
Dies ist ein Gastartikel von Patrick Mebus.
Arbeiten im Online-Marketing ohne Tools wie Automated Bidding, Affinity-Targeting oder Responsive Search Ads. Nur schwer vorstellbar oder? Sie alle sind fester Bestandteil unseres Büro-Alltages. Und Sie alle basieren auf Maschinellem Lernen. Das Problem hierbei: Als Account-Manager sitzen wir oft vor einer Black-Box. Wertvolles Wissen über den User, sein Verhalten und Interesse verbleiben auf den Servern von Google und Facebook. In-Market-Audiences beispielsweise werden als fertiges Marketing-Segment bereit gestellt. Die Hintergründe und Berechnungen dieser Zuordnungen bleiben verborgen. Dabei ist es genau dieses Wissen, welches über langfristigen Erfolg und Misserfolg im Marketing entscheidet. Mit Owned Machine Learning, selber implementierten und trainierten Algorithmen, können sich Unternehmen dieses Wissen in kurzer Zeit selbst aus großen Datenmengen ziehen und zu Nutze machen. Dieser Artikel soll zeigen, wie Machine Learning grundsätzlich funktioniert, wieso es für den langfristigen Unternehmenserfolg notwendig ist und wie wir dieses Werkzeug sinnvoll in unser Online Marketing integrieren können.
Dieser Beitrag beschäftigt sich im Fokus mit dem Einsatz von Machine Learning in SEA, Facebook-Werbung und Paid Avdvertising. Als Ergänzung dazu der Beitrag Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google
Inhaltsverzeichnis
- 1 Was ist überhaupt Machine Learning?
- 2 Machine Learning Potentiale im Online-Marketing
- 3 Überwachtes vs. Unüberwachtes Maschinelles Lernen
- 4 So lernt eine Maschine: Fehler ausdrücklich erwünscht
- 5 Wieso Owned Machine Learning im Online Marketing heute existenziell ist
- 6 First Party Daten sollten nicht brach herumliegen
- 7 Online Marketing Implementierung: Owned Machine Learning im Einsatz
- 8 Welcher Algorithmus für welches Marketing-Problem nützlich ist
- 9 Fazit
Was ist überhaupt Machine Learning?
„What we want is a Machine that can learn from experience“- Alan Turing (Mathematiker, IT-Pionier)
Maschinelles Lernen (im englischen ‚Machine Learning‘) ist einer von vielen Teilbereichen der Künstlichen Intelligenz. Nach der gängigen Definition des amerikanischen Informatikers Tom Mitchell besteht der Grundgedanke von Machine Learning darin, dass ein Computer-Programm seine Performance durch neu gemachte Erfahrungen (Daten) in einem bestimmten Bereich automatisch verbessert. Der Vorteil dabei: Das Programm muss nicht mit tausenden Zeilen an Code permanent neu programmiert werden. Unterschiedlichste mathematische Algorithmen sorgen für eine automatische Verarbeitung der Daten und somit für den Lernprozess.
Machine Learning ist einer von vielen Bereichen der Künstlichen Intelligenz
Die wohl bekanntesten Beispiele für Machine Learning Implementierungen dürften die Empfehlungssysteme sein, die bei Amazon und Netflix zum Einsatz kommen. Online-Shopping und Video-Streaming, wie wir es heute kennen, wären ohne Algorithmen und ohne die Verarbeitung von Nutzerdaten nicht möglich.
Auch selbstfahrende Autos oder Social Media Feeds würden ohne Künstliche Intelligenz nicht existieren. Derzeit rettet Machine Learning im Zuge der Corona-Epidemie womöglich viele Menschenleben, da Wissenschaftlicher und Virologen mit Hilfe der Algorithmen Vorhersagen über die Ausbreitung machen können.

Ohne Machine Learning wären Amazons Empfehlungen nicht so zielgenau und effektiv
Durch das Zusammenspiel aus Big-Data und einem sich stetig vergrößerndem Maß an CPU-Rechenpower wurde es in den vergangenen Jahrzehnten natürlich auch im Online-Marketing zunehmend möglich, Modelle mit Daten zu trainieren und diese „lernen“ zu lassen. Mittlerweile sind Algorithmen ein fester Bestandteil im digitalen Tagesgeschäft der meisten Marketers. Google und Facebook haben diese Entwicklung maßgeblich vorangetrieben. Beide machen jeweils mehr als 85% ihres Umsatzes mit Online-Advertising und konnten gerade im Bereich der Deep Learning Implementierung in den 2010er-Jahren große Fortschritte verzeichnen.
Ein viel beachteter Artikel über Googles wegweisende Entscheidung, das komplette Unternehmen rund um Künstliche Intelligenz und Machine Learning herum zu organisieren, war das NY-Times Feature von Gideon Lewis-Kraus aus dem November 2016: https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html

The Great A.I. Awakening, Quelle: New York Times
Machine Learning Potentiale im Online-Marketing
„Accuracy is, in every case, advantageous to beauty“- David Hume (Philosoph)
Leider sind wir Menschen kognitiv generell sehr schlecht darin, Muster in großen Datenmengen (wie beispielsweise Marketing-Reports) zu erkennen. Noch problematischer wird es, wenn aus diesen Datenmengen auch noch Rückschlüsse und Learnings für zukünftiges Handeln gezogen werden sollen. Jeder von uns verfügt über einen individuellen Erfahrungsschatz, der unsere Vorstellungen, Werte und unsere Weltanschauung prägt. Diese „kognitive Bias“ bei einer Analyse komplett auszuschalten ist nicht immer möglich. Wenn ich auf Basis meiner Marketingerfahrung davon ausgehe, dass die Zielgruppe Männlich 50+ tendenziell positiver auf die Werbung für einen neuen Sportwagen reagiert, werde ich diese Muster vermutlich auch im Analyse-Datensatz der Kampagne wiedererkennen und andere – womöglich viel relevantere Fakten – ignorieren.
Von Ablenkungen im Büro, von Müdigkeit und von Hunger, welche uns Menschen zu Fehlern verleiten, wollen wir gar nicht erst reden.

Durch Erfahrungen verfestigte Voreingenommenheit, Bias genannt, prägt unsere Entscheidungen
Alle diese Befindlichkeiten kennt ein Machine Learning Modell nicht, womit die Vorteile von ML-Anwendungen im Online Marketing auf der Hand liegen. Durch die Reduzierung menschlicher Befangenheit und Voreingenommenheit, werden businessrelevante Entscheidungen verstärkt auf Basis von Daten getroffen.
Zudem können Prozesse durch die Rechenpower der Computer enorm beschleunigt und digitale Werbemaßnahmen, wie beispielsweise Kampagnen im Search Advertising bzw. Suchmaschinenwerbung automatisiert werden. Das Ergebnis sind eine sehr viel höhere Effektivität und eine Reduzierung von Marketingkosten.
Natürlich ist Machine Learning auch im Online-Marketing kein Wundermittel. Vielmehr sollte es als potentielles – jedoch überaus kraftvolles – Tool in die bestehende Strategie und Marketing-Maßnahmen eingebettet werden und diese ergänzen.
Und auch nicht immer ist Machine Learning die optimale Lösung für ein Marketing-Problem. Beispielsweise, wenn eindeutig zu wenige Daten vorliegen, die der Algorithmus verarbeiten könnte. Hier muss zwischen verschiedenen Lösungsansätzen abgewägt werden. Der Auspruch „Wer als Werkzeug nur einen Hammer hat, sieht in jedem Problem einen Nagel“ beschreibt dies ziemlich gut.
Einen kompakten Überblick über die Mythen und Realitäten von Machine Learning im Digitalen Marketing gab Catherine Williams, Chief Data Scientiest bei AT &T, im vergangenenen Sommer: https://www.youtube.com/watch?v=kVxNRigNlZg
Überwachtes vs. Unüberwachtes Maschinelles Lernen
Im Bereich des Maschinellen Lernens wird grundsätzlich in drei verschiedene Kategorien unterschieden:
- Im Überwachten (Supervised) Lernen werden auf Basis von strukturierten, historischen Eingabe- und Ergebnis-Daten (z.B. User Daten und Conversions) Rückschlüsse und Vorhersagen über zukünftige Ereignisse gemacht. Der Ausgabewert fungiert dabei stets als abhängiges „Label“ in Korrelation zu den unabhängigen Eingabe-Variablen.
Es wird geschätzt, dass sich derzeit noch etwa 70% aller Machine Learning Anwendungen in diesem gut erforschten Bereich wiederfinden. Typische Supervised ML-Anwendungen im Marketing sind etwa der datengetriebene Revenue-Forecast oder die Einteilung von Kundengruppen in vordefinierte Segmente und Klassen (Klassifizierung).
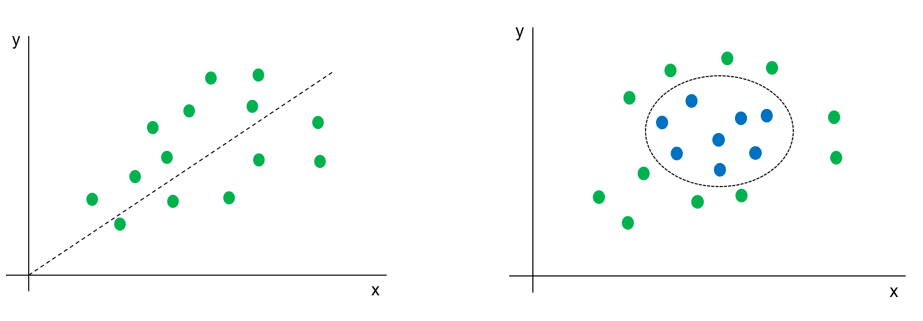
Zwei typische ‚Supervised’ Machine Learning Probleme: Regression und Klassifizierung
- Dem gegenüber steht das Unüberwachte (Unsupervised) Lernen. Diese Algorithmen und Modelle dienen der Mustererkennung in großen Datenmengen ohne vordefinierte Abhängigkeit oder Korrelation. Im Online Marketing ist dies beispielsweise nützlich, um Website-Besucher akkurat in unterschiedliche noch-nicht definierte Gruppen einzuteilen, um diese anschließend mit einer auf sie zugeschnittenen Werbebotschaft anzusprechen (Clustering).
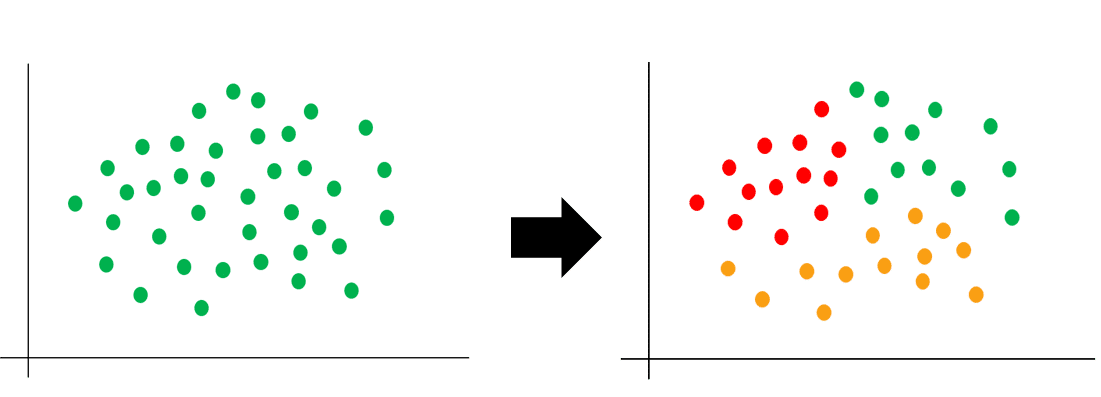
Unsupervised Algorithmen erkennen zuverlässig Muster in großen Datenmengen
- Im Bestärkenden (Reinforcement) Lernen, erfolgt der Lernprozess der Maschine durch Interaktion mit einer in der Regel vordefinierten Umwelt. Positives Verhalten wird belohnt und das System somit bestärkt, zukünftig erneut so zu handeln. Viele dieser Anwendungen und Entwicklungen finden sich derzeit in den Bereichen Gaming und Robotik wieder.
Die Herausforderung im Supervised Learning besteht vor allem im Data-Preprocessing und darin bereits im Vorfeld die richtigen Fragen zu stellen, welche das System erlernen soll. Das Modell kann nur die Tasks und Probleme lösen, die wir ihm beibringen und nur die Korrelationen verstehen, die wir vordefinieren. Dementsprechend spielt die menschliche Bias hier eine größere Rolle als im Unsupervised Learning. Ein Problem, welchem sich derzeit unter anderem Teams bei Google widmen: https://arxiv.org/pdf/1912.02783.pdf
Bereits vor dem Lernprozess kann dafür gesorgt werden, dass das Modell weniger Rechenkapazität benötigt und so schneller solide Ergebnisse liefert. Stellschrauben sind hier zum Beispiel das Entfernen unnötiger Spalten (Etwa die Currency Spalte in Keyword-Reports) und das Label-Encoding von Strings (Textbausteinen, wie zum Beispiel Keywords oder Locations), also die Umwandlung in numerische Werte, welche vom System leichter interpretiert werden können.
Durch die Visualisierung der Daten vor dem eigentlichen Training, beispielsweise durch Histogramme oder Streudiagramme, können wir uns schon im Vorfeld einen Überblick darüber verschaffen, ob wir ausreichend Daten im Set haben, von denen die Maschine lernen kann. Auf diese Weise können wir schon frühzeitig die Qualität der Aussagekraft unseres Modells in die richtige Bahn lenken und Phänomene wie Überanpassung (Overfitting) und Unteranpassung (Underfitting) vermeiden.
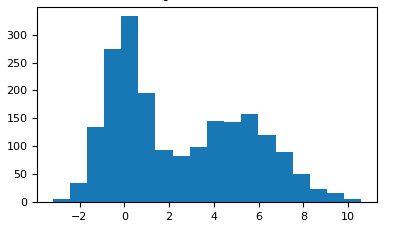
Mit Histogrammen können bereits erste grobe Hypothesen zum Modell erstellt werden
So lernt eine Maschine: Fehler ausdrücklich erwünscht
„The beautiful thing about learning is nobody can take it away from you“- B.B. King (Blues-Legende)
In den 1930er Jahren machte der Schweizer Psychologe Jean Piaget bei seinem Nachwuchs eine interessante Entdeckung. Zwar machten die – noch sehr kleinen – Kinder schnelle Lern- und Sinnesfortschritte, wenn sie mit ihrer Umwelt interagierten. Sie wendeten das Erfahrungs-Wissen auf neue Situationen an, um diese zu erfassen.
Ihre sich bereits verfestigten ersten Vorstellungen von der Welt wurden jedoch zunächst nur sehr langsam durch neue Informationen verändert oder ersetzt. „Geupdated“ würden wir heute sagen.
War eines der Kinder beispielsweise bereits mit dem Schema eines Hundes vertraut und begegnete dann zum ersten Mal einer Katze, handelte es sich in dessen Augen ebenfalls um einen Hund, da dieses Tier auf vier Beinen läuft und ein Fell hat. Erst zusätzliche Erfahrungen durch häufigere Aufeinandertreffen mit der Katze, führten dazu, dass das Kind die Katze anhand verschiedener Kriterien vom Hund unterscheiden konnte.
Piaget bezeichnete dies als Assimilation (Wissen wird aufgenommen durch Erfahrung) und Akkommodation (Wissen wird verändert und ersetzt).
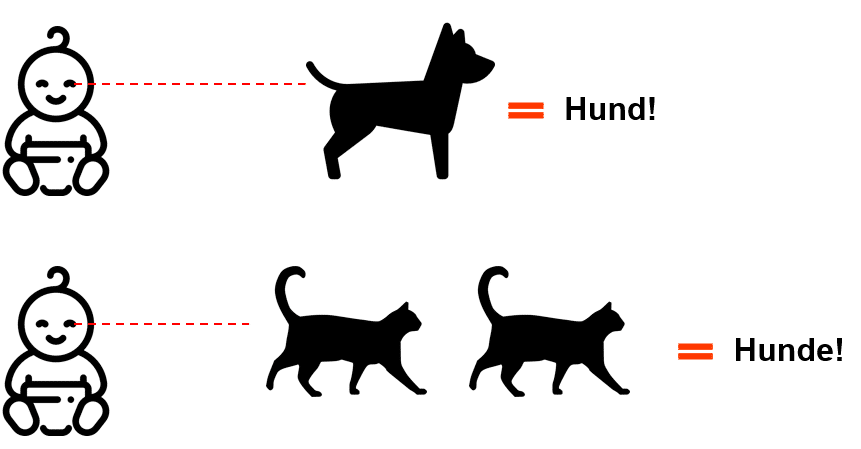
Assimilation und fehlgeschlagene Akkommodation beim Menschen
Interessanterweise ist der maschinelle Lernprozess gar nicht so unterschiedlich zu dem, welchen wir als Kinder durchlaufen. In der Tat tauchen in den wissenschaftlichen Veröffentlichungen recht häufig Vergleiche von untrainierten Maschinen mit kleinen Kindern auf.
Was beide gemein haben, ist ein relativ überschaubarer bis nicht vorhandener Schatz an Erfahrung. Daten auf denen Schlussfolgerungen gemacht werden könnten, sind zunächst nur spärlich bis nicht vorhanden.
So würde auch eine Maschine mit überschaubarer Datenmenge mit großer Zuversicht zunächst Katzen als Hunde klassifizieren. Nur dass die Maschine die Tiere als Spalten und Reihen von Daten sieht und die Schlussfolgerung durch Kalkulation und Algorithmen macht. Mit zunehmender Erfahrung, durch weitere Datenzufuhr und zusätzliche Informationen über Katzen, würde sich die Fähigkeit, beide Tiere zuverlässig voneinander zu unterscheiden, erheblich verbessern.

Assimilation und fehlgeschlagene Akkommodation der Maschine
Der Lernprozess eines Machine Learning Modells durchläuft dabei stets vier Schritte. Dieser Prozess findet sich in allen ML-Modellen und Anwendungen wieder; vom Social Media Feed bis zum selbstfahrenden Auto.
- Datenaufnahme/Hypothese (Assimilation)
- Fehler Berechnung
- Paramater Updates/Fehler Minimierung (Akkommodation)
- Evaluation
Zunächst wird auf Basis der vorhandenen Daten eine Hypothese berechnet, welche die vorhandenen Beobachtungen möglichst gut beschreiben sollte. Meist gibt es dabei Abweichungen , welche im zweiten Schritt mit Hilfe einer Error-Funktion kalkuliert werden.
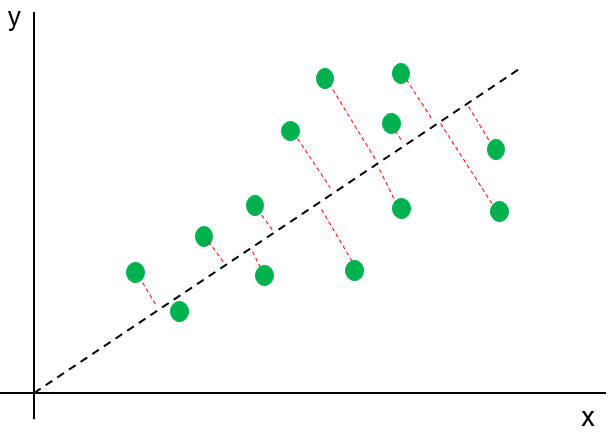
Hypothese und Fehlerkalkulation (rote Linien) im Linearen Modell
Das eigentliche Lernen erfolgt dann in Schritt Nummer drei, in dem die kalkulierten Fehler so lange minimiert werden, bis ein optimaler Wert erreicht ist. Ein vierter Schritt beschränkt sich auf den Bereich Supervised Learning wo uns der Output bereits bekannt ist. Durch den Split in ein Trainings- und ein Testdatenset können wir unser Modell hier mit Hilfe ihm bisher unbekannter Daten evaluieren.
Eine ausführliche Beschreibung des Machine Learning Prozesses liefert der Machine Learning Crash-Kurs von Google: https://developers.google.com/machine-learning/crash-course/reducing-loss/an-iterative-approach
Was aus diesem Prozess abgeleitet werden kann, ist die Schlussfolgerung, dass ein Machine Learning Modell exakter und akkurater ist, je mehr Erfahrung es hat. Sprich: je mehr Trainingsdaten zur Verfügung stehen desto genauer wird die Vorhersage. Gigantische Datenmengen mit positiven und negativen Daten werden benötigt. Darin besteht der große Wettbewerbsvorteil der Tech Firmen wie Google und Facebook. Da nicht davon auszugehen ist, dass diese ihr Wissen und ihre Daten irgendwann mit uns teilen werden (auch wenn von Seiten der Politik darauf gepocht wird), müssen wir als Unternehmen selber zur Tat schreiten.
Wieso Owned Machine Learning im Online Marketing heute existenziell ist
„The aim of marketing is to know and understand the customer so well the product or service fits him and sells itself“- Peter Drucker (Ökonom)
Die Machine Learning Tools von Google und Facebook haben unser Arbeiten im Online Marketing grundlegend revolutioniert. Werbebotschaften können heute schneller und effektiver an den richtigen User zur richtigen Zeit am richtigen Ort ausgespielt werden als jemals zuvor. Der Preis den wir als Marketers für die gewonnene Effektivität zahlen, sind jedoch ein erhöhtes Maß an Abhängigkeit und Intransparenz. Wir schieben Daten in Smartbidding-Black-Boxes und hoffen auf das Beste. Häufig ist das Resultat zufriedenstellend, so dass im nächsten Reporting ausreichend Conversions verzeichnet werden können.
Wie diese letzten Endes zustande gekommen sind, entzieht sich jedoch unserem Blickwinkel. Aber gerade hier liegt der eigentliche Wert. Wenn wir als Unternehmen langfristig erfolgreich sein wollen, benötigen wir genau diese Informationen. Zielgruppenwissen ist bekanntlich Macht im Marketing. Wer weiß, welcher Trigger für welche Zielgruppe am effektivsten ist, kann seine Ressourcen effektiv auf diesen konzentrieren.
Zwar bietet beispielsweise Google seit einiger Zeit einen so genannten „Bid Strategy Report“ an, erwähnt jedoch auch, dass es sich bei den gezeigten „Top Signals“ nur um Beispiele handelt. Informationen zur Gewichtung der Variablen untereinander gibt es keine. Welchen Stellenwert beispielsweise das User-Signal Mobile Device gegenüber einem bestimmten Wochentag oder einem bestimmten Interessen auf die Conversion-Wahrscheinlichkeit haben, sehen wir nicht.
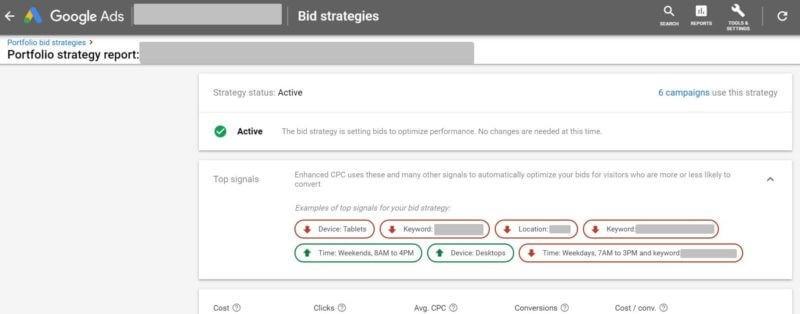
Bid-Strategy report in Google Ads, Quelle: searchengineland.com
Ein wenig fühlt es sich so an, wie die Fahrt mit einem selbstfahrenden Auto, welches uns nicht über die geplante Route in Kenntnis setzt. Wir lehnen uns zurück und kümmern uns nicht mehr darum, Wissen über den optimalen Weg in unserem Gehirn zu speichern.
Doch eines Tages fällt der Autopilot aus und wir müssen doch wieder ans Steuer. Die Straßenführung hat sich mittlerweile verändert. Was nun? Die schnellste und effektivste Strecke zum Ziel ist uns nicht mehr bekannt.
Was, wenn Google oder Facebook übermorgen den Stecker ziehen (oder gezogen bekommen).
- Könnten wir dann noch sagen, welche Variablen die größte Hebelwirkung auf unsere wertvollste Zielgruppe haben?
- Könnten wir noch fundiert und datengetrieben sagen, welche Zielgruppe überhaupt die für uns wertvollste ist?
Hier lohnt es sich anzusetzen und mit eigenen Machine Learning Modellen bereits im Vorfeld eines Kampagnen-Launches umsatzstarke Zielgruppen und Hebelwirkungen ausfindig zu machen.
Unser größter Trumpf als Account-Manager ist dabei wenig überraschend das, was Google & Co am meisten begehren.
First Party Daten sollten nicht brach herumliegen
„More data beats clever algorithms, but better data beats more data “- Peter Norvig (Director of Research, Google)
Die eigentliche Macht beim Maschinellen Lernen liegt in den Daten. Wer die meisten Daten hat, gewinnt immer, richtig? Nicht ganz.
Denn auch die Qualität der Daten ist von entscheidender Bedeutung. Es ist keine Überraschung, dass CRM-Integration-Tools wie ‚Customer Match’ von den Big Techs so stark angepriesen werden. Die Ad-Companies wissen um die Relevanz und Kostbarkeit direkter Kundendaten.
Denn das, was wir im Online Marketing letzten Endes wollen, sind neue Nutzer, die unseren tatsächlichen Bestandskunden möglichst ähnlich sind. Im Verhalten, den Interessen, der Demografie. Dahinter steht die Hypothese, dass jene Lookalike-User im gleichen Maße zum Kauf tendieren wie ihre Targeting-Spiegelbilder.
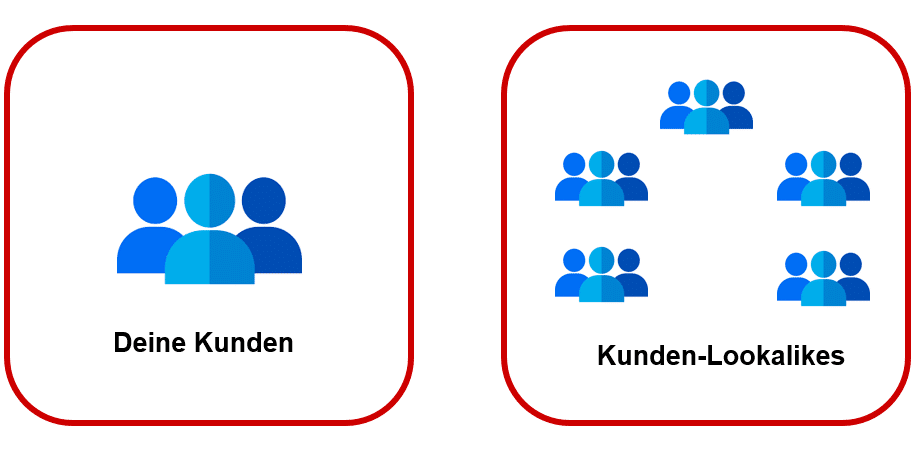
Was wir im Online-Marketing suchen, sind statistische Zwillinge unserer Kunden
Jene Nutzer wollen wir durch statistische Modelle im Machine Learning ausfindig machen. Wir wollen Muster erkennen (lassen) und das Puzzle zusammensetzten, indem wir einen potenziellen Kunden als diesen erkennen. Wenn User X die gleichen Merkmale aufweist wie Bestandskunde Y, ist die Wahrscheinlichkeit größer, dass wir diesen User ebenfalls vom Kauf unseres Produktes überzeugen können.
Diesen Informations-Wert bietet uns nur First Party Daten. Daten von Nutzern, die bereits mit der eignen Brand interagiert haben. Gesammelt beispielsweise über Website-Tracking, E-Mail-Subscriber, Apps-Engagements oder digitale Kassensysteme.
Aus Machine-Learning-Perspektive geht es wie beschrieben darum, Daten als Input zu verwenden, die unsere Hypothese möglichst gut wiedergeben. Je weiter die Daten jedoch vom Kunden entfernt sind (Third Party-Daten) desto mehr wird unsere Hypothese verwaschen. Die Aussagekraft des Modells wird ungenauer. Es wird unbrauchbar, um auf dessen Basis Businessentscheidungen zu treffen.
„The answers are all out there. We just need to ask the right questions“- Oscar Wilde (Schriftsteller)
Am Ende des Tages geht es darum in der Lage zu sein mit den vorhandenen Daten die richtigen Fragen zu stellen. Wir erfragen den Wert einzelner Variablen und Informationen und machen auf Basis bereits erfolgter Conversions Rückschlüsse auf das Handeln neuer Usergruppen.
Somit verfolgt Owned Machine Learning den Ansatz eigene effektive Modelle zu bauen und zu trainieren, die wir jeder Zeit im Zusammenspiel mit unseren eigenen Daten flexibel einsetzten können. So haben wir die Möglichkeit bessere, schnellere und möglichst fundierte Entscheidungen zu treffen. Darüber hinaus können Zielgruppen und Projekte zielgerichteter priorisiert werden.
Online Marketing Implementierung: Owned Machine Learning im Einsatz
„The amount of work we can automate with AI is vastly bigger than before“- Andrew Ng (Gründer Google Brain Projekt)
Wo kann uns Owned Machine Learning im Marketing den Arbeitsalltag erleichtern?
Zahlreiche Tasks können wir an unsere Daten-Modelle auslagern, welche diese Aufgaben mit etwas Training und qualitativ hochwertigen Daten effektiv übernehmen können.
- Audience Priorisierung: Leider können wir nicht für jede einzelne Zielgruppe eine personalisierte User-Experience erstellen. Dafür fehlen uns stets die Zeit und oft auch das Geld. Müssen wir aber auch gar nicht. Denn wenn wir mit Machine Learning herausfinden, welche Zielgruppen die höchste Wahrscheinlichkeit haben zu konvertieren, können wir unsere begrenzten Mittel auf diese fokussieren.
Affinity Audiences in Google Ads, Welche ist die für mich wertvollste?
- Kunden Klassifizierung: Gehört ein User zu unseren wertvolleren Zielgruppen? Ist eine hohe Wahrscheinlichkeit für einen hohen Customer Lifetime Value gegeben? oder lohnen sich Kosten und Aufwand ihn mit Werbung zu bespielen nicht. Diese Einordnung können wir mit Machine Learning automatisieren. Eine Ausführliche Beschreibung des Ansatzes, gibt es von Google selbst: https://cloud.google.com/solutions/machine-learning/clv-prediction-with-offline-training-intro
- Keyword-Segmentation: Wie sucht unsere Zielgruppe? Gibt es Suchbegriffe und Keywords, die wir dem Lower-Funnel zuordnen können? (Mehr zu Customer Journey und Sales Funnel) Klassifizierungs-Algorithmen können uns hier weiterhelfen. Eine Möglichkeit der Umsetzung mit dem Logistic Regression Algorithmus findet ihr hier: https://sem-smartation.com/how-to-build-a-keyword-classifier-with-machine-learning/
- Audience Clustering: Wo macht es Sinn den Cut zu setzen und zwei oder mehrere User-Gruppen voneinander zu trennen. Lassen wir die Daten entscheiden. Für Probleme solcher Art, wird häufig der k-Means Algorithmus verwendet: http://sem-smartation.com/audience-clustering/
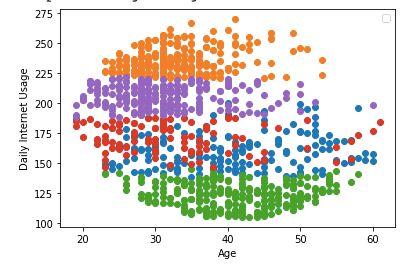
Audience Segmentierung mit Machine Learning
- Marketing-Kanal-Attribution: Arbeiten wir mit mehreren Kanälen parallel können wir mit Machine Learning den Wert einzelner Channels im Marketing-Mix für bestimmte User-Gruppen ermitteln. Weitere Informationen zur Umsetzung findet ihr hier: https://towardsdatascience.com/data-driven-marketing-attribution-1a28d2e613a0
- Forecasting und Budget-Kalkulation: Wie viele Conversions können wir für Budget X erwarten? Wie viele Klicks erhalten wir mit Budget Y? Jeder Marketer kennt dieses Problem. Ein klassischer Fall für Logistic Regression und Timeseries Algorithmen.
- Anomalie-Erkennung in Reportings: Reportings und Berichte gehören zu den größten Zeitfressern im Online-Marketing. Lass dein Machine Learning-Modell deine Daten durchforsten und effektiv Ausreißer oder mögliche Trends erkennen. Eine der ausführlichsten Erklärungen zu Anomaly Detection Algorithmen findet man in Andrew Ngs Machine Learning Kurs auf coursera.org: https://www.coursera.org/lecture/machine-learning/anomaly-detection-using-the-multivariate-gaussian-distribution-DnNr9
Welcher Algorithmus für welches Marketing-Problem nützlich ist
„Now the skillful workman is very careful indeed as to what he takes into his brain-attic. He will have nothing but the tools which may help him in doing his work, but of these he has a large assortment, and all in the most perfect order“- Sherlock Holmes, Study in Scarlet
„All Models are wrong – but some are useful“, soll der Brite George E.P. Box, einer der einflussreichsten Statistiker des 20. Jahrhunderts, einst gewarnt haben. Damit bringt er einen der zentralen Aspekte bei der Arbeit mit Algorithmen auf den Tisch: Das perfekte Modell und den idealen Algorithmus gibt es nicht. Jeder einzelne hat seine Stärken und Schwächen. Selbst Tiefe Neuronale Netzwerke sind nicht in jeder Machine-Learning Situation geeignet.
Die folgende Tabelle soll eine kompakte Übersicht darüber geben, welche Algorithmen für welche Art von Marketing-Problem angewandt werden könnten, und wo ihre jeweiligen Stärken und Schwächen liegen.
und/oder Audiences
Logistic Regression
Einfache Implementierung; Mehrere Variablen gleichzeitig untersuchen; Gut interpretierbarer Output zwischen 0 und 1
Support Vector Machine
Sehr speichereffizient bei Kalkulation
Decision Tree
Häufig nicht so akkurat wie andere Algorithmen
Naive Bayes
Geht stets davon aus, dass Variablen unabhängig voneinander sind
k-Nearest Neighbor (KNN)
Häufig Probleme mit größeren Datasets; Viel „Data Cleaning Aufwand“ im Vorfeld
Berechnung komplexer, nichtlinearer Funktionen
Sehr berechnungsintensiv; Oft eine „Black-Box“
Linear Regression
Interpretiert nur lineare Funktionen
Eine ausführlichen Überblick über verschiedene Algorithmen und Kategorien, liefert unter anderem Jason Brownlee in seiner „Tour of Machine Learning Algorithms“: https://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
Das praktische an Algorithmen in Machine Learning ist, dass wir diese nicht erst selbst entwickeln müssen. Zur Implementierung liegen diese bereits vordefiniert in Bibliotheken wie scikit-learn, numpy oder pandas und müssen lediglich in den jeweiligen Code importiert werden. Wichtig ist es jedoch, sich mit der Funktionsweise sowie den Stärken und Schwächen eines Algorithmus auseinander zu setzten.
Verschiedene Wege sollten dabei gestestet und ausprobiert werden. Eine Übersicht über die verschiedenen Import-Befehle in Python mit scikit-learn findet ihr hier: https://sem-smartation.com/import-algorithms/
Fazit
„Would you tell me, please, which way I ought to go from here? That depends a good deal on where you want to get to.“- Lewis Caroll (Alice in Wonderland)
Wenn wir als Unternehmen langfristig erfolgreich sein wollen, müssen wir wissen, wie unsere wertvollsten Zielgruppen denken und fühlen. Da führt kein Weg dran vorbei.
Mit Owned Machine Learning, eigens trainierten Modellen, können wir diese Erkenntnisse effizient aus großen Datenmengen herausfiltern. Dieses Wissen können wir dann wiederum nutzen, um den unglaublich starken – aber undurchsichtigen – Machine Learning Modellen von Google, Facebook & Co entsprechende klarere Signale als Input zu liefern. Beispielsweise durch die Fokussierung auf für uns besonders wertvolle In-Market- oder Affinity Audiences.
Die Umsetzung sollte sich stark an den vorhandenen Daten und der jeweiligen Problem- bzw. Fragestellung orientieren. Uns Online-Marketers stehen an dieser Stelle unzählige Algorithmen zur Verfügung, jeder einzelne hat Vor- und Nachteile.
Owned Machine Learning lässt sich also auf zwei Kernaspekte fokussieren. Wir sichern uns langfristiges Wissen über das Verhalten unserer Zielgruppe und integrieren qualitativ hochwertige Daten in unsere selbst entwickelten Modelle, um so unser Online Marketing effektiver zu gestalten.
Einen vorgegebenen Weg gibt es dabei nicht. Auch wenn es eine Reise mit vorgegebenem, klar definiertem Ziel sein mag: unterwegs, werden wir durch maschinelle Power Dinge über unsere Zielgruppe lernen, die wir keineswegs erwartet hätten.
Künstliche Intelligenz und Maschinelles Lernen stehen noch am Anfang ihrer Entwicklung. Auch im Online-Marketing haben wir bei weitem noch nicht alles gesehen und das noch nicht erschlossene Potenzial ist gigantisch.
Wenn wir uns frühzeitig mit diesem Thema auseinandersetzen, sichern wir uns einen Wettbewerbsvorteil und langfristig auch die Gunst des Kunden.


























Ein Kommentar