
Google hat dieses Jahr viele Patente veröffentlicht und erneut veröffentlicht. Dieser Artikel behandelt die 11 interessantesten Google-Patente.
Die Recherche zu Google-Patenten ist eine der intelligentesten Möglichkeiten, moderne Suchmaschinen wie Google zu verstehen.
Ein Pionier der Google-Patentforschung war der unvergessliche Bill Slawski. Er verstarb im Sommer 2022 vorzeitig. Er inspirierte mich dazu, selbst zu Google-Patente zu recherchieren und meine eigenen Gedanken und Theorien aus Google-Patenten zu verfassen.
Inhaltsverzeichnis
- 1 Spiegeln die Patente die tatsächlichen Praktiken von Google wider?
- 2 Search result filters from resource content
- 3 Evaluating an Interpretation for a Search Query
- 4 Generative summaries for search results
- 5 Providing search results based on a compositional query
- 6 Contextualizing knowledge panels
- 7 Systems and methods for using document activity logs to train Machine-Learned models for determining document relevance
- 8 Query composition system
- 9 Combining parameters of multiple search queries that share a line of inquiry
- 10 Presenting search result information
- 11 Multi source extraction and scoring of short query answers
- 12 Wie man SEO grundlegend lernt und welche Bedeutung Patente für SEO haben
Spiegeln die Patente die tatsächlichen Praktiken von Google wider?
Nur weil Google eine Patentanmeldung einreicht und veröffentlicht, ist das keine Garantie dafür, dass die beschriebenen Methoden in der Google-Suche implementiert werden. Um zu beurteilen, ob Google eine Methodik oder Technologie für überzeugend genug hält, um sie in der Praxis anzuwenden, kann man prüfen, ob das Patent nicht nur in den USA, sondern auch in anderen Ländern angemeldet ist. Ein Anspruch auf Patentpriorität in anderen Ländern muss innerhalb von 12 Monaten nach der Erstanmeldung geltend gemacht werden.
In diesem Artikel gehe ich nur auf Google-Patente ein, die auch außerhalb der USA veröffentlicht werden.
Auch wenn ein Patent nicht direkt in die Praxis umgesetzt wird, ist die Prüfung der Patente von Google wertvoll. Es bietet Einblicke in die Themen und Herausforderungen, auf die sich die Produktentwickler von Google konzentrieren.
Die folgenden Patente sind nicht nach Priorität sortiert.
Search result filters from resource content
Die Google-Suche wird mit mehr Filtern zur Verfeinerung der Suche noch intelligenter. Dieses neue Patent könnte eine Grundlage für die Filtermethodik sein.
Kennung:US11797626B2
Länder: USA, China, Europa, Russland
Erscheinungsdatum: Oktober 2023
Das Patent beschreibt ein System zur Verbesserung des Sucherlebnisses durch die dynamische Generierung von Suchabfragefiltern, die auf den Inhalt von Ressourcen (wie Webseiten) zugeschnitten sind, die für die Suchanfrage eines Benutzers relevant sind. Ziel dieses Ansatzes ist es, die Relevanz und Vielfalt der Suchmöglichkeiten zu verbessern.
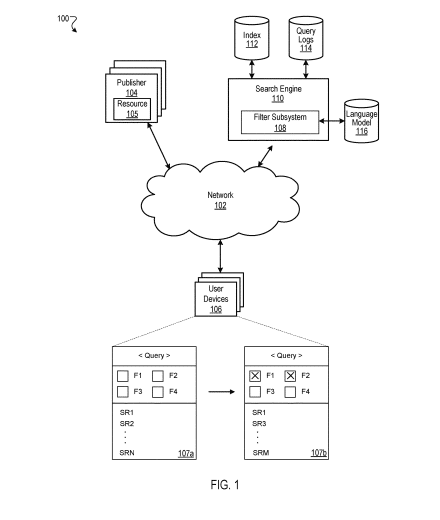
Konzeptübersicht:
- Datenverarbeitung: Das System beginnt mit der Analyse der Suchanfrage eines Benutzers, um relevante Ressourcen wie Webseiten oder Dokumente zu identifizieren.
- Schlüsselwortextraktion: Nach der Identifizierung relevanter Ressourcen werden Schlüsselbegriffe aus deren Inhalt extrahiert. Diese Schlüsselwörter spiegeln die Hauptthemen oder Themen innerhalb der Ressourcen wider. Beispielsweise könnte eine Suche nach „besten Smartphones 2023“ Schlüsselwörter wie „Akkulaufzeit“, „Kameraqualität“ und „5G-Unterstützung“ ergeben.
- Filterauswahl: Das System verfeinert diese extrahierten Schlüsselwörter zu einer Reihe von Abfragefiltern. Es verwendet Kriterien wie Diversität und Differenzschwellen, um sicherzustellen, dass jeder Filter eine einzigartige Perspektive auf die Suchergebnisse bietet. Folglich werden Filter wie „Beste Kamerahandys“, „5G-Smartphones“ und „Telefone mit langer Akkulaufzeit“ gebildet, die jeweils auf unterschiedliche Teilmengen der Suchergebnisse verweisen.
- Benutzerinteraktion: Diese Abfragefilter werden dem Benutzer dann zusammen mit seinen Suchergebnissen angezeigt. Mit dieser Funktion können Benutzer ihre Suche basierend auf bestimmten Interessen weiter verfeinern. Die Filter sind dynamisch und ändern sich als Reaktion auf die Suchanfrage und den Inhalt der aktuell verfügbaren Ressourcen. Beispielsweise würde bei der Smartphone-Suche die Auswahl des Filters „Beste Kamerahandys“ die Ergebnisse eingrenzen, um sich auf Telefone mit überlegener Kameraqualität zu konzentrieren.
Zusammenfassend bietet dieses System ein verfeinertes, benutzerorientiertes Sucherlebnis, indem es Suchanfragen verarbeitet, relevante Schlüsselwörter extrahiert, verschiedene Filter erstellt und eine dynamische Benutzerinteraktion mit diesen Filtern ermöglicht.
SEO-Implikationen
Für SEO-Profis ist es wichtig, die Nuancen dieser dynamischen Suchfiltersysteme zu verstehen. Es unterstreicht die Notwendigkeit, abwechslungsreiche, reichhaltige und relevante Inhalte zu erstellen, die gut auf die potenziellen Suchfilter abgestimmt sind. Diese Ausrichtung ermöglicht es Websites, sich effektiv in den Suchergebnissen zu positionieren und gezielt auf die unterschiedlichen Interessen und Suchanfragen der Nutzer einzugehen.
- Schwerpunkt auf vielfältigen und relevanten Inhalten: SEO-Strategien müssen sich auf die Entwicklung von Inhalten konzentrieren, die ein breites Spektrum relevanter Themen innerhalb eines bestimmten Bereichs abdecken. Dieser Ansatz beeinflusst wahrscheinlich die dynamischen Filter, die eine Suchmaschine generieren könnte, und verbessert dadurch die Sichtbarkeit der Website.
- Keyword-Optimierungn: Ein tiefes Verständnis der relevantesten und vielfältigsten Schlüsselwörter in einer bestimmten Domain ist heute wichtiger denn je. Diese Schlüsselwörter beeinflussen wahrscheinlich die Suchfilter und sind somit ein Schlüsselfaktor dafür, wie Inhalte entdeckt und eingestuft werden.
- Ausrichtung an der Benutzerabsicht: SEO-Bemühungen sollten auf ein genaues Verständnis und die Erfüllung der Benutzerabsichten ausgerichtet sein. Da sich Suchmaschinen zunehmend darauf konzentrieren, mithilfe von Filtern dynamisch auf Benutzerabsichten einzugehen, wird die Ausrichtung auf diese Absichten zu einer strategischen Notwendigkeit.
- Bleiben Sie auf dem Laufenden über neue Trends: Es ist von entscheidender Bedeutung, über neue Schlüsselwörter und Trends in einer bestimmten Domain auf dem Laufenden zu bleiben. Diese neuen Elemente könnten schnell in die dynamischen Filter integriert werden und sich auf die Relevanz der Suchergebnisse auswirken.
- Verbesserung des Benutzerengagements: Websites sollten danach streben, umfassende und vielfältige Informationen anzubieten. Dies bindet Benutzer nicht nur effektiver ein, sondern wirkt sich möglicherweise auch darauf aus, wie sie in den gefilterten Suchergebnissen angezeigt werden, und beeinflusst dadurch ihre allgemeine Suchsichtbarkeit.
Evaluating an Interpretation for a Search Query
Für Suchmaschinen ist es von entscheidender Bedeutung, die Bedeutung und Absicht einer Suchanfrage zu erkennen. Dieses Patent könnte Teil der Methodik sein.
Das Patent enthält insbesondere einen Verweis auf BERT (Bidirektionale Encoderdarstellungen von Transformers), was darauf hindeutet, dass diese Methodik im Zusammenhang mit der Anwendung von BERT in Suchalgorithmen relevant sein könnte.
Kennung:US20230334045A1
Länder: USA, China, Südkorea, Europa
Erscheinungsdatum: Oktober 2023
Das Patent beschreibt ein System und eine Methode zur Bewertung der Genauigkeit menschlicher Interpretationen von Suchanfragen, die zwei unterschiedliche Modelle umfassen:
- Erstes Modell: Dieses Modell wird anhand eines Datensatzes trainiert, der historische Suchanfragen, ihre menschlichen Interpretationen und von Menschen zugewiesene Bezeichnungen enthält, die die Genauigkeit dieser Interpretationen anzeigen. Seine Hauptfunktion besteht darin, zunächst die Genauigkeit einer menschlichen Interpretation einer Suchanfrage zu bestimmen.
- Zweites Modell: Aufbauend auf der Erstbewertung des ersten Modells integriert dieses Modell zusätzliche Faktoren wie zeitbezogene und Cluster-Merkmale der Suchanfrage. Seine Aufgabe besteht darin, ein endgültiges Urteil über die Genauigkeit der menschlichen Interpretation der Suchanfrage zu fällen.
Das Google-Patent befasst sich mit dem Konzept der Gruppierung oder Clusterung von Suchanfragen, einem Schlüsselaspekt seiner Methodik zur Bewertung von Interpretationen von Suchanfragen.
Das Patent beinhaltet das Konzept der Suchabsicht, auch wenn der Begriff „Suchabsicht“ möglicherweise nicht ausdrücklich erwähnt wird. Der Fokus des Patents auf die Genauigkeit menschlicher Interpretationen von Suchanfragen beinhaltet von Natur aus das Erkennen des beabsichtigten Zwecks oder Ziels des Benutzers hinter seiner Suchanfrage, was den Kern der Suchabsicht ausmacht. Hier ist ein Überblick darüber, wie das Patent implizit die Suchabsicht berücksichtigt:
Menschliche Interpretation von Suchanfragen:
Die Bewertung der Genauigkeit menschlicher Interpretationen von Suchanfragen durch das System erfordert grundsätzlich ein Verständnis der beabsichtigten Bedeutung oder des beabsichtigten Ziels des Benutzers. Dieses Verständnis ist von zentraler Bedeutung für das Konzept der Suchabsicht.
Verfeinerungen der Suchanfrage:
Das Patent diskutiert die Identifizierung nachfolgender Suchanfragen als Verfeinerungen früherer Suchanfragen. Dieser Prozess ist untrennbar mit der Suchabsicht verbunden, da Benutzer ihre Suche häufig verfeinern, wenn die ersten Ergebnisse ihre Absicht nicht vollständig erfüllen, was zu Anpassungen ihrer Abfragen führt, um präzisere Ergebnisse zu erzielen.
Zeit- und Clusterfunktionen:
Durch die Berücksichtigung von Zeit- und Clustermerkmalen im Bewertungsprozess befasst sich das System indirekt mit dem Kontext und den Nuancen der Suchabsicht. Beispielsweise kann der Zeitpunkt der Abfragen oder deren Gruppierung innerhalb bestimmter Themencluster Aufschluss über die angestrebten Ziele der Nutzer geben.
Trainingsdatensatz mit vom Menschen bewerteten Etiketten:
Die Einbeziehung menschlicher Interpretationen und ausgewerteter Bezeichnungen für frühere Suchanfragen in den Trainingsdatensatz weist darauf hin, dass das System aus früheren Fällen lernt, in denen menschliches Urteilsvermögen zum Verständnis der Absicht hinter einer Suchanfrage genutzt wurde.
Vektorsatzdarstellungen und Distanzalgorithmen:
Die Verwendung von Vektorsatzdarstellungen und Distanzalgorithmen beim Parsen und Gruppieren von Abfragen hängt mit dem Verständnis der Suchabsicht zusammen. Diese Technologien helfen dabei, die semantischen Bedeutungen und Feinheiten von Abfragen zu verstehen, die für die Erkennung der Benutzerabsichten von entscheidender Bedeutung sind.
SEO-Implikationen:
- Schwerpunkt auf genauer Abfrageinterpretation: SEO-Strategien sollten die Ausrichtung von Inhalten auf die wahrscheinlichen Interpretationen von Suchanfragen durch Benutzer priorisieren. Das Verstehen und Abgleichen der erwarteten Interpretationen der Benutzeranfragen ist für eine effektive Suchmaschinenoptimierung von entscheidender Bedeutung.
- Bedeutung von Kontext und Zeitlichkeit: Es ist wichtig, dass Inhalte unter Berücksichtigung des zeitlichen Kontexts und einer möglichen Häufung von Themen oder Schlüsselwörtern optimiert werden. Dieser Ansatz stellt sicher, dass der Inhalt relevant bleibt und basierend auf neuen Trends und zeitkritischen Abfragen genau indiziert wird.
- Anpassung an Suchverfeinerungen: Die Optimierung von Websites für verfeinerte Suchen ist wichtig, da diese Verfeinerungen auf anfängliche Missverständnisse oder Fehlinterpretationen durch Suchmaschinen hinweisen können. Ein Fokus auf die Beantwortung verfeinerter Suchanfragen kann die Relevanz und Genauigkeit einer Website in den Suchergebnissen verbessern.
- Nutzung natürlicher Sprachverarbeitung (NLP): Mit der Integration von Methoden wie BERT in Suchmaschinen wird die Einbeziehung von NLP-Strategien in die Inhaltserstellung immer wichtiger. Diese Angleichung an die Abfrageinterpretationsmethoden von Suchmaschinen kann die Sichtbarkeit und Relevanz einer Website in den Suchergebnissen verbessern.
Generative summaries for search results
Dieses Patent ist das einzige in dieser Liste, was bisher nur in US veröffentlicht wurde. Aufgrund der Nähe zu SGE habe ich es hier dennoch mit aufgenommen.
Kennung:US11769017B1
Länder: USA
Erscheinungsdatum: 26. September 2023

Dieses Google-Patent beschäftigt sich mit der Verwendung von großen Sprachmodellen (LLMs) zur Generierung von natürlichsprachigen Zusammenfassungen in Antwort auf Suchanfragen.
Das Patent beschreibt eine Methode, die die selektive Verwendung eines großen Sprachmodells (LLM) zur Generierung von natürlichsprachigen (NL) Zusammenfassungen in Antwort auf Benutzeranfragen beinhaltet. Es führt die Idee ein, zusätzliche Inhalte über die Anfrage hinaus mithilfe des LLM zu verarbeiten, um genauere und kontextbewusstere NL-Zusammenfassungen zu generieren. Das Ziel ist es, Ungenauigkeiten sowie Über- oder Unterbeschreibungen der generierten Zusammenfassungen zu reduzieren.
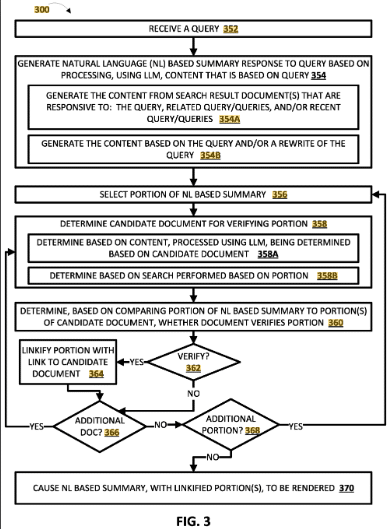
Prozess:
- Verarbeitung zusätzlicher Inhalte, einschließlich Suchergebnis-Dokumenten, die auf die Anfrage reagieren.
- Generierung von Zusammenfassungen basierend auf verschiedenen zusätzlichen Inhalten, um die Relevanz für den Benutzer zu erhöhen.
- Überarbeitung von Zusammenfassungen basierend auf Benutzerinteraktion mit den Suchergebnissen.
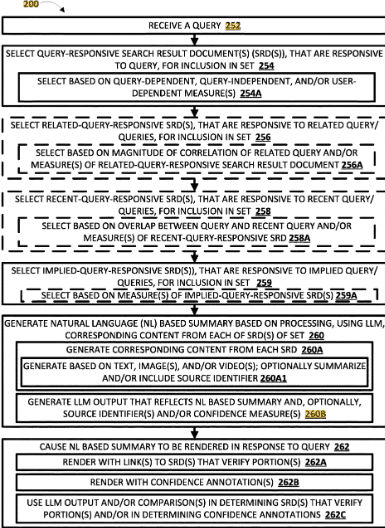
Faktoren:
- Unterschiedliche Verarbeitung von zusätzlichem Inhalt für verschiedene Anfragen.
- Berücksichtigung des Kontext des Nutzers mit bestimmten Inhalten.
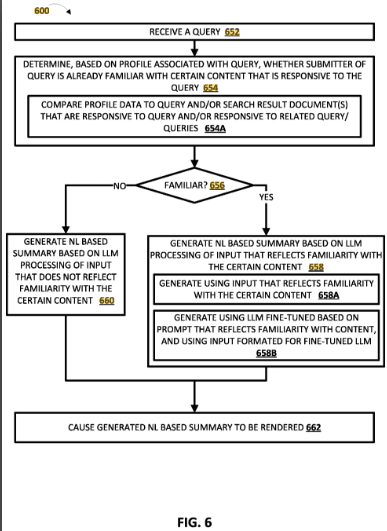
Die Methoden aus diesem Patent nutzen LLMs, um bessere, genauere und benutzerfreundlichere natürlichsprachige Zusammenfassungen in Reaktion auf Suchanfragen zu generieren. Dies wird erreicht, indem zusätzliche Inhalte, einschließlich Suchergebnis-Dokumenten, in die Generierung einbezogen werden. Dadurch können Ungenauigkeiten reduziert und die Relevanz für den Benutzer verbessert werden.
Auswirkungen auf SEO
Dieses Patent könnte erhebliche Auswirkungen auf die Suchmaschinenoptimierung (SEO) haben, da es die Art und Weise verändert, wie Suchergebnisse zusammengefasst und präsentiert werden. SEO-Experten müssen möglicherweise ihre Strategien anpassen, um sicherzustellen, dass ihre Inhalte in den generierten Zusammenfassungen berücksichtigt werden und die Benutzererfahrung verbessert wird. Mehr dazu im Artikel Sind LLMO oder GAIO die Zukunft von SEO? . Es wird auch wichtig sein, die Benutzerfamiliarität mit Inhalten zu berücksichtigen, um relevantere Zusammenfassungen zu generieren.
Providing search results based on a compositional query
Google entwickelt die Suche immer mehr zu einer Entitäten basierten Suchmaschine. Daher ist es von entscheidender Bedeutung, relevante Ergebnisse nach Einheiten zu liefern. Dieses Patent könnte ein Teil des Puzzles sein, um Entitäten und ihre Beziehungen besser zu verstehen.
Kennung:US11762933B2
Länder: USA, Europa, China
Erscheinungsdatum: September 2023
Das Patent beschreibt eine Technik zur Bereitstellung von Suchergebnissen basierend auf kompositorischen Abfragen. Diese Methode umfasst das Erkennen von Entitätstypen und ihren Beziehungen innerhalb der Abfrage, das Lokalisieren von Knoten innerhalb eines Wissensgraphen und das Bewerten von Attributwerten, um die resultierenden Entitätsreferenzen zu ermitteln. Dieses System ist in der Lage, Abfragen zu verwalten, die relative Beziehungen zwischen verschiedenen Entitätstypen beinhalten, und bietet so Suchergebnisse, die aussagekräftiger und kontextbezogener sind.
Kompositionsabfragen, wie sie im Patent und allgemein im Bereich der Suche und des Informationsabrufs beschrieben werden, umfassen Abfragen, die mehrere Entitätstypen und deren Wechselbeziehungen umfassen. Im Gegensatz zu Abfragen, die sich auf ein einzelnes Schlüsselwort oder eine einzelne Entität konzentrieren, zielen kompositorische Abfragen darauf ab, Ergebnisse basierend auf der Beziehung verschiedener Entitäten in der Abfrage zueinander zu interpretieren und zu generieren.
Hier eine Übersicht:
- Mehrere Entitätstypen: Kompositionsabfragen enthalten Verweise auf mindestens zwei verschiedene Entitätstypen. Eine Entität bezieht sich hier auf alles, was eindeutig, einzigartig und genau definiert ist, wie eine Person, ein Ort, ein Objekt, ein Konzept usw.
- Relative Beziehungen: Die Entitäten in diesen Abfragen sind durch eine Form relativer Beziehungen verknüpft. Bei diesen Beziehungen kann es sich um räumliche, zeitliche oder andere Arten von Verbindungen handeln, die die Entitäten gezielt auf sinnvolle Weise miteinander verbinden.
SEO-Implikationen:
- Komplexe Abfragebearbeitung: SEO-Experten sollten beachten, dass Suchmaschinen wahrscheinlich zu einer ausgefeilteren Handhabung von Suchanfragen übergehen, bei denen es um das Zusammenspiel verschiedener Entitäten geht. Diese Entwicklung erfordert ein tieferes Verständnis dafür, wie Inhalte für diese komplexen Abfragestrukturen optimiert werden können.
- Optimierung des Wissensgraphen: Angesichts des Fokus des Patents auf die Verwendung eines Wissensgraphen ist es zwingend erforderlich, Inhalte so zu optimieren, dass sie in diesen Graphen genau erkannt und kategorisiert werden. Eine effektive Integration in Wissensgraphen kann die Sichtbarkeit und Relevanz von Inhalten erheblich verbessern.
- Entitätsanerkennung: Es ist von entscheidender Bedeutung, Inhalte so zu strukturieren, dass Suchmaschinen die verschiedenen Entitäten und ihre Beziehungen leicht erkennen und kategorisieren können. Eine klare und logische Organisation von Informationen kann die Auffindbarkeit und Relevanz des Inhalts bei Suchanfragen mit mehreren Entitäten verbessern.
- Kontextbezogene Relevanz: SEO-Strategien sollten vorrangig darauf achten, sicherzustellen, dass Inhalte kontextuell relevant sind. Dabei muss die Fähigkeit der Suchmaschine berücksichtigt werden, die Attribute verschiedener Entitäten zu verstehen und zu vergleichen und so die Inhaltsstrategie mit den erweiterten Interpretationsfähigkeiten der Suchmaschine in Einklang zu bringen.
Contextualizing knowledge panels
Knowledge Panels sind das Fenster zum Google Knowledge Graph und den gespeicherten Entitäten. Die Bereitstellung relevanter und korrekter Informationen für die einzelnen Unternehmen ist von entscheidender Bedeutung. Diese Panels sind in Standardsuchergebnisse integriert und bieten eine umfassende Informationsquelle.
In diesem Patent werden Methoden zur Bewältigung dieser Aufgabe erörtert.
Kennung:US11720577B2
Länder: USA, Japan, Südkorea, China, Deutschland, Europa
Letztes Erscheinungsdatum: August 2023
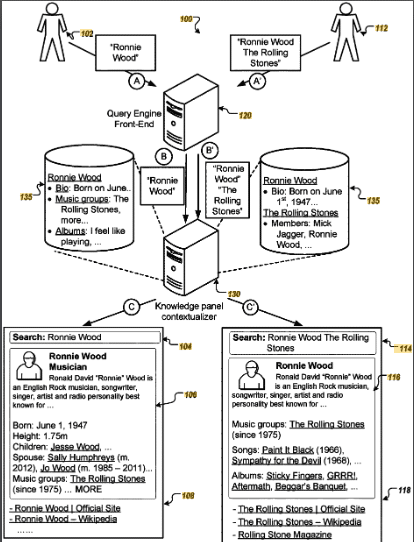
Das Patent konzentriert sich auf Methoden, Systeme und Geräte zur Verbesserung von Suchmaschinenergebnissen durch die Einbindung von Wissenspanels, die kontextbezogene Informationen zu Suchanfragen bereitstellen. Diese Wissenspanels werden basierend auf der Identifizierung von Entitäten (wie Sängern, Schauspielern, Musikern) und Kontextbegriffen in Benutzersuchanfragen generiert.
- Entitätsidentifikation: Das System identifiziert Entitäten, auf die in einer Suchabfrage verwiesen wird.
- Kontextbegriffe: Es identifiziert auch Kontextbegriffe, die diesen Entitäten zugeordnet sind.
- Wissenspanels: Basierend auf diesen Identifikationen werden Wissenspanels generiert, die relevante Fakten und Informationen über die Entität im Kontext der Suchanfrage bereitstellen.
- Ranking und Auswahl: Das System weist verschiedenen Wissenselementen basierend auf ihrer Relevanz für die Kontextbegriffe Rangbewertungen zu und wählt die relevantesten für die Anzeige aus.
Ziel der Wissenspanels ist es, das Benutzererlebnis zu verbessern, indem relevantere, kontextbezogene Informationen direkt in den Suchergebnissen bereitgestellt werden.
Der Inhalt von Knowledge Panels ändert sich dynamisch basierend auf den in der Suchabfrage enthaltenen Kontextbegriffen.
Das System verwendet einen ausgefeilten Ranking-Mechanismus, um die relevantesten anzuzeigenden Wissenselemente zu ermitteln.
Dieses Patent unterstreicht die sich weiterentwickelnde Natur von Suchmaschinen hin zu einer kontextbewussteren und benutzerorientierten Informationsbeschaffung, die für SEO-Praktiker von entscheidender Bedeutung ist, um sie zu verstehen und sich daran anzupassen.
Implikationen für SEO
- Fokus auf entitätsbasierter Optimierung: SEO-Strategien sollten die Bedeutung von Entitäten und ihrem Kontext bei der Inhaltserstellung berücksichtigen.
- Rich-Content-Erstellung: Die Erstellung von Inhalten, die Entitäten und ihre zugehörigen Aspekte umfassend abdecken, kann die Chancen erhöhen, in Wissenspanels vorgestellt zu werden.
- Keyword-Strategie: Durch die Integration relevanter Kontextbegriffe neben primären Keywords kann die Sichtbarkeit des Inhalts verbessert werden.
- Benutzerabsicht verstehen: SEO-Bemühungen sollten auf dem Verständnis der Benutzerabsicht und der kontextbezogenen Verwendung von Suchbegriffen ausgerichtet sein.
Systems and methods for using document activity logs to train Machine-Learned models for determining document relevance
Benutzerinteraktion und Benutzerprotokolle sind eine wichtige Quelle für die Optimierung der maschinellen Lernalgorithmen von Google, die für die Ranking-Ergebnisse verantwortlich sind. Dieses Patent beschreibt Techniken zur Bewältigung dieser Aufgabe.
Kennung:US20230267277A1
Länder: Vereinigte Staaten, WIPO
Letztes Erscheinungsdatum: 24. August 2023
Hinweis: Dieses Patent hat den Status schwebend. Dies bedeutet, dass es heute nicht verwendet wird, aber in Zukunft verwendet werden könnte.
Das Patent beschreibt Systeme und Methoden zum Trainieren eines maschinell erlernten semantischen Matching-Modells unter Verwendung von Dokumentaktivitätsprotokollen, um die Dokumentrelevanz zu bestimmen. Dieser Ansatz ist besonders nützlich für Umgebungen wie Cloud-Speicher oder private Dokumentenspeicher, in denen der Zugriff auf Inhaltsdaten oder Benutzerinteraktionsdaten begrenzt ist.
Diese Methode ist in Szenarien von Vorteil, in denen herkömmliche Datenquellen wie Benutzerinteraktionsdaten oder vollständiger Dokumentinhalt nicht verfügbar sind.
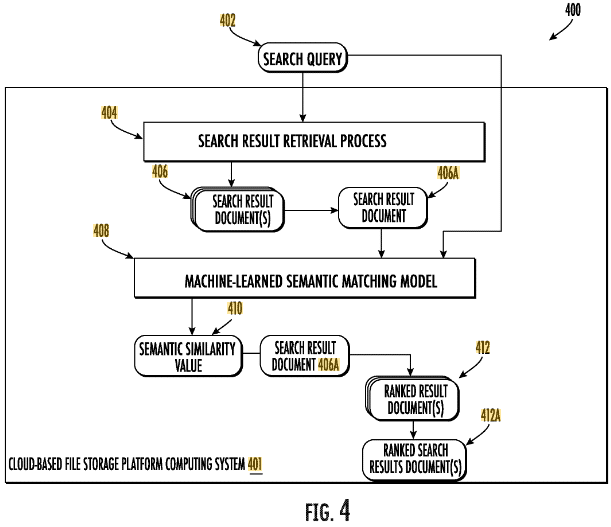
Verfahren:
- Datenerfassung: Besorgen Sie sich zwei Dokumente zusammen mit den jeweiligen Aktivitätsprotokollen.
- Bestimmung der Beziehungsbezeichnung: Bestimmen Sie anhand der Aktivitätsprotokolle eine Beziehungsbezeichnung, die angibt, ob die Dokumente miteinander verbunden sind.
- Semantische Ähnlichkeitsbewertung: Geben Sie die Dokumente in das Modell ein, um einen semantischen Ähnlichkeitswert zu erhalten, der die geschätzte semantische Ähnlichkeit zwischen ihnen darstellt.
- Modelltraining: Bewerten Sie eine Verlustfunktion, die den Unterschied zwischen der Beziehungsbezeichnung und dem semantischen Ähnlichkeitswert bewertet. Ändern Sie die Modellparameter basierend auf dieser Verlustfunktion.
Faktoren:
- Dokumentaktivitätsprotokolle: Dazu gehören Zugriffszeitstempel und Arten von Interaktionen (z. B. Bearbeiten, Teilen).
- Beziehungsbezeichnungen: Werden basierend auf der Zeitdifferenz zwischen den Zugriffen auf die Dokumente generiert.
- Semantischer Ähnlichkeitswert: Eine Ausgabe des Modells, die schätzt, wie ähnlich zwei Dokumente sind.
- Verlustfunktion: Wird verwendet, um das Modell durch Vergleich der Beziehungsbezeichnung mit dem semantischen Ähnlichkeitswert zu verfeinern.
Implikationen für SEO
- Schwerpunkt auf Benutzerinteraktion: SEO-Strategien müssen sich möglicherweise stärker auf die Benutzerinteraktion mit Dokumenten konzentrieren, da diese Daten die Dokumentenrelevanz beeinflussen können.
- Über Schlüsselwörter hinaus: Die Relevanz von Inhalten könnte durch Benutzerverhalten und Dokumentinteraktionen bestimmt werden, nicht nur durch Schlüsselwörter.
- Private und Cloud-Dokumente: SEO für private oder in der Cloud gespeicherte Dokumente hängt möglicherweise mehr davon ab, wie auf diese Dokumente zugegriffen und wie sie verwendet werden, als von herkömmlichen On-Page-Faktoren.
- Prädiktive Modellierung: Das Verstehen und Vorhersagen des Benutzerverhaltens könnte ein wichtiger Bestandteil von SEO-Strategien werden.
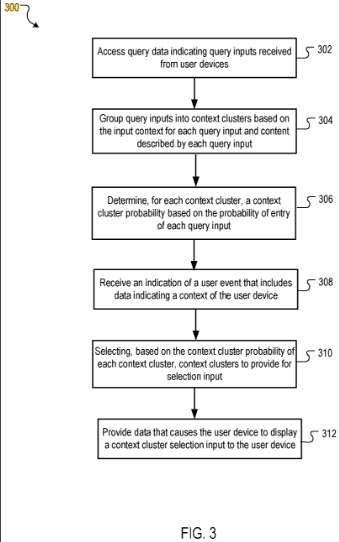
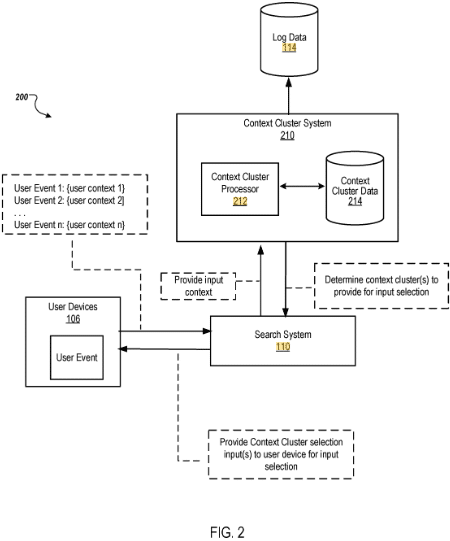
Query composition system
Suchergebnisse sind immer kontextbezogener. Eine bessere Erkennung des Kontexts einer Suchanfrage und des Benutzers führt zu besseren Suchergebnissen und einem besseren Benutzererlebnis. Dieses Patent ist eine Lösung, um diese Herausforderung zu meistern.
Kennung:US20230244657A1
Länder: USA, China, WIPO, Russland
Letztes Veröffentlichungsdatum: 3. August 2023
Hinweis: Dieses Patent hat den Status schwebend. Dies bedeutet, dass es heute nicht verwendet wird, aber in Zukunft verwendet werden könnte.
Das Patent konzentriert sich auf Methoden, Systeme und Geräte zur Generierung von Daten, die Kontextcluster und Kontextclusterwahrscheinlichkeiten beschreiben. Diese Cluster werden basierend auf Abfrageeingaben und dem mit jeder Abfrageeingabe verknüpften Kontext gebildet.
Das Patent beschreibt ein System, das den Suchabfrageprozess durch die Verwendung von Kontextclustern vereinfacht. Diese Cluster werden basierend auf dem Kontext und Inhalt früherer Abfragen gebildet. Wenn ein Benutzer eine Suche startet, präsentiert das System relevante Kontextcluster, sodass der Benutzer eine Abfrage auswählen kann, ohne sie eingeben zu müssen.
Das System zielt darauf ab, das Benutzererlebnis zu verbessern, indem es kontextrelevante Suchvorschläge bereitstellt, ohne dass der Benutzer Zeichen der Suchabfrage eingeben muss.
Verfahren
- Datenverarbeitung und Gruppierung: Das System greift auf Abfragedaten mehrerer Benutzer zu und gruppiert diese Abfragen basierend auf ihrem Eingabekontext und Inhalt in Kontextclustern.
- Bestimmung der Kontextcluster-Wahrscheinlichkeit: Für jeden Kontextcluster wird eine Wahrscheinlichkeit berechnet, die die Wahrscheinlichkeit angibt, dass eine zu diesem Cluster gehörende Abfrageeingabe von einem Benutzer ausgewählt wird.
- Reaktion auf ein Benutzerereignis: Beim Empfang eines Hinweises auf ein Benutzerereignis (z. B. Zugriff auf eine Suchmaschine) wählt das System einen Kontextcluster basierend auf dem Kontext des Benutzergeräts und den berechneten Wahrscheinlichkeiten aus.
- Anzeige und Auswahl: Der ausgewählte Kontextcluster wird dem Benutzer dann zur Auswahl angezeigt, gefolgt von einer Liste von Abfragen innerhalb dieses Clusters für weitere Eingaben.
Faktoren
- Eingabekontext: Beinhaltet Faktoren wie Standort, Datum und Uhrzeit sowie Benutzerpräferenzen.
- Inhalt der Abfrageeingaben: Der tatsächliche Inhalt, der von jeder Abfrageeingabe beschrieben wird.
- Kontext-Cluster-Wahrscheinlichkeit: Eine Metrik, die die Wahrscheinlichkeit angibt, dass eine Abfrageeingabe aus einem Cluster vom Benutzer ausgewählt wird.
Implikationen für SEO
- Konzentrieren Sie sich auf Kontextrelevanz: SEO-Strategien sollten Inhalte priorisieren, die mit Benutzerkontexten wie Ort und Zeit übereinstimmen.
- Verbessertes Verständnis der Benutzerabsicht: Das Verständnis der wahrscheinlichen Kontextcluster kann dabei helfen, Inhalte genauer an die Benutzerabsicht anzupassen.
- Anpassung an abfragelose Suchen: SEO muss sich an Szenarien anpassen, in denen Benutzern Vorschläge gemacht werden, bevor sie eine Abfrage eingeben, wobei die Bedeutung der Einbeziehung in relevante Kontextcluster betont wird.
Dieses Patent zeigt einmal mehr, wie wichtig für Google der individuelle Kontext eines Nutzers ist. Hierauf liegt der Fokus.
Kennung:US11762848B2
Länder: USA, China
Letztes Veröffentlichungsdatum: 19. September 2023
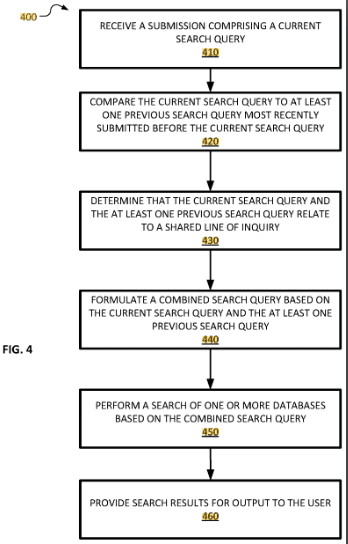
Das Patent konzentriert sich auf die Verbesserung der Suchabfrageverarbeitung. Es stellt eine Methode zum Generieren einer kombinierten Suchabfrage vor, die auf den Parametern einer aktuellen Suchabfrage und einer oder mehreren vorherigen Abfragen desselben Benutzers basiert, sofern diese Abfragen eine gemeinsame Anfragelinie haben.
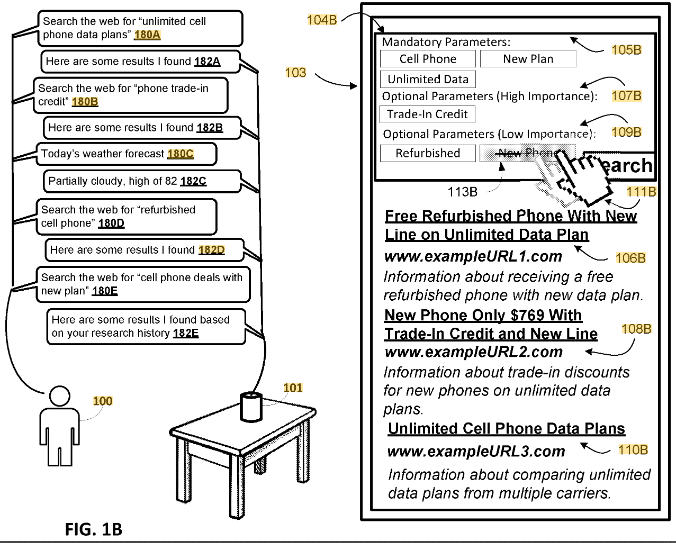
Das Patent beschreibt eine Methode zur Optimierung des Online-Sucherlebnisses durch die intelligente Kombination mehrerer verwandter Suchanfragen zu einer einzigen, effektiveren Suchanfrage. Dieser Ansatz nutzt semantische Analyse und Benutzerinteraktion, wodurch möglicherweise Redundanzen in Suchergebnissen reduziert und die Relevanz der abgerufenen Informationen erhöht werden.
Im Wesentlichen deutet dieses Patent auf einen deutlichen Wandel hin zu einem differenzierteren, kontextbewussten Suchprozess hin, der SEO-Strategien mit Schwerpunkt auf semantischer Relevanz und Benutzerabsicht neu gestalten könnte.
Verfahren
- Identifizierung einer gemeinsamen Anfragelinie: Das System erkennt, wenn zwei oder mehr Suchanfragen eines Benutzers semantisch verwandt sind und somit eine gemeinsame Anfragelinie haben.
- Kombinieren von Suchabfragen: Sobald eine gemeinsame Suchlinie eingerichtet ist, formuliert das System eine kombinierte Suchabfrage, die Parameter sowohl der aktuellen als auch der vorherigen Abfragen enthält.
- Benutzerinteraktion und Feedback: Benutzer können mit den Suchparametern oder Ergebnissen interagieren, um die kombinierte Suchabfrage zu verfeinern.
Faktoren
- Semantische Ähnlichkeit: Das System verwendet semantische Ähnlichkeit, die durch die Einbettung von Abfragen in den latenten Raum und die Berechnung der Abstände zwischen diesen Einbettungen gemessen wird, um festzustellen, ob Abfragen miteinander verbunden sind.
- Verknüpfung von Grammatiken und Heuristiken: Das System kann auch Verknüpfungsgrammatiken oder Heuristiken verwenden, um verwandte Abfragen zu identifizieren, insbesondere in Sprachsuchszenarien.
- Stateful Research-Modus: Benutzer werden möglicherweise aufgefordert, in einen Stateful Research-Modus zu wechseln, der es dem System ermöglicht, frühere Abfragen für die Formulierung kombinierter Abfragen zu verwenden.
Implikationen für SEO
- Verstärkter Fokus auf semantische Relevanz: SEO-Strategien müssen möglicherweise mehr Wert auf semantische Relevanz und Kontext legen, da das Patent darauf hinweist, dass Google sich zunehmend auf das Verstehen und Verknüpfen semantisch verwandter Abfragen konzentriert.
- Long-Tail-Keyword-Optimierung: Die Möglichkeit, Abfragen zu kombinieren, deutet auf eine mögliche Verlagerung hin zu Long-Tail-Keywords und konversationelleren Abfrageformaten hin.
- Inhaltsstrukturierung: Inhalte müssen möglicherweise so strukturiert werden, dass sie sich nahtlos in eine Reihe verwandter Suchanfragen einfügen und so ihre Chancen erhöhen, in einem kombinierten Suchszenario gefunden zu werden.
- Optimierung der Sprachsuche: Durch die Verwendung von Verknüpfungsgrammatiken wird die Optimierung für die Sprachsuche immer wichtiger, da das System gesprochene Abfragen im Laufe der Zeit verknüpfen kann.
Presenting search result information
Auf den ersten Blick erscheint dieses Patent etwas verwirrend, da es um die Verwendung von Inhalten, Markups und Anmerkungen vom Gerät des Benutzers geht. Vor allem aber zeigt es, dass Suchmaschinen wie Google in Zukunft hochgradig personalisierte Suchergebnisse liefern könnten.
Kennung:US20230244657A1
Länder: USA, China, WIPO, Russland
Letztes Veröffentlichungsdatum: 3. Oktober 2023
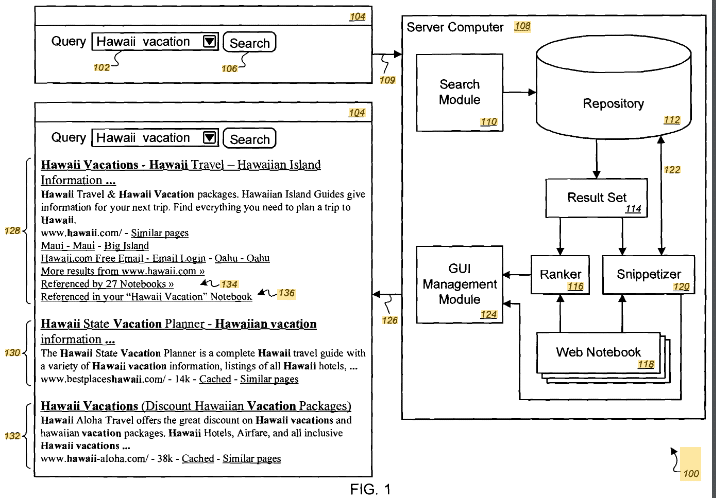
Im Mittelpunkt des Patents steht eine Methode zur Darstellung computergenerierter Suchergebnisse. Dabei geht es darum, eine Suchanfrage zu erhalten, mehrere Suchergebnisse zu identifizieren, diese Ergebnisse mithilfe von Inhalten aus einem oder mehreren Web-Notizbüchern in eine Rangfolge zu bringen und diese dann in der Rangliste aufgeführten Ergebnisse zur Präsentation bereitzustellen.
Das Patent beschreibt eine Methode zur Verbesserung der Genauigkeit und Relevanz von Suchergebnissen durch die Einbindung von Inhalten aus Web-Notizbüchern. Dieser Ansatz ermöglicht ein personalisierteres und kontextbezogeneres Sucherlebnis, da die Rangfolge der Suchergebnisse durch benutzergenerierte Inhalte und Anmerkungen in Webnotizbüchern beeinflusst wird.
Web-Notizbücher, auf die im Google-Patent Bezug genommen wird, sind digitale Sammlungen von Inhalten, die Benutzer aus verschiedenen Webquellen erstellen und zusammenstellen. Diese Notizbücher können eine Reihe von Inhaltstypen wie Textauszüge, Bilder und möglicherweise Benutzeranmerkungen oder Metadaten enthalten. Zu den wichtigsten Merkmalen und Einsatzmöglichkeiten von Web-Notizbüchern gehören:
- Inhaltsaggregation: Benutzer schneiden Inhalte aus verschiedenen Webseiten aus oder wählen sie aus und fassen diese Informationen an einem einzigen Ort zusammen. Dies kann zum persönlichen Nachschlagen, zur Recherche oder zum Teilen mit anderen dienen.
- Benutzeranmerkungen und Metadaten: Zusätzlich zu den ausgeschnittenen Inhalten können Benutzer dem Inhalt dieser Notizbücher eigene Anmerkungen, Kommentare oder Metadaten hinzufügen. Dies könnte Kontext oder persönliche Einblicke in die gesammelten Informationen liefern.
- Themenorientierte Sammlungen: Web-Notizbücher konzentrieren sich häufig auf bestimmte Themen oder Themen. Beispielsweise könnte ein Benutzer ein Web-Notizbuch über „nachhaltige Gartenpraktiken“ oder „Ressourcen für die Webentwicklung“ erstellen.
- Teilbarkeit und Zugänglichkeit: Diese Notizbücher können privat sein oder mit einer ausgewählten Gruppe von Benutzern geteilt oder sogar öffentlich gemacht werden. Dies ermöglicht den Austausch kuratierter Informationen und Erkenntnisse.
- Dynamischer Charakter: Im Gegensatz zu statischen Lesezeichen können Web-Notizbücher kontinuierlich aktualisiert und bearbeitet werden, was sie zu einer dynamischen Ressource zum Sammeln und Organisieren von Webinhalten macht.
Suchmaschinenintegration: Wie aus dem Patent hervorgeht, können Inhalte in Web-Notizbüchern verwendet werden, um Suchmaschinenergebnisse zu beeinflussen. Die Suchmaschine könnte die Relevanz des Inhalts in diesen Notizbüchern für eine bestimmte Suchanfrage berücksichtigen und sie möglicherweise zur Verfeinerung und Personalisierung der Suchergebnisse verwenden.
Verfahren
- Empfangen einer Suchanfrage: Die Methode beginnt mit dem Empfang einer Suchanfrage von einem Client-Computer.
- Identifizieren von Suchergebnissen: Anschließend werden mehrere Suchergebnisse als Reaktion auf die Anfrage identifiziert.
- Ranking mithilfe von Web-Notizbüchern: Die Suchergebnisse werden anhand der Inhalte in Web-Notizbüchern eingestuft. Dazu gehört die Prüfung, ob Titel, Überschriften, ausgeschnittene Inhalte, Metadaten oder Benutzeranmerkungen in den Web-Notizbüchern einen Bezug zur Suchanfrage haben. Wenn ja, erhöht sich das Ranking der referenzierten Suchergebnisse.
- Bereitstellung geordneter Ergebnisse: Abschließend werden die geordneten Suchergebnisse zur Präsentation auf dem Client-Computer bereitgestellt.
Faktoren
- Inhalt von Web-Notizbüchern: Der Inhalt von Web-Notizbüchern spielt eine entscheidende Rolle für das Ranking. Es umfasst Titel, Überschriften, ausgeschnittene Inhalte, Metadaten und Benutzeranmerkungen.
- Backlink-Analyse: Der Prozess kann auch die Analyse von Backlinks umfassen, die den Suchergebnissen entsprechen.
- Benutzeridentität: Die Auswahl von Web-Notizbüchern für das Ranking kann auf der Identität des Benutzers basieren, der die Suchanfrage initiiert.
- Snippet-Informationen: Teil des Prozesses ist die Generierung von Snippet-Informationen durch die Identifizierung von Teilen von Dokumenten in Web-Notizbüchern, die mit den Suchergebnissen verknüpft sind.
Implikationen für SEO
- Bedeutung von benutzergenerierten Inhalten: SEO-Strategien müssen möglicherweise den Schwerpunkt auf benutzergenerierte Inhalte legen, da Web-Notizbücher das Suchranking beeinflussen.
- Personalisierung und Kontext: Es gibt einen Trend hin zu stärker personalisierten und kontextbezogenen Suchergebnissen, weshalb es für SEO wichtig ist, sich auf diese Aspekte zu konzentrieren.
- Verschiedene Inhaltstypen: Die Einbeziehung verschiedener Inhaltstypen wie Metadaten, Anmerkungen und ausgeschnittene Inhalte könnte für SEO wichtiger werden.
Multi source extraction and scoring of short query answers
Die Ausgabe direkter Antworten in den SERPs nimmt immer mehr zu. Ein Beispiel hierfür sind die Informationen, die direkt aus dem Knowledge Graph ausgegeben werden, sowie Featured Snippets und die Antworten in den Snapshot AI Boxen bei SGE. Dieses Patent zeigt Methoden zur Generierung und Auswahl solcher direkter Antworten.
Kennung:US20230342411A1
Länder: USA, Europa, WIPO, Südkorea
Letztes Veröffentlichungsdatum: 26. Oktober 2023
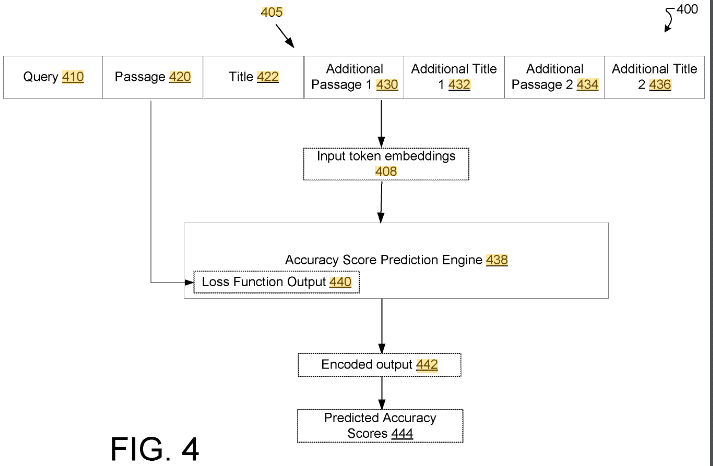
Das Patent konzentriert sich auf die Verbesserung der Qualität von Kurzantworten, die von Suchmaschinen bereitgestellt werden. Es stellt eine Methode zum Generieren und Bewerten dieser Kurzantworten auf der Grundlage mehrerer Quellen vor, anstatt sich auf ein einzelnes Suchergebnis mit dem höchsten Rang zu verlassen.
Das Patent beschreibt eine Methode zur Verbesserung der Zuverlässigkeit und Genauigkeit von Kurzantworten in Suchmaschinenergebnissen. Dies geschieht durch die Bewertung einer Kandidatenpassage anhand anderer Kontextpassagen aus unterschiedlichen Suchergebnissen, wodurch ein höheres Maß an Genauigkeit und Relevanz gewährleistet wird.
Verfahren
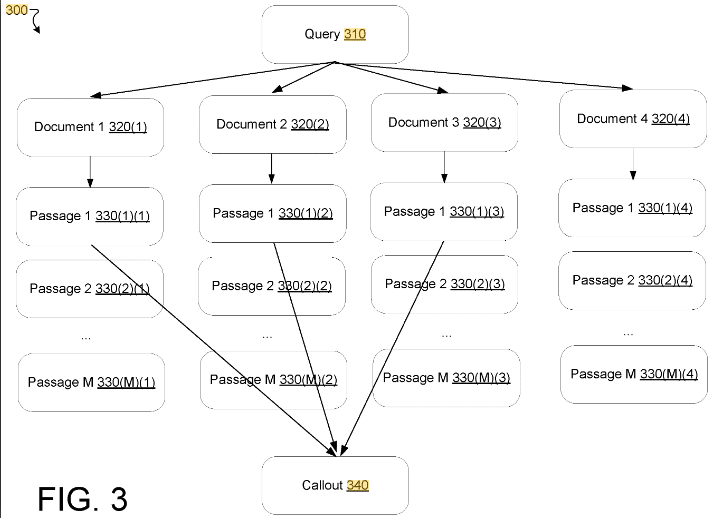
- Empfangen von Abfragedaten: Der Prozess beginnt damit, dass die Suchmaschine die Suchabfrage eines Benutzers empfängt.
- Generieren von Suchergebnissen: Es werden mehrere Suchergebnisse generiert, die jeweils eine Passage enthalten, die sich auf die Suchanfrage bezieht.
- Auswählen von Passagen: Es wird eine Reihe von Passagen ausgewählt, darunter eine Kandidatenpassage aus einem Suchergebnis mit dem höchsten Rang und zusätzliche Kontextpassagen aus anderen Ergebnissen.
- Bewertung der Kandidatenpassage: Die Kandidatenpassage wird anhand der Kontextpassagen bewertet, um eine Genauigkeitsbewertung zu erhalten.
- Anzeigeentscheidung: Basierend auf der Genauigkeitsbewertung wird die Kandidatenpassage entweder als Kurzantwort in den Suchergebnissen angezeigt oder nicht.
Faktoren
- Genauigkeitsbewertung: Die Entscheidung, eine kurze Antwort anzuzeigen, hängt von der Genauigkeitsbewertung ab, die mit einem vorgegebenen Schwellenwert verglichen wird.
- Konsens mit Kontextpassagen: Der Genauigkeitswert wird aus dem Grad der Übereinstimmung zwischen der Kandidatenpassage und den Kontextpassagen abgeleitet.
- Qualität der Kurzantwort: Die Qualität und Zuverlässigkeit der Kurzantwort werden durch diesen Multi-Source-Ansatz verbessert.
Implikationen für SEO
Für SEO deutet dieses Patent auf eine Verlagerung hin zu Inhalten hin, die nicht nur relevant, sondern auch kontextuell korrekt und konsensorientiert sind. SEO-Strategien müssen sich möglicherweise mehr auf die Bereitstellung umfassender, abgerundeter Inhalte konzentrieren, die mit dem breiteren Kontext eines Themas übereinstimmen, anstatt nur auf Schlüsselwörter oder Phrasen mit dem höchsten Rang abzuzielen. Dies könnte dazu führen, dass der Schwerpunkt stärker auf gründlicher Recherche, vielfältigen Inhaltsperspektiven und der Genauigkeit der auf Webseiten präsentierten Informationen liegt.
Wie man SEO grundlegend lernt und welche Bedeutung Patente für SEO haben
Viele SEOs stürzen sich daher direkt in die Umsetzung der Optimierung, weil sie sich Ideen aus Blogs, Social Media, YouTube… von SEO-Hacks holen, ohne die theoretischen Grundlagen zu kennen.
Deshalb empfehle ich jedem, der sich mit SEO beschäftigt, sich zunächst mit den Grundlagen des Crawlings, der Indexierung und des Information Retrievals vertraut zu machen.
Der nächste Schritt besteht darin, die Grundlagen moderner Suchmaschinentechnologien wie die Verarbeitung und Einbettung natürlicher Sprache zu verstehen.
Wir wollen für technische Systeme optimieren, uns aber nicht mit der Technik auseinandersetzen?
Das ergibt für mich keinen Sinn.
Ich empfehle jedem, der es mit SEO ernst meint, folgende Punkte zu beachten:
- Verstehen Sie moderne Suchmaschinentechnologie
- Grundlagen Information Retrieval
- Grundlagen der semantischen Suche / Entitäten
- Grundlagen der Verarbeitung natürlicher Sprache
- Grundlagen Embeddings
- Sammeln Sie Erfahrungen mit Projekten
Die bloße Suche nach praktischen Erfahrungen, ohne die wissenschaftlichen Grundlagen zu kennen und die Technik zu verstehen, führt oft dazu, die Dinge sehr subjektiv zu betrachten. Die Kenntnis der Technologie und der wissenschaftlichen Grundlagen ist wie eine rationale Ebene, die als Gegenkontrolle zu unseren subjektiven Theorien fungiert. So sind Sie besser davor geschützt, jedem Hype zu folgen.
Die Google-Sprecher im Kontext der Suche sind nur teilweise sichtbar, insbesondere wenn es um das Ranking der Suchergebnisse geht. Die Informationen sind oft ungenau und unklar. Dies ist verständlich, da Google eine Manipulation der Suchergebnisse verhindern möchte.
Wir brauchen also andere Informationsquellen, die uns tiefere Einblicke ermöglichen. Die Patentforschung ist fortgeschritten. Als Anfänger sollten Sie sich zunächst auf die oben genannten Schritte konzentrieren.
Dann können Sie mit der Patentrecherche fortfahren. Sie müssen die Grundlagen verstehen, wenn Sie Google-Patente verstehen wollen.
Unabhängig davon, ob ein Patent in die Praxis umgesetzt wird, ist es sinnvoll, sich mit Google-Patenten zu befassen, da Sie so ein Gefühl für die Probleme und Herausforderungen bekommen, mit denen Produktentwickler bei Google konfrontiert sind.
Ausführlichere Zusammenfassungen der Google-Patente finden Sie in meinem Blog. Ich füge fast jede Woche neue Patente hinzu. https://www.kopp-online-marketing.com/interesting-google-patents

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023
























