
Dieser Beitrag erläutert auf der Grundlage einiger Google-Patente und Tests wie Google aufgrund von Verknüpfungen von Suchanfragen aus der Vergangenheit den individuellen Kontext des Nutzers besser verstehen und Suggest-Vorschläge sowie Suchergebnisse besser gestalten kann. Viel Spass beim Lesen!
Inhaltsverzeichnis
Grundsätzliches zur Personalisierung von Suchergebnissen
Insofern ein Nutzer in sein Google-Konto eingeloggt ist Google in der Lage personalisierte SERPs abgestimmt auf das Nutzerverhalten und den Kontext auszuliefern. Man ist lange davon ausgegangen, dass dieser Einfluss groß bei der Auslieferung von Suchergebnissen sei. Das klingt logisch, da Google jede Menge nutzerbezogene Verhaltens-Daten je Nutzerkonto sammelt, wie man unter https://myactivity.google.com/myactivity erkennen kann.
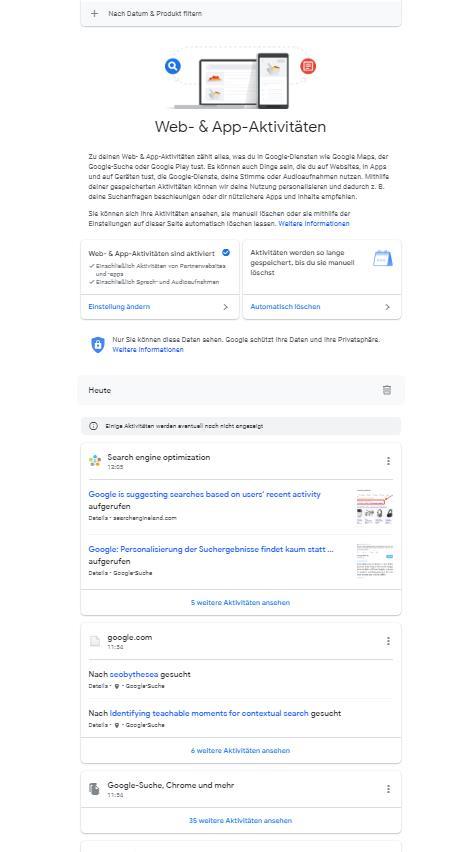
Meine Aktivitäten in der Google-Suche und anderen Anwendungen aus dem Google-System
Im Jahr 2018 gab es allerdings einige deutliche Aussagen seitens Google zum Personalisierungsgrad der SERPs. Siehe hier und hier. Demnach beschränkt sich die Personalisierung auf folgende Faktoren:
- Der Ort
- Die Sprache
- Die Zeit
- Die verwendete Plattform
- Die Verteilung auf verschiedene Datencenter
Weitere Faktoren wie die Klickrate, vergangene Suchanfragen und andere Nutzersignale wurden nicht bestätigt oder dementiert. Ich weiss aus eigener Erfahrung, dass zwischen 2012 und 2018 z.B. die Klickrate auf ein Suchergebnis einen deutlicher Faktor dafür war, dass bei der erneuten Eingabe der gleichen Suchanfrage das vorher geklickte Suchergebnis deutlich prominenter in den SERPs platziert wurde. Dazu muss ich hier betonen. Bei der Personalisierung geht es um ein nutzerbezogenes individuelles Ranking und nicht um ein generelles Scoring bestimmter Inhalte.
Immerhin zeigt Google immer noch an wenn ich ein Suchergebnis in der Vergangenheit schon geklickt habe:
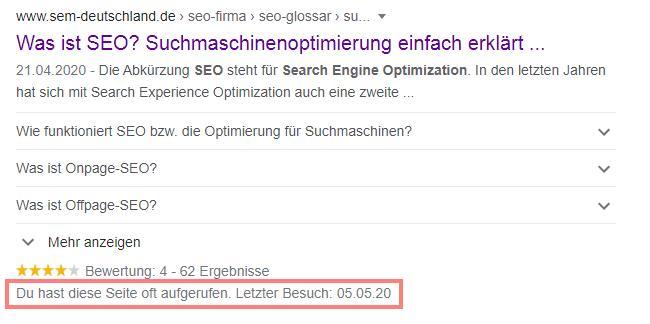
Informationen zu bereits besuchten Suchergebnissen bei Google
Einen deutlichen Einfluss auf meine persönlichen Suchergebnisse kann ich aktuell aber nicht mehr erkennen, was die Aussagen seitens Google bekräftigt.
Ich nehme an Google hat den Grad der Personalisierung wieder deutlich zurückgefahren, um die Suchergebnisse wieder objektiver zu gestalten, um eine zu einseitige Meinungsbildung zu verhindern.
Bei den Autosuggest-Vorschlägen werden individuelle nutzerbezogene Vorschläge basierend auf eigenen Suchanfragen aus der Vergangenheit vorgeschlagen. Diese lassen sich auch entfernen.
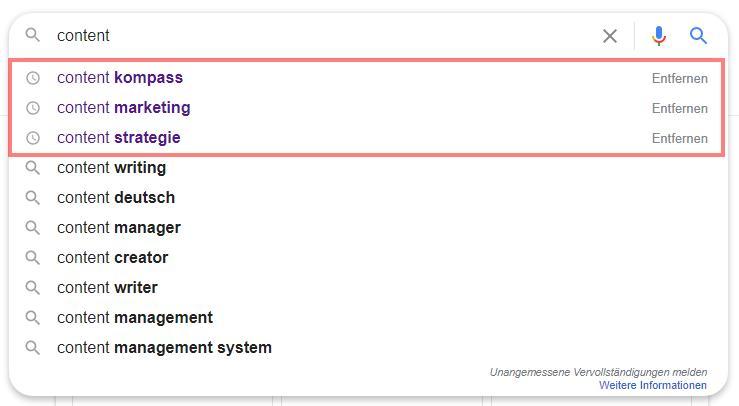
Individualisierte Autosuggest-Vorschläge bei Google
Thematischer Kontext bei Suchanfragen mit Bezug zu benannten Entitäten
Etwas anders verhält es sich bei Suchanfragen, die einen Bezug zu Entitäten haben. Hier spielt die Suchhistorie, also in der Vergangenheit getätigte Suchanfragen mit Bezug zu der jeweiligen Entität eine Rolle, wie die folgenden Tests zeigen.
Ich habe im ersten Anlauf nach Leibniz gesucht. Daraufhin ergab sich folgendes Bild:
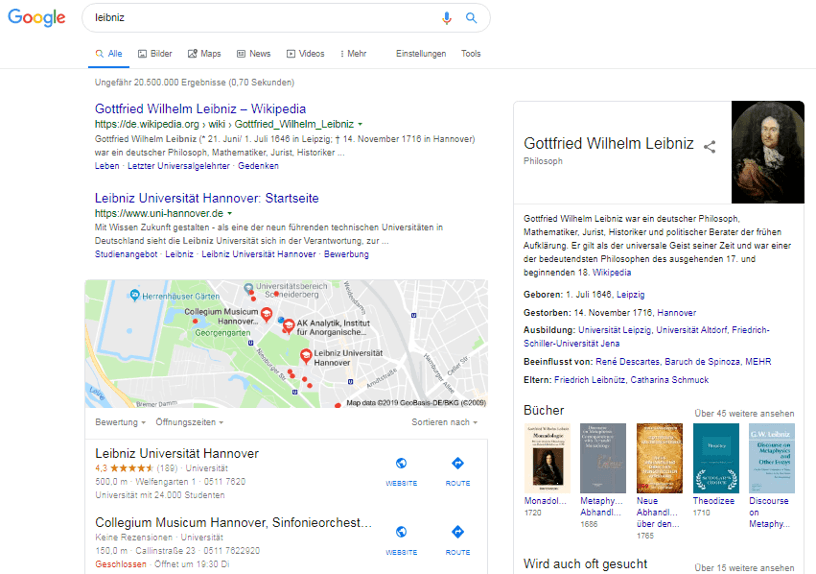
SERPs erste Suchanfrage nach der Entität „Leibniz“
Der Entitätsname ist mehrdeutig. So könnte gemeint sein:
- Der Philosoph Gottfried Wilhelm Leibniz
- Die Leibniz Universität in Hannover
- Der Leibniz Keks von Bahlsen
- IFO-Leibniz Institute in München
- Leibniz Assoziation
- diversen Songs und Bücher
Google muss bei der ersten Suchanfrage bezogen auf diese Entität entscheiden zu welcher dieser Entitäten Suchergebnisse ausgeliefert werden sollen. Google fehlt hier bisher der Kontext und so werden Ergebnisse der wahrscheinlichsten Entitäten ausgeliefert. Die Wahrscheinlichkeit bestimmt Google auf dem resultscore aus der Knowledge Graph API und bereits vorhandenen Informationen zum Nutzer.
In diesem Fall hat der Philosoph den höchsten resultscore
- Der Philosoph Gottfried Wilhelm Leibniz (resultscore: 2316.544189453125)
- IFO-Leibniz Institute in München (resultscore: 185.78216552734381)
- Der Leibniz Keks von Bahlsen (resultscore: 117.6958465576172)
- Leibniz Assoziation (resultscore: 64.970230102539062)
Die resultscores wird Google über z.B. die Popularität einer Entität ermitteln können wie in dem Beitrag Wie funktionieren Knowledge Panel & Knowledge Cards? erläutert. Für die Entität Leibniz Universität entscheidet sich Google aufgrund meines Standorts Hannover.
Als zweite Suchanfrage habe „leibniz keks“ ausgeführt. Hier ist die Entität klar durch Google zu ermitteln.
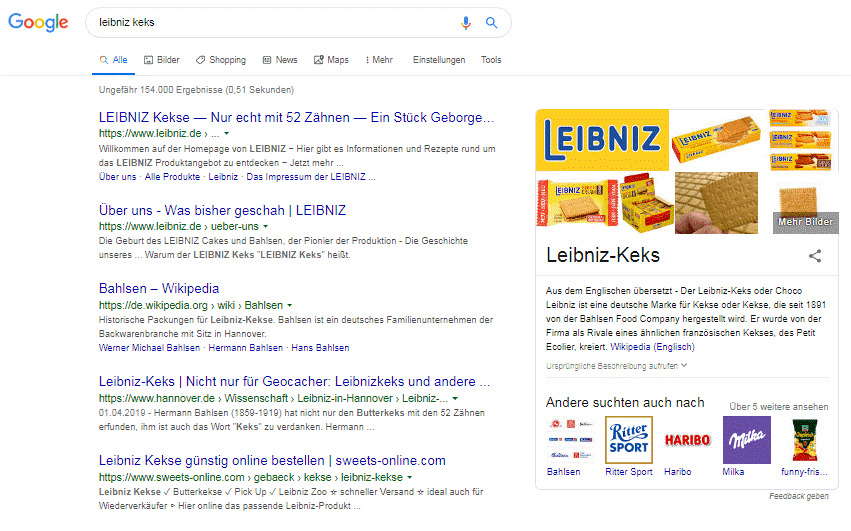
SERPs zweite Suchanfrage nach der Entität „leibniz keks“
Spannen wird es wenn man jetzt als dritte Suchanfrage in Folge wieder „leibniz“ eingibt.
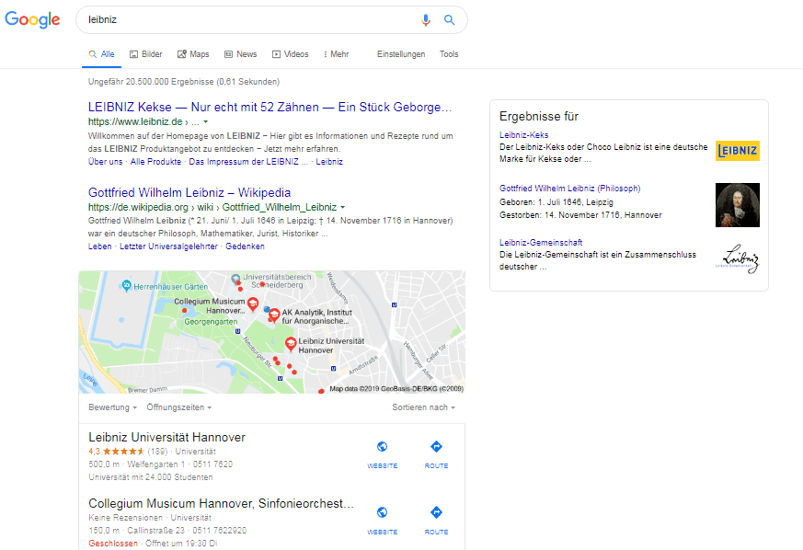
SERPs dritte Suchanfrage nach der Entität „leibniz“
Durch den geänderten thematischen Kontext aus der vorherigen Suchanfrage ist sich Google nicht mehr sicher, ob ich wirklich den Philosophen meine und tauscht Platz 1 in den SERPs gemäß der vorherigen Suchanfrage „leibniz keks“ aus. Zudem liefert Google auch kein eindeutiges Knowledge Panel mehr aus, sondern gibt mir die Möglichkeit die Suchanfrage in Richtung der Entitäten Leibniz Keks, Philosoph und Leibniz Assoziation zu verfeinern.
Ergo Google berücksichtigt den Standort als auch den thematischen Kontext vorheriger nutzerbezogener Suchanfragen. für das Ranking und Gestaltung der SERPs.
Verknüpfung Entitäten-bezogener Suchanfragen in der Voice Search
Einen weiteren Test habe ich mit meinem Google-Home gemacht. Dazu dieses Video:
Google kennt aufgrund der ersten Frage den thematischen Kontext bzw. die Entität für die ich mich interessiere und kann zumindest teilweise bei den nachfolgenden Fragen immer wieder den Kontext zur Entität herstellen. Das funktioniert leider aber nicht in der klassischen Suche, sondern nur über Google Home. Daran erkennt man aber in welche Richtung es geht und wie wichtig das Entitäten-Konzept auch für die Voice Search ist.
Google-Patente zu dem Thema
Folgende aktive Google-Patente konnte ich zu diesem Thema ausfindig machen:
Autocompletion using previously submitted query data
Dieses Google-Patent ist schon etwas älter und wurde 2009 gezeichnet. Es bildet wahrscheinlich die Grundlage generell für die Autosuggest-Vorschläge bei Google.
„The methods include receiving query information at a server system. The query information includes a portion of a query from a search requestor. The methods also include obtaining a set of predicted queries relevant to the portion of the search requestor query based upon the portion of the query from the search requestor and data indicative of search requestor behavior relative to previously submitted queries. The methods also include providing the set of predicted queries to the search requestor. Other embodiments of this aspect include corresponding systems, apparatus and computer program products.“
Laut dem Patent greift Google auf ein Set an weiteren Suchanfragen, die einen Bezug zur aktuell eingegebenen Suchanfrage zu. Diese werden dann basierend auf vorab getätigten Suchanfragen des jeweiligen Nutzers gerankt und einige wenige Vorschläge aus diesem Set als Ergänzung vorgeschlagen. Zusätzlich können in das Ranking Klickdaten, standortspezifische Daten, sprachspezifische Daten oder andere ähnliche Arten von Daten ergänzend einbezogen werden, um den jeweiligen Kontext des Nutzers noch besser zu verstehen.
Folgende Aufgaben kann diese Methode erfüllen:
- Eine Suchender erhält weiter Such-Vorschläge, bevor der Anfragende den Abschluss der Eingabe der Anfrage anzeigt.
- Zusätzlich werden Informationen gesammelt, die mit früheren Suchanfragen des Benutzers (oder der Benutzer) in Verbindung stehen (z.B. Klickdaten, die mit den Suchergebnissen verbunden sind). Aus den erhaltenen Abfrageinformationen und den vorherigen Suchinformationen wird eine Reihe von vorhergesagten Vorschlägen erstellt und dem Nutzer präsentiert.
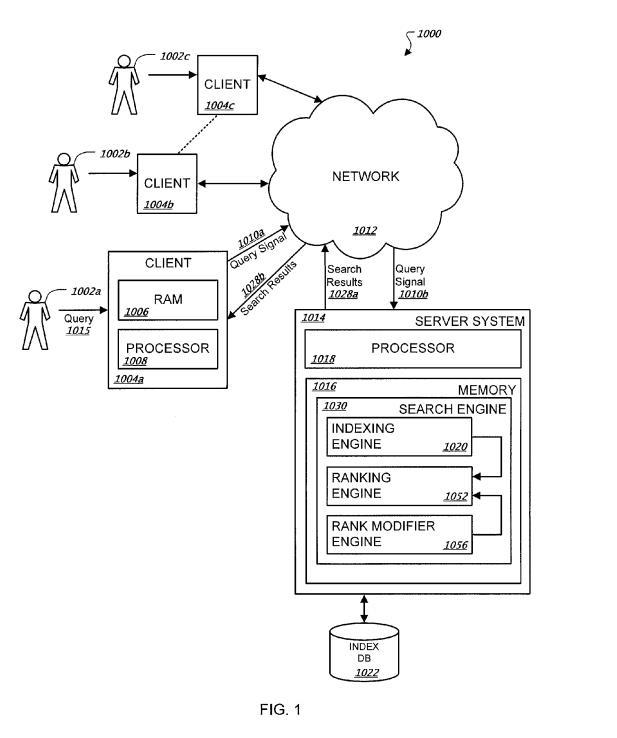
Identifying teachable moments for contextual search
 Dieses Patent wurde 2018 von Google gezeichnet und Anfang 2020 erteilt. In dem Patent wird beschrieben wie Google aufgrund einer Reihe an aufeinanderfolgenden Suchanfragen, Suchmuster erkennt. Diese Suchmuster können auf identischen Entitäten und weiteren semantisch in Verbindung miteinander stehenden Begriffen sein. Aufgrund des erkannten Musters kann Google besser den Kontext des Nutzers bzw. die Bedeutung der Suchanfrage genauer identifizieren und dementsprechend bessere Suchergebnisse ausgeben. Die Suchergebnisse können sich sowohl auf die aktuelle Suchanfrage, als auch vorangegangene Suchanfragen beziehen.
Dieses Patent wurde 2018 von Google gezeichnet und Anfang 2020 erteilt. In dem Patent wird beschrieben wie Google aufgrund einer Reihe an aufeinanderfolgenden Suchanfragen, Suchmuster erkennt. Diese Suchmuster können auf identischen Entitäten und weiteren semantisch in Verbindung miteinander stehenden Begriffen sein. Aufgrund des erkannten Musters kann Google besser den Kontext des Nutzers bzw. die Bedeutung der Suchanfrage genauer identifizieren und dementsprechend bessere Suchergebnisse ausgeben. Die Suchergebnisse können sich sowohl auf die aktuelle Suchanfrage, als auch vorangegangene Suchanfragen beziehen.
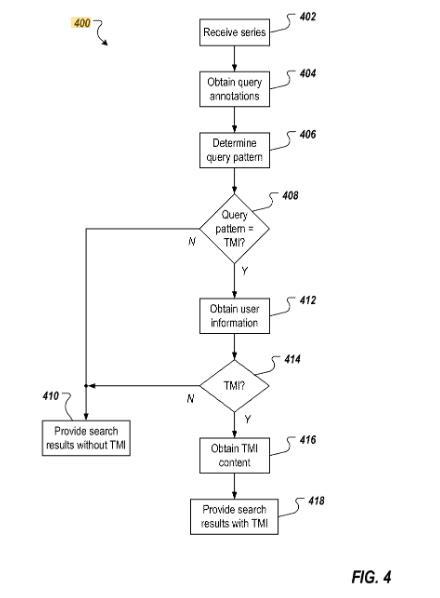
In dem Patent werden einige Beispiele für mögliche Muster aufgeführt:
Eine Beispielserie vonS uchen kann [Obama Weißes Haus], [Obamas Rede im Weißen Haus] und [Obamas Rede im Weißen Haus heute] umfassen. In dieser Beispielserie von Suchanfragen können die Begriffe der Entitäten „Obama“ im Zusammenhang mit der primären Entität „Barack Obama“ und der sekundären Entität „Präsident der Vereinigten Staaten“ sowie „Weißes Haus“ im Zusammenhang mit der sekundären Entität „Weißes Haus“ umfassen. In dieser Beispielserie sind Nicht-Entitätsbegriffe „Rede“ und „heute“ enthalten. Das Muster kann sein, dass die primäre Entität und die sekundären Entitäten innerhalb der Abfrageserie konsistent sind, z.B. mit jeder Suchanfrage der Serie assoziiert sind, und dass die Nicht-Entitätsterme innerhalb der Abfrageserie inkonsistent sind.
Eine weitere Beispielserie von Anfragen kann [Obama Reden im Weißen Haus], [Buschreden im Weißen Haus] und [Reagan Reden im Weißen Haus] umfassen. In dieser Beispielserie von Abfragen können die Begriffe der Entitäten „Obama“, „Bush“ und „Reagan“ umfassen, die jeweils mit der primären Entität „Barack Obama“, der primären Entität „George W. Bush“, der primären Entität „George H.W. Bush“, der primären Entität „Ronald Reagan“ und der sekundären Entität „Präsident der Vereinigten Staaten“ und „Weißes Haus“ in Verbindung mit der sekundären Entität „Weißes Haus“ stehen. In dieser Beispielserie von Abfragen kann ein Nicht-Entitätsbegriff „Reden“ einschließen. In diesem Beispiel kann das Abfragemuster die primäre Entität einschließen, die innerhalb der Abfrageserie inkonsistent ist, und den/die Nicht-Entitätsbegriff(e), der/die innerhalb der Abfrageserie konsistent ist/sind.
Fazit: Was können SEOs daraus lernen
Da SEOs die individuelle Personalisierung des Nutzers nicht direkt beeinflussen können sind die Erkenntnisse aus diesem Beitrag eher dafür geeignet Suchmaschinen wie Google besser zu verstehen. Man könnte sich aber genauer mit den Autosuggest-Vorschlägen bei einem Suchbegriff beschäftigen. Dabei sollte man allerdings nicht auf die eigenen individualisierten Suggest-Vorschläge achten, sondern auf die Allgemeinen. Bei der Produktion von Content kann man dann möglichst viele dieser Suggest-Vorschläge berücksichtigen und somit die Wahrscheinlichkeit erhöhen mit dem Content bei personalisierten Suchergebnissen angezeigt zu werden.
Folgende Tools eignen sich für die Identifikation allgemeiner Suchmuster:
- Answer the Public
- Hypersuggest (teils kostenpflichtig)
- Ubersuggest (großteils kostenlos)
- keywordtool.io (großteils kostenlos)
Hier ein Vergleich zu Hypersuggest und Answer the Public: https://www.aufgesang.de/blog/suggest-tools-answerthepublic-vs-hypersuggest-wer-macht-das-rennen-20224

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.