
Machine Learning und Artificial Intelligence (AI) nehmen einen immer größeren Raum bei der Modellierung und Klassifizierung nach Mustern auch im Online Marketing ein. Unternehmen wie z.B. Tesla, Google, Microsoft, Amazon und Facebook betreiben großen Forschungsaufwand im Bereich der künstlichen Intelligenz.
Spätestens nach der Bekanntgabe von Google im November 2015, dass ein neues sehr wichtiges Ranking-Signal bzw. wichtiger Ranking-Faktor namens Rankbrain bereits seit Monaten im Einsatz ist, ist das Interesse an dem Thema Machine-Learning in der SEO- und Online-Marketing-Gemeinde endgültig angekommen. Ich halte das Thema Machine Learning gerade im digitalen Kontext für ähnlich einschneidend und zukunftsweisend wie z.B. die Themen Mobile, Big Data und Content-Marketing. Wie Machine-Learning im Zusammenhang mit anderen aktuellen Buzzwords wie Artificial Intelligence (Künstliche Intelligenz), Semantik oder Deep Learning steht und welche Auswirkungen diese Entwicklung hin zu selbstlernenden Algorithmen auf Suchmaschinen hat möchte ich nachfolgend erläutern. Dabei möchte ich darauf hinweisen, dass ich das Thema Künstliche Intelligenz bzw. Machine Learning nur oberflächlich betrachten konnte. Wer tiefer in die Materie einsteigen möchte findet am Ende des Beitrags eine ausführliche Quellen-Sammlung an Videos und Links zu dem Thema.
In diesem Beitrag versuche ich die Welt des Machine Learnings und deren Einfluss auf SEO zusammen mit der Unterstützung einiger geschätzter Kollegen namens Markus Hövener, Sepita Ansari, Christian Kunz, Marcus Tober, Kai Spriestersbach, Sebastian Erlhofer und Marcel Schrepel greifbarer zu machen.
Inhaltsverzeichnis
- 1 Was ist Machine Learning? Bedeutung, Definition & Methodik
- 2 Was sind Neurale Netzwerke?
- 3 Machine-Learning-Arten
- 4 Unterschied zwischen Machine Learning und Deep Learning
- 5 Abgrenzung zwischen Machine Learning und Semantik
- 6 Machine Learning und (Suchmaschinen-) Algorithmen
- 7 Googles Engagement in Sachen künstlicher Intelligenz & Machine Learning
- 8 Quellen zum Thema Machine Learning und Künstliche Intelligenz
- 9 Welche Rolle spielt Rankbrain?
- 10 Rankbrain für das Query Refinement
- 11 Rankbrain als Mittler zwischen Suchanfrage und Hummingbird
- 12 Welche Auswirkung kann Machine-Learning zukünftig auf das Ranking haben?
- 13 Welche Auswirkung haben selbst lernende Algorithmen auf SEO?
- 14 Expertenstimmen zum Einfluss von Machine Learning auf SEO
- 15 Weitere Beiträge zum Thema Machine Learning und SEO
- 16 Videos zum Thema Machine Learning und Artificial Intelligence
Was ist Machine Learning? Bedeutung, Definition & Methodik
Die aktuelle und vor allem zukünftige Bedeutung von Machine Learning ist im digitalen Kontext ähnlich einzuordnen wie die Themen Mobile, Big Data oder Content–Marketing. Auch die Schlagzahl der medialen Präsenz der Themen nimmt seit 2014 deutlich zu, wie man bei Google-Trends nachverfolgen kann.
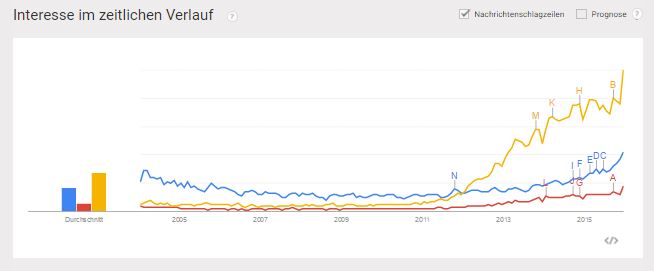
Google Trends: Weltweite Entwicklung des Suchvolumens für Big Data (gelb), Machine Learning (blau) und Content-Marketing (rot)
Wie ich in meinem Beitrag Das semantische Web (Web 3.0) als logische Konsequenz aus dem Web 2.0 bereits erläutert habe sind Systeme, die Informationen identifizierbar, kategorisierbar, bewertbar und je nach Kontext sortierbar machen die einzige Möglichkeit der Informations- und Datenflut begründend auf den Innovationen des Web 2.0 herr zu werden. Doch hier reicht reine Semantik nicht aus. Deswegen benötigen die digitalen Gatekeeper immer zuverlässigere Algorithmen um diese Aufgabe zu bewerkstelligen. Hier werden zukünftig selbstlernende Algorithmen basierend auf Artificial Intelligence und Methoden des Machine-Learnings eine immer wichtigere Rolle spielen. Nur so kann die Relevanz von Ergebnissen bzw. erwartungskonforme Ausgaben / Ergebnisse gewährleistet werden.
Doch was ist Machine-Learning nun genau und wie funktioniert es?
Machine Learning ist im Themenfeld Artficial Intelligence zu deutsch Künstliche Intelligenz zu verorten. Der Bereich Artificial Intelligence teilt sich in folgende Teilbereiche auf:
1. Reasoning
2. Knowledge representation
3. Automated planning and scheduling
4. Machine Learning
5. Natural language processing
6. Computer vision
7. Robotics
8. General intelligence, or strong AI
Der Begriff Intelligenz trifft in Bezug auf Machine-Learning nicht ganz zu, da es weniger um Intelligenz, viel mehr um durch Maschinen bzw. Computer erkennbare Muster und Genauigkeit geht. Machine Learning befasst sich mit der automatisierten Entwicklung von Algorithmen basierend auf empirischen Daten bzw. Trainings-Daten. Dabei liegt der Fokus auf der Optimierung der Ergebnisse bzw. Verbesserung der Vorhersagen aufgrund von Lernprozessen.
Künstliche Intelligenz hat zum Ziel Entscheidungen aufgrund erhobener Daten gemäß eines Menschen zu treffen. Dafür bedarf es mehr als nur Machine-Learning-Methodiken. Die Technologie hinter dem Machine-Learning sind sogenannte Neural Networks.
Was sind Neurale Netzwerke?
Neural Network zu deutsch Neurale Netzwerke sind Gruppen von Algorithmen, die gemäß eines menschlichen Gehirns aufgebaut sind, um wiederkehrende Muster zu erkennen und diese daraufhin zu ordnen bzw. zu etikettieren. Die erkannten Muster werden in mathematisch Vektoren übersetzt. Dabei werden alle Informationen der realen Welt wie Bilder, Sound, Text oder Zeitfolgen berücksichtigt.
Neurale Netzwerke helfen über mehrere Ebenen hinweg für das jeweilige System neue Informationen aufgrund von Ähnlichkeiten zu klassifizieren und in Modellgruppen zusammenzufassen. Labels helfen dabei diese Gruppen zu benennen. Beispiele für Labels können sein: Spam, Kein Spam, Zufriedener Kunde, Unzufriedener Kunde, Gekaufter Link, Nicht gekaufter Link 😉 …
Die folgende Folie aus einem Vortrag von Googles Jeff Dean, veranschaulicht, dass bestimmte Muster z.B. eines Bilds eines Löwen immer wiederkehrend sind, Aufgrund dieser immer wieder kehrenden Muster kann man über Machine Learning automatisiert das Bild eines Löwen interpretieren und etikettieren.

Quelle: Präsentation Jeff Dean / Google
Neurale Netzwerke bestehen aus mehreren Ebenen bzw. Layern, die in Reihe geschaltet zur Verfeinerung bzw. Genauigkeit der Annahmen beitragen. Wer sich noch tiefer mit dem Thema beschäftigen findet hier eine schöne Einführung.
Machine-Learning-Arten
Man unterscheidet grundsätzlich in drei verschiedene Arten des Machine Learnings:
- Überwachtes Lernen
- Unüberwachtes Lernen
- Bestärkendes Lernen
Dazu ein Auszug aus der deutschen Wikpiedia:
- Überwachtes Lernen (engl. supervised learning)Der Algorithmus lernt eine Funktion aus gegebenen Paaren von Ein- und Ausgaben. Dabei stellt während des Lernens ein „Lehrer“ den korrekten Funktionswert zu einer Eingabe bereit. Ziel beim überwachten Lernen ist, dass dem Netz nach mehreren Rechengängen mit unterschiedlichen Ein- und Ausgaben die Fähigkeit antrainiert wird, Assoziationen herzustellen. Ein Teilgebiet des überwachten Lernens ist die automatische Klassifizierung. Ein Anwendungsbeispiel wäre die Handschrifterkennung.
- Unüberwachtes Lernen (engl. unsupervised learning)Der Algorithmus erzeugt für eine gegebene Menge von Eingaben ein Modell, das die Eingaben beschreibt und Vorhersagen ermöglicht. Dabei gibt es Clustering-Verfahren, die die Daten in mehrere Kategorien einteilen, die sich durch charakteristische Muster voneinander unterscheiden. Das Netz erstellt somit selbständig Klassifikatoren, nach denen es die Eingabemuster einteilt. Ein wichtiger Algorithmus in diesem Zusammenhang ist der EM-Algorithmus, der iterativ die Parameter eines Modells so festlegt, dass es die gesehenen Daten optimal erklärt. Er legt dabei das Vorhandensein nicht beobachtbarer Kategorien zugrunde und schätzt abwechselnd die Zugehörigkeit der Daten zu einer der Kategorien und die Parameter, die die Kategorien ausmachen. Eine Anwendung des EM-Algorithmus findet sich beispielsweise in den Hidden Markov Models (HMMs). Andere Methoden des unüberwachten Lernens, z. B. Hauptkomponentenanalyse verzichten auf die Kategorisierung. Sie zielen darauf ab, die beobachteten Daten in eine einfachere Repräsentation zu übersetzen, die sie trotz drastisch reduzierter Information möglichst genau wiedergibt.
- Bestärkendes Lernen (engl. reinforcement learning)Der Algorithmus lernt durch Belohnung und Bestrafung eine Taktik, wie in potenziell auftretenden Situationen zu handeln ist, um den Nutzen des Agenten (d. h. des Systems, zu dem die Lernkomponente gehört) zu maximieren. Dies ist die häufigste Lernform eines Menschen.
Dazu habe ich auch in dieser Präsentation von Rahul Jain einige gute Grafiken gefunden. (Verlinkung zur Präsentation am Ende des Artikels).
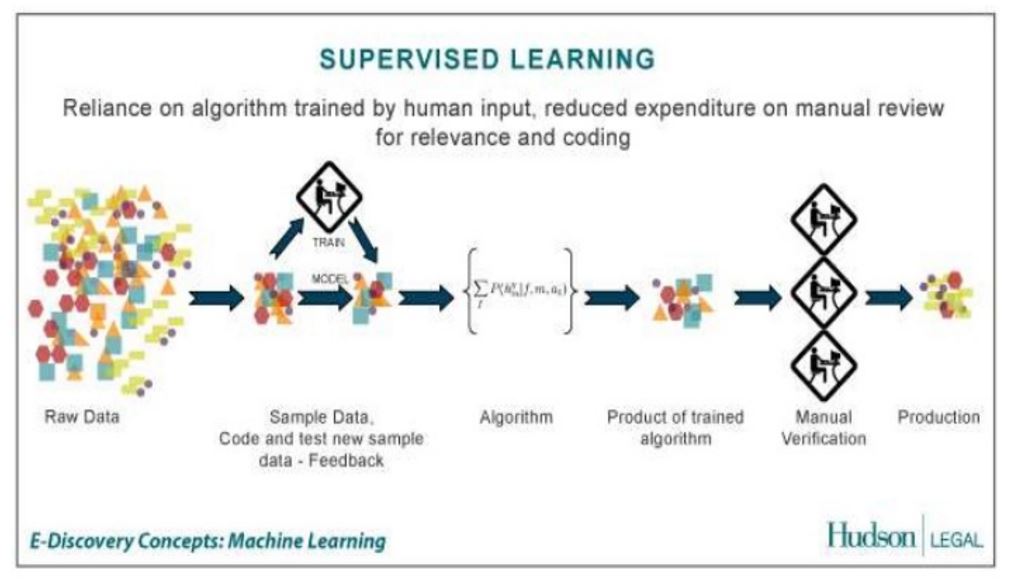
Machine-Learning-Prozess: Überwachtes Lernen
Das Überwachte Lernen bedarf Einiges an Vorarbeit, denn es müssen Beispielmodelle im Vorfeld festgelegt und belabelt werden, um eingehende Informationen zu identifizieren und dieser Modellgruppe zuordnen zu können bzw. zu klassifizieren. Diese Belabelung wird aufgrund der Qualitätssicherung in der Regel durch menschliche Hand durchgeführt. Aufgrund bestimmter immer wieder auftretender Muster kann das System dann, zukünftig Informationen mit gleichen oder ähnlichen Muster-Eigenschaften selbstständig erkennen und der jeweiligen Modellgruppe zuordnen.
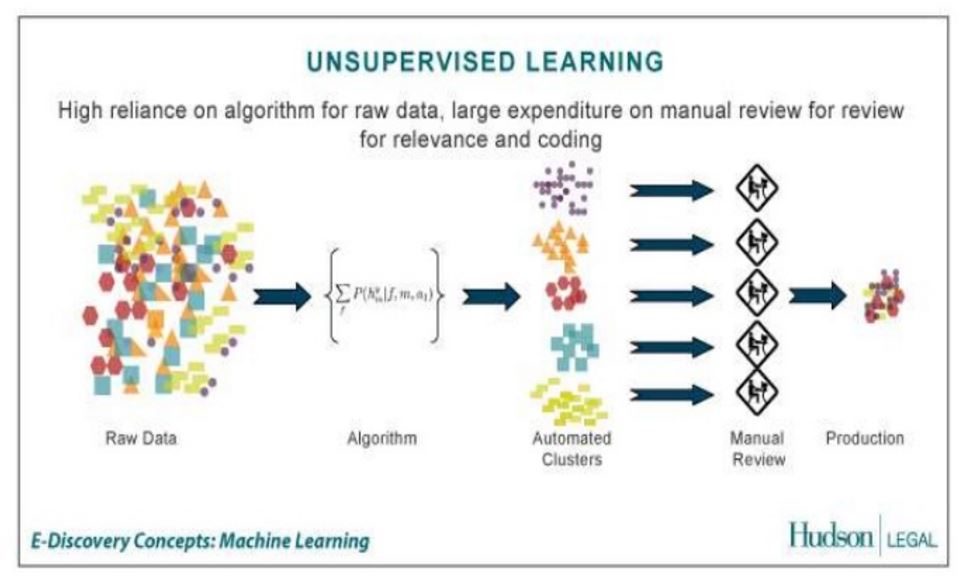
Machine-Learning-Prozess: Unüberwachtes Lernen
Beim Unüberwachten Lernen findet die Vorab-Belabelung nicht statt und die Modellgruppen werden automatisiert aufgrund von Mustern gebildet.
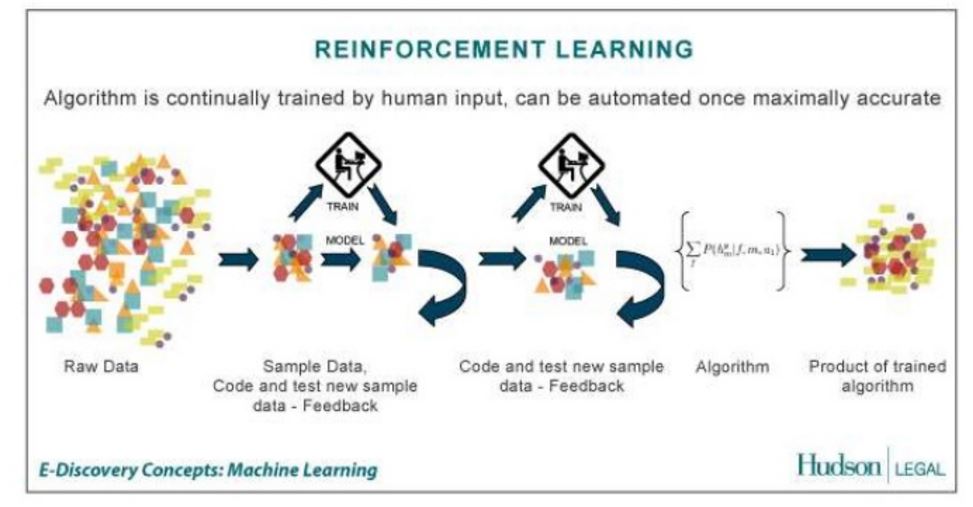
Machine-Learning-Prozess: Bestärkendes Lernen
Ähnlich wie mit dem Begriff Artificial Intelligence wird der Begriff Machine Learning mit Deep Learning und Semantik oft gleichgesetzt bzw. im selben Atemzug genannt. Nachfolgend ein Versuch der Differenzierung.
Unterschied zwischen Machine Learning und Deep Learning
Deep Learning ist ein Teilbereich des Machine Learnings, könnte auch als Weiterentwicklung bezeichnet werden. Während klassische Machine-Learning Algorithmen auf feste Modellgruppen zur Erkennung und Klassifizierung zurückgreifen, entwickeln Deep-Learning Algorithmen eigenständig diese Modelle weiter bzw. erstellen eigenständig neue Modellebenen innerhalb der Neuralen Netzwerke. Dadurch müssen nicht immer wieder Modelle für neue Begebenheiten manuell entwickelt und eingeführt werden, wie es bei klassischen Machine-Learning-Algorithmen der Fall wäre. So sind auch Vorraussagen durch Deep-Learning-Algos besser zu treffen. Dazu diese Grafik (Die Orginaquelle ist leider nicht mehr online. Deswegen der Verweis auf diesen Beitrag.)
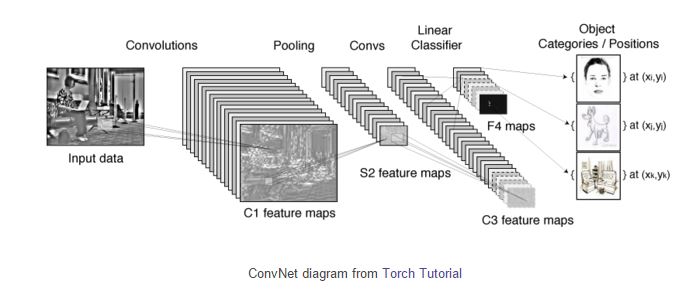
Hier ein veranschaulichendes kurzes Video dazu
Abgrenzung zwischen Machine Learning und Semantik
Die Semantik kann dabei helfen die Bedeutung eines Objekts über die Klassifizierung als eindeutige Entität und über die Beziehungen mit anderen Entitäten besser zu indentifizieren. Bei der Klassifizierung greift die Semantik auf Eigenschaften ähnlich der Muster bei der Zuordnung zu Modellgruppen im Machine Learning zurück. Der entscheidende Unterschied ist aber, dass die Semantik keinen keinen Lernprozess verfolgt, wie es beim Machine Learning der Fall ist. Dadurch sind semantische Systeme eher statisch und nur schlecht in der Lage Vorraussagen für neu eintretende Situation durchzuführen. Modellgruppen und Muster bzw. Enitäten müssen bekannt sein.
Machine Learning und (Suchmaschinen-) Algorithmen
Das spannende an dieser Entwicklung hin zum Machine-Learning ist, dass Algorithmen sich zukünftig selbst weiter entwickeln und anpassen können. Bisher wurden z.B. bei Google der Suchalgorithmus wie folgt weiter entwickelt.
Eine durchschnittliche Veränderung an den Algorithmen beginnt mit einer Idee zur Verbesserung der Suche von einem der Google-Entwickler. Sie folgen einem datenbasierten Ansatz und alle vorgeschlagenen Algorithmusänderungen werden vor der Veröffentlichung im Rahmen einer umfangreichen Qualitätsbewertung getestet.
In der Regel führen Entwickler zu Beginn eine Reihe von Experimenten durch, optimieren die eine oder andere Variable und bitten Kollegen um Feedback. Wenn sie mit dem Ergebnis zufrieden sind, wird das Experiment für ein größeres Publikum freigegeben.
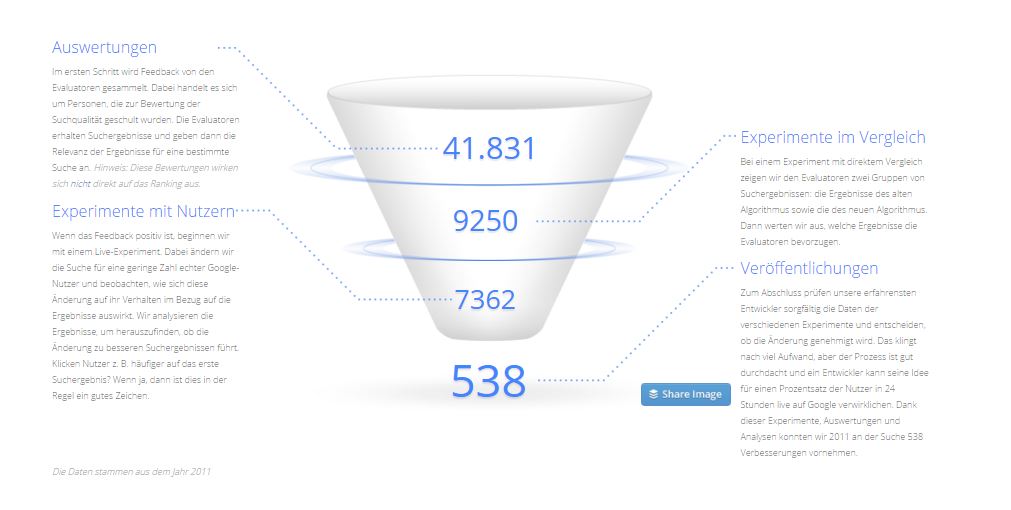
Algorithmus-Weiterentwicklung bei Google Quelle: Google
Die Folge ist ein statischer allgemeiner Algorithmus, der durch viele kleinere und größere Updates weiter entwickelt wird. Dieser Algorithmus ist für jede Situation gleich. Tauchen völlig neue vorher nie da gewesene Situationen auf ist der Algo erst einmal überfordert. Auch die Berücksichtigung jedes inviduellen Kontexts, wie z.B. Standort, genutztes Endgerät … in dem sich ein Nutzer befindet muss dieser eine Algorithmus bedienen. Im Optimalfall hätte jeder Nutzer oder zumindest Nutzergruppe einen eigenen individuellen Algorithmus „verdient“, um gemäß des jeweiligen Kontexts bedient zu werden. Das ist mit dem bisherigen relativ statischem Algorithmus nicht möglich.
Es ist nicht möglich für jede Aufgaben einen eigenen Algorithmus zu schreiben. Es müssen Algorithmen geschrieben werden, die aufgrund von Beobachtungen lernen. Machine-Learning würde dies möglich machen und Google geht bereits in diese Richtung.
Zudem hat Google Signale von Nutzerseite, die als Erfolgsmetriken im Lernprozess genutzt werden können:
- Long to Short Click Ratio
- Anteil der Suchenden die verwandte und zusätzliche Suchanfragen durchführen
- Kennzahlen für Nutzer-Engagement (ermittelbar z.B. über Chrome)
- Relative Kickrate in den SERPs
- Geteilte Inhalte
- Nutzer Engagement auf den Websites
Im Zusammenspiel mit den klassischen Offpage-Ranking-Signalen wie Backlinks, Co-Citations und Co-Occurences können diese als Erfolgsmetriken zur Verifizierung einer Einschätzung durch den Algorithmus genutzt werden.
Eine interessante Frage ist Woher bezieht Google die Nutzerbezogenen Trainings-Daten zum Einleiten des Machine-Learning-Prozess?
Sind es echte Nutzerdaten oder bedient sich Google hier zukünftig weiter der Daten, die durch die Such-Evaluatoren vzw. Quality-Rater in einer Testumgebung generiert werden?
(Diskussionen u.a. hierzu gerne in den Kommentaren.)
Das obige Modell zur Algorithmus-Weiterentwicklung nach und nach obsolet zu werden. Ein Beleg dafür sind auch die immer häufiger werdenden Real-Time-Updates wie z.B. das Real-Time-Pinguin Updates oder die „nebenher laufenden“ Panda Updates. Früher wurden kommende Updates groß angekündigt und von den Kollegen wie z.B. sistrix dokumentiert. Ich denke solche Dokumentationen werden bald ihre Sinnhaftigkeit verloren haben. Und auch Studien und Übersichten von Rankingfaktoren wie wir sie bisher kennen werden in ein paar Jahren Geschichte sein. Aber dazu weiter unten mehr.
Google bezieht schon eine Menge von Informationen aus verschiedenen Ebenen beim Indexieren und Ranking ein, die irgendwie im Algorithmus berücksichtigt werden müssen
- Text
- Visuelles (Bilder, Videos)
- Audio
- Nutzerverhalten
- Knowledge Graph (Abbild von Beziehungen)
Dabei kann Google inzwischen auch schon Nummern und Text aus Bildern auslesen, wie mein Kollege Philipp in seinem Beitrag in der nächsten Woche eindrucksvoll beschreiben wird.
Mehr dazu im Beitrag Bilderkennung: Kann Google Texte in Bildern lesen und erkennen?
Wenn man sich noch einmal, die verschiedenen Machine-Learning-Arten ansieht und in die Suchmaschinen-Welt überträgt macht es Sinn zu überlegen, wo bereits zumindest Machine-Learning-Ansätze bei Google genutzt werden. Bezogen auf die Suche kann man zumindest Ansätze des ML hier erkennen:
- Knowledge Graph
- Hummingbird
- Rankbrain
- eventuell Real-Time-Pinguin
Zudem sind schone einige Google Produkte im Einsatz, die sich Deep-Learning-Funktionalitäten bedienen wie z.B. Text in Bild Erkennung, Spracherkennung, Google Translate …
Die große Frage ist: Wie kann man Systeme schaffen, die mit all diesen ganzen Informationen zurecht kommen?
Und wieder lautet die Antwort: Machine-Learning kann sie sein.
Das größte Problem beim Handling bei solch einer Masse an Daten ist das Thema Performance und Skalierbarkeit. Dennoch möchte Google hier mit aller Kraft einen Weg in Richtung Machine-Learning gehen will und laut Eric Schmidt ist Machine Learning das bestimmende Thema der Zukunft für Google, wie er vor Studenten der TU Berlin kürzlich darstellte:
Das überragende Thema der kommenden Jahre ist laut Schmidt Machine Learning. Also die Entwicklung von Maschinen und Computern, die selbstständig lernen können. Schmidt: „Wir werden dem Computer in Zukunft keine Fragen mehr stellen müssen, weil er gelernt hat, was wir fragen werden. Es beginnt gerade etwas ganz Großes.“ Schmidt vertraut den Maschinen. Computer seien in vielen Dingen einfach besser und schneller als Menschen.
Googles Engagement in Sachen künstlicher Intelligenz & Machine Learning
Dass Google irgendwann ein künstliches Gehirn erschaffen möchte und dass dafür Hummingbird und der Knowldege Graph nur der Anfang sind hat meine Kollegin Svenja vor zwei Jahren mit dem Beitrag Knowledge Graph: Google baut ein Gehirn hier im Blog erläutert. Doch bis dato konnte man es nur erahnen. Durch die weiteren Aktivitäten in den letzten Jahren wird das Bild nun immer klarer.
Laut eigenen Angaben hat Google seit 2014 seine Aktivitäten in Sachen Deep Learning knapp vervierfacht, wie man aus der Folie des weiter unten aufgeführten Vortrag von Jeff Dean entnehmen kann.
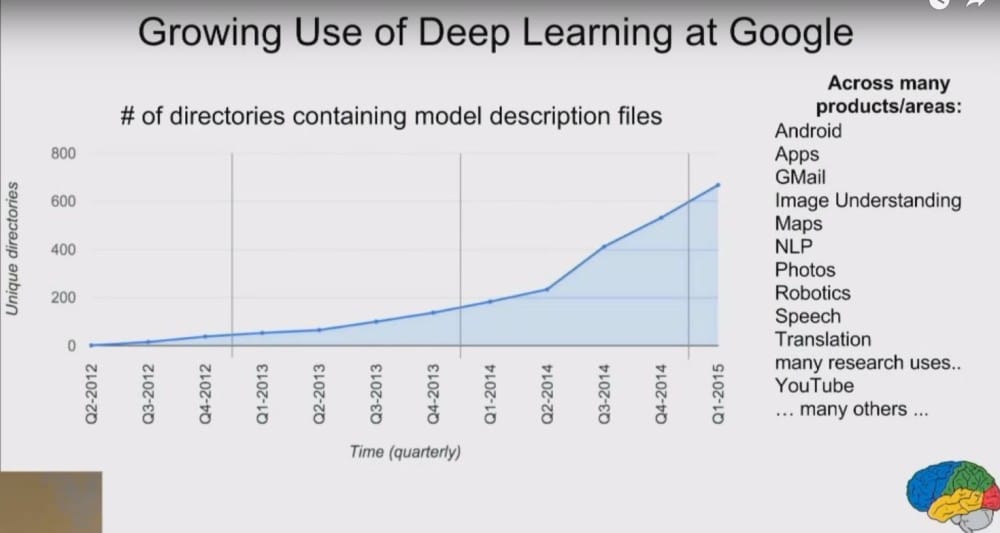
Quelle: Präsentation Jeff Dean / Google
Googles Engagement in Sachen Artificial Intelligence und Machine-Learning begann im Jahr 2011 mit dem Projektstart von „Google Brain“. Ziel von Google Brain ist es eigene Neural Networks zu schaffen. Seitdem entwickelt Google mit einer selbst entwickelten Deep-Learning-Software DistBelief die eigenen Produkte in Sachen Machine-Learning weiter. Die zweite Software-Generation namens Tensor Flow steht aber schon in den Startlöchern.
Betrachtet man die Investitionen und Engagements in Sachen Artificial Intelligence im Zeitverlauf wird schnell klar wie wichtig Google diese Themen sind:
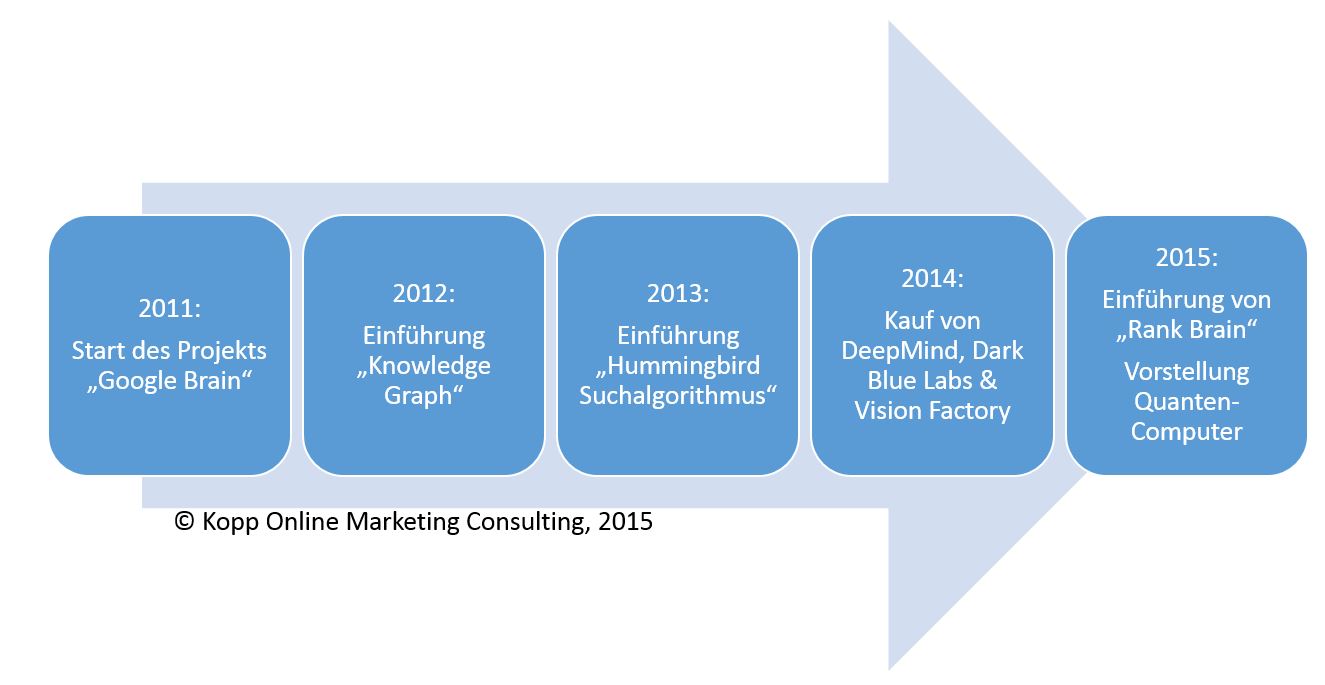
Googles Engagement in Sachen Machine Learning und Artificial Intelligence
Während der Knowledge-Graph und Hummingbird bereits Machine-Learning-Ansätze beinhalten, lag hier noch eher die semantische Suchmaschine im Fokus. Spätestens mit den mehrere hundert Millionen schweren Investitionen in diverse Unternehmen aus den Bereichen Artificial Intelligence und Machine-Learning im Jahr 2014 wird klar wohin Google aber wirklich will.
Mit Deep Mind (ca. 365 Mio. Dollar) kaufte Google ein bereits 2011 gegründetes Unternehmen, das sich im Schwerpunkt mit Systemen rund um Künstlicher Intelligenz beschäftigt. U.a. ist DeepMind für die Entwicklung von Google Now verantwortlich. DeepMinds ausgegebenes Unternehmensziel ist das Verstehen von Intelligenz. Zudem beschäftigt sich DeepMind nicht nur mit der Entwicklung von neuronalen Netzen sondern arbeitet an deutlich flexibleren Modellen ähnlich einem Kurzzeitgedächtnis.
Dark Blue Labs hingegen beschäftigt sich im Schwerpunkt mit der Erkennung und Deutung natürlicher Sprache also auch Audio-Formaten.
Vision-Factory hat sich auf Erkennung und Deutung von visuellen Medien wie Bildern oder Videos spezialisiert.
Im Umgang Mit Texten hat Google hingegen als textbasierte Suchmaschine schon länger Erfahrungen. Im Bereich Audio, Video und Bild hat man sich mit den genannten Unternehmen professionelle Unterstützung mit ins Boot geholt.
Zudem investiert Google laut eigener Aussage seit Jahren sehr viel in das Thema Künstliche Intelligenz. So hat Google hat bis heute Dekaden an Mannstunden investiert in die Entwicklung einer State-of-the-Art Infrastruktur z.B. eigene neuronale Netze investiert. Desweiteren beschäftigt Google tausende CPUs und GPUs um aus dem Billionen von Datensätzen parallel weiter zu lernen.
Im Dezember 2015 gab Google bekannt zusammen mit der NASA an einem Quanten-Computer zu arbeiten.
Google veröffentlicht oft als erste Instanz wissenschaftliche Aufgabenstellungen zu Themen wie Bilderkennung, Spracherkennung. So wurden in den letzten zwei Jahren über 460 Publikationen zum Thema Artificial Intelligence veröffentlicht. Siehe dazu http://research.google.com/pubs/ArtificialIntelligenceandMachineLearning.html.
Und es bleibt nicht nur bei der Theorie. So hat Google laut eigener Aussage ihre Erfahrungen in Sachen Deep Learning seit 2012 in mehr als 47 Produkte implementiert. Hier ein Auszug:
- Objekt-Erkennung in Bildern
- Objekt- Katgeorie Erkennung in Videos
- Spracherkennung
- Passanten-Erkennung für selbstfahrende Autos
- OCR: Texterkennung in Bildern
- Erkennung von Umgangssprache
- Maschinen-Übersetzung
- Online-Werbung
The Expander team’s machine learning system is now being used on massive graphs (containing billions of nodes and trillions of edges) to recognize and understand concepts in natural language, images, videos, and queries, powering Google products for applications like reminders, question answering, language translation, visual object recognition, dialogue understanding, and more.
Google selbst bestätigt, dass Semi-Supervised-Machine-Learning (Erklärung weiter oben im Beitrag) zum Einsatz kommt.
At its core, Expander’s platform combines semi-supervised machine learning with large-scale graph-based learning by building a multi-graph representation of the data with nodes corresponding to objects or concepts and edges connecting concepts that share similarities. The graph typically contains both labeled data (nodes associated with a known output category or label) and unlabeled data (nodes for which no labels were provided).
Wer die manuelle Belabelung bzw. Vorkennzeichnung bei Google übernimmt ist unklar. Es könnte sein, dass dies je nach Aufgabenstellung durch Quality-Rater und günstige Clickworker durchgeführt wird.
Wer mehr über Googles Aktivitäten in Sachen Artificial Intelligence herausfinden möchte, den empfehle ich einen der zahlreichen Vorträge von Jeff Dean
Spätestens mit der Einführung von der Algorithmus-Erweiterung von Hummingbird namens Rankbrain sollte jedem SEO klar sein, dass das Thema Machine Learning ein immer wichtigere Einflussfaktor für das Ranking sein wird.
Bevor ich dann auf die Auswirkungen dieser Aktivitäten auf die Suchmaschinenoptimierung eingehe für die Vertiefung einige weiterführende Lesetipps.
Quellen zum Thema Machine Learning und Künstliche Intelligenz
Deep Learning vs Machine Learning vs Pattern Recognition
Machine learning explained in simple words
Wikipedia: Maschinelles Lernen
Introduction to Machine Learning
Rise of the Machines from JAX TV on Vimeo.
Welche Rolle spielt Rankbrain?
Laut Google wurde Rankbrain am Anfang in erster Linie auf 15-20% der vorher niemals gestellten Suchanfragen angewendet. Seit ca. Juni 2016 wird Rankbrain auf alle Suchanfragen angewendet.
Rankbrain wird von Google selbst als drittwichtigster Rankingfaktor benannt. Ber Begriff Rankingfaktor sorgt erst einmal für Verwirrung. Rankingfaktor ja, Rankingsignal nein. Und hier beginnt bereits für viele SEOs die Unklarheit, die teilweise von widersprüchlichen Aussagen von Google nicht beseitigt wird.
Es gibt zwei Fragen, die SEOs in Bezug auf Rankbrain immer wieder beschäftigen
- Ist Rankbrain für das Query Refinement bzw. Suchbegriff-Klassifizierung sowie -Interpretation zuständig oder das Scoring von URLs?
- Nutzt Rankbrain reale Nutzerdaten, Trainingsdaten von Suchevaluatoren bzw. Quality-Ratern oder keins von beiden als Trainingsdaten?
Hier gibt es folgende Theorien:
- Rankbrain ist kein Rankingsignal sondern nur für das Query Refinement zuständig
- Rankbrain ist Rankingsignal und damit im Scoring von Dokumenten involviert
- Neben Rankbrain sind noch weitere Machine Learning Systeme im Hummingbird im Einsatz
1. Rankbrain ist kein Rankingsignal sondern nur für das Query Refinement zuständig
Bei Rankbrain handelt es sich nicht um einen klassischen Rankingfaktor wie z.B. Seitentitel oder Backlinks. Rankbrain ist vielmehr eine Update des Hummingbird-Algorithmus in Form einer Erweiterung. Aufgrund der Ermittlung thematischer Nähe zu bereits bekannten Begriffen kann Rankbrain bisher unbekannte Suchanfragen in thematische Kontexte einordnen bzw. insbesondere längere komplexere Suchanfragen auf gemeinsame Nenner herunterbrechen. Dadurch kann besser die Bedeutung interpretiert und damit die unbekannte Suchanfrage bereits bekannten Synonymen bzw. Begriffen ähnlicher oder gleicher Bedeutung zugeordnet werden. Gerade bei der Interpretation von Suchanfragen kann Rankbrain so Google einen großen Schritt weiter bringen.
So wurde Rankbrain bei der ersten Bekanntmachung von Google vorgestellt und Paul Haahr von Google bestätigte diese Theorie auf der SMX Advanced 2016 in diesem Interview mit Danny Sullivan (ab Minute 3:00). Man beachte, dass auch Gary Illyes in einer Nebenrolle dabei ist, der gleich noch an anderer Stelle Erwähnung findet.
2. Rankbrain ist Rankingsignal und damit im Scoring von Dokumenten involviert
Rankbrain ist direkt bei der Bewertung von Seiteninhalten beteiligt. Hier könnten bestimmte Muster, die passenden Inhalten zu einer bestimmten Suchanfrage immer wieder vorkommen identifiziert und zum Scoring herangezogen werden. Dazu gibt es aber nur wenige Aussagen seitens Google. Etwas verblüffend ist, dass der bereits erwähnte Gary Illyes nun in der Hauptrolle in einer Q&A mit Danny Sullivan ebenfalls auf der SMX Advanced 2016 folgendes in Bezug zu Rankbrain von sich gab (ab 5:40 Minuten):
„It’s less for understanding the query, more for scoring the results…“
Danny Sullivan schien bis dato auch eher von der ersten Theorie ausgegangen zu sein, die ihm auf dem selben Event von Illyes Kollegen Haahr bestätigt wurde.
Sehr verwirrend was aus dem Hause Google hier kommuniziert wird.
3. Neben Rankbrain sind noch weitere Machine Learning Systeme im Hummingbird im Einsatz
Eine weitere Vermutung ist, dass neben Rankbrain auch in anderen Teilen des Hummingbird Machine Learning auch z.B. für das Website Scoring eingesetzt wird. Dazu auch Mario Fischer in einer Diskussion auf Facebook:
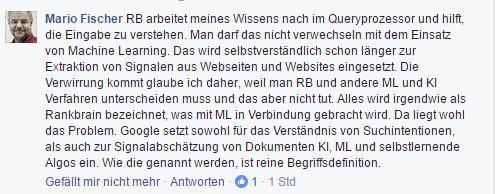
Mario Fischer zur Verwirrung um Rankbrain in einer Facebook-Diskussion am 22.11.2016
Ich habe John Mueller von Google im Webmaster Hangout vom 01.12.2016 um eine Antwort gebeten. Hier seine Meinung zur Rolle von Rankbrain:
Damit bestätigt John die erste der drei Theorien, dass Rankbrain nur für die Interpretation der Suchanfragen im Einsatz ist. Das eigentliche Scoring von Websites, was für die Sortierung der Suchergebnisse sorgt findet im Hummingbird-Algorithmus statt. Ob hier Nutzersignale als Trainingsdaten für die Interpretation von Suchanfragen z.B. zur Ermittlung zum Einsatz kommen ist unklar.
Rankbrain für das Query Refinement
Ich glaube an die erste Aussage von Google, dass Rankbrain als Mittel zum Query Refinement, also auf der Seite der Suchanfrage eingesetzt wird. Zumal Paul Haahr mir in den beiden Videos den deutlich kompetenteren Eindruck machte und Gary Illyes nicht zum ersten Mal etwas unsouverän in Kommunikation aufgetreten ist. Das würde aber bedeuten, dass Rankbrain entgegen der Folumierung von Gary Illyes kein direkter Rakingfaktor ist.
Ich denke auch, dass neben Rankbrain weitere Machine-Learning-Systeme z.B. für das Scoring von Websites eingesetzt werden. Wenn nicht schon jetzt, dann in Zukunft. Davon, dass Google auch Machine Learning zur Ermittlung der Suchintention auch unter Einbeziehung von realen Nutzerdaten einsetzt bin ich auch überzeugt. Aber fast alles ist bis dato Spekulation bzw. Annahme.
Rankbrain als Mittler zwischen Suchanfrage und Hummingbird
Schauen wir uns mal an wie Googles-Suchmaschine aktuell wahrscheinlich funktioniert.
Googles Funktionsweise teilt sich grob in folgende Bereiche auf:
- Crawling und Indexierung
- Suchanfragen verstehen und erweitern (u.a.Rankbrain)
- Retrieval und Scoring (Hummingbird / Knowledge Graph)
- Nach-Retrieval-Anpassungen (u.a. Panda, Penguin)
Für das Scoring also die Bewertung einzelner Dokumente unabhängig von der Suchanfrage ist nebenbei gesagt nicht Rankbrain zuständig, sondern der Hummingbird-Algorithmus. Rankbrain interpretiert erst einmal nur die Suchanfragen.
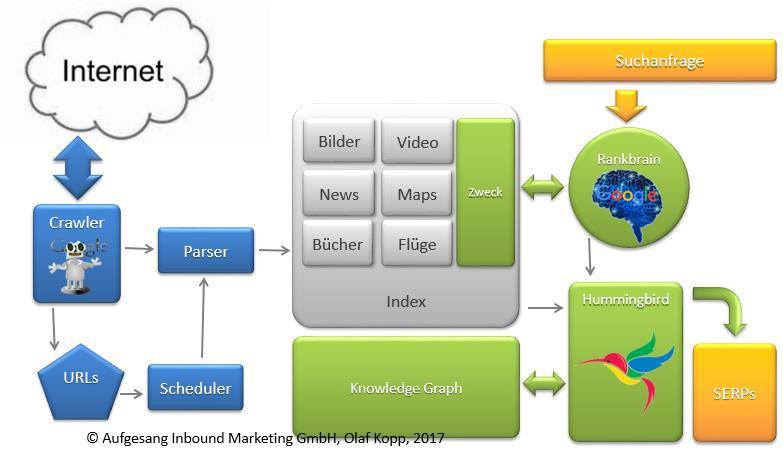
So könnte Google aktuell funktionieren
Wenn man Gary Illyes schon fast etwas genervt wirkenden Post bei Twitter und seine Antwort auf Rand Fishkins Nachfragen interpretiert könnte Rankbrain dafür genutzt werden Rankingfaktoren je nach Suchintention unterschiedlich zu gewichten. Hätte also so Einfluss auf das Ranking von Dokumenten.
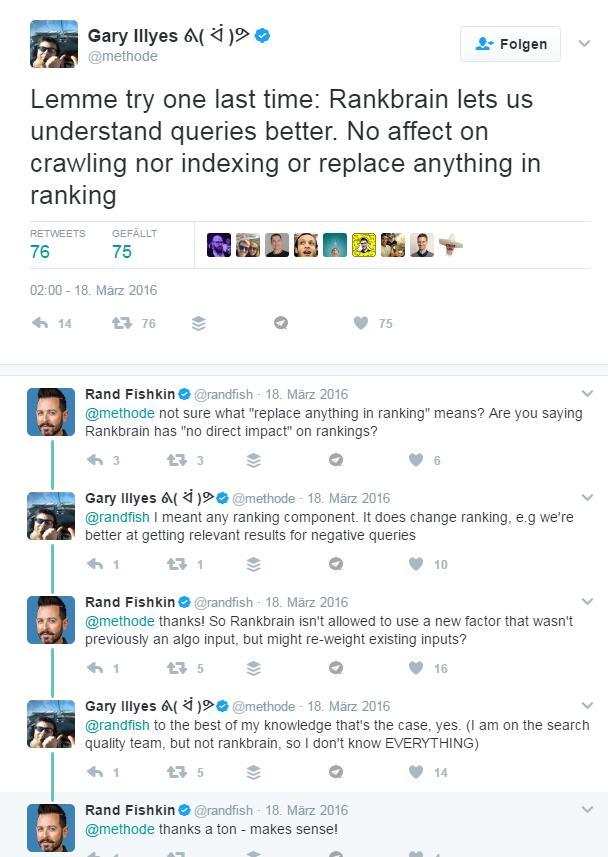
Jetzt behaupten einige SEOs, dass zumindest bei der Ermittlung der Suchintention durch Rankbrain Google auf reale Nutzersignale zurückgreift. Ich bin zuerst auch davon ausgegangen, aber laut Aussage von Gary Illyes scheint es nicht so. Zumindest keine Nutzersignale in der freien Online-Wildbahn.
It’s an offline learning algorithm. It’s refreshed every now and then with new training data.
Wenn man zwischen den Zeilen liest gibt es zwei Möglichkeiten:
- Google könnte Nutzersignale ihrer Such-Evaluatoren nutzen um auch die Suchintention zu ermitteln bzw. Keyword-Modellgruppen bezogen auf die Suchintention zu bilden.
- Google könnte Nutzersignale erfassen und als Trainingsdaten in das Offline Machine-Learning-System von Rankbrain einfließen lassen.
Aber alles pure Spekulation.
Kommen wir zum eigentlichen Scoring der Dokumente über Hummingbird. Ich versuche, das mal mit Hilfe von Paul Haahrs Vortrag von der SMX West 2016 zu erklären, ohne es genau zu wissen.
Google klassifiziert laut Paul Haahr (Video weiter unten) Dokumente und Websites in sogenannte Shards innerhalb des Index. Laut Haahr gibt es tausende von verschiedenen Shards. Ich könnte mir vorstellen diese Shards sind nach Zweck des Dokuments und/oder Themenbereich im Index klassifiziert. Das für das Ranking relevante Gesamt-Scoring findet dann aus dem allgemeinen Scoring des Dokuments im Abgleich mit der über Rankbrain identifizierten Suchintention der Suchanfrage statt.

Paul Haahr zum Thema Scoring
Zu weiteren Theorien, zu was Rankbrain noch genutzt werden könnte empfehle ich die Präsentation von Kai Spriestersbach von der SEOkomm 2016. Die Einschätzung zum Einfluss der Engagement-Daten wie Absprungrate und CTR auf Rankbrain teile ich allerdings nicht voll und ganz.
Wir sollten bei Kais Präsentation vielleicht eher von Machine Learning bei Google und nicht explizit von Rankbrain sprechen.
Wer sich mit dem Thema beschäftigt sollte sich auch diese Keynote von Marcus Tandler ansehen:
Marcus Tandler Vortrag, Rise of the Machines
Welche Auswirkung kann Machine-Learning zukünftig auf das Ranking haben?
Ich denke, dass Machine Learning Funktionalitäten nicht erst bei Rankbrain, sondern bereits bei Hummingbird und der stetigen Weiterentwicklung bzw. Vergrößerung und Strukturierung des Knowledge Graph im Einsatz sind. Dass Machine Learning zur Spam-Bekämpfung z.B. im Rahmen des Pinguin-Algos zum Einsatz kommt wurde inzwischen durch eine Aussage von Google bzw. Gary Illyes wiedersprochen. Ich hoffe hier bleibt es auch bei dieser eindeutigen Aussage.
Ob Google jetzt schon Machine Learning für die Bewertung von Websites nutzt kann aufgrund der widersprüchlichen Aussagen aus dem Hause Google nicht beantwortet werden. Sinn würde es für die Zukunft machen.
Ich denke, dass Machine Learning bereits schon seit längerem zur Kategorisierung von Suchanfragen, Inhalten aber auch Entitäten ( Mehr zum Thema Semantik und Entitäten) eingesetzt wird. Es muss ja nicht zwangsläufigüber Rankbrain sein. Die ein oder andere Prise Machine Learning könnte auch schon in den Hummingbird-Algo direkt eingeflossen sein.
Gerade in Kombination mit dem Knowledge Graph als semantische Datenbank hätte Google zwei mächtige Werkzeug an der Hand.
Hilfreich könnte hierfür auch ein Google-Patent zur Nutzung von Knowledge Base Kategorien sein, über das man im Beitrag How Google Might Make Better Synonym Substitutions Using Knowledge Base Categories mehr erfahren kann.
Dafür, dass Google Suchanfragen bereits zu verschiedenen Kategorien zuordnet gibt es klare Anzeichen wie z.B. die Beobachtungen von Ross Hudgens zeigen.

Entitäten-Katgeorien in Google Suggest: Quelle siehe obigen Link zu The SEM Post
Google versucht hier zwecks Eindeutigkeit Begriffe insbesondere Entitäten mit mehreren Bedeutungen je nach Kontext über Kategorisierung voneinander abzugrenzen. Auch in Google Trends kategorisiert Google Begriffe bereits nach Kategorien:
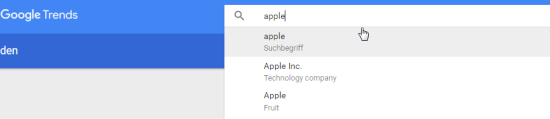

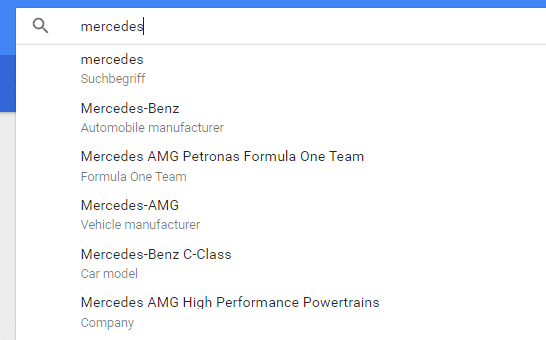
Hier scheint Google sowohl allgemeine Kategorisierungen wie z.B. nach Thema, Company, Brand oder Suchbegriff als auch fachspezifische Kategorien wie z.B. Vehicle-Manufacturer, Fruit, Technology Company, Formula One Team, Design Company Chancellor of Germany … zu nutzen.
Bisher wird Machine- bzw. Deep-Learning mit hoher Wahrscheinlichkeit bzw. laut Googles eigener Aussage bereits für folgende Fälle eingesetzt:
- Kategoriesierung bzw. Identifizierung von Suchanfragen nach Suchintention (Infomational, Transactional, Navigational …)
- Kategorisierung von Inhalten/Dokumenten nach Zweck (Information, Verkauf, Navigation …)
- Erkennung, Kategorisierung von Entitäten im Knowledge Graph
- Erkennung, Kategorisierung und Interpretation von Bildern
- Erkennung, Kategorisierung und Interpretation von Sprache
- Erkennung, Kategorisierung und Interpretation von Video
Das wirklich Neue ist dabei, dass Google diese Kategorisierung nun immer besser, da stetig dazu lernend und vor allem automatisiert durchführen kann.

Zur Kategorisierung von Text-Inhalten via Machine Learning habe ich hier schöne wissenschaftliche Arbeit mit dem Titel Automatic text categorization by unsupervised learning gefunden, aus der auch die obige Grafik stammt.
Die Kombination aus Nutzerdaten insbesondere Interaktionsdaten bezogen auf Dokumente, Inhalte, aber auch ganze Domains in Kombination mit dem Abgleich bestimmter Dokumenten-, Domain- bzw. Enitätsmuster ist eine gute gute Grundlage für Google die eigenen Machine-Learning-Prozesse z.B. nach dem Muster des bestärkenden Lernens einzusetzen.
Machine-Learning-Pozess: Bestärkendes Lernen / Quelle: http://www.slideshare.net/rahuldausa/introduction-to-machine-learning-38791937
Ob nun die Nutzerdaten oder das Feedback der Such-Evaluatoren bzw. Quality-Rater oder sogar beide Gruppen das bestärkende Element für den Algorithmus sind kann man nur erraten…
Das alles ist reichhaltiges Futter für die selbst lernende Weiterentwicklung der Ranking-Algorithmen und dadurch teils sehr individuelle Suchergebnisse pro Nutzer.
Ich glaube, dass die bisherigen Einsatzgebiete für Machine Learning bei Google nur der Anfang sind. So könnten theoretisch selbstlernende Algorithmen auch für alle vorkommenden Suchanfragen angewandt werden, nicht nur wie bei Rankbrain auf die bisher unbekannten Suchwörter. Doch welche Auswirkungen hätte das Ganze für SEOs?
Welche Auswirkung haben selbst lernende Algorithmen auf SEO?
Machine Learning als Teil des Ranking-Algorithmus könnte dafür sorgen, dass Google zukünftig auf die Optimierung von statischen Rankingsignalen durch Webmaster und SEOs nicht mehr angewiesen ist.
Die Implementierung von strukturierten Daten in Form von Mark-Ups hat in der Vergangenheit nur sehr schleppend stattgefunden. So hat eine Untersuchung des Tool-Anbieters Searchmetrics aus dem Jahr 2014 ergeben, dass nur 0,3% der untersuchten Websites auf Schema.org Mark Ups setzen. Die Daten stammen aus Herbst 2013 und es ist anzunehmen. dass sich hier inzwischen etwas getan hat. Ich denke, aber das Google lieber auch ohne der technischen Mithilfe von Webmastern, Redakteuren und SEOs erkennen möchte, was sich hinter einem Inhaltsbaustein verbirgt. Die meisten Inhalts-Verantwortlichen kennen sich mit Mark-Ups nicht aus und wollen sich auch zukünftig nicht damit beschäftigen. Deswegen ist es für Google umso wichtiger Inhaltselemente auch ohne die Ausweisung strukturierter Daten zu interpretieren.
Auch was Optimierungen der Seitentitel, Alt-Tags von Bildern, etc. angeht haben viele Websites immer noch Nachholbedarf.
Anhand selbst lernender pro Nutzer individueller Such-Algorithmen kann Google alle Dimensionen bezogen auf den situativen Kontexts des jeweiligen Nutzers berücksichtigen. Jeder Nutzer hätte damit komplett eigene Suchergebnisse. Das wäre der letzte Schritt von Google zur Entmanipulierung ihrer Suchergebnisse.
Die Folgen für SEOs noch einmal kurz zusammengefasst:
- Noch personalisiertere Suchergebnisse als bisher nach Kontext des Nutzers
- Nur noch bedingte Mithilfe durch SEOs bzw. Webmaster für Google notwendig
- Manipulierung der Suchergebnisse quasi nicht mehr möglich
- Einfluss statischer Rankingfaktoren wie Seitentitel, Backlinks, Nutzung von Keywords, Alt-Tags für Bilder … nimmt weiter ab
- Aktive Optimierung nur für Suchmaschinen verliert noch mehr an Wichtigkeit
Das Ganze ist natürlich Zukunftsmusik und wann und ob überhaupt Google das Ranking komplett selbst lernenden Algorithmen übergibt bleibt abzuwarten. Dies würde mit einem nahezu kompletten Kontrollverlust durch Google einhergehen. Somit könnte Google überhaupt nicht mehr nachvollziehen, warum Rankings für den einen Nutzer so und für den anderen Nutzer so aussehen. Laut Aussage von John Mueller scheint der anarchistische Algorithmus auch bisher nicht angedacht, wie aus seiner Aussage aus dem Webmaster Hangout Anfang Dezember zu entnehmen ist:
Wir machen viel mit Machine Leraning, das ist ein faszinierendes Feld. Manchmal ist es spannend, dass die maschinellen Algorithmen auf etwas kommen, an das wir sonst nicht gedacht hätten. Dann versuchen wir herauszufinden, wie die Algorithmen darauf gekommen sind.
Es ist jedoch oft schwer, in dieser Umgebung die Fehler zu finden. Wenn wir also einen nur maschinell lernenden Algorithmus hätten, der alles macht, dann würde es sehrschwerwerden potentielle Fehler zu finden und zu beheben.
Man muss also die richtige Balancezwischen den verschiedenen Algorithmen finden. Alles muss reproduzierbar und verständlich sein, aber es muss auch Raum für Neuerungen geben.
Google scheint hier selbst noch nicht sicher zu sein wie viel Kontrolle sie an selbst lernende Algorithmen abgeben wollen. Wir werden es in Zukunft sehen oder auch nicht …
Mehr zum Thema Semantik und Machine Learning kann man hier bei uns im Blog lesen >>>
Expertenstimmen zum Einfluss von Machine Learning auf SEO
Hier einige weitere exklusive Stimmen von geschätzten Kollegen und SEO-Experten zu der Thematik Machine Learning und SEO:
 Christian Kunz: Christian ist Inhaber der Webseite SEO Südwest und Senior Project Manager Search bei 1&1. Dort ist er unter anderem für die Suche-Projekte der Marken WEB.DE und GMX verantwortlich.
Christian Kunz: Christian ist Inhaber der Webseite SEO Südwest und Senior Project Manager Search bei 1&1. Dort ist er unter anderem für die Suche-Projekte der Marken WEB.DE und GMX verantwortlich.
Für die SEOs wird sich nur wenig ändern. Warum? Dazu muss man sich den Wirkungskreislauf von SEO-Maßnahmen, Nutzersignalen und den durch maschinelles Lernen angepassten Rankingfaktoren ansehen. Gehen wir aus vom wichtigsten Indikator, den eine Webseite an Google sendet: den Nutzersignalen. Dazu gehören zum Beispiel die Verweildauer, die Absprungrate, aber auch die Gesamtzahl der Besuche und der Page Impressions. Anhand dieser Nutzersignale kann Google erkennen, ob eine Webseite den Bedürfnissen der Besucher entspricht. Wird die Seite häufig besucht, gibt es viele wiederkehrende Besucher und bleiben diese länger auf der Seite, dann kann davon ausgegangen werden, dass die Inhalte der Seite den Besuchern gefallen.
Google verwendet die besonders beliebten Seiten (und damit meine ich nicht nur die großen Webseiten, sondern zum Beispiel auch kleine Nischenseiten zu speziellen Themen) und analysiert deren Aufbau. Dabei werden nicht nur die Inhalte bewertet, sondern zum Beispiel auch die Navigation, die Seitenstruktur, das Verhältnis von Text zu Bildern und so weiter. Natürlich weiß außer einem kleinen Kreis von Google-Mitarbeitern niemand genau, wie genau diese Analyse abläuft und welche Faktoren betrachtet werden. Man kann aber mit ziemlicher Sicherheit davon ausgehen, dass die beliebten Seiten als Blaupause für die Bewertung weiterer Webseiten genutzt werden. Dabei können sich die Rankingfaktoren und deren Gewichtung immer wieder ändern. Umso mehr eine Webseite dem jeweiligen Idealbild entspricht, desto besser die Rankingchancen der Seite.
Hier kommt die Suchmaschinenoptimierung ins Spiel: Aufgabe der SEOs ist es, die Webseiten ihrer Kunden an die jeweils aktuellen Rankingfaktoren anzupassen. Wenn zum Beispiel gerade das Thema Mobilfreundlichkeit wichtig ist, dann muss dafür gesorgt werden, die Webseite des Kunden für die Darstellung auf Smartphones zu optimieren. Geht es um sichere Datenübertragung, muss die Webseite auf TLS und idealerweise auf HTTP/2 portiert werden und so weiter.
Die SEO-Maßnahmen wirken sich wiederum auf die Nutzersignale aus, die dann zur weiteren Anpassung der Rankingfaktoren führen können – ein sich fortsetzender Kreislauf also.
Die Arbeit der SEOs ändert sich im Vergleich zu früher nicht viel, denn sie sind weiterhin im Unklaren darüber, welche Rankingfaktoren mit welchem Gewicht wirken. Sie können nur spekulieren. Der Unterschied zum alten Vorgehen besteht in zwei Dingen: Erstens werden sich die Rankingfaktoren zukünftig schneller ändern, denn maschinelles Lernen wird Anpassungen nahezu in Echtzeit ermöglichen. Zweitens werden Nutzersignale wie die Verweildauer oder die Absprungrate noch wichtiger als schon in der Vergangenheit, denn sie werden die Hauptindikatoren für Google zur Bewertung der Webseitenqualität sein.
Bei alldem darf natürlich nicht vergessen werden, dass es neben dem beschriebenen Mechanismus weiterhin auch andere Rankingfaktoren geben wird, die konstant bleiben. Die Relevanz der Inhalte auf einer Webseite zur jeweiligen Suchanfrage wird genauso einfließen wie die Autorität der Webseite, gemessen an Backlinks und Signalen aus den sozialen Netzwerken.
 Markus Hövener: Markus ist Gründer und Head of SEO der auf SEO und SEM spezialisierten Online-Marketing-Agentur Bloofusion (www.bloofusion.de). Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Chefredakteur des Magazins suchradar (www.suchradar.de) und Blogger bei den Internetkapitänen (www.internetkapitaene.de). Außerdem ist er Autor vieler Artikel und Studien rund um SEO und SEM und spricht auf vielen Online-Marketing-Konferenzen.
Markus Hövener: Markus ist Gründer und Head of SEO der auf SEO und SEM spezialisierten Online-Marketing-Agentur Bloofusion (www.bloofusion.de). Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Chefredakteur des Magazins suchradar (www.suchradar.de) und Blogger bei den Internetkapitänen (www.internetkapitaene.de). Außerdem ist er Autor vieler Artikel und Studien rund um SEO und SEM und spricht auf vielen Online-Marketing-Konferenzen.
Grundsätzlich ist Machine Learning für Google ja nichts neues. Die haben zwar erst vor einigen Wochen TensorFlow („Open Source Software Library for Machine Intelligence“) veröffentlicht, aber das Thema verfolgt Google ja schon seit langem. So basiert ja schon das Panda-Update auf dem, was Googles Maschinen aus guten und schlechten Websites lernen konnten.
Für Google ist Machine Learning wahnsinnig wichtig, da sie so effizient arbeiten können und aus den gewaltigen Datenmengen Sinn machen können. Für klassisches SEO ist das natürlich der Exodus: Man kann Google halt nicht mehr mit einfachen Mitteln reinlegen und etwas mit geringer Qualität in etwas verwandeln, das Google trotzdem mag.
Für SEOs ergibt sich also ein Nachteil – aber zeitgleich auch ein Vorteil, denn es geht ja schon lange nicht mehr darum, eine bestimmte Keyword-Dichte einzuhalten. Es geht für uns als Agentur wirklich darum, den Kunden dahin zu bringen, eine erstklassige Website mit herausragenden Inhalten zu haben.
 Marcus Tober: Marcus ist nicht nur als Gründer, Geschäftsführer und treibende Kraft von Searchmetrics über einschlägige SEO Kreise hinaus bekannt, sondern auch als Impulsgeber und Experte auf vielen internationalen Bühnen: Der „Big Data und Statistik-Freak“ (Tober über Tober) ist bei Kongressen, Symposien und Think Tanks weltweit ein gefragter Gast und Keynote Speaker.
Marcus Tober: Marcus ist nicht nur als Gründer, Geschäftsführer und treibende Kraft von Searchmetrics über einschlägige SEO Kreise hinaus bekannt, sondern auch als Impulsgeber und Experte auf vielen internationalen Bühnen: Der „Big Data und Statistik-Freak“ (Tober über Tober) ist bei Kongressen, Symposien und Think Tanks weltweit ein gefragter Gast und Keynote Speaker.
In 2016 wird für den SEO explizites Analysieren oder Anwenden von Machine Learning Funktionen nicht Bestandteil der Arbeit sein. Auch wenn Machine Learning längst allgegenwärtig ist und die Grundlage für zig Updates die Suchmaschinen in den letzten Jahren gemacht haben. Was bedeutet das? Suchmaschinen benutzen schon seit vielen Jahren die gelernten Daten aus vorherigen Updates (Panda 1,2,3 etc, Penguin) und mache täglich Tests aus denen sie wiederum Anpassungen vornehmen die zu weiteren Updates führen. Bei Google ist der ständige Everflux, quasi die andauernde Bewegung der Ergebnisse.
Userdaten dienen mindestens dazu zu bewerten ob die Features die Google eingebaut oder geändert zu Verbesserungen geführt hat. Für uns SEOs heißt das ingesamt dass die abhängig von guten Ergebnissen (Rankings) weniger von nur ein paar Faktoren abhängt. Vielmehr müssen SEOs immer den Kontext berücksichtigen. Sprich die Faktoren warum eine Page erfolgreich ist können stark abweichen wenn man verschiedene Branchen oder Keywords zwischen Shorthead und Longtail betrachtet. 2016 wird sich also der Trend fortsetzen dass sich SEO je nach Webseite, Branche und natürlich Gerät (Desktop, Mobile) ändern wird und man unterschiedliche Strategien braucht um holistisch erfolgreich zu werden.
 Sebastian Erlhofer: Sebastian ist geschäftsführender Gesellschafter der mindshape GmbH aus Köln und Bestsellerautor des Buches „Suchmaschinen-Optimierung“. Er betreibt SEO seit 2002 und freut sich auf die nächste SEO-Dekade
Sebastian Erlhofer: Sebastian ist geschäftsführender Gesellschafter der mindshape GmbH aus Köln und Bestsellerautor des Buches „Suchmaschinen-Optimierung“. Er betreibt SEO seit 2002 und freut sich auf die nächste SEO-Dekade
Als Suchmaschinen-Optimierer ist man ja gewohnt, regelmäßig sich mit neuen Technologien und Bewertungsmechanismen auseinander zu setzen. Vor 10 Jahren waren es noch ganz einfache statistische Verfahren, die ein Dokumententreffer und ein Ranking ausmachten: Wenn ein bestimmtes Keyword in der Meta-Beschreibung stand, dann kam das Dokument in die Treffermenge. Und wenn das Keyword noch häufig vorkam im Dokument, dann wurde dieses auch gut geranked. Heute ist – wie jeder SEO weiß – die ganze Geschichte etwas vielfältiger. Nach der Keyworddichte kam WDF*IDF und mittlerweile geht es um holistische, verständliche und nutzerorientierte Texte, die möglichst multimodal mit Videos, Infografiken und Co aufbereitet sein sollen. Links verlieren stetig an Bedeutung bzw. die Qualität der Links ist immer wichtiger. Soweit so klar.
Was verändert maschinelles Lernen dann eigentlich? Meiner Meinung nach ist das eine weitere Stufe in der Suchmaschinen-Optimierung. Mit zunehmender Rechnerkapazität und verstärkter Forschung werden Computerprogramme immer besser darin, bestimmte Entitäten zu verstehen, zu klassifizieren und letztendlich Rankings zu generieren. Irgendwann – aber das ist meiner Meinung nach noch Jahre entfernt – wird maschinelles Lernen eingesetzt werden können, damit Algorithmen sich selbst optimieren und verbessern. Hier sind wir dann im Bereich der künstlichen Intelligenz oder vielleicht sogar von künstlichen Lebensformen. Die Einflüsse des maschinellen Lernens auf SEO sind schleichend. RankBrain und Co. kommen Stück für Stück und die Forschungsergebnisse von den schlausten Forschern, die sich Google weltweit kaufen kann, werden über die nächsten Jahre spannende „Rankingfaktoren“ produzieren.Ich denke nicht, dass wir in den nächsten zwei bis drei Jahren signifikante Auswirkungen auf unsere Arbeit als SEOs spüren werden – nicht anders als sonst auch: Es werden neue Verfahren kommen und wir werden versuchen, sie zu verstehen und zu optimieren. Im Vergleich zu Beispielen aus der Vergangenheit, etwa WDF*IDF, werden allerdings noch mehr SEOs thematisch aussteigen. Heute schon können viele SEOs kaum die Hintergründe von WDF*IDF korrekt und vollständig erklären. Man nutzt die Tools und gut ist. Das reicht auch, um hier und da gut zu optimieren und Dienstleistungen zu verkaufen. Der Einäugige ist unter den Blinden immer der Sehende. Aber maschinelles Lernen mit neuronalen Netzen, Entscheidungsalgorithmen und anderen Dingen sind nicht für Laien verständlich – ich habe selbst im Informatikstudium mich alleine nur mit den Grundlagen beschäftigt (d.h. vor allem viel Mathematik die dahinter steckt) und es ist wahnsinnig komplex. Seit mittlerweile Generationen beschäftigen sich Forscher damit, Computerprogrammen das Lesen und Verstehen von Texten beizubringen. Wir sollten als SEOs nicht den Anspruch haben, das verstehen zu können oder zu wollen.
Wir sollten trotz des Fortschritts auf technischer Seite das im Fokus behalten, was unsere Arbeit ausmacht: Produkte und Dienstleistungen von unseren Kunden in den Suchergebnissen sichtbarer machen (um SEO einmal ganz klassisch zu definieren). Wir müssen Abschied nehmen von Glaubenssätzen wie „das hat bei anderen Sites auch so funktioniert“ und wir müssen uns verabschieden von den Tipps und Tricks, den Abkürzungen, die es früher gab, um schneller zu optimieren. Ich freue mich auf das jetzige und zukünftige SEO, weil es gezwungen nachhaltiger wird und damit zwingend auf den Menschen fokussiert werden muss. Nicht mehr auf Google. Denn spätestens wenn in ein paar Jahren maschinelles Lernen große Teile im Algorithmus ausmacht, und daran glaube ich definitiv, wird auch kein Ingenieur bei Google mehr irgendwelche logischen Zusammenhänge erklären können. Das können Sie heute im Prinzip schon nicht mehr. Am Ende können wir alle dann nur noch versuchen, die Entscheidungen des Rankalgorithmus nachzuvollziehen. Eben genau so, wie wir Entscheidungen von Mitmenschen nicht immer detailliert in ihre Bestandteile sezieren können, aber wir können sie nachvollziehen. Ich freu mich drauf!
 Marcel Schrepel: Marcel ist Geschäftsführer und Gründer der Onlinemarketing-Agentur trust in time in Berlin. Die fachlichen Schwerpunkte der Agentur liegen im Suchmaschinenmarketing für D-A-CH und Russland (Yandex). Marcel ist überzeugter Slow-Blogger und schreibt Fachartikel über Suchmaschinenoptimierung (SEO), Google und die moderne Welt des Web 2.0. Er beschäftigt sich gerne mit Strategieentwicklung und Kommunikationswissenschaft und ist nebenbei als Lehrbeauftragter tätig.
Marcel Schrepel: Marcel ist Geschäftsführer und Gründer der Onlinemarketing-Agentur trust in time in Berlin. Die fachlichen Schwerpunkte der Agentur liegen im Suchmaschinenmarketing für D-A-CH und Russland (Yandex). Marcel ist überzeugter Slow-Blogger und schreibt Fachartikel über Suchmaschinenoptimierung (SEO), Google und die moderne Welt des Web 2.0. Er beschäftigt sich gerne mit Strategieentwicklung und Kommunikationswissenschaft und ist nebenbei als Lehrbeauftragter tätig.
Durch die Digitale Revolution und die Computerisierung unserer Gesellschaft, haben sich Kommunikations- und Informationsprozesse seit der Jahrtausendwende gewaltig geändert. Fast alles ist digitalisiert und Nutzer- sowie Nutzerverhalten lassen sich immer besser in Form von Daten darstellen. Durch die zunehmende mobile Nutzung lässt sich das Nutzungsverhalten von Menschen auf immer mehr Ebenen messen und algorithmisch aus- und verwerten.
Maschinelles Lernen gibt es nicht erst seit gestern. Das Finden von Gesetzmäßigkeiten in Daten ist meiner Meinung nach die Kernfunktion von Google (Information Retrieval System).Man sollte meinen, dass man aus all diesen Modellen, da stark datengetrieben, SEO relevante Muster und Daten generieren kann, die man strategisch einsetzen kann. Viele verwechseln das immer noch mit Korrelationen. Man vergisst gerne schnell die Komplexität, mit der Algorithmen heutzutage arbeiten. Google-Algorithmen, KI-Modelle und erhobene Daten – das sind alles Variablen in einer „SEO-Rechnung“, die wir nicht kennen, auch wenn das vor 10 Jahren vielleicht noch anders war.
Menschen sind launisch und verändern ihre Gewohnheiten. Lebenslagen und Jobs wechseln. Krankheit, Heirat, Kinder sind einschlägige Ereignisse. Algorithmen werden von diesen Veränderungen lernen, inwiefern sich ein Nutzer anders im Netz bewegt.
„Emotionale Intelligenz“ ist das Stichwort.
Suchmaschinen wie Google wollen auch genau das lernen, damit der Algorithmus eine gewisse Flexibilität besitzt. Durch Machine Learning bedarf es keiner ständigen Einspielung separater Algorithmen oder Algorithmus-Updates – durch Machine Learning selbst wird ein Algorithmus erst flexibel und erweitert sein „Wissen“ auf selbstständige Art und Weise – dauerhaft und zeitgemäß.
Google wird in nicht allzu ferner Zukunft in der Lage sein, Menschen zu verstehen, sie kennen zu lernen und zu erahnen, was sie als nächstes tun werden. Aktuell arbeitet Google schon mit Mustern, z.B. die personalisierte Suche oder Hummingbird.
Dem ein oder anderen dürfte vielleicht das „Google Opinion Reward“ – Programm etwas sagen.
https://www.google.com/insights/consumersurveys/google_opinion_rewards
Auf den ersten Blick scheint dies wie ein Tool für Marktforscher zu wirken. Denkt man das Ganze aber etwas utopischer in die Höhe, so könnte Google theoretisch mit solchen Umfragen auch wertvolle Zusatzdaten über einen Nutzer generieren. Daten, die sich nicht aus dem normalen Sucherverhalten schöpfen lassen, die aber zur Erstellung von Lern-Modellen unbedingt benötigt werden. Quasi ein Vorzeigedatensatz zur Referenzierung in den Lern-Algorithmen.
Das Gleiche unterstelle ich Facebook mit dem Kauf von WhatsApp.Ich denke, dass sich SEO weiterhin in eine empathiegetriebene, zielgruppenorientierte Richtung entwickeln wird, was ja einige SEO´s schon länger praktizieren. Alleine deswegen, weil SEO längst nicht mehr rein datengetrieben funktioniert. Conversion Prozesse sind längst nicht mehr einzig und allein an die Auffindbarkeit eines Angebots gekoppelt. Traffic allein ist kein Garant für eine Conversion.
Ich denke, dass Machine Learning nur ein Faktor von etlichen ist, der dafür sorgen wird, dass einheitliche Rankings verschwinden werden. Schon jetzt sind die Unterschiede messbar.
 Kai Spriestersbach: Kai ist Online Strategy Consultant und strategischer Partner der eology GmbH sowie Inhaber der strategischen SEO-Beratung SEARCH ONE. Er berät und begleitet ausgewählte Kunden bei der Positionierung im Internet sowie der Verbesserung ihrer Online-Präsenz mit Blick auf die Sichtbarkeit in den Suchmaschinen. Derzeit forscht und entwickelt er an neuen Ansätzen für Marketing Software sowie Website-Projekten und bereitet sein erstes Buchprojekt vor.
Kai Spriestersbach: Kai ist Online Strategy Consultant und strategischer Partner der eology GmbH sowie Inhaber der strategischen SEO-Beratung SEARCH ONE. Er berät und begleitet ausgewählte Kunden bei der Positionierung im Internet sowie der Verbesserung ihrer Online-Präsenz mit Blick auf die Sichtbarkeit in den Suchmaschinen. Derzeit forscht und entwickelt er an neuen Ansätzen für Marketing Software sowie Website-Projekten und bereitet sein erstes Buchprojekt vor.
In der näheren Zukunft stehen uns spannende Veränderungen ins Haus. Aber Machine Learning ist nicht neu. Die beiden Updates Panda und Penguin basieren bereits auf Machine Learning Technologie und werden nun zu einem sich kontinuierlich selbst verbessernden System ausgebaut. Anhand der Informationen über das Panda Update, die allesamt sehr vage und auf einem sehr viel abstrakteren Level waren (z.b. Würden Sie dieser Seite Ihre Kreditkarteninformationen anvertrauen) wird klar, dass es in Zukunft noch weniger Informationen von Google über Updates und direkte Rankingfaktoren geben wird.
Zum einen liegt das daran, dass Deep Learning Algorithmen selbst erkennen, welche Metriken relevant sind und die Engineers bei Google keinen Einfluß mehr darauf haben und zum anderen sehr viel mehr Daten in das Ranking einfließen werden. Hier bei ist alles vorstellbar – Googles Mitarbeiter sind sehr kreativ – wieso nicht die (auf den ersten Blick) absurdesten Informationen über Webseiten einfach mal in das System kippen und die Maschine untersuchen zu lassen, was davon sich als Rankingfaktor eignet.
Deutlich wichtiger und auch sehr viel schneller spürbar werden Nutzerdaten in das Ranking einfließen. Eine schlechte Seite wird trotz toller Optimierung und vieler Links alleine durch die Signale unzufriedener Nutzer nach unten rutschen. Das ist zwar bisher schon der Fall, allerdings nur bei sehr großen Suchvolumen und über längere Zeiträume. Hier wird Google sehr viel schneller reagieren können.
Ich betrachte selbst die Entwicklungen als sehr positiv, denn wer sich darauf konzentriert den Nutzern genau das zu bieten, was diese Suchen, wird sehr viel stärker profitieren als bisher.
 Sepita Ansari: Sepita, Geschäftsführer der Catbird Seat GmbH, ist einer der anerkanntesten SEO-Experten in Deutschland. Seit 2005 beschäftigt sich Sepita Ansari mit Online Marketing. Der Wirtschafts-und Sozialwissenschaftler war 3 Jahre bei der Scout24-Gruppe tätig und hat dort das JobScout24-Online Team geleitet.
Sepita Ansari: Sepita, Geschäftsführer der Catbird Seat GmbH, ist einer der anerkanntesten SEO-Experten in Deutschland. Seit 2005 beschäftigt sich Sepita Ansari mit Online Marketing. Der Wirtschafts-und Sozialwissenschaftler war 3 Jahre bei der Scout24-Gruppe tätig und hat dort das JobScout24-Online Team geleitet.
[poll id=“2″]Früher bedienten wir die Technik, heute dient die Technik uns und lernt und interagiert mit uns. Dank zahlreicher Sensoren, ist ein interaktiver Umgang mit Computern möglich geworden, dabei ist das Smartphone zum persönlichen Alltagsmanager geworden. Algorithmen und die künstliche Intelligenz „verstehen“ zunehmend den Bedeutungszusammenhang und liefern relevante Ergebnisse. Diese Maschinen werden uns weiter unterstützen und gar imitieren, ersetzen werden sie uns aber nicht.
Mit Hilfe von Daten können Suchmaschinen (mit stochastischer Wahrscheinlichkeit) das menschliche Suchverhalten vorhersagen, mit Hilfe von Mathematik kann die Suchvergangenheit erklärt werden. Die Zukunft kann jedoch nicht mit 100% Güte prognostiziert werden. Da unser menschliches (Such-)Verhalten auf individuellen Interpretationen und Bewertungen beruht, kann eine Maschine dieses noch schwer vorhersehen, aber sehr gut erklären. Diese Erklärbarkeit der Daten wird auch im SEO zum erfolgsentscheidenden Kriterium: Inhalte müssen individuell ansprechen, strukturiert sein und optimal innerhalb der User Journey auf den verschiedenen Medien und Geräten auf den Nutzer zugeschnitten werden. Damit wird die Datenstruktur, die -transparenz und –validität zu einem wichtigen Faktor innerhalb der Suchmaschinenoptimierung.
Weitere Beiträge zum Thema Machine Learning und SEO
- Quantum Computing, Search and The Web
- Online Radar Podcast: Google Updates, Guidelines und das Brain
- What Deep Learning and Machine Learning mean for the Future of SEO
- Rankbrain: Künstliche Intelligenz bestimmt das Ranking von Google
- Deep Learning and the Future of Search Engine Optimization
- Machine Learning for SEOs
Videos zum Thema Machine Learning und Artificial Intelligence

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























6 Kommentare
Danke für den in Umfang monströsen Artikel!
Was schema.org angeht – seitdem ich mich mit Online Marketing beschäftige, kann ich mir den Nutzen vom Mark-up Tool nicht erklären. Die Suchmaschinen, insbesondere Google, können sehr wohl fast alle Inhaltsbausteine problemlos auswerten, ohne die Hilfe dieses Tools … Na ja, wenn diese semantisch eingebaut sind. Klar, divs und spans sind nicht zu unterscheiden, doch Bilder, Überschriften, html5 gekennzeichneten Content (section / aside) usw. kann die Suchmaschine ja problemlos einordnen.
Hallo Jana, ich bekommen die Beiträge in normaler Länge nicht hin. Aber ich muss auch zugeben, dass ich es mag Dinge in die Tiefe zu beleuchten und auseinander zu nehmen. Oberflächlichkeit gibt es schon genug auf der Welt 🙂 Ja die ganze Mühe mit der Mark-Up-Auszeichnung scheint für mich auch keinen nachhaltigen Nutzen zu haben außer für Google als Vorlage für das Machine Learning.
Sehr schöner Artikel!
„Ich betrachte selbst die Entwicklungen als sehr positiv, denn wer sich darauf konzentriert den Nutzern genau das zu bieten, was diese Suchen, wird sehr viel stärker profitieren als bisher.“
Dieser letzte Satz beschreibt es schön: Den Nutzern einen Mehrwert bieten ist in Zukunft das, worauf es ankommt.
Content Farms, Clickbait… es ist zu hoffen, dass Googles Werkzeuge noch besser werden.
Denn viele Unternehmen scheinen zu vergessen, dass Sie nur einen Zweck haben: Dem Kunden einen Mehrwert bieten. Geld und Kapital kommt dann „von alleine“.