Du interessierst Dich für das Thema Natural Language Processing bzw. NLP. Dann bist Du hier genau richtig. In diesem Beitrag bekommst Du alle wichtigen Informationen zum Thema Natural Language Processing.
Inhaltsverzeichnis
- 1 Was ist Natural Language Processing ?
- 2 Welchen Formen von Machine Learning nutzt Natural Language Processing?
- 3 Wie funktioniert Natural Language Processing?
- 4 Einsatzgebiete für für Natural Language Processing
- 5 NLP vs. NLU: Wo ist der Unterschied zwischen Natural Language Processing und Natural Language Understanding
- 6 Einsatz von Natural Language Processing in Suchmaschinen
- 7 Natural Language Processing ist die wichtigste Methodik zur Identifikation von Entitäten
- 8 Verwandte Themen
- 9 FAQ zu Natural Language Processing
- 10 Weiterführende Quellen zum Thema Natural Language Processing
- 11
- 12 Weitere SEO-Fachbegriffe
Was ist Natural Language Processing ?
Natural Language Processing (NLP) ist ein Prozess zur automatischen Analyse und Darstellung der menschlichen Sprache. Natural Language Processing versucht, natürliche Sprache zu erfassen und mithilfe von Regeln und Algorithmen computerbasiert zu verarbeiten.
In anderen Worten Natural Language Processing also NLP ist der Prozess des Analysierens von Text und menschlicher Sprache durch das Herstellen von Beziehungen zwischen Wörtern, des Verstehens der Bedeutung dieser Wörter und des Ableitens eines besseren Verständnisses der Bedeutung der Wörter, um daraus Informationen, Wissen oder neuen Text zu generieren
Welchen Formen von Machine Learning nutzt Natural Language Processing?
Natural Language Processing setzt auf verschiedene Arten von Machine Learning wie Supervised Machine Learning und Unsupervised Machine Learning, um auf Basis statistischer Modelle sowie Vektorraumanalysen Inhalt und Struktur von Texten und gesprochener Sprache zu erkennen. Neuere NLP-Ansätze beschäftigen sich auch mit Methoden für die Textgenerierung und Labeling (Kennzeichnung) über Reinforcement Learning (Bestärkendes Lernen) via Semi- oder Weak Supervised Machine Learning.
Wie funktioniert Natural Language Processing?
Generell kann man die Funktionsweise von NLP gobe in die folgendenden Prozessschritte aufgliedern:
- Datenbereitstellung
- Datenvorbereitung
- Textanalyse
- Textanreicherung
Klassisch beginnt der Prozess mit der Datenbereitstellung über einen Textkorpus, welcher aus mehreren Dokumenten besteht. Diese bestehen aus mindestens einem Wort, meistens aber aus mehreren Sätzen. Ein Textkorpus wären z.B. alle relevanten Dokumente zum Thema SEO. Die einzelnen Dokumente bestehen aus Kapiteln, Absätzen und Sätzen. Die Sätze werden dann pro Satz in einzelne Tokens zerlegt. Hier ein Beispiel aus einem Glossar-Beitrag zu SEO:
Suchmaschinenoptimierung kurz SEO ist eine Methode im Online-Marketing, um die Auffindbarkeit in Suchmaschinen zu verbessern. Die Abkürzung SEO steht für Search Engine Optimization. In den letzten Jahren hat sich mit Search Experience Optimization auch eine zweite Bedeutung durchgesetzt. In der klassischen Suchmaschinenoptimierung wird zwischen Onpage-SEO und Offpage-SEO unterschieden.
Die einzelnen Tokens bleiben im Kontext der Sätze, damit die Relationen zwischen ihnen erhalten bleiben. Dadurch bleibt die semantische Beziehung der Absätze, Sätze und Tokens erhalten. In dem Prozessschritt der Datenvorbereitung werden die einzelnen Tokens noch mit Labels bzw. Annotationen versehen.
Das so kommentierte Dokument dient als Grundlage für weitere vorbereitende Maßnahmen wie Text-Embeddings oder die Erkennung und Deutung von Entitäten (Entity Recognition).
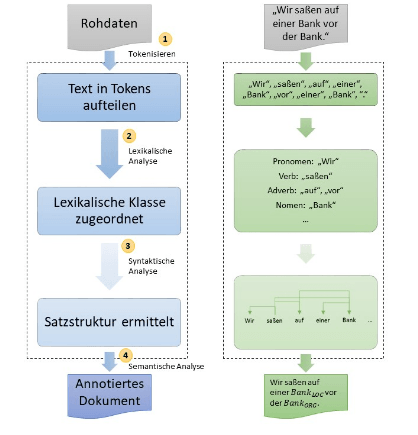
Prozess der Sprachmodellierung; Quelle: http://www.datenbanken-verstehen.de/lexikon/natural-language-processing/
Dann können im nächsten Schritt Modelle auf die vorbereiteten Dokumente angewendet werden. Diese Sprachmodelle werden auf Basis von Machine Learning bzw. Trainingsdaten erlernt. In diesem Prozessschritt werden die Trainingsdaten in Tokens aufgeteilt, einer lexikalischen Klasse zugeordnet und Satzstrukturen ermittelt. In der abschließenden semantischen Analyse werden Entitäten identifiziert und gemäß ihrer Bedeutung mit Kommentaren versehen.
Die Kernkomponenten von NLP sind Tokenization zu deutsch Tokenisierung, Kennzeichnung von Wörtern nach Wortarten (Part of Speech Tagging), Lemmatisierung, Wort-Abhängigkeiten (Dependency Parsing), Parse Labeling, Extraktion von benannten Entitäten (Named Entity Recognition), Salience-Scoring, Sentiment-Analysen, Kategorisierung, Text-Klassifizierung, Extrahierung von Content-Typen und Identifikation einer impliziten Bedeutung aufgrund der Struktur.
- Tokenisierung: Tokenisierung ist der Vorgang, bei dem ein Satz in verschiedene Begriffe unterteilt wird.
- Kennzeichnung von Wörtern nach Wortarten: Wortartenkennzeichnung klassifiziert Wörter nach Wortarten wie z.B. Subjekt, Objekt, Prädikat, Adjektiv …
- Wortabhängigkeiten: Wortabhängigkeiten schafft Beziehungen zwischen den Wörtern basierend auf Grammatikregeln. Dieser Prozess bildet auch „Sprünge“ zwischen Wörtern ab.
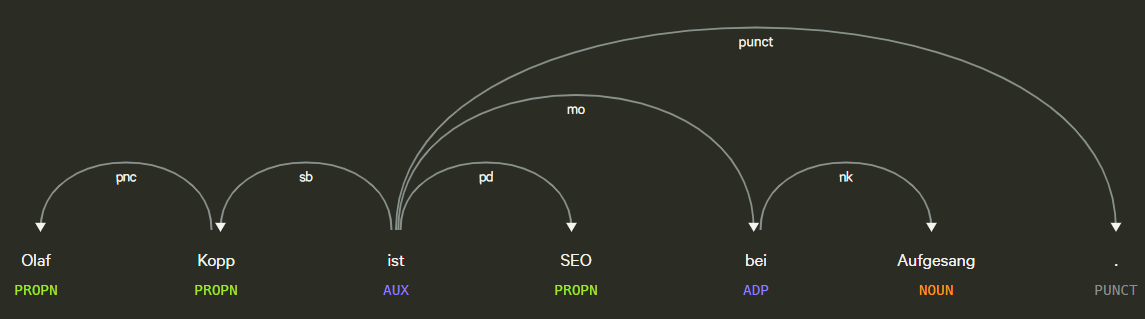
Beispiel für Part of Speech Tagging und Dependency Parsing, Quelle: Explosion.ai Demo
- Lemmatisierung: Die Lemmatisierung bestimmt, ob ein Wort verschiedene Formen hat und normalisiert Abwandlungen zur Grundform,. Zum Beispiel ist die Grundform von Tiere, Tier oder von verspielt, Spiel.
- Parsing Labels: Die Kennzeichnung klassifiziert die Abhängigkeit oder die Art der Beziehung zwischen zwei Wörtern, die über eine Abhängigkeit verbunden sind.
- Analyse und Extraktion von benannten Entitäten: Dieser Aspekt sollte uns aus den vorangegangenen Beiträgen bekannt sein. Damit wird versucht, Wörter mit einer „bekannten“ Bedeutung zu identifizieren und Klassen von Entitätstypen zuzuordnen. Im Allgemeinen sind benannte Entitäten Menschen, Orte und Dinge (Substantive). Entitäten können auch Produktnamen enthalten. Dies sind im Allgemeinen die Wörter, die ein Knowledge Panel auslösen. Aber auch Begriffe, die kein eigenes Knowledge Panel auslösen können Entität sein. Dazu mehr im Beitrag Was ist eine Entität ? Was sind Entitäten ?
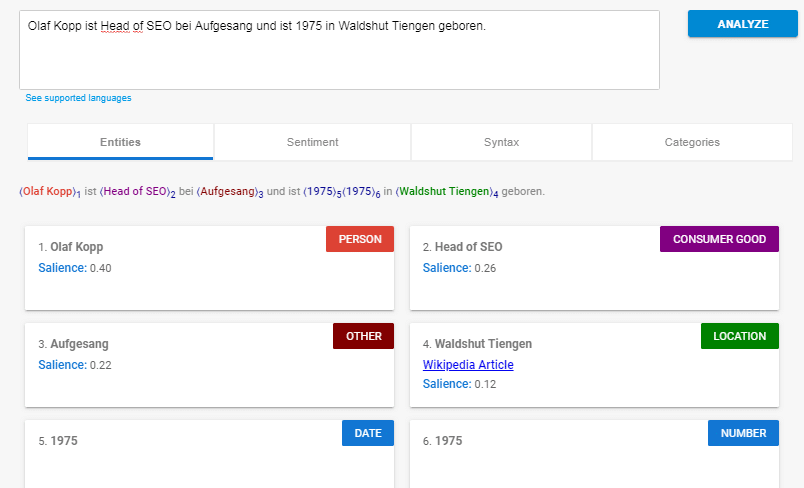
Beispiel für eine Entitäten-Analyse mit der Natural Language Processing API von Google.
- Salience-Scoring: Salience bestimmt, wie intensiv ein Text sich mit einem Thema beschäftigt. Dies wird in NLP basierend auf den sogenannten Indikatorwörtern bestimmt. Im Allgemeinen wird der Bekanntheitsgrad durch das Mitzitieren von Wörtern im Web und die Beziehungen zwischen Entitäten in Datenbanken wie Wikipedia und Freebase bestimmt. Google wendet dieses Verknüpfungsdiagramm wahrscheinlich auch auf die Entitätsextraktion in Dokumenten an, um diese Wortbeziehungen zu bestimmen. Eine ähnliches Vorgehen kennen erfahrene SEOs von der TF-IDF-Analyse.
- Sentiment-Analysen: Kurz gesagt, dies ist eine Bewertung der in einem Artikel zum Ausdruck gebrachten Meinung (Ansicht oder Haltung) zum im Text behandelten Entitäten.
- Fachkategorisierung: Auf Makroebene klassifiziert NLP Text in Betreffkategorien. Die Kategorisierung von Themen hilft dabei, allgemein zu bestimmen, worum es in dem Text geht.
- Textklassifizierung & Funktion: NLP kann noch weiter gehen und die beabsichtigte Funktion bzw. Zweck des Inhalts bestimmen.
- Extrahierung von Content-Typen: Google kann mithilfe von Strukturmustern bzw. des Kontext den Inhaltstyp eines bestimmten Texts ohne die Ausweisung mit strukturierten Daten bestimmen. Das HTML, die Formatierung des Texts und der Datentyp des Texts (Datum, Ort, URL usw.) können verwendet werden, um den Text ohne zusätzliches Markup zu verstehen Mithilfe dieses Prozesses kann Google ermitteln, ob es sich bei Text um ein Ereignis, ein Rezept, ein Produkt oder einen anderen Inhaltstyp handelt, ohne dass Markups verwendet werden müssen.
- Identifikation einer impliziten Bedeutung aufgrund der Struktur: Die Formatierung eines Textkörpers kann seine implizite Bedeutung ändern. Überschriften, Zeilenumbrüche, Listen und Nähe vermitteln ein sekundäres Verständnis des Textes. Wenn beispielsweise Text in einer HTML-sortierten Liste oder in einer Reihe von Überschriften mit Zahlen davor angezeigt wird, handelt es sich wahrscheinlich um einen Vorgang oder eine Rangfolge. Die Struktur wird nicht nur durch HTML-Tags definiert, sondern auch durch die visuelle Schriftgröße / -stärke und -nähe beim Rendern.
Einige dieser Kerneleemente von Natural Language Processing sollten Dir durch die vorhergenden Beiträge dieser Artikelreihe bekannt sein wie z.B. die Extrahierung benannter Entitäten oder Identifikation einer impliziten Bedeutung aufgrund von Struktur-Elementen.
Dass Google viele dieser Prozesse bereits beherrscht zeigt die Natural Language Processing API, auf die ich nachfolgend eingehen möchte.
Einsatzgebiete für für Natural Language Processing
Natural Language Processing wird auf viele verschiedene Arten verwendet, darunter Spracherkennung, Text-zu-Sprache-Synthese, maschinelle Übersetzung, Beantwortung von Fragen, Zusammenfassung, Stimmungsanalyse und mehr. Es hat Anwendungen in vielen Bereichen, wie Gesundheitswesen, Bildung, Finanzen, Recht, Kundenservice, Suchmaschinen und Regierung.
Für folgende Anwendungsbreiche kann Natural Language Processing eingesetzt werden:
- Spracherkennung (text to speech & speech to text)
- Segmentierung zuvor erfasster Sprache in einzelne Wörter, Sätze und Phrasen.
- Erkennen der Grundformen der Wörter und Erfassung grammatischer Informationen
- Erkennen der Funktionen einzelner Wörter im Satz (Subjekt, Verb, Objekt, Artikel, etc.)
- Extraktion der Bedeutung von Sätzen und Satzteilen bzw. Phrasen wie Adjektivphrasen (z.B. zu langen), Präpositionalphrasen (z.B. an den Fluss) oder Nominalphrasen (z.B. der zu langen Party)
- Erkennen von Satzzusammenhängen, Satzbeziehungen und Entitäten.
- Erkennen von Sentiment in Sprache und Text sowie rund um um Entitäten.
- Ausgabe von Text und Sprache
Natural Language Processing kann sowohl für die linguistische Textanalyse, Stimmungs- und Meinungs-Analyse (Sentimentanalyse), Übersetzungen als auch für Sprachassistenten, Chatbots und zu Grunde liegenden Frage- & Antwort-Systemen zum Einsatz kommen.
NLP vs. NLU: Wo ist der Unterschied zwischen Natural Language Processing und Natural Language Understanding
Natural Language Understanding kurz NLU ist ein Teilbereiche von Natural Language Processing.
Ähnlich benannt befassen sich beide Konzepte mit der Beziehung zwischen natürlicher Sprache (wie wir als Menschen sprechen, nicht was Computer verstehen) und künstlicher Intelligenz.
Sie verfolgen das gemeinsame Ziel, Konzepte, die in unstrukturierten Daten wie Sprache dargestellt sind, besser zu verstehen als strukturierte Daten wie Statistiken, Aktionen usw. Zu diesem Zweck sind NLP und NLU Gegensätze zu vielen anderen Data-Mining-Techniken. Aber hier hören die Vergleiche auf: NLU und NLP sind nicht dasselbe.
NLP umfasst zwei Hauptarbeitsbereiche: Natural Language Understanding (NLU) und Natural Language Generation (NLG). Natural Language Generation (NLG) bezieht sich auf jede Technologie, die es Computern ermöglicht, Text in menschlicher Sprache zu generieren. NLG-Systeme können für eine Vielzahl von Zwecken verwendet werden, einschließlich Zusammenfassung, Dialogmanagement, Fragebeantwortung und Chatbots.
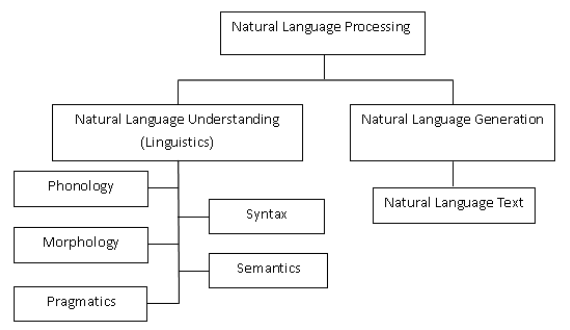
Quelle: https://ichi.pro/de/ein-blick-in-die-verarbeitung-naturlicher-sprache-nlp-84326662468171
Natural Language Understanding ist eine Technologie, die es Computern ermöglicht, menschliche Sprache zu verstehen.
Als Unterthema von NLP ist das NLU ein wesentlicher Bestandteil für ein erfolgreiches NLP. NLU hat einen engeren Zweck und konzentriert sich in erster Linie auf das maschinelle Leseverständnis: Den Computer dazu zu bringen, zu verstehen, was ein Textkörper wirklich bedeutet.
Das Verständnis der natürlichen Sprache kann auf eine Vielzahl von Prozessen angewendet werden, z. B. das Kategorisieren von Text, das Sammeln von Nachrichten, das Archivieren einzelner Textteile und in größerem Maßstab das Analysieren von Inhalten.
Beispiele für NLUs in der Praxis reichen von kleinen Aufgaben wie dem Ausgeben von kurzen Befehlen zum Verstehen von Text bis hin zum Umleiten einer E-Mail an die richtige Person auf der Grundlage einer Basissyntax und eines angemessen großen Lexikons. Viel komplexeres Unterfangen könnte darin bestehen, Nachrichtenartikel oder Bedeutungsnuancen in Gedichten oder Romanen vollständig zu erfassen.
NLU ist am besten als erster Schritt zur Erreichung von NLP anzusehen: Bevor eine Maschine eine Sprache verarbeiten kann, muss sie zuerst verstanden werden.
Ein guter Weg, um den Unterschied zwischen NLP und NLU zu verstehen? Es handelt sich um Natural Language Understanding, wenn es sich nur auf die Fähigkeit einer Maschine bezieht, unsere Sprache und das, was wir sagen, zu verstehen. Wenn es um mehr als das geht, wie das Treffen von Entscheidungen auf der Grundlage des Textes, das Reagieren auf den Inhalt wie in einem Chatbot, der mit einem Menschen spricht, wird wahrscheinlich das umfassendere Konzept von Natural Language Processing mit einbezogen.
Einsatz von Natural Language Processing in Suchmaschinen
Ich denke, dass Natural Language Processing in Bezug auf die Google-Suche vor allem in den folgenden Bereichen genutzt wird:
- Interpretation von Suchanfragen und Dokumenten (Rankbrain, BERT & MUM)
- Klassifizierung von Thema und Zweck von Dokumenten
- Entitäten-Analyse in Dokumenten, Suchanfragen und Social-Media-Posts
- Für Featured Snippets und Voice Search
- Interpretation von Video-Inhalten
- Ausbau und Verbesserung des Knowledge Graphs
Natural Language Processing ist die wichtigste Methodik zur Identifikation von Entitäten
Wie im Beitrag Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ? erläutert spielt Natural Language Processing bei der Identifikation von Entitäten und deren Bedeutung aktuell die wichtigste Rolle für Google.
Die Praxis zeigt allerdings, dass Google bisher nur sehr begrenzt auf unstrukturierte Informationen zurückgreift, zumindest was die Ausspielung in den Knowledge Panels angeht. Erste praktische Anwendungen für Data Mining aus unstrukturierten Daten finden wir in den Featured Snippets wieder, obwohl das eher nach dem direkten Einsatz von Natural Language Processing aussieht ohne den Knowledge Graph einzubeziehen.
Auch bei bisher nicht im Knowledge Graph erfassten Entitäten arbeitet Google aktuell nur mit NLP, um diese zu identifizieren, unabhängig vom Knowledge Graph. Für die Identifikation von Entitäten und thematische Einordnung leistet Natural Language Processing gute Dienste. Allerdings wäre dadurch nur das Kriterium der Vollständigkeit ggf. Aktualität gewährleistet. NLP alleine gewährleistet aber nicht den Anspruch auf Richtigkeit.
Ich denke, dass Google im Bereich Natural Language Processing schon recht gut ist, aber bei der Evaluation von automatisch extrahierten Informationen hinsichtlich Richtigkeit noch nicht zufriedenstellende Ergebnisse erzielt. Das wird wohl der Grund sein, warum Google hier noch vorsichtig agiert, was direkte Positionierung in den SERPs angeht.
Verwandte Themen
- maschinelles Lernen
- künstliche Intelligenz
- Text-Mining
- Datenwissenschaft
- semantische Analyse
- Informationsextraktion
- Informationsmanagement
FAQ zu Natural Language Processing
Was bedeutet Natural Language Processing
Natural Language Processing (NLP) ist ein Prozess zur automatischen Analyse und Darstellung der menschlichen Sprache. Natural Language Processing versucht, natürliche Sprache zu erfassen und mithilfe von Regeln und Algorithmen computerbasiert zu verarbeiten. NLP setzt auf verschiedene Arten von Supervised Machine Learning und Unsupervised Machine Learning, um auf Basis statistischer Modelle sowie Vektorraumanalysen Inhalt und Struktur von Texten und gesprochener Sprache zu erkennen.
Wie funktioniert Natural Language Processing?
Generell kann man die Funktionsweise von NLP gobe in die folgendenden Prozessschritte aufgliedern: - Datenbereitstellung - Datenvorbereitung - Textanalyse - Textanreicherung Mehr dazu in diesem Beitrag.
Wo wird NLP eingesetzt?
Für folgende Anwendungsbreiche kann Natural Language Processing eingesetzt werden: - Spracherkennung (text to speech & speech to text) - Segmentierung zuvor erfasster Sprache in einzelne Wörter, Sätze und Phrasen. - Erkennen der Grundformen der Wörter und - - - Erfassung grammatikalischer Informationen - Erkennen der Funktionen einzelner Wörter im Satz (Subjekt, Verb, Objekt, Artikel, etc.) - Extraktion der Bedeutung von Sätzen und Satzteilen bzw. Phrasen wie Adjektivphrasen (z.B. zu langen), Präpositionalphrasen (z.B. an den Fluss) oder Nominalphrasen (z.B. der zu langen Party) - Erkennen von Satzzusammenhängen, Satzbeziehungen und Entitäten.
Weiterführende Quellen zum Thema Natural Language Processing
- http://ruder.io/nlp-imagenet/
- http://ruder.io/a-review-of-the-recent-history-of-nlp/
- https://medium.com/@lola.com/nlp-vs-nlu-whats-the-difference-d91c06780992
Weitere SEO-Fachbegriffe
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023
Blog-Artikel zu diesem Thema
Die Google Suche: So funktioniert das Ranking der Suchmaschine heute
 Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf di... Artikel anzeigen
Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf di... Artikel anzeigen
Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO
 Google hat dieses Jahr viele Patente veröffentlicht und erneut veröffentlicht. Dieser Artikel behandelt die 11 interessantesten Google-Patente.
Die Recherche zu Google-Patenten ist eine der intelligentesten Möglichkeiten, moderne Suchmaschinen wie Google zu verstehen.
Ein Pionier der Google... Artikel anzeigen
Google hat dieses Jahr viele Patente veröffentlicht und erneut veröffentlicht. Dieser Artikel behandelt die 11 interessantesten Google-Patente.
Die Recherche zu Google-Patenten ist eine der intelligentesten Möglichkeiten, moderne Suchmaschinen wie Google zu verstehen.
Ein Pionier der Google... Artikel anzeigen
Googles Weg zur semantischen Suchmaschine
 In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
Wie versteht Google Suchanfragen durch Search Query Processing?
 Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index
 Die Basis für das Google-Ranking waren bis 2013 Websites, deren Content, Keywords und Backlinks. Mit dem Hummingbird-Update und dem Google Knowledge Graph startete Google die eigene Transformation zur semantischen Suchmaschine. Entitäten spielen bei dieser Transformation mit Blick auf die Indexier... Artikel anzeigen
Die Basis für das Google-Ranking waren bis 2013 Websites, deren Content, Keywords und Backlinks. Mit dem Hummingbird-Update und dem Google Knowledge Graph startete Google die eigene Transformation zur semantischen Suchmaschine. Entitäten spielen bei dieser Transformation mit Blick auf die Indexier... Artikel anzeigen
Wie schlau ist Google? Echtes semantisches Verständnis oder nur Statistik?
 Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Die semantische Bedeutung von Keywords bei modernen Suchmaschinen
 In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
 In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
E-A-T als kritischer Rankingeinfluss: 10 Tipps für die Optimierung
 Aufzeichnung meines Vortrags auf der virtuellen Search Seekers Konferenz präsentiert von der SMX. E-A-T ist seit Jahren einer der meist genannten Einflussfaktoren auf das Ranking. Seitens Google gibt es, aber wenig konkrete Informationen, was sich genau hinter E-A-T verbirgt. In diesem Vortrag wird... Artikel anzeigen
Aufzeichnung meines Vortrags auf der virtuellen Search Seekers Konferenz präsentiert von der SMX. E-A-T ist seit Jahren einer der meist genannten Einflussfaktoren auf das Ranking. Seitens Google gibt es, aber wenig konkrete Informationen, was sich genau hinter E-A-T verbirgt. In diesem Vortrag wird... Artikel anzeigen
Video: Entitäten basierte Suche – Alles zum Knowledge Graph, NLP, Ranking, E A T und Semantik in der SEO
 Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
 Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Entitäten & E-A-T: Die Rolle von Entitäten bei Autorität und Trust
 Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
Wie kann Google über Entitäten, NLP & Vektorraumanalysen relevante Dokumente identifizieren und ranken?
 Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO beschäftigt sich damit wie Google für Suchanfragen mit Entitäten-Bezug u.a. über Natural Language Language Processing und Vektorraumanalysen passende Inhalte identifiziert und rankt. Dazu habe ich über 20 Google-Patente un... Artikel anzeigen
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO beschäftigt sich damit wie Google für Suchanfragen mit Entitäten-Bezug u.a. über Natural Language Language Processing und Vektorraumanalysen passende Inhalte identifiziert und rankt. Dazu habe ich über 20 Google-Patente un... Artikel anzeigen
Google MUM Update: Was erwartet SEOs in der Zukunft?
 In diesem Beitrag gehe ich auf das Google MUM-Update ein, dass Google 2021 vorgestellt hat. Ich gehe auf die Neuigkeiten ein, die auf die Suchmaschinen-Nutzer und SEOs in den nächsten Jahren durch MUM zukommen werden. Zudem gehe ich darauf ein wie SEOs und Webmaster darauf vorbereiten können.
Was... Artikel anzeigen
In diesem Beitrag gehe ich auf das Google MUM-Update ein, dass Google 2021 vorgestellt hat. Ich gehe auf die Neuigkeiten ein, die auf die Suchmaschinen-Nutzer und SEOs in den nächsten Jahren durch MUM zukommen werden. Zudem gehe ich darauf ein wie SEOs und Webmaster darauf vorbereiten können.
Was... Artikel anzeigen
Indexierung und SERP-Auslieferung nach Themen bzw. Entitäten
 Dieser Beitrag beschäftigt sich mit einem Google Patent aus Juni 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Content bestimmten Entitäten / Themen zuordnet und in ein Ranking überführt. Interessant ist dieser Beitrag für fortgeschrittene SEOs, Content-Verantwortliche und Lehr... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google Patent aus Juni 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Content bestimmten Entitäten / Themen zuordnet und in ein Ranking überführt. Interessant ist dieser Beitrag für fortgeschrittene SEOs, Content-Verantwortliche und Lehr... Artikel anzeigen
Youtube: Interpretation und Ranking von Videos via Entitäten
 Dieser Beitrag beschäftigt sich mit einem Google Patent aus Dezember 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Entitäten in einem Video z.B. bei Youtube erkennen kann. Aufgrund von Features, die man bereits in der Google-Suche und bei Youtube vorfindet ist es sehr wahrscheinli... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google Patent aus Dezember 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Entitäten in einem Video z.B. bei Youtube erkennen kann. Aufgrund von Features, die man bereits in der Google-Suche und bei Youtube vorfindet ist es sehr wahrscheinli... Artikel anzeigen
Personalisierung und Darstellung von Informationen zu einer Entität
 Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
SMX-Vortrag: Entitäten, Knowledge Graph & Natural Language Processing als Grundpfeiler der Google-Suche
 Im März 2021 habe ich auf der virtuellen SMX einen Vortrag zum Thema "Entitäten, Knowledge Graph, Natural Language Processing und E-A-T als Grundpfeiler der Google-Suche" gehalten. Für meine Premium-Mitglieder habe ich den Vortrag mit Erlaubnis der SMX online gestellt.
... Artikel anzeigen
Im März 2021 habe ich auf der virtuellen SMX einen Vortrag zum Thema "Entitäten, Knowledge Graph, Natural Language Processing und E-A-T als Grundpfeiler der Google-Suche" gehalten. Für meine Premium-Mitglieder habe ich den Vortrag mit Erlaubnis der SMX online gestellt.
... Artikel anzeigen
Das Internet als Datengraph und wie Google daraus Informationen zu Entitäten extrahiert
 Dieser Beitrag ist eine Übersetzung des Originals THE WEB AS A DATA GRAPH IS A NEW DIRECTION FOR SEO von Bill Slawski.
Viele der Artikel, die Leute über SEO schreiben, haben mit Webseiten und Links zwischen Seiten zu tun, aber in diesem Beitrag geht es um
Entitäten und Beziehungen zwisc... Artikel anzeigen
Dieser Beitrag ist eine Übersetzung des Originals THE WEB AS A DATA GRAPH IS A NEW DIRECTION FOR SEO von Bill Slawski.
Viele der Artikel, die Leute über SEO schreiben, haben mit Webseiten und Links zwischen Seiten zu tun, aber in diesem Beitrag geht es um
Entitäten und Beziehungen zwisc... Artikel anzeigen
Wie Google Ergebnisse für ein Featured Snippet auswählen kann
 Ein diese Woche veröffentlichtes Update zu einem Patent verrät uns, wie Google die Ergebnisse für ein Snippet bewerten kann.
Wenn eine Suchmaschine eine Rangfolge von Suchergebnissen als Antwort auf eine Suchanfrage erstellt, kann sie eine Kombination aus anfrageabhängigen und anfrageunabhän... Artikel anzeigen
Ein diese Woche veröffentlichtes Update zu einem Patent verrät uns, wie Google die Ergebnisse für ein Snippet bewerten kann.
Wenn eine Suchmaschine eine Rangfolge von Suchergebnissen als Antwort auf eine Suchanfrage erstellt, kann sie eine Kombination aus anfrageabhängigen und anfrageunabhän... Artikel anzeigen
Digitale Sprachassistenten – Das Marketing der Absichten
 Seit Digitale Sprachassistenten in die Wahrnehmung und Geldbeutel der breiten Masse gefunden haben, wird nicht nur die Entwicklung der Systeme selbst mit Hochdruck angetrieben, sondern auch Marken und Unternehmen suchen ihren Eintrittspunkt in den Markt und die Anwendung von "Smart Voice". Im folgen... Artikel anzeigen
Seit Digitale Sprachassistenten in die Wahrnehmung und Geldbeutel der breiten Masse gefunden haben, wird nicht nur die Entwicklung der Systeme selbst mit Hochdruck angetrieben, sondern auch Marken und Unternehmen suchen ihren Eintrittspunkt in den Markt und die Anwendung von "Smart Voice". Im folgen... Artikel anzeigen
Eindeutige Suchanfragen helfen Google, die Suchintention besser zu verstehen
 Zum Anfang des Beitrags, wollte ich einige Whitepaper einbeziehen, an denen Autoren aus dem Hause Google beteiligt sind. Die Autoren des ersten Papiers sind die Erfinder einer Patentanmeldung, die am 28. April 2020 veröffentlicht wurde. Diese Whitepaper sind lesenswert, um einen Eindruck davon zu b... Artikel anzeigen
Zum Anfang des Beitrags, wollte ich einige Whitepaper einbeziehen, an denen Autoren aus dem Hause Google beteiligt sind. Die Autoren des ersten Papiers sind die Erfinder einer Patentanmeldung, die am 28. April 2020 veröffentlicht wurde. Diese Whitepaper sind lesenswert, um einen Eindruck davon zu b... Artikel anzeigen
Knowledge Graph für alle: Google führt personenbezogene Search Profile Cards ein
 Die semantische Suche hält mit großen Schritten Einzug bei Google. Die Search Profile Cards erlauben unabhängig von Wikipedia und Einträgen bei Wikidata Personen sich als Entität bei Google zu registrieren.
Die Search Cards als Eintritt in den Knowledge Graph für jedermann
Meine Vermutung is... Artikel anzeigen
Die semantische Suche hält mit großen Schritten Einzug bei Google. Die Search Profile Cards erlauben unabhängig von Wikipedia und Einträgen bei Wikidata Personen sich als Entität bei Google zu registrieren.
Die Search Cards als Eintritt in den Knowledge Graph für jedermann
Meine Vermutung is... Artikel anzeigen
Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google
 Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
























