Es gibt nur wenige Informationen zu den wichtigen Elementen des Google Knowledge Graph wie Entitätstypen, -Klassen und -Attributen und Analyse der Beziehungen zwischen diesen Elementen. Ein Grund mehr im Rahmen meiner Artikelreihe zu semantischer Suchmaschinenoptimierung darauf einzugehen.
Inhaltsverzeichnis
- 1 Vom Entitäten-Katalog zum Knowledge Graph
- 2 Was sind Entitäts-Attribute ?
- 3 Was sind die Quellen für die Attribute?
- 4 Die Verarbeitung von strukturierten Daten für den Knowledge Graph
- 5 Was sind Entitätstypen und Entitäts-Klassen bzw. Domains?
- 6 Beziehung zwischen Entitäts-Klassen in Ontologien
- 7 Wie relevant ist ein Attribut für eine Entität, Entitäts-Typ oder -Klasse ?
- 8 Data Mining zu Entitäten ist Googles größte Herausforderung
Vom Entitäten-Katalog zum Knowledge Graph
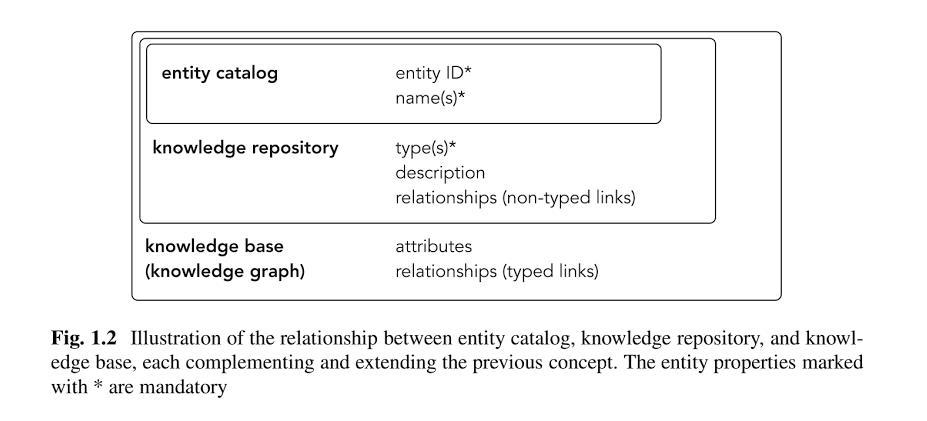
Als Grundlage für den Knowledge Graph dienen drei Ebenen:
- Entitäten-Katalog: Hier werden alle Entitäten gespeichert, die mit der Zeit identifiziert worden sind.
- Knowledge Respository: Die Entitäten werden in einem Wissens-Depot (Knowledge Repository) mit den Informationen bzw. Attributen aus den verschiedenen Quellen zusammengeführt. Im Knowledge Repository geht es in erster Linie um die Zusammenführung und Speicherung von Beschreibungen und die Bildung semantischer Klassen bzw. Gruppen in Form von Entitäts-Typen. Googles Knowledge Repository ist aktuell der Knowledge Vault.
- Knowledge Graph: Im Knowledge Graph werden die Entitäten mit Attributen ergänzt und Beziehungen zwischen den Entitäten hergestellt .
Innerhalb dieser Wissens-Datenbanken sind Entitäten das zentrale Organisations-Element, um das herum alle Informationen angeordnet werden. So können einer Entität z.B. folgende Informationen zugeordnet werden:
- Attribute
- Entitätstypen
- Social Media Profile
- Medien (Dokumente, Videos, Audios …)
- Verwandte Entitäten mit denen die Entität in Beziehung steht
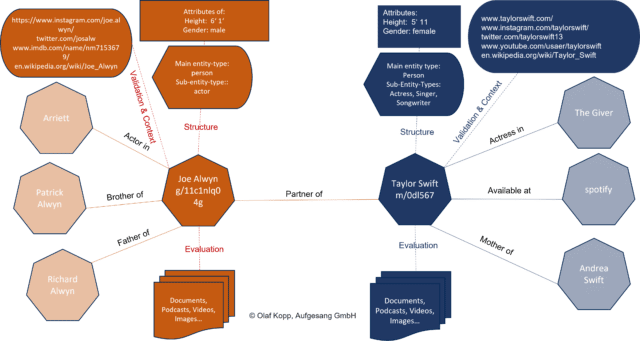
Organisation von Entitäten innerhalb eines Knowledge Graph
Was sind Entitäts-Attribute ?
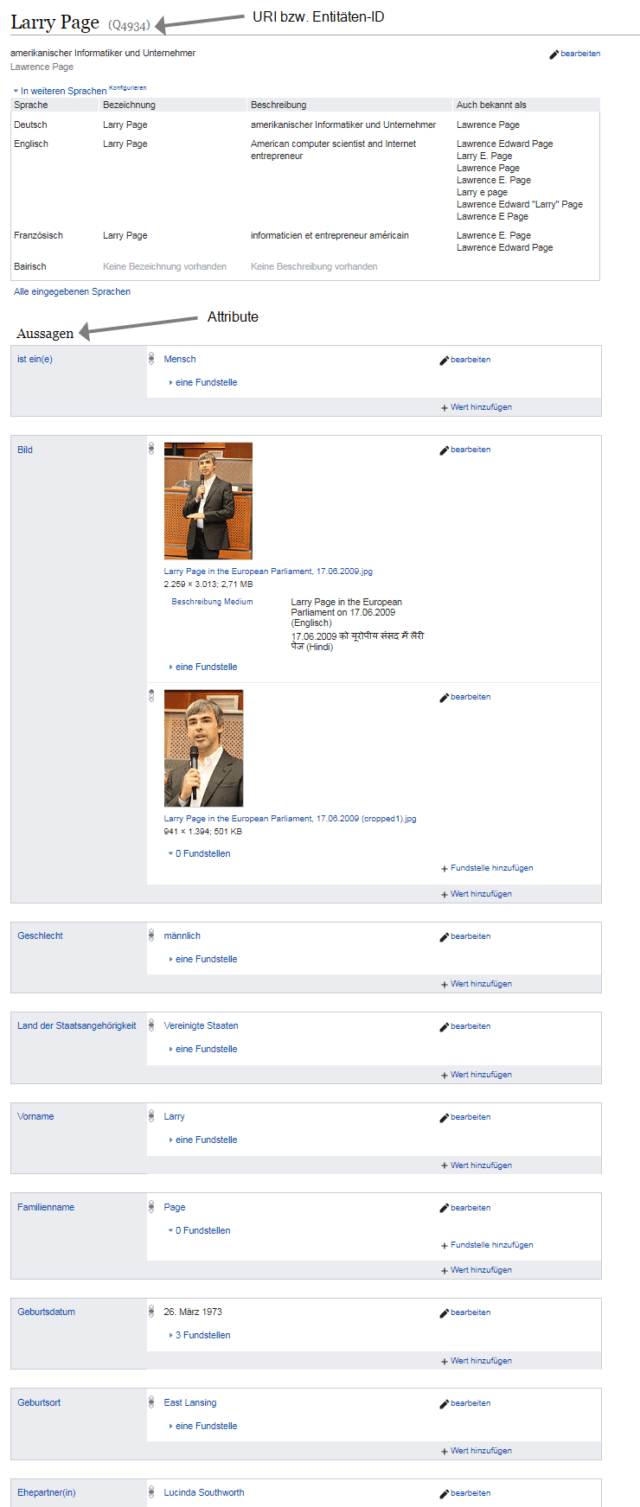
Attribute beschreiben die Eigenschaften einer Entität. In Wikidata werden diese Attribute unter Aussagen zusammengefasst. So sind dort der Entität Larry Page u.a. die folgenden Attribute zugeordnet:
- Geschlecht: männlich
- Land der Staatsangehörigkeit: Vereinigte Staaten
- Vorname: Larry
- Familienname: Page
- Bilder von Larry Page
- Geburtsdatum: 26.März 1973
- Geburtsort: East Lansing
- Ehepartner: Lucinda Southworth
- Anzahl Kinder: 2
- gesprochene oder publizierte Sprache: Englisch
- Tätigkeit: Unternehmer, Informatiker, Ingenieur
- Arbeitgeber: Google
- öffentliches Amt oder Stellung: Chief Executive Officer
- Mitglied von: American Academy of Arts an Sciences, National Academy of Engineering
- Wohnsitz: Palo Alto
- Vermögen: 30.000.000.000 US Dollar
- …
So sieht der Datensatz dann in Wikidata aus:
Im Knowledge Panel werden folgende Informationen ausgegeben:
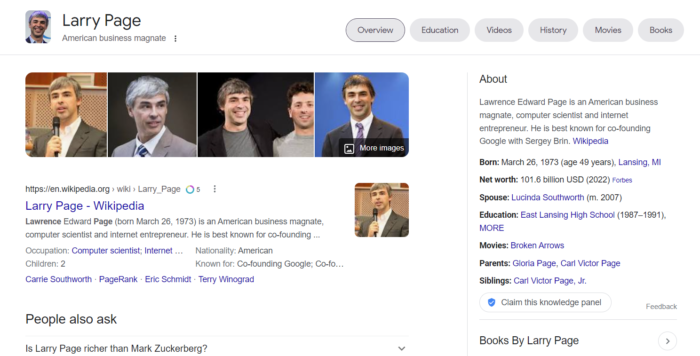
Man sieht, dass nicht alle Informationen aus Wikidata ausgespielt werden und auch zusätzliche Infos wie aus Wikipedia ergänzt werden. Es gibt auch Unterschiede wie z.B. beim Gehalt obwohl in der Wikidata eine Fundstelle für diese Aussage hinterlegt ist. Das Attribut Ausbildung wird ausgespielt obwohl keine Fundstelle für die Verifizierung hinterlegt ist. Daraus lässt sich schließen, dass die Platzierung der Attribute im Knowledge Panel nichts zwangsläufig etwas mit der Validierung zu tun hat.
Ein Abruf der Entität Larry Page über die Knowledge Graph API ergibt folgende Informationen:
{
„@type“: „EntitySearchResult“,
„result“: {
„@id“: „kg:/m/0gjpq„,
„name“: „Larry Page„,
„@type“: [
„Person“,
„Thing“
],
„description“: „Chief Executive Officer of Alphabet„,
„image“: {
„contentUrl“: „http://t2.gstatic.com/images?q=tbn:ANd9GcQRfAXPOVZYYyTQXdos1xYsjQx6Q6MbR4GRc9lzreCuMHevp1NT“,
„url„: „https://commons.wikimedia.org/wiki/File:Larry_Page_laughs.jpg„
},
„url“: „http://www.google.com/corporate/execs.html„
},
„resultScore“: 676.908813
},
Nur der Name, die Description, die Knowledge Graph ID, eine Bild-Quelle und Link zu einer offiziellen Google Quelle werden angegeben.
Der resultscore stellt die Nähe bzw. die Übereinstimmung der jeweiligen Entität mit der Suchanfrage in der Knowledge Graph API dar und entscheidet bei mehrdeutigen Entitäts-Namen welches Knowledge Panel priorisiert ausgeliefert wird bei Entitäts-bezogenen Suchanfragen. So gibt es auch eine Entität Larry Page, die einen Sänger repräsentiert. Diese hat aber nur einen niedrigeren resultscore.
Was sind die Quellen für die Attribute?
Die Informationen zu den Entitäten und deren Beziehungen untereinander kann Google aus folgenden Quellen beziehen:
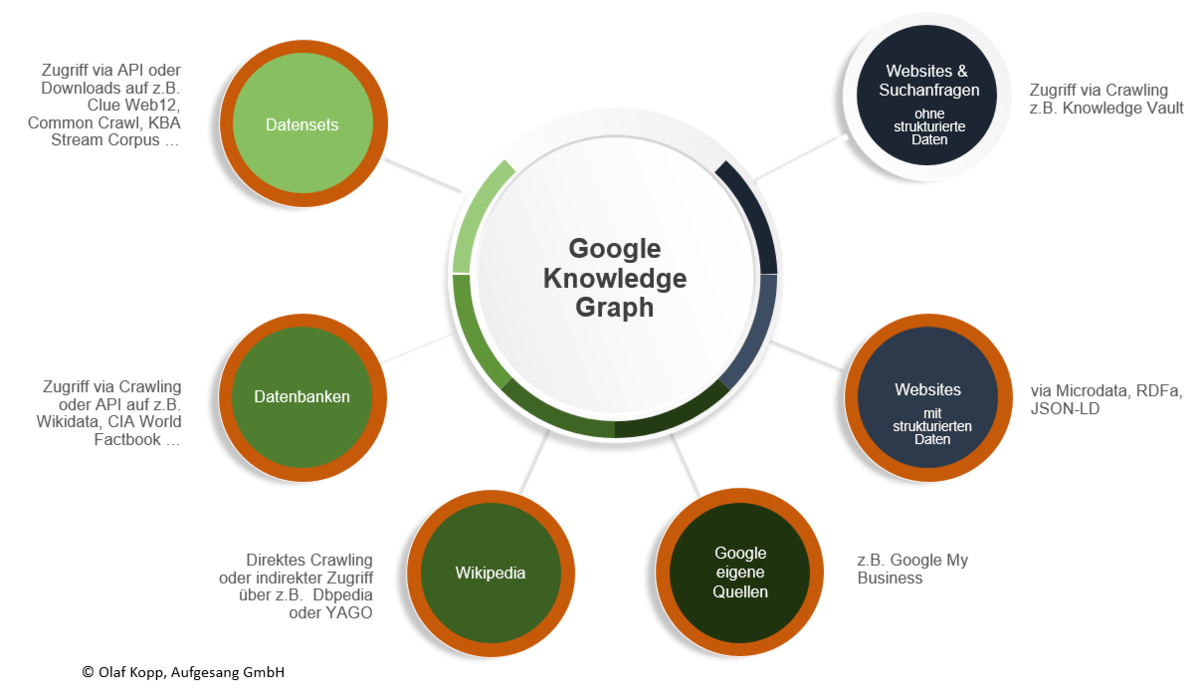
Datenquellen für den Knowledge Graph
Quellen für unstrukturierte Daten
Quellen aus denen Google theoretische unstrukturierte Informationen zu Entitäten extrahieren kann sind
- Normale Web-Seiten via Crawling und Natural Language Processing
- Suchanfragen über Natural Language Processing
- unstrukturierte Datenbanken und Datensets
Dabei spielt der Knowledge Vault eine besondere Rolle. Dazu mehr in meinem Beitrag How Google can identify and interpret entities from unstructured content?
Quellen für semistrukturierte Daten
Semistrukturierte Informationen kann Google aus Enzyklopädien wie z.B. Wikipedia, die eine systematische Struktur besitzen. Mehr dazu in meinem Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?
Quellen für strukturierte Daten
Über semantische Datenbanken und Datensets kann Google strukturierte Daten direkt z.B. via API übernehmen und für den Knowledge Graph nutzen. Folgende Datenbanken sind dafür möglich:
- Wikidata (ehemals Freebase)
- Google My Business
- CIA World Factbook
- DBpedia
- YAGO
- Webseiten mit strukturierten Daten via Microdata, RDFa und JSON-LD
- Lizensierte Daten
- CIA World Factbook
- Datensets
- ClueWeb09 bis ClueWeb12
- Common Crawl
- KBA Stream Corpus
Die Verarbeitung von strukturierten Daten für den Knowledge Graph
Die Anlaufstelle Nummer Eins für Google um Informationen zu Entitäten zu bekommen sind Quellen über die sie strukturierte Daten bereitgestellt werden.
In diesem Beitrag werde ich mich nur mit dieser Art von Datenquellen beschäftigen. Auf die weitaus komplexere Methodik unstrukturierte Daten und semistrukturierte Daten wie z.B. aus der Wikipedia zu extrahieren werde ich in Folgebeiträgen eingehen.
Die strukturierten Daten kann Google über das Resource Description Framework kurz RDF erfassen. Eine Enität ist eine Zusammenfassung verschiedener RDF-Statements nach dem Muster Objekt-Prädikat-Subjekt. Ein Statement wäre z.B. „Canberra ist die Hauptstadt von Australien.“
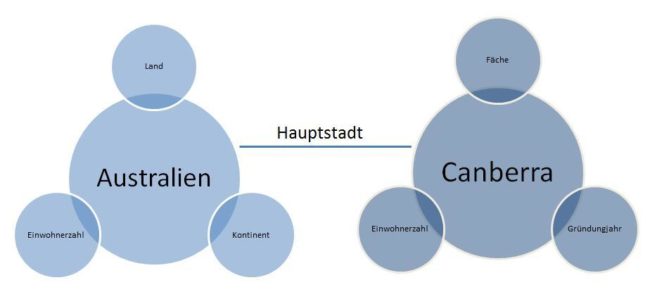
Man kann diesen Zusammenhang auch grammatikalisch so darstellen. Canberra ist das Subjekt, Australien das Objekt und (ist die)Hauptstadt ist das Prädikat. Die Beziehungsart kann aber auch durch ein Verb beschrieben werden wie „Thomas Müller spielt für Bayern München.“ Objekt und Subjekt sind demnach immer Entitäten. Das Prädikat kann ein Entitäts-Typ oder -Klasse, ein Attribut ein Verb oder eine Kombination aus allen sein.
Die meisten strukturierten Datenbanken stellen die Informationen im maschinenlesbaren RDF-Format zur Verfügung bzw. lassen eine Übersetzung in dieses Format zu. Google greift auf Datenbanken zu, in die sie Vertrauen haben wie z.B. Wikidata, CIA World Factbook …, strukturierte Datensets oder Übersetzungs-Datenbanken wie z.B. DBpedia oder YAGO, die die Informationen der Wikipedia in maschinenlesbare Daten übersetzen.
Da die Datenbanken und Datensets mit strukturierten Daten verhältnismäßig nur sehr langsam wachsen und aktualisieren wundert es nicht, dass Google Webmaster immer wieder dazu animiert mit strukturierten Daten in ihren Websites zu arbeiten. Je mehr Google strukturierte Daten sammelt und verarbeitet, desto näher kommen sie dem Ziel auch unstrukturierte Daten verarbeiten zu können. Die strukturierten Daten funktionieren als Trainingsdaten für das maschinelle Lernen.
Dazu mehr in meinem Beitrag Warum strukturierte Daten für Google zukünftig überflüssig werden könnten.
Was sind Entitätstypen und Entitäts-Klassen bzw. Domains?
In verschiedenen Google-Patenten findet man die Begriffe Entitätstypen und Entitäts-Klassen bzw. Domains. Bestimmte Entitätstypen und Domains haben ein ähnliche Zusammenstellung von Attributen und bilden damit eine Gruppe. Z.B. können der Domain „Person“ oder „Mensch“ immer Attribute wie Geburtsort, Wohnort, Geburtsdatum … zugeordnet werden. Dadurch ist die Domain und die zugehörigen Entitätstypen klar definiert.
Ein Entitäts-Typ und eine Domain beschreibt eine Gruppe von Entitäten, die über ähnliche Attribute beschrieben werden können. Im obigen Beispiel von Larry Page könnte ein Entitätstyp CEO oder Unternehmer sein.
Im dem sehr guten Buch Entity Oriented Search von Krisztian Balog findet man folgende Beschreibung für Entitätstypen:
Entities may be categorized into multiple entity types (or types for short). Types can also be thought of as containers (semantic categories) that group together entities with similar properties. An analogy can be made to object oriented programming, whereby an entity of a type is like an instance of a class.
Beziehung zwischen Entitäts-Klassen in Ontologien
Es gibt Datenbanken wie z.B. YAGO oder die DBpedia Ontology, die Beziehungen zwischen Entitäts-Klassen bzw. Entitätstypen darstellen. Bei DBpedia Ontology ist die Basis Wikipedia. In dem folgenden Auszug aus DBpedia Ontology werden Entitätstypen (abgerundete Rechtecke) via aufsteigenden Pfeilen mit übergeordneten Entitäts-Klassen in Beziehung gesetzt. Z.B. sind die Entitätstypen Athlet und Rennfahrer der Entitäts-Klasse „Person“ zugeordnet. Typen- und Klassen-verbindende Attribute sind mit den gestrichelten Pfeilen dargestellt.
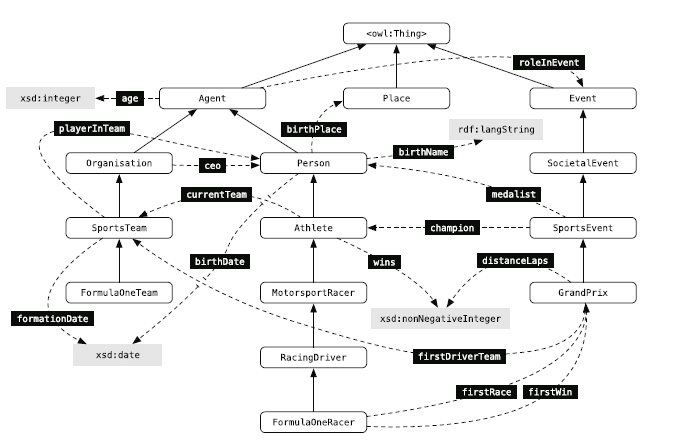
Auszug aus DBpedia Ontology; Quelle: Entity-Oriented Search – Krisztian Balog
Das Ganze stellt dann eine Ontologie dar, die die Beziehungen zwischen den Klassen, Typen und somit auch Entitäten abbildet.
Wie relevant ist ein Attribut für eine Entität, Entitäts-Typ oder -Klasse ?
Über eine Gewichtung der Attribute je Entität kann Google zum einen feststellen wie relevant ein bestimmtes Attribut für eine Entität ist. Zum anderen könnte Google darüber auch die Relevanz der Entität für eine gestellte Suchanfrage nach diesem Attribut ermitteln.
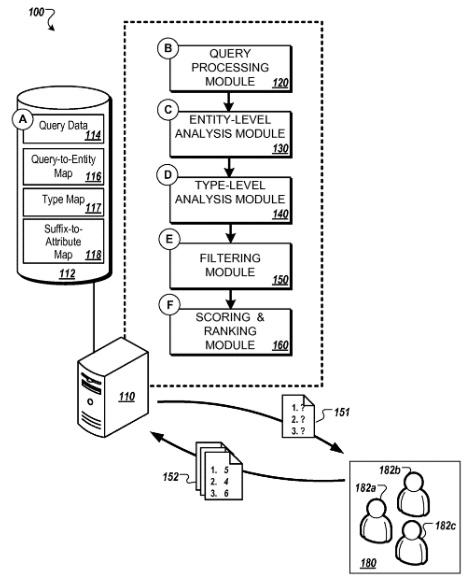
Quellen: Google Patent US9047278B1
Das Google-Patent Identifying and ranking attributes of entities zeigt einen Ansatz wie so etwas funktionieren könnte.
Laut diesem Patent können über die Eingaben bestimmter Suchterm-Kombinationen Attribute Entitäten zugeordnet und gewichtet werden.
One innovative aspect of the subject matter described in this specification is embodied in methods that include the actions of: identifying queries in query data; determining, in each of the queries, (i) an entity-descriptive portion that refers to an entity and (ii) a suffix; determining a count of a number of times the one or more queries were submitted; estimating, based on the count, an entity-level count of query submissions that include the particular suffix and are considered to refer to a first entity; determining that the entity is a particular type of entity; determining a type-level count of the query submissions that include the first suffix and are estimated to refer to entities of the particular type of entity; and assigning a score to the particular suffix based on the entity-level count and the type-level count.
Über diese Methode könnte Google darüber festlegen welche Informationen zu Entitäten eines bestimmten Entitäts-Typ im Knowledge Panel angezeigt werden. Desweiteren ließe sich bei mehrdeutigen Aussagen feststellen welches Attribut das relevanteste ist. Bezogen auf das Beispiel von oben.
Hier ein Beispiel:
Larry Page ist als Unternehmer, Informatiker und Ingenieur tätig. Welche dieser drei Aussagen ist die relevanteste bzw. zutreffendste?
Je mehr Menschen nach „Larry Page Unternehmer“ suchen, desto zutreffender ist das Attribut „Unternehmer“.
Data Mining zu Entitäten ist Googles größte Herausforderung
Aus den Recherchen und Gedanken zu diesem Beitrag habe ich für mich mitgenommen, dass Googles größte Herausforderung bezüglich des Knowledge Graph das Extrahieren von Informationen bzw. Attributen bezüglich Entitäten sowie Entitätstypen und -Klassen gerade aus unstrukturierten Datenquellen ist. Der Knowledge Graph ist aktuell noch sehr lückenhaft, da die Informationen aus den genannten strukturierten Datenquellen sehr unvollständig sind, was die Gesamtmenge aller Entitäten in der realen Welt betrifft.
Daraus sind dann einige weitere Artikel entstanden, die sich mit dem Data Mining von Informationen rund um Entitäten für den Knowledge Graph beschäftigen:

- Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?
- Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
- Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























3 Kommentare
Das klingt wirklich mega-informativ und ich kann mir gut vorstellen, dass man seinen Seiten etwas gutes tun kann, wenn man es beachtet.
Aber wie kann man das in der Praxis nutzen?
Mit ‚etwas’ Mühe kann man die einzelnen Informationen verstehen. Was leider überhaupt nicht verstanden wird, ist die Anwendung bzw. Umsetzung dieser Informationen in der PRAXIS 😕
Genau so interessant wie Esperanto. Soll heißen: Was genau sollen diese Informationen bringen, wenn man nicht gerade selbst eine Suchmaschine entwickeln will?