
Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei Suchmaschinen
Inhaltsverzeichnis
Um welches Google-Patent handelt es sich?
Im Folgenden werden ich das folgende Google-Patent zusammenfassen:
Personalized entity information page, United States Patent 10917499
Veröffentlichungsdatum: 09.02.2021
Datum der Einreichung: 09.03.2020
Um was geht es bei dem Patent?
Das Patent beschreibt eine Methode und einen Prozess, wie Informationen zu einer Suchanfrage mit Bezug zu einer Entität in strukturierter Form ausgegeben werden können. Das könnte z.B. ein Knowledge Panel oder eine Knowledge Crad sein. (mehr dazu im Beitrag Wie erstellt Google Knowledge Panel & Knowledge Cards? )
Dabei werden sowohl statische Informationen, die der Entität bzw. dem Entitäts-Typ schon zugeordnet sind ausgegeben, als auch personalisierte Informationen individuell nach Nutzer.

Wie funktioniert die im Patent beschriebene Methoden?
Die aktuellen Knowledge Panel und Knowledge Cards basieren auf Informationen, die Google zu einer Entität bereits vorab im Knowledge Graph gespeichert hat. Die Informationen sind relativ statisch. In dem Patent wird neben der Ausspielung dieser statischen Informationen auch von personalisierten Informationen basierend auf der Suchhistorie des jeweiligen Nutzers gesprochen.
The methods and systems described herein disclose systems and methods for presenting information of various information types about an entity in a structured information page, in which some of the information types included in the structured information page are dynamically selected for inclusion in the structured information page in accordance with historical user activity. Such methods and systems provide an effective way to present to users entity information that is organized and which includes information that users are more likely to consider important.
Ich konnte in der Vergangenheit immer wieder tägliche Veränderungen z.B. bei der Beschreibung und den Bildern meines eigenen Knowledge Panels (zur Entität Olaf Kopp) beobachten.
Häufig hat sich Google auf meine Autorenbeschreibung im Aufgesang-Blog bezogen. Aber auch die Autorenbeschreibung im Searchmetrics Blog oder meine Experten-Seite beim OMT wurde bereits als Quelle herangezogen. Ob das in Verbindung mit meinem individuellen Nutzerverhalten steht?
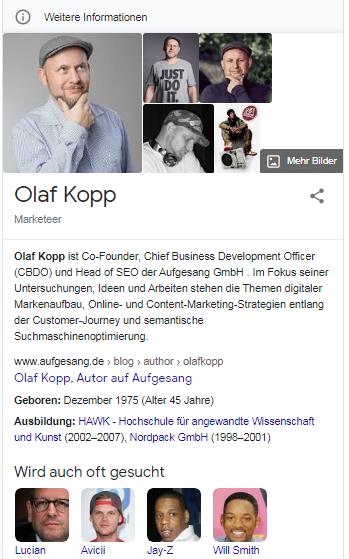
Knowledge Panel für die Entität „olaf kopp“
Als Quellen für die Informationen von Entitäten werden u.a. folgende genannt:
- Websites
- Datenbanken
- Online-Shops
- Online-Medien
- …
The distributed system 100 includes one or more information sources 170, which include any type of external sources of information about entities, such as websites, databases, online stores, online media content sources, and so on.
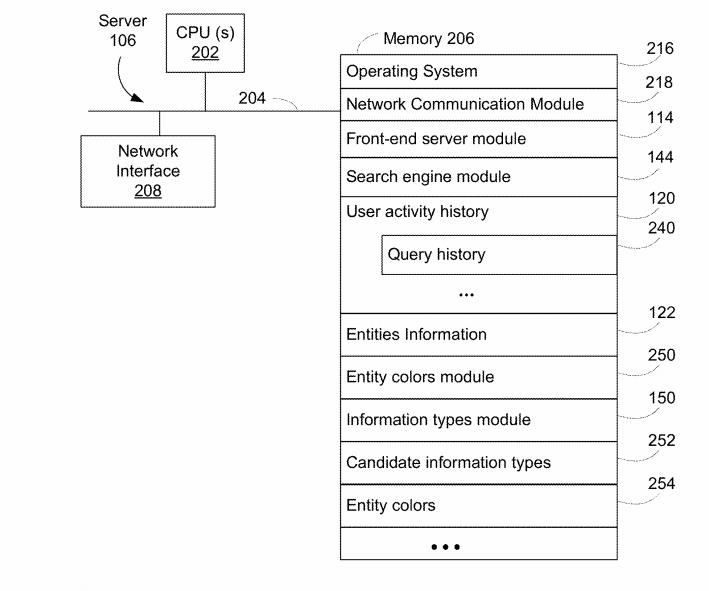
In dem Patent wird von einem Knowledge Repository gesprochen aus dem Google die Informationen bezieht. Meine Vermutung ist schon länger, dass dieses Repository eine Weiterentwicklung des Knowledge Vault ist. (mehr dazu im Beitrag Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?). In diesem Repository sind Entitäten, Entitäts-Klassen bzw. Entitäts-Typen und Verlinkungen zu Dokumenten In Beziehung zu Entitäten gespeichert.
The server 106 includes an entities information repository 122 of information about or associated with entities (e.g., a database). As used herein, an entity is any distinct existence or thing, and an entity class is a class or category of entities. In some implementations, entity classes include, without limitation, movies, television shows, books, music albums, video games, places of business (e.g., restaurants), and organizations. The information stored in the repository 122 includes locally stored information (e.g., for a movie, the cast and crew lists stored within the repository 122 and directly retrievable from the repository 122) and/or an index of information about/associated with entities in information sources 170 (e.g., links to documents in information sources 170).
Im Patent werden auch Beispiele genannt mit welchen Informationen wie z.B. ein Film in Verbindung gebracht werden kann.
For example, for a movie, information types for a movie include, without limitation, the title, running time, cast, crew, content rating, review information (e.g., review scores, review snippets), theater show times for the movie, purchase, rental, or online viewing locations, information on songs and/or music included in the movie, awards nominated and won, box office receipts information, plot synopsis or summary, trivia, images (e.g., cast photos, advertising images, posters) associated with the entity, and so on.
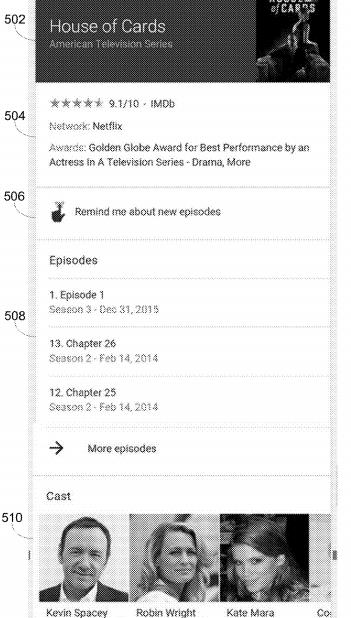
Wie im bereits weiter oben erwähnten Beitrag von mir wird auch hier darauf hingewiesen, dass je Entitäts-Klasse bzw. Entitäts-Typ ein festgelegtes Set an Attributen besteht. Welche der Standard-Attribute in einem Knowledge Panel ausgeliefert werden hängt zum Teil von den Akivitäten des Nutzers oder einer Nutzergruppe ab.
The server system 106 includes an information types module 150 that analyzes the historical user activity, stored in the user activity history 120, to determine which information types, other than those in the default set, satisfy one or more importance criteria. These importance criteria gauge the importance of an information type for an entity from the perspective of users.
Ein Faktor können historische Suchanfragen bzw. Suchverhalten aus der Vergangenheit sein, wobei hier Nachfrage-Popularität im Allgemeinen, über eine bestimmten Zeitraum oder plötzlich entstehende Trends bei Suchanfragen sein.
For example, if the information types module 150 identifies a high number of queries for movie songs in the user activity history 120, the information type module 150 may determine that the song(s) for a movie is an important information type.
Dieser Teil an dynamischen Informationen in einem Knowledge Panel kann sich immer wieder verändern bzw. an das Suchverhalten anpassen. Auch Knowledge Cards mit speziellen Attributen zur jeweiligen Entität können bei Bedarf zusätzlich ausgeliefert werden, wenn es die aktuelle Suchintention bedarf.
Und die im Patent beschriebene Methode geht noch weiter. So können Entitäten auch Farben zugeordnet werden, die mit der Entität in Verbindung gebracht werden, um z.B. für das Knowledge Panel in diese als Hintergrundfarbe zu nutzen.
Was sind die Schlussfolgerungen für die semantische Suche von Google und für SEOs?
An den in diesem Google-Patent beschriebenen Methoden und Prozessen erkennt man wie Google versuchen möchte Informationen rund um Entitäten zu speichern und auch teilweise dynamisch je nach Nutzer-Bedürfnis im Knowledge Panel auszuspielen. Besonders spannend fand ich bei der Angabe der Informationsquellen strukturierte Datenbanken nur noch ein Teil darstellen, was bedeutet, dass Google beim Data Mining von Informationen rund um Entitäten unabhängig von strukturierten Daten schon weit fortgeschritten sein könnte. Auch das Verlinkungen direkt z.B. zu Dokumenten Bestandteil des Repository sind ist eine interessante Information.
Ich denke die nächsten Jahre werden sehr spannend werden, was die Entwicklung der semantischen Google-Suche angeht.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.