Bei der Suchmaschinenoptimierung dreht sich alles um die Sichtbarkeit in den Suchergebnissen. Und da ist seit einigen Jahren eine Menge los. Panda und Pinguin haben die Spielregeln für das Ranking verändert und der Knowledge-Graph hat uns das Konzept der Entitäten gebracht.
Im heutigen Artikel möchte ich vorstellen, wie selbige in den Suchergebnissen dargestellt werden, ohne dass das Google-Ökosystem verlassen wird. Das nenne ich ich jetzt einfach mal die Entitäten-Box.
Spätestens seit der Bekanntgabe des Kolibri, könnte ich den ganzen Tag nichts anderes tun als Suchanfragen bei Google einzugeben und mir anzuschauen, was in den Suchergebnissen passiert. Dabei benutze ich meistens Google.com, denn im US-Amerikanischen Ableger des Suchmaschinengiganten werden Updates schneller ausgerollt und mehr getestet. Ein Beispiel sind die In-Depth Artikel, die ich hier schon mal als Feuilleton der Suchergebnisse beschrieben habe und noch nie bei Google.de entdeckt habe.
Inhaltsverzeichnis
Suchergebnisse sind dynamischer denn je
Bevor ich nun mit dem eigentlichen Artikel beginne, möchte ich kurz darauf eingehen, dass Google’s Suchergebnisse keine statischen, neutralen oder einheitlichen Rankings mehr sind. Die Zeiten sind durch personalisierte Elemente wie Standort, Suchhistorie oder Search+ Your World für eingeloggte Nutzer schon lange vorbei. Das bedeutet nichts geringeres als dass Du und ich sehr unterschiedliche Ergebnisse zu derselben Anfrage bekommen können.
Des Weiteren hat Google das eigene Verständnis für Sprache geändert, indem es nicht mehr nur Keywords abgleicht, sondern Begriffe als Entitäten versteht. Dadurch lernt Google die Bedeutung von Wörtern durch semantische Zusammenhänge. Mit dem Knowledge Graph entwickelt Google so etwas wie ein Gehirn und das bringt noch mehr Dynamik in die dynamischen Suchergebnisse. Die Dynamik entsteht vor allem dadurch, dass Google sich ständig weiterentwickelt und lernfähig geworden ist. Wer lernt, macht Fehler. Fehler sind Erfahrungen und durch Erfahrungen enstehen neue Erkenntnisse und Perspektiven, durch die man klüger werden kann, wenn man möchte.
Dass auch Google etablierte Muster durchaus ändern kann, hat der Wegfall der Autorenbildchen aus den organischen Ergebnissen kürzlich gezeigt. Dass das ‚klüger‘ ist wird natürlich nur aus Google’s Perspektive deutlich, denn dadurch entsteht ein Potenzial für noch mehr lukrative Klicks auf AdWords. Dass das für Autoren eher nachteilig und auch ärgerlich ist, ist eine andere Perspektive, die Google relativ egal zu sein scheint.
Entitäten versteht Google durch strukturierte Daten
Google liebt Inhalte in strukturierter Form. Das bedeutet, dass sie mit Metainformationen ausgezeichnet werden und je einheitlicher das Ganze ist, desto leichter kann der Algorithmus sie verarbeiten. Vom Prinzip gibt es zwei Wege, Daten in strukturierter Form bereit zu stellen:
- Einträge in Metadatendatenbanken wie Freebase, Nischensuchmaschinen oder andere Branchenverzeichnisse wie Google Business (aka Branchencenter aka Places aka Local aka unnötige Verwirrung)
- Inhalte auf der eigenen Seite strukturieren. Das geht sowohl durch ganz simple Formatierungen wie Zwischenüberschriften, Listen, Tabellen oder aber durch Schema.org, eine standardisierte Auszeichnungssprache auf die sich die ‚großen‘ Suchmaschinen geeinigt haben.
Garantien, ob und welche Daten Google nutzt um sie auf den Ergebnisseiten darzustellen gibt es keine. Aus Prinzip nicht mitzuspielen, weil man es Google nicht noch einfacher machen möchte ist allerdings gleichbedeutend damit, sich selbst ein Bein zu stellen. Dennoch besteht die wichtige und berechtigte Frage, welche Daten ein Unternehmen auszeichnen und damit preisgeben möchte.
Für konkrete Antworten muss der Einzelfall betrachtet werden, aber ein grundsätzliches Patentrezept ist: Betriebs- und Geschäftsgeheimnisse gehören selbstverständlich nicht in die Suchergebnisse und müssen geschützt werden. Öffentlich zugängliche Daten wie Unternehmensname, Logo, Adresse, Kontaktdaten, Branche oder Öffnungszeiten, also Daten, bei denen es im Interesse des Unternehmens steht, dass sie gefunden werden und korrekt sind, gehören ausgezeichnet beziehungsweise in andere relevante (!) Datenbanken eingetragen.
Quellen für Datenwerte der Entitätseigenschaften
Google hat sich von einer Suchmaschine zu einer Antwort- und Entdeckermaschine entwickelt und die Metainformationen in den Suchergebnissen sind in den letzten Jahren immer detaillierter, umfassender und bunter geworden. Bisher wurde vor allem Wikipedia als Ressource für Daten herangezogen, was zur Folge hatte, dass die Suchergebnisse above-the-fold teilweise sehr, sehr Wikipedialastig waren und immer noch sind. Wikipedia PR ist definitiv mehr als ‚nett-zu-haben‘ und ein Thema für sich.
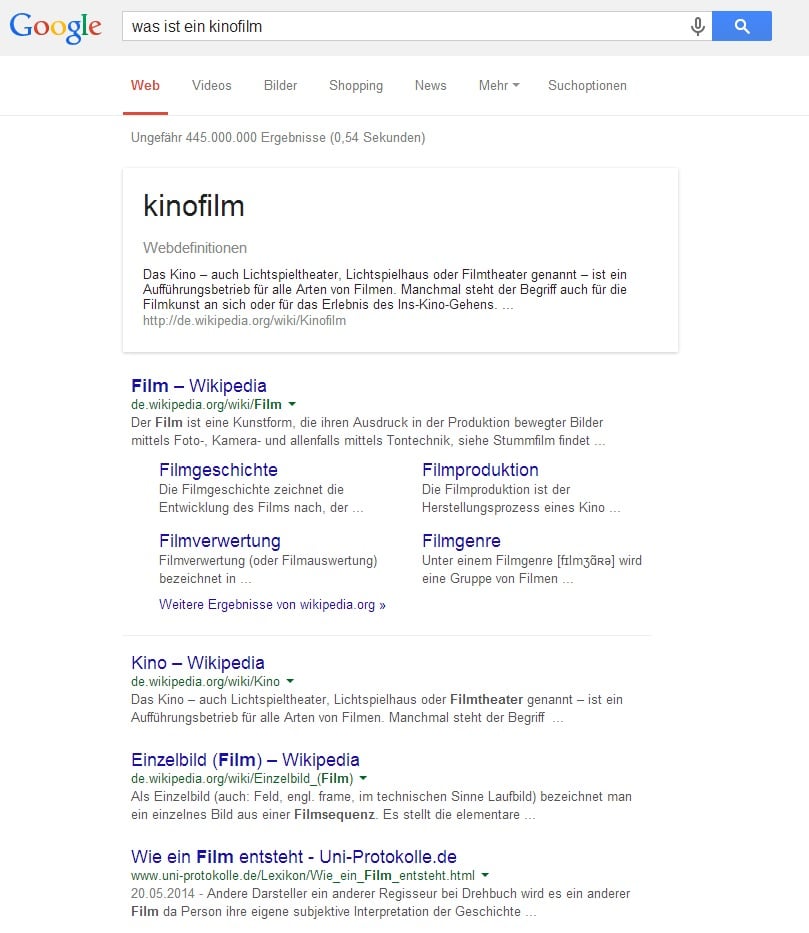
Gerade bei Suchanfragen, deren Intention mit großer Wahrscheinlichkeit eine Definition oder allgemein gültige Information ist, steht Wikipedia hoch im Kurs und so schnell wird sich das sicherlich nicht ändern. Bei der Frage „Was ist ein Kinofilm?“ erscheint folgendes Ergebnis:
Google ist aber auch auf der Suche nach anderen wertvollen Quellen, die für verschiedene Arten von Anfragen relevant sind. Ob das immer gerecht ist, sei dahingestellt und inwieweit es Kooperationen und Vereinbarung gibt, kann ich nicht beurteilen, aber drei Beispiele möchte ich an dieser Stelle geben:
Nährwertangaben
Nährwertangaben kommen von der amerikanischen Datenbank USDA:

Universum
Auf meine Frage „How far away is Mars?“ hat Google einen Textauszug von Universe Today, einer in den USA etablierten „Astronomy News Site“ genutzt:

Fußball WM
Während der WM wurden auf Anfragen wie „Spiel heute“ oder „WM 2014“ Antwortboxen in folgendem Stil gezeigt. Als Quelle diente die Fifa, was als Ausrichter der Weltmeisterschaft viel Sinn macht.

Entitäten-Box: man bleibt innerhalb des Google-Ökosystems
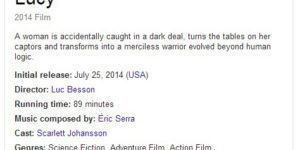
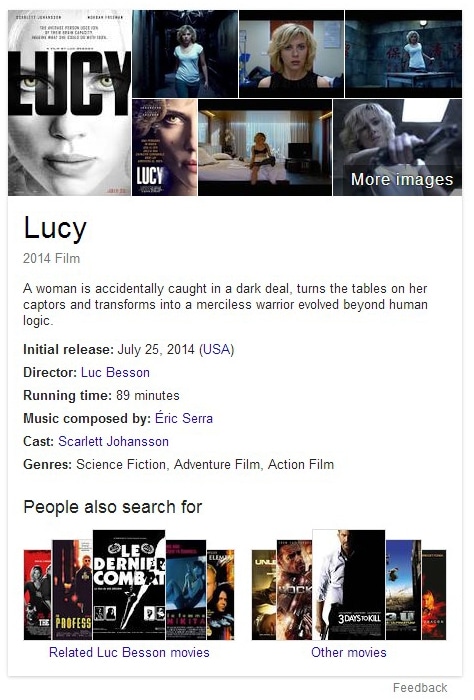
Als ich mich letzte Woche über den Film „Lucy“ informieren wollte, ist mir zum ersten Mal eine Antwortbox ohne Wikipedia Referenz aufgefallen. Klar, der Wikipedia Artikel zum Film war das erste organische Suchergebnis, aber dass innerhalb der Box kein einziger Wikipedia Link zu finden ist, fand ich erstaunlich. Stattdessen waren eine ganze Reihe Links vorhanden, die zu anderen semantisch relevanten Suchergebnisseiten von Google führen. Man bleibt also innerhalb des Google-Ökosystems.
Insgesamt ist hier das Konzept des Knowledge Graph sehr gut zu erkennen. Dabei geht es darum, dass eine Entität (der Film Lucy) dargestellt wird, der ganz bestimmte Eigenschaften zugewiesen sind (ein Film hat einen Regisseur, Hauptdarsteller, Spielzeitlänge, etc.) und diese Eigenschaften wiederum haben bestimmte Werte (Regisseur = Luc Besson, Hauptdarsteller = Scarlett Johannson, Spielzeitlänge = 89 Minuten). Das ganze sieht dann für die Suchanfrage „Lucy Movie“ so aus:
Der Aspekt der Entdeckermaschine wird immer interessanter, denn durch die Entitäten-Box werden weitere, semantisch relevante Suchergebnisse prominent gefeatured. Das bedeutet, wer für das Key „Lucy movie initial release date“ gut rankt, hat eine Chance auch für „Lucy movie“ gefunden zu werden. Im folgenden hab ich die Entitäten-Box mal grob auseinander genommen:
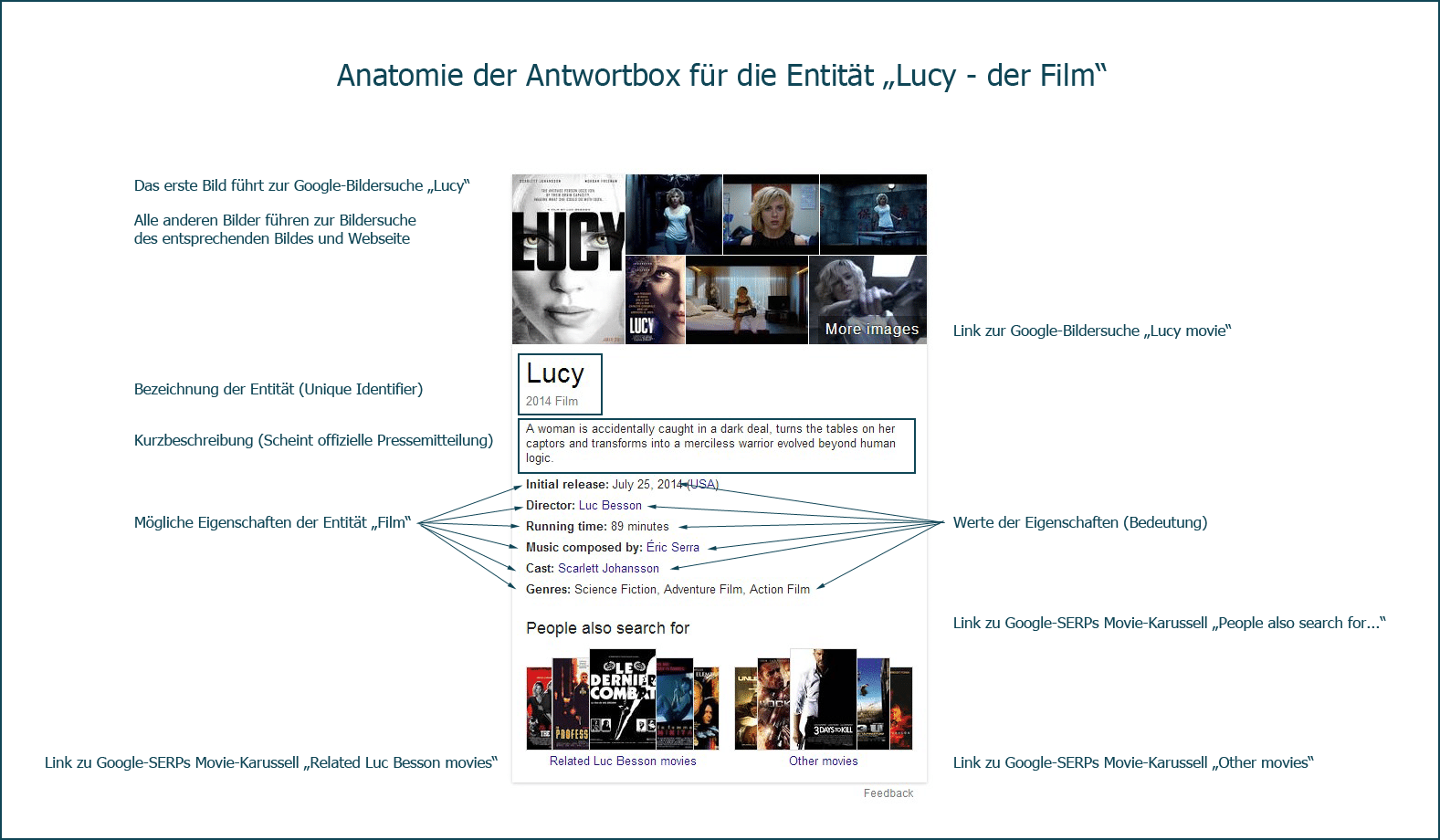
Erkenntnisse für die Entitäten-Optimierung
Der Knowledge-Graph ermöglicht eine ganzheitliche Betrachtung von Entitäten und um auf eine Entität zu optimieren sollte ein holistisches Verständnis derselbigen recherchiert werden. Im Fall eines Filmes gilt es also herauszufinden, welche Eigenschaften ein Film haben kann. Diese Eigenschaften sind innerhalb der Ontologie festgelegt. Es ist also für die Entitäten-Optimierung wichtig die zugrunde liegenden ontologischen Vorstellungen, die für uns Menschen übrigens sehr natürlich wirken, zu verstehen.
Um also mit einem Artikel oder einer Webseite zu einem Film gut zu ranken sollte dieser Artikel eine oder mehrere Ebenen der Entität behandeln. Für die Planung des Artikels ist es durchaus sinnvoll einen Blick auf die Webseite von Schema.org zu werfen und nachzuschauen, welche Eigenschaften dort vergeben werden. Für Filme gelten auszugsweise folgende Eigenschaften:
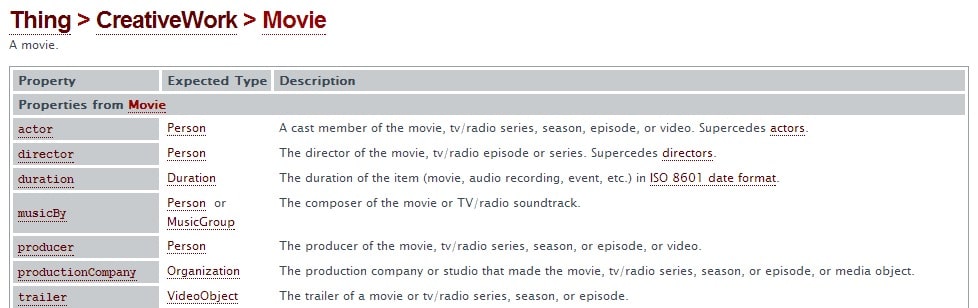
Schema.org als wertvolles Tool zur Inhaltsplanung
Schema.org kann als Antwort auf die leidige Frage „worüber soll ich bloß schreiben?!?“ gesehen werden. Hier werden Ebenen festgelegt, die für eine bestimmte Entität als relevant erachtet werden. Das heißt allerdings noch lange nicht, dass Kreativität tot ist. Schließlich handelt es sich hier um eine öffentlich zugängliche Datenbank und ist deswegen nicht als Wettbewerbsvorteil, sondern als grobe Orientierung zu verstehen.
Generell bleibt, werde zur Marke, erschaffe Vertrauen, zeige Expertise und Leidenschaft und biete damit emotionalen Mehrwert bei der Zielgruppe. Auch wenn es sicherlich keine harten, messbaren Rankingfaktoren sind, aber die Liebessignale (aka Social Signals) des Zielpublikums sind die wohl nachhaltigsten und langfristigen Faktoren der SEOnline-Präsenz.

- SERPs in den SERPs: Die Entitäten-Box bei Google - 24. Juli 2014
- Leidenschaft: die Grundlage guter Inhalte - 3. Juli 2014
- Build your Brand mit Storytelling - 26. Juni 2014
- Happy Hash-Tagging bei Google! Semantische Verbindung von Inhalten und Entitäten - 27. Mai 2014
- Branking: Notizen zur SEOptimierung des Selbst - 20. Mai 2014

























Kommentare sind geschlossen.