Du interessierst Dich für das Thema Machine Learning bzw. Artificial Intelligence (AI). Dann bist Du hier genau richtig. In diesem Beitrag bekommst Du alle wichtigen Informationen zum Thema Machine Learning.
Inhaltsverzeichnis
- 1 Was ist Machine Learning?
- 2 Zusammenfassung
- 3 Was ist Deep Learning?
- 4 Was sind Neuronale Netze?
- 5 Wie funktionieren neuronale Netzwerke?
- 6 Unterscheidung zwischen Machine Learning und Künstlicher Intelligenz
- 7 Einsatzgebiete für Machine Learning im Marketing
- 8 Welche Machine-Learning-Arten gibt es?
- 9 Welche Machine Learning Algorithmen gibt es?
- 10 Unterschied zwischen Machine Learning und Deep Learning
- 11 Warum Machine Learning immer wichtiger wird?
- 12 Was ist der Unterschied zwischen maschinell Gelerntem und Heuristiken?
- 13 Wo ist der Unterschied zwischen Machine Learning und Statistik?
- 14 Abgrenzung zwischen Machine Learning und Semantik
- 15 Welche Programmiersprachen nutzt man für Machine Learning?
- 16 Häufig gestellte Fragen zum Thema Machine Learning
Was ist Machine Learning?
Machine Learning zu deutsch maschinelles Lernen ist ein Teilgebiet von Artificial Intelligence (zu deutsch Künstliche Intelligenz) und beschreibt dymanische Algorithmen, die in der Lage sind eigenständig dazuzulernen, um Ergebnisse bzw. die Performance zu verbessern.
Maschinelles Lernen verwendet Algorithmen, um Ergebnisse basierend auf vergangenen Daten vorherzusagen.
Zusammenfassung
Du willst nicht alles zum Thema Machine Learning lesen? Kein Problem. Hier eine kurze Zusammenfassung:
- Deep Learning ist ein Unterbereich des Machine Learnings und nutzt neuronale Netze, um Computer das Lernen aus Daten zu ermöglichen. Es hat Anwendungen in Bereichen wie Computer Vision und Gesichtserkennung. Neuronale Netze, inspiriert vom menschlichen Gehirn, erkennen wiederkehrende Muster in Daten.
- Es gibt drei Arten des Machine Learnings: Überwachtes, Unüberwachtes und Bestärkendes Lernen, wobei jedes verschiedene Ansätze zum Lernen aus Daten verfolgt.
- Machine Learning und Deep Learning sind Teil der Künstlichen Intelligenz (KI), die darauf abzielt, menschenähnliche Entscheidungsprozesse zu simulieren.
- Verschiedene Algorithmen und Programmiersprachen wie Python, R und C++ werden in Machine Learning eingesetzt, um Vorhersagen auf Grundlage von Daten zu treffen.
- Unterschiede zwischen Machine Learning und Statistik sowie zwischen Machine Learning und Semantik werden hervorgehoben, wobei erstere auf prädiktive Analysen und letztere auf die Bedeutungserkennung abzielen.
Was ist Deep Learning?
Deep Learning bedeutet die Verwendung neuronaler Netze, um Computer zu trainieren, aus Daten zu lernen. Deep Learning wurde verwendet, um Computer-Vision-Systeme wie selbstfahrende Autos, Gesichtserkennungssoftware und Bildunterschriften zu erstellen. Das Ziel von Deep Learning besteht darin, Computern beizubringen, aus Rohdaten und nicht aus programmierten Regeln zu lernen.
Deep Learning ist ein Teilbereich des Machine Learnings, könnte auch als Weiterentwicklung bezeichnet werden.
Was sind Neuronale Netze?
Neural Network zu deutsch Neuronale Netzwerke sind Gruppen von Algorithmen, die gemäß eines menschlichen Gehirns aufgebaut sind, um wiederkehrende Muster zu erkennen und diese daraufhin zu ordnen bzw. zu etikettieren. Die erkannten Muster werden in mathematisch Vektoren übersetzt.
Neuronale Netze werden zur Bilderkennung, Spracherkennung und Verarbeitung natürlicher Sprache verwendet. Das erste neuronale Netz wurde 1943 von Warren McCulloch und Walter Pitts an der University of Chicago erfunden.
Neuronale Netze werden oft als „Black Boxes“ bezeichnet, weil sie nicht einfach erklären können, was sie tun. Sie sind auch notorisch schwer zu trainieren. Tatsächlich brauchte es jahrzehntelange Forschung, um Methoden zu entwickeln, um neuronale Netze effektiv zu trainieren. Heute können wir neuronale Netze mit handelsüblichen Softwaretools aufbauen und diese schnell in unseren Daten bereitstellen.
Wie funktionieren neuronale Netzwerke?
Neurale Netzwerke helfen über mehrere Ebenen hinweg für das jeweilige System neue Informationen aufgrund von Ähnlichkeiten zu klassifizieren und in Modellgruppen zusammenzufassen. Labels helfen dabei diese Gruppen zu benennen. Beispiele für Labels können sein: Spam, Kein Spam, Zufriedener Kunde, Unzufriedener Kunde, Gekaufter Link, Nicht gekaufter Link 😉 …
Die folgende Folie aus einem Vortrag von Googles Jeff Dean, veranschaulicht, dass bestimmte Muster z.B. eines Bilds eines Löwen immer wiederkehrend sind, Aufgrund dieser immer wieder kehrenden Muster kann man über Machine Learning automatisiert das Bild eines Löwen interpretieren und etikettieren.

Quelle: Präsentation Jeff Dean / Google
Neurale Netzwerke bestehen aus mehreren Ebenen bzw. Layern, die in Reihe geschaltet zur Verfeinerung bzw. Genauigkeit der Annahmen beitragen.
Unterscheidung zwischen Machine Learning und Künstlicher Intelligenz
Machine Learning und die verwandten Themen wie Artificial Intelligence bzw. zu deutsch Künstliche Intelligenz kurz KI gehören zu den wichtigsten Entwicklung- und Forschungsfeldern der Zukunft. Hier erhältst Du eine ausführliche Übersicht zum Thema Machine Learning. Machine Learning ist im Themenfeld Artficial Intelligence zu deutsch Künstliche Intelligenz zu verorten. Der Bereich Artificial Intelligence teilt sich in folgende Teilbereiche auf:
1. Reasoning
2. Knowledge representation
3. Automated planning and scheduling
4. Machine Learning
5. Natural language Processing
6. Computer vision
7. Robotics
8. General intelligence, or strong AI
Nach der gängigen Definition des amerikanischen Informatikers Tom Mitchell besteht der Grundgedanke von Machine Learning darin, dass ein Computer-Programm seine Performance durch neu gemachte Erfahrungen (Daten) in einem bestimmten Bereich automatisch verbessert. Der Vorteil dabei: Das Programm muss nicht mit tausenden Zeilen an Code permanent neu programmiert werden. Unterschiedlichste mathematische Algorithmen sorgen für eine automatische Verarbeitung der Daten und somit für den Lernprozess.
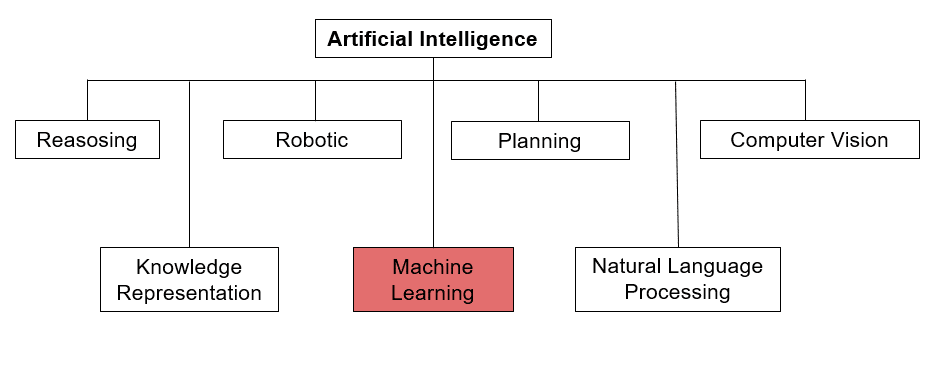
Machine Learning ist einer von vielen Bereichen der Künstlichen Intelligenz, ©Patrick Mebus
Der Begriff Intelligenz trifft in Bezug auf Machine-Learning nicht ganz zu, da es weniger um Intelligenz, viel mehr um durch Maschinen bzw. Computer erkennbare Muster und Genauigkeit geht. Machine Learning befasst sich mit der automatisierten Entwicklung von Algorithmen basierend auf empirischen Daten bzw. Trainings-Daten. Dabei liegt der Fokus auf der Optimierung der Ergebnisse bzw. Verbesserung der Vorhersagen aufgrund von Lernprozessen.
Künstliche Intelligenz hat zum Ziel Entscheidungen aufgrund erhobener Daten gemäß eines Menschen zu treffen. Dafür bedarf es mehr als nur Machine-Learning-Methodiken. Die Technologie hinter dem Machine-Learning sind sogenannte Neural Networks.
Einsatzgebiete für Machine Learning im Marketing
Maschinelles Lernen wird in vielen verschiedenen Bereichen wie Gesundheitswesen, Finanzen und Fertigung angewendet. Der Hauptvorteil des maschinellen Lernens besteht darin, dass Computer aus Daten lernen können, anstatt manuell programmiert werden zu müssen. Dies erleichtert die Erstellung von Algorithmen, die große Datenmengen analysieren und zukünftige Trends vorhersagen können. Diese Technologie wird bereits in einer Vielzahl von Branchen eingesetzt, darunter Einzelhandel, Finanzen, Gesundheitswesen und Fertigung. Tatsächlich ist maschinelles Lernen so effektiv, dass einige Unternehmen es mittlerweile als Ersatz für menschliche Mitarbeiter einsetzen.
Die wohl bekanntesten Beispiele für Machine Learning Implementierungen dürften die Empfehlungssysteme sein, die bei Amazon und Netflix zum Einsatz kommen. Online-Shopping und Video-Streaming, wie wir es heute kennen, wären ohne Algorithmen und ohne die Verarbeitung von Nutzerdaten nicht möglich.

Ohne Machine Learning wären Amazons Empfehlungen nicht so zielgenau und effektiv, ©Patrick Mebus
Auch selbstfahrende Autos oder Social Media Feeds würden ohne Künstliche Intelligenz nicht existieren. Im Falle von Pandemien wie Corona kann Machine Learning womöglich Menschenleben retten, da Wissenschaftlicher und Virologen mit Hilfe der Algorithmen Vorhersagen über die Ausbreitung machen können. Zudem lassen sich in der Medizin aufgrund bestimmter Muster für mögliche anstehende Ereignisse wie Herzinfarkte oder Schlaganfälle voraussagen.
Welche Machine-Learning-Arten gibt es?
Man unterscheidet grundsätzlich in drei verschiedene Arten des Machine Learnings:
- Überwachtes Lernen (Supervised Machine Learning): Überwachtes Lernen erfordert gekennzeichnete Trainingsdaten, wobei jedes Beispiel ein bekanntes Label hat. Beim überwachten maschinellen Lernen wird ein Algorithmus anhand einer Reihe von gekennzeichneten Beispielen trainiert, um ein Modell zu erstellen, das verwendet werden kann, um Vorhersagen für neue ungesehene Instanzen zu treffen. Supervised Machine Learning ist in eine Umgebung implementiert, deren Systemverhalten von einem menschlichen Bediener überwacht wird.
- Unüberwachtes Lernen (Unsupervised Machine Learning): Beim unüberwachten Lernen werden nicht gekennzeichnete Daten verwendet, was bedeutet, dass der Algorithmus aus Mustern in den Daten lernt, ohne zu wissen, was diese Muster bedeuten. Unüberwachtes maschinelles Lernen ist eine Art des maschinellen Lernens, bei der keine gekennzeichneten Trainingsbeispiele verfügbar sind. Sprich ein menschliches Eingreifen ist nicht erforderlich.
- Bestärkendes Lernen (Reinforcement Learning): Reinforcement Learning (RL) ist ein Gebiet der künstlichen Intelligenz bzw. Machine Learning, das sich damit beschäftigt, wie ein System lernen kann, in einer dynamischen Umgebung optimal zu agieren. Reinforcement Learning ermöglicht es Systemen zu lernen, ohne explizit programmiert zu werden. Reinforcement Learning bringt einem System bei, durch Versuch und Irrtum optimal zu handeln.
Dazu ein Auszug aus der deutschen Wikpiedia:
- Überwachtes Lernen (engl. supervised learning)Der Algorithmus lernt eine Funktion aus gegebenen Paaren von Ein- und Ausgaben. Dabei stellt während des Lernens ein „Lehrer“ den korrekten Funktionswert zu einer Eingabe bereit. Ziel beim überwachten Lernen ist, dass dem Netz nach mehreren Rechengängen mit unterschiedlichen Ein- und Ausgaben die Fähigkeit antrainiert wird, Assoziationen herzustellen. Ein Teilgebiet des überwachten Lernens ist die automatische Klassifizierung. Ein Anwendungsbeispiel wäre die Handschrifterkennung.
- Unüberwachtes Lernen (engl. unsupervised learning)Der Algorithmus erzeugt für eine gegebene Menge von Eingaben ein Modell, das die Eingaben beschreibt und Vorhersagen ermöglicht. Dabei gibt es Clustering-Verfahren, die die Daten in mehrere Kategorien einteilen, die sich durch charakteristische Muster voneinander unterscheiden. Das Netz erstellt somit selbständig Klassifikatoren, nach denen es die Eingabemuster einteilt. Ein wichtiger Algorithmus in diesem Zusammenhang ist der EM-Algorithmus, der iterativ die Parameter eines Modells so festlegt, dass es die gesehenen Daten optimal erklärt. Er legt dabei das Vorhandensein nicht beobachtbarer Kategorien zugrunde und schätzt abwechselnd die Zugehörigkeit der Daten zu einer der Kategorien und die Parameter, die die Kategorien ausmachen. Eine Anwendung des EM-Algorithmus findet sich beispielsweise in den Hidden Markov Models (HMMs). Andere Methoden des unüberwachten Lernens, z. B. Hauptkomponentenanalyse verzichten auf die Kategorisierung. Sie zielen darauf ab, die beobachteten Daten in eine einfachere Repräsentation zu übersetzen, die sie trotz drastisch reduzierter Information möglichst genau wiedergibt.
- Bestärkendes Lernen (engl. reinforcement learning)Der Algorithmus lernt durch Belohnung und Bestrafung eine Taktik, wie in potenziell auftretenden Situationen zu handeln ist, um den Nutzen des Agenten (d. h. des Systems, zu dem die Lernkomponente gehört) zu maximieren. Dies ist die häufigste Lernform eines Menschen.
Dazu habe ich auch in dieser Präsentation von Rahul Jain einige gute Grafiken gefunden. (Verlinkung zur Präsentation am Ende des Artikels).
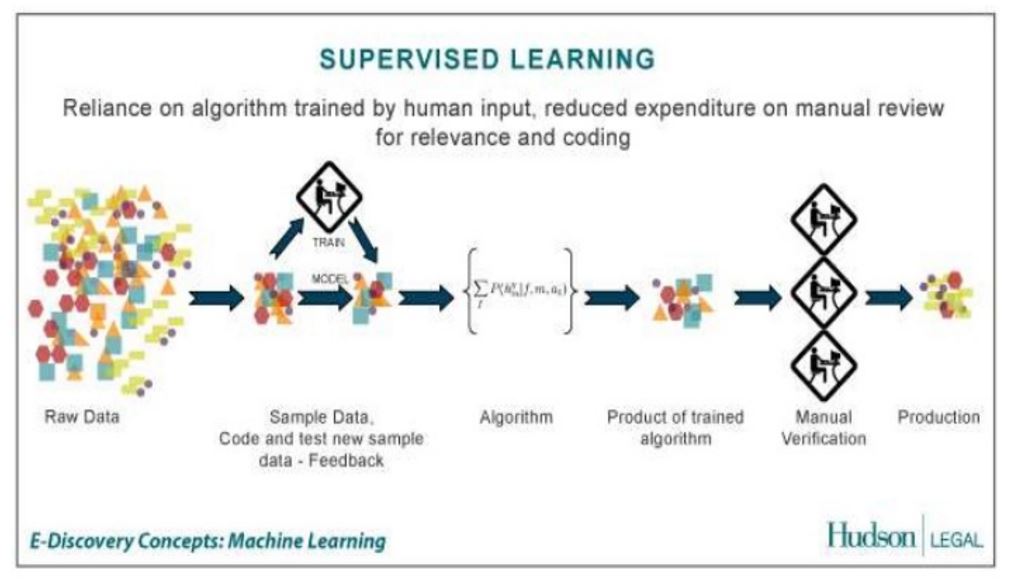
Machine-Learning-Prozess: Überwachtes Lernen
Das Überwachte Lernen bedarf Einiges an Vorarbeit, denn es müssen Beispielmodelle im Vorfeld festgelegt und belabelt werden, um eingehende Informationen zu identifizieren und dieser Modellgruppe zuordnen zu können bzw. zu klassifizieren. Diese Belabelung wird aufgrund der Qualitätssicherung in der Regel durch menschliche Hand durchgeführt. Aufgrund bestimmter immer wieder auftretender Muster kann das System dann, zukünftig Informationen mit gleichen oder ähnlichen Muster-Eigenschaften selbstständig erkennen und der jeweiligen Modellgruppe zuordnen.
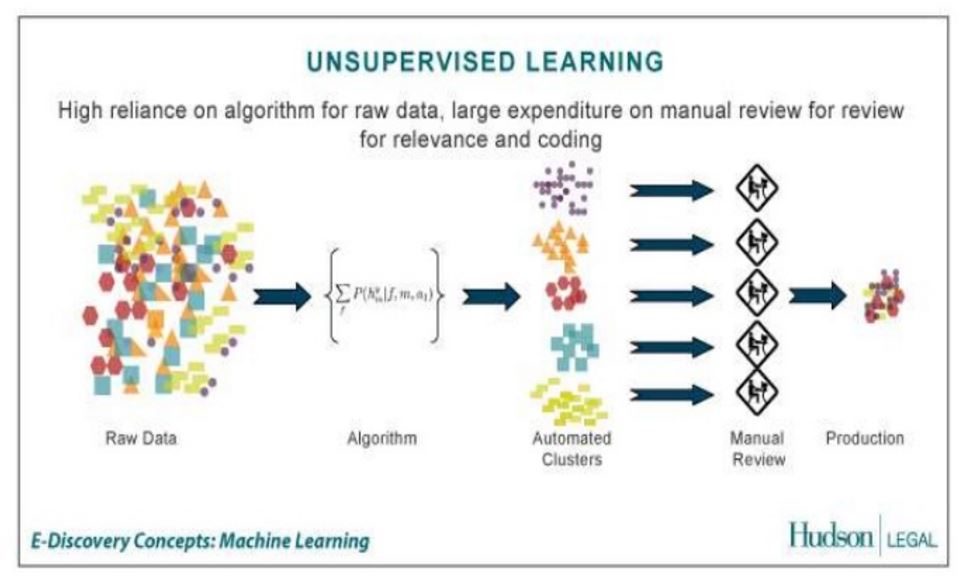
Machine-Learning-Prozess: Unüberwachtes Lernen
Beim Unüberwachten Lernen findet die Vorab-Belabelung nicht statt und die Modellgruppen werden automatisiert aufgrund von Mustern gebildet.
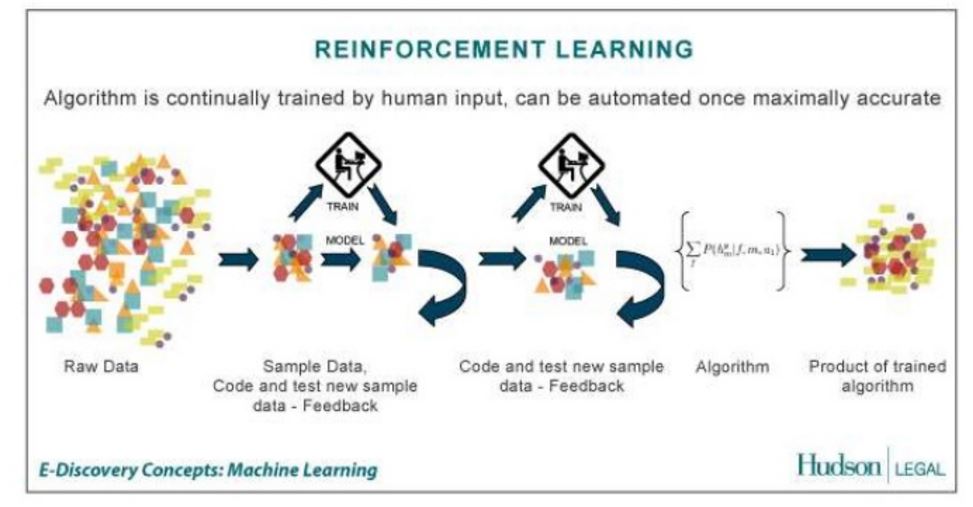
Machine-Learning-Prozess: Bestärkendes Lernen
Ähnlich wie mit dem Begriff Artificial Intelligence wird der Begriff Machine Learning mit Deep Learning und Semantik oft gleichgesetzt bzw. im selben Atemzug genannt. Nachfolgend ein Versuch der Differenzierung.
Welche Machine Learning Algorithmen gibt es?
Algorithmen des maschinellen Lernens werden für verschiedene Zwecke wie Bilderkennung, Spracherkennung, Spam-Filterung usw. verwendet. Der gebräuchlichste Algorithmus ist Naive Bayes, der Daten basierend auf der bedingten Wahrscheinlichkeit jeder Klasse anhand der Merkmale der Trainingsdaten in zwei Klassen einteilt. Ein weiterer beliebter Algorithmus ist Support Vector Machines, der die Hyperebene findet, die den Abstand zwischen zwei Klassen maximiert.
Das Problem bei der Verwendung von maschinellen Lernalgorithmen besteht darin, dass sie große Datenmengen benötigen, um sie zu trainieren. Wenn Sie nicht über genügend Daten verfügen, lässt sich Ihr Modell nicht gut verallgemeinern. Hier kommt das Konzept des Transferlernens ins Spiel. Transferlernen ermöglicht es uns, Wissen aus einer Domäne wiederzuverwenden, um Probleme in einer anderen Domäne zu lösen. In diesem Fall sprechen wir von der Übertragung von Wissen von einem Datentyp (z.B. Bilder) auf einen anderen Datentyp (z.B. Text).
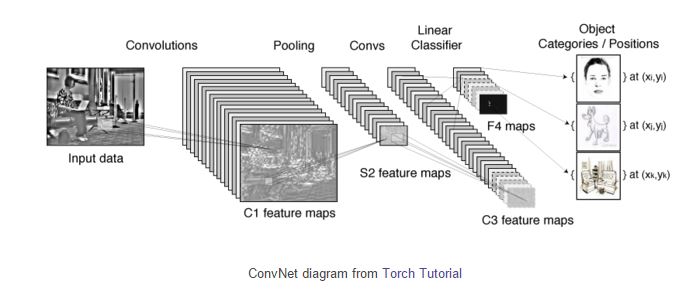
Unterschied zwischen Machine Learning und Deep Learning
Der Hauptunterschied zwischen Deep Learning und traditionellem maschinellem Lernen besteht darin, dass Deep Learning mehrere Verarbeitungsebenen verwendet, um den Daten Bedeutung zu entnehmen. Herkömmliche Algorithmen für maschinelles Lernen funktionieren, indem sie ein Problem in kleinere Teile zerlegen und dann eine Reihe von Regeln auf jedes Teil anwenden. Deep-Learning-Algorithmen unterteilen Probleme in mehrere Abstraktionsschichten, sodass sie komplexere Muster lernen können.
Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz (KI), das darauf abzielt, Computersysteme aufzubauen, die in der Lage sind, Aufgaben auszuführen, die normalerweise menschliche Intelligenz erfordern, wie Spracherkennung, Übersetzung, Beantwortung von Fragen usw. Deep Learning ist eine Teilmenge des maschinellen Lernens, die künstliche neuronale Netze, um Computer zu trainieren, aus Daten zu lernen. Deep Learning wurde für Bildklassifizierung, Objekterkennung, Verarbeitung natürlicher Sprache, Spracherkennung und Empfehlungssysteme verwendet.
Während klassische Machine-Learning Algorithmen auf feste Modellgruppen zur Erkennung und Klassifizierung zurückgreifen, entwickeln Deep-Learning Algorithmen eigenständig diese Modelle weiter bzw. erstellen eigenständig neue Modellebenen innerhalb der Neuralen Netzwerke. Dadurch müssen nicht immer wieder Modelle für neue Begebenheiten manuell entwickelt und eingeführt werden, wie es bei klassischen Machine-Learning-Algorithmen der Fall wäre. So sind auch Vorraussagen durch Deep-Learning-Algos besser zu treffen. Dazu diese Grafik (Die Orginaquelle ist leider nicht mehr online. Deswegen der Verweis auf diesen Beitrag.)
Warum Machine Learning immer wichtiger wird?
Die aktuelle und vor allem zukünftige Bedeutung von Machine Learning ist im digitalen Kontext ähnlich einzuordnen wie die Themen Mobile, Big Data oder Content-Marketing. Wie ich in meinem Beitrag Das semantische Web (Web 3.0) als logische Konsequenz aus dem Web 2.0 bereits erläutert habe sind Systeme, die Informationen identifizierbar, kategorisierbar, bewertbar und je nach Kontext sortierbar machen die einzige Möglichkeit der Informations- und Datenflut begründend auf den Innovationen des Web 2.0 herr zu werden. Doch hier reicht reine Semantik nicht aus. Deswegen benötigen die digitalen Gatekeeper immer zuverlässigere Algorithmen um diese Aufgabe zu bewerkstelligen. Hier werden zukünftig selbstlernende Algorithmen basierend auf Artificial Intelligence und Methoden des Machine-Learnings eine immer wichtigere Rolle spielen. Nur so kann die Relevanz von Ergebnissen bzw. erwartungskonforme Ausgaben / Ergebnisse gewährleistet werden.
Auch die Schlagzahl der medialen Präsenz der Themen nimmt seit 2014 deutlich zu, wie man bei Google-Trends nachverfolgen kann.
Was ist der Unterschied zwischen maschinell Gelerntem und Heuristiken?
Maschinelles Lernen ist eine Form der künstlichen Intelligenz, bei der Algorithmen aus Daten lernen und sie verwenden, um zukünftige Ergebnisse vorherzusagen. Heuristiken sind Faustregeln, die uns helfen, Entscheidungen basierend auf unserer Erfahrung und unserem Wissen zu treffen.
Wo ist der Unterschied zwischen Machine Learning und Statistik?
Machine Learning ist eine Teilmenge der künstlichen Intelligenz, die statistische Methoden verwendet, um aus Daten zu lernen und Vorhersagen über zukünftige Ereignisse zu treffen. Statistik ist das Studium der Wahrscheinlichkeitstheorie und mathematischer Modelle, die zur Analyse von Daten verwendet werden. Maschinelles Lernen wird für prädiktive Analysen verwendet, während Statistiken für deskriptive Analysen verwendet werden.r
Abgrenzung zwischen Machine Learning und Semantik
Die Semantik kann dabei helfen die Bedeutung eines Objekts über die Klassifizierung als eindeutige Entität und über die Beziehungen mit anderen Entitäten besser zu indentifizieren. Bei der Klassifizierung greift die Semnatik auf Eigenschaften ähnlich der Muster bei der Zuordnung zu Modellgruppen im Machine Learning zurück. Der entscheidende Unterschied ist aber, dass die Semantik keinen keinen Lernprozess verfolgt, wie es beim Machine Learning der Fall ist. Dadurch sind semantische Systeme eher statisch und nur schlecht in der Lage Vorraussagen für neu eintretende Situation durchzuführen. Modellgruppen und Muster bzw. Enitäten müssen bekannt sein.
Welche Programmiersprachen nutzt man für Machine Learning?
Folgende Programmiersprachen können für die Erstellung von Machine-Learning-Systemen genutzt werden:
- Python
- R
- C++
Python ist eine Allzwecksprache und leicht zu erlernen, während R ein Statistikpaket ist, das für die Datenanalyse verwendet wird. C++ ist eine Hochleistungssprache für die Entwicklung von Anwendungen. Python greift auf eine breite Palette von Bibliotheken und Paketen für die Arbeit mit Daten zu.
Häufig gestellte Fragen zum Thema Machine Learning
Was ist Machine Learning?
Machine Learning zu deutsch maschinelles Lernen ist ein Teilgebiet von Artificial Intelligence (zu deutsch Künstliche Intelligenz) und beschreibt dymanische Algorithmen, die in der Lage sind eigenständig dazuzulernen, um Ergebnisse bzw. die Performance zu verbessern.
Welche Bereiche zählen zu Artificial Intelligence?
Der Bereich Artificial Intelligence teilt sich in folgende Teilbereiche auf:
- Reasoning
- Knowledge representation
- Automated planning and scheduling
- Machine Learning
- Natural language Processing
- Computer vision 7. Robotics
- General intelligence, or strong AI
Warum ist Machine Learning nicht gleich Künstliche Intelligenz?
Der Begriff Intelligenz trifft in Bezug auf Machine-Learning nicht ganz zu, da es weniger um Intelligenz, viel mehr um durch Maschinen bzw. Computer erkennbare Muster und Genauigkeit geht. Machine Learning befasst sich mit der automatisierten Entwicklung von Algorithmen basierend auf empirischen Daten bzw. Trainings-Daten. Dabei liegt der Fokus auf der Optimierung der Ergebnisse bzw. Verbesserung der Vorhersagen aufgrund von Lernprozessen. Künstliche Intelligenz hat zum Ziel Entscheidungen aufgrund erhobener Daten gemäß eines Menschen zu treffen. Dafür bedarf es mehr als nur Machine-Learning-Methodiken. Die Technologie hinter dem Machine-Learning sind sogenannte Neural Networks.
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023
Blog-Artikel zu diesem Thema
Die Google Suche: So funktioniert das Ranking der Suchmaschine heute
 Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf di... Artikel anzeigen
Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf di... Artikel anzeigen
Sind LLMO, GAIO oder GEO die Zukunft von SEO?
 Seit der Vorstellung von generativer KI in Form von ChatGPT, BARD oder SGE erobern Large Language Models (LLMs) die Welt und finden den Weg auch in die Suchmaschinen. SEOs diskutieren weltweit über die Möglichkeit, KI-Ausgaben via Large Language Model Optimization (LLMO), Generative Engine Optimiz... Artikel anzeigen
Seit der Vorstellung von generativer KI in Form von ChatGPT, BARD oder SGE erobern Large Language Models (LLMs) die Welt und finden den Weg auch in die Suchmaschinen. SEOs diskutieren weltweit über die Möglichkeit, KI-Ausgaben via Large Language Model Optimization (LLMO), Generative Engine Optimiz... Artikel anzeigen
Googles Weg zur semantischen Suchmaschine
 In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T
 In Zeiten von massenhaft erstellten KI-Inhalten und Large Language Models (LLMs) als Basis für die Ausgabe von Antworten werden Inhalte immer ähnlicher und austauschbarer werden. Zudem steigt die Gefahr der Verbreitung von Falschinformationen exponentiell an.
Deswegen wird es für Suchmaschinen... Artikel anzeigen
In Zeiten von massenhaft erstellten KI-Inhalten und Large Language Models (LLMs) als Basis für die Ausgabe von Antworten werden Inhalte immer ähnlicher und austauschbarer werden. Zudem steigt die Gefahr der Verbreitung von Falschinformationen exponentiell an.
Deswegen wird es für Suchmaschinen... Artikel anzeigen
20+ Faktoren für eine E-E-A-T-Bewertung durch Google
 E-E-A-T hat sich durch die Core-Updates seit 2018 zu einem der wichtigsten Rankingeinflüsse für Google-Suchergebnisse entwickelt und wird durch die Einführung von SGE zusätzlich an Wichtigkeit gewinnen. In diesem Beitrag möchte ich auf 20+ Faktoren eingehen, die Google algorithmisch für eine E... Artikel anzeigen
E-E-A-T hat sich durch die Core-Updates seit 2018 zu einem der wichtigsten Rankingeinflüsse für Google-Suchergebnisse entwickelt und wird durch die Einführung von SGE zusätzlich an Wichtigkeit gewinnen. In diesem Beitrag möchte ich auf 20+ Faktoren eingehen, die Google algorithmisch für eine E... Artikel anzeigen
Sind Nutzersignale wie CTR, Absprungrate oder Verweildauer ein Rankingfaktor?
 Der große Einfluss der Nutzersignale auf das Ranking ist in der SEO-Branche unumstritten und für die meisten SEO-Experten sind die Nutzersignale der heilige Gral. Doch sind Nutzersignale wirklich ein Rankingfaktor? Dieser Beitrag beschäftigt sich kritisch mit dieser Theorie und soll darüber ... Artikel anzeigen
Der große Einfluss der Nutzersignale auf das Ranking ist in der SEO-Branche unumstritten und für die meisten SEO-Experten sind die Nutzersignale der heilige Gral. Doch sind Nutzersignale wirklich ein Rankingfaktor? Dieser Beitrag beschäftigt sich kritisch mit dieser Theorie und soll darüber ... Artikel anzeigen
Wie versteht Google Suchanfragen durch Search Query Processing?
 Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing... Artikel anzeigen
Wie schlau ist Google? Echtes semantisches Verständnis oder nur Statistik?
 Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Goo... Artikel anzeigen
Die semantische Bedeutung von Keywords bei modernen Suchmaschinen
 In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent m... Artikel anzeigen
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
 In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
Video: Entitäten basierte Suche – Alles zum Knowledge Graph, NLP, Ranking, E A T und Semantik in der SEO
 Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Im April 2020 habe ich für den OMT ein knapp zweistündiges Webinar zum Thema Semantische Suche bzw. Entitäten basierte Suche gehalten. Ich beschreibe ausführlich den Zusammenhang zwischen Knowledge-Graph, Data-Mining via Natural-Language-Processing und wie das Ganze mit E-A-T und digitalen Marke... Artikel anzeigen
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
 Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Youtube: Interpretation und Ranking von Videos via Entitäten
 Dieser Beitrag beschäftigt sich mit einem Google Patent aus Dezember 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Entitäten in einem Video z.B. bei Youtube erkennen kann. Aufgrund von Features, die man bereits in der Google-Suche und bei Youtube vorfindet ist es sehr wahrscheinli... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google Patent aus Dezember 2021, in dem Methoden beschrieben werden wie eine Suchmaschine Entitäten in einem Video z.B. bei Youtube erkennen kann. Aufgrund von Features, die man bereits in der Google-Suche und bei Youtube vorfindet ist es sehr wahrscheinli... Artikel anzeigen
Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index
 Dies ist eine Übersetzung des Original-Beitrags Google Describes a Machine Learning Model For a Searchable Index von Bill Slawski.
Information Retrieval Ranking vs. Machine Learning Ranking
In der Vergangenheit wurden die Suchergebnisse als Reaktion auf die von den Suchenden in ein Suchfeld eing... Artikel anzeigen
Dies ist eine Übersetzung des Original-Beitrags Google Describes a Machine Learning Model For a Searchable Index von Bill Slawski.
Information Retrieval Ranking vs. Machine Learning Ranking
In der Vergangenheit wurden die Suchergebnisse als Reaktion auf die von den Suchenden in ein Suchfeld eing... Artikel anzeigen
Personalisierte Knowledge Graphen: Dahin kann die Reise gehen!
 Die ist ein Gastbeitrag von Bill Slawski.
Ich habe einige Beiträge über Patente bei Google zu personalisierten Knowledge Graphen geschrieben (ein Thema, über das es sich lohnt, ernsthaft nachzudenken).
Als Google 2012 den Knowledge Graph einführte, erzählte man uns nur von einem einzigen ... Artikel anzeigen
Die ist ein Gastbeitrag von Bill Slawski.
Ich habe einige Beiträge über Patente bei Google zu personalisierten Knowledge Graphen geschrieben (ein Thema, über das es sich lohnt, ernsthaft nachzudenken).
Als Google 2012 den Knowledge Graph einführte, erzählte man uns nur von einem einzigen ... Artikel anzeigen
Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann
 Dies ist ein Beitrag von Bill Slawski übersetzt aus dem englischen Original-Beitrag Adjusting Featured Snippet Answers by Context
Wie wird über Featured-Snippet-Antworten entschieden?
Ich habe vor kurzem über die Bewertungssignale für Featured Snippet Answer Scores geschrieben. In diesem Beitr... Artikel anzeigen
Dies ist ein Beitrag von Bill Slawski übersetzt aus dem englischen Original-Beitrag Adjusting Featured Snippet Answers by Context
Wie wird über Featured-Snippet-Antworten entschieden?
Ich habe vor kurzem über die Bewertungssignale für Featured Snippet Answer Scores geschrieben. In diesem Beitr... Artikel anzeigen
Eindeutige Suchanfragen helfen Google, die Suchintention besser zu verstehen
 Zum Anfang des Beitrags, wollte ich einige Whitepaper einbeziehen, an denen Autoren aus dem Hause Google beteiligt sind. Die Autoren des ersten Papiers sind die Erfinder einer Patentanmeldung, die am 28. April 2020 veröffentlicht wurde. Diese Whitepaper sind lesenswert, um einen Eindruck davon zu b... Artikel anzeigen
Zum Anfang des Beitrags, wollte ich einige Whitepaper einbeziehen, an denen Autoren aus dem Hause Google beteiligt sind. Die Autoren des ersten Papiers sind die Erfinder einer Patentanmeldung, die am 28. April 2020 veröffentlicht wurde. Diese Whitepaper sind lesenswert, um einen Eindruck davon zu b... Artikel anzeigen
Owned Machine Learning: Wieso unternehmenseigene Algorithmen in SEA & Online-Werbung überlebenswichtig sind
 Dies ist ein Gastartikel von Patrick Mebus.
Arbeiten im Online-Marketing ohne Tools wie Automated Bidding, Affinity-Targeting oder Responsive Search Ads. Nur schwer vorstellbar oder? Sie alle sind fester Bestandteil unseres Büro-Alltages. Und Sie alle basieren auf Maschinellem Lernen. Das Proble... Artikel anzeigen
Dies ist ein Gastartikel von Patrick Mebus.
Arbeiten im Online-Marketing ohne Tools wie Automated Bidding, Affinity-Targeting oder Responsive Search Ads. Nur schwer vorstellbar oder? Sie alle sind fester Bestandteil unseres Büro-Alltages. Und Sie alle basieren auf Maschinellem Lernen. Das Proble... Artikel anzeigen
Warum strukturierte Daten für Google zukünftig überflüssig werden könnten
 Googles Engagement in Sachen Machine-Learning könnte in der Zukunft dazu führen , dass die Auszeichnung von Informationen mittels strukturierter Daten überflüssig werden könnte. Die Hinweise von Google weisen darauf hin.
Google lernt auch dank der Mithilfe von Webmastern und SEOs
Der Aufbau e... Artikel anzeigen
Googles Engagement in Sachen Machine-Learning könnte in der Zukunft dazu führen , dass die Auszeichnung von Informationen mittels strukturierter Daten überflüssig werden könnte. Die Hinweise von Google weisen darauf hin.
Google lernt auch dank der Mithilfe von Webmastern und SEOs
Der Aufbau e... Artikel anzeigen
Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google
 Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlich... Artikel anzeigen
Kann Google Texte in Bildern lesen bzw. erkennen?
 Googles Engagement in Sachen in Machine Learning und Articial Intelligence ist beachtlich wie im Beitrag Welche Bedeutung hat ML für Google? erläutert. Auch der Einfluss auf SEO ist deutlich erkennbar wie im Beitrag Welche Bedeutung hat Machine Learning für SEO? Experten wagen den Blick in die ... Artikel anzeigen
Googles Engagement in Sachen in Machine Learning und Articial Intelligence ist beachtlich wie im Beitrag Welche Bedeutung hat ML für Google? erläutert. Auch der Einfluss auf SEO ist deutlich erkennbar wie im Beitrag Welche Bedeutung hat Machine Learning für SEO? Experten wagen den Blick in die ... Artikel anzeigen
























