussehen kann, um Inhalte bzw. Medien in einem Entitäten-basierten Index einer Kategorie zuzuordnen.
Folgende Schritte werden aufgeführt:
- Eine Suchmaschine erhält eine Suchanfrage für eine Seite mit Inhalten über eine Haupt-Entität.
- Eine erste Gruppe verwandter Entitäten wird basierend auf Suchverhalten des Nutzers identifiziert.
- Eine Reihe von Eigenschaften bezüglich der Haupt-Entität werden identifiziert.
- Für jede dieser Eigenschaften wird eine zweite Gruppe von Neben-Entitäten identifiziert.
- Jede dieser Eigenschaften erhält eine Bewertung, die teilweise auf der Gruppe von verwandten Entitäten (basierend auf den Suchverhalten des Nutzers identifiziert) und der zweiten Gruppe von Neben-Entitäten für die Eigenschaft basiert. Die Bewertungs-Punktzahl gibt die Wahrscheinlichkeit an, dass ein Suchender an Inhalten zu der jeweiligen Entität interessiert ist.
- Die Suchmaschine bestimmt eine Teilmenge aus der Gruppe von Eigenschaften basierend auf der Bewertung je Nutzer.
- Eine Teilmenge von Inhaltselementen aus der Gruppe von Inhaltselementen wird bestimmt.
- Die Inhaltselemente werden auf dem Endgerät des Nutzers angezeigt.
Die Zuordnung von Medien-Inhalten zu Kategorien und/oder Entitäten kann z.B. über die im Titel eines Videos oder Text rund um ein Bild oder im Alt-Attribut genannten Entitäten geschehen. In der Google-Bilder-Suche finden wir solche Kategorisierungen bereits.
Medien-Klassifizierung in der Google-Bilder-Suche bei der Suchanfrage „olaf kopp“
Welche Inhaltselemente bzw. Medientypen für ein bestimmtes Thema bzw. Entität auszuwählen ist könnte die Suchmaschine u.a. auf dem individuell präferierten Medien-Inhalten des Nutzers und/oder der allgemeinen Beliebtheit bezogen auf die Entitäten bewerten. Das ist ein ähnlicher Vorgang wie Google die anzuzeigenden Attribut-Wert-Paare im Knowledge Panel auswählen könnte (siehe dazu den Beitrag Wie erstellt Google Knowledge Panel & Knowledge Cards? ).
Über einen Knowledge Graph lassen sich über diesen Prozess Inhalte nicht nur einer Entität und/oder Kategorie zuordnen, sondern es können Querverbindungen zu allen weiteren verwandten Entitäten hergestellt werden.
Neben den allgemeinen Informationen könnte auch eine individuelle Ausspielung von Medien-Inhalten basierend auf dem Suchverhalten des Nutzers erfolgen. Hier könnte sich Google z.B. auf folgende Faktoren beziehen:
- Suchanfragen eines Nutzers
- Inhalte, die der Nutzer normalerweise in derselben Sitzung nutzt
- Weitere Arten von Suchverhalten
Darüber würde sich dann auch eine individuelle Ausgabe in einer Recommendation Engine wie Google Discover nutzerspezifisch umsetzen lassen.
Anwendungsbeispiele
Wenn die Haupt-Entität beispielsweise eine fiktive Figur ist, kann die Gruppe von Inhalten Folgendes umfassen:
- Filme, in denen die fiktive Figur dargestellt wurde.
- Schauspieler, die die fiktive Figur dargestellt haben.
- Andere geeignete Eigenschaften.
- Eine Gruppe von verwandten Entitäten
- die der Eigenschaft von Filmen entsprechen
- in denen die fiktive Figur dargestellt wurde
- die Namen jedes Films enthalten.
Darüber können dann Inhaltselemente identifiziert werde, die sich auf die Entitäten in der Gruppe verwandter Entitäten beziehen.
Mögliche Inhalts-Elemente und Medien-Formate
In Fällen, in denen die Entitäten in der Gruppe bekannter Entitäten beispielsweise Namen von Filmen enthalten, in denen die fiktive Figur dargestellt wurde, können die Inhaltselemente Folgendes umfassen:
- Ausschnitte aus den Filmen
- Soundtracks aus den Filmen
- Andere geeignete Inhaltselemente
- Eine Suchmaschine kann Eigenschaften identifizieren, die mit der ersten Entität verbunden sind
Beispielsweise kann eine Kandidatengruppe aus Eigenschaften identifiziert werden. Eine Teilmenge der Kandidatengruppe von Eigenschaften kann basierend darauf identifiziert werden, wie relevant jede Eigenschaft für die Haupt-Entität ist, was darauf basiert, wie interessant jede Eigenschaft wahrscheinlich für einen Suchenden ist (s.o.)
In einem anderen Beispiel, in dem die Haupt-Entität eine fiktive Figur ist, kann die Kandidatengruppe von Eigenschaften / verwandte Entitäten umfassen:
- Filme, in denen der Charakter porträtiert wurde
- Schauspieler, die den Charakter dargestellt haben
- Ein fiktiver Geburtstag des Charakters
Medienformate, die in einem solchen Prozess berücksichtigt werden können:
- Videoinhalte
- Audioinhalte
- Fernsehprogramm
- Filme
- Live-Streaming-Inhalte
- Hörbücher
- Unterlagen
- Webseiten
- …
Aus den Inhalts-Elementen und Medienformaten könnten zusätzlich Zusammenstellungen und/oder Aggregationen erzeugt werden.
Auch eine Wiedergabeliste zu einer Entität oder Themen-Kategorie, die die verschiedenen Inhalte in einer bestimmten Reihenfolge präsentiert wäre möglich.
Fazit: Google entwickelt sich immer weiter zu einer Wissens-Plattform nicht nur für Suchende
Dieses Patent zeigt deutlich in welche Richtung Google sich entwickeln möchte. Eine Verschmelzung aus Recommendation Engine und Suche. Derzeit gibt es eine klare Trennung von Google Discover und der Google Suche. Diese Grenzen könnten zukünftig immer mehr verschwimmen. Auch die Entwicklung zu einem Entity-First Index wird durch solche Patente sehr deutlich.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.