
In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Language Processing im Data Mining für semantischen Datenbanken ein. Der Beitrag ist interessant für SEOs, Lehrende und Journalisten, die sich mit dem Thema Suchmaschinen-Technologie beschäftigen wollen.
Inhaltsverzeichnis
- 1 Was ist semantische Suche?
- 2 Warum ist eine semantische Suche so erstrebenswert für Google?
- 3 Googles Schritte und Innovationen zur semantischen Suchmaschine
- 4 Infografik „Googles Weg zur semantischen Suchmaschine“ zum Download
- 5 Semantische Datenbanken bzw. Entitäten-Index in Graphen-Form
- 6 Durch Vektorraumanalysen und Machine Learning zum besseren semantischen Verständnis
- 7 Funktionalität und Einsatzgebiete von Natural Language Processing in modernen Suchmaschinen
- 8 Natural Language Processing zum Aufbau einer semantischen Wissensdatenbank
- 9 Sprachmodelle als Alternative zum klassischen Suche-Index und Knowledge Graph
- 10 Mehr Publikation zur semantischen Suche
Was ist semantische Suche?
Eine semantische Suchmaschine berücksichtigt den Kontext einer Suchanfrage, um die Bedeutung des Suchterms besser zu verstehen. Im Gegensatz zu rein Keyword basierten Such-Systemen soll in der semantischen Suche die Bedeutung bzw. Suchintention der Suchanfrage und von die Bedeutung von Dokumenten besser interpretiert werden. Während Keyword basierte Suchmaschinen auf Grundlage eines Keyword-Text-Abgleich funktionieren, berücksichtigen semantische Suchmaschinen auch die Beziehungen zwischen Entitäten für die Ausgabe von Suchergebnissen. Mehr zum Thema >>> Semantische Suche: Suchmaschinen, Definition, Funktion, Geschichte
Warum ist eine semantische Suche so erstrebenswert für Google?
Durch Googles große Neueinführungen bezüglich der Suche zieht sich ein roter Faden, der ein klares Ziel erkennen lässt. Das vollständige Verständnis aller Inhalte im Netz und eindeutigen Interpretation von Suchanfragen. Um die wirkliche Bedeutung von Suchanfragen und Interpretation von Inhalten zu erkennen muss Google
- Suchanfragen und deren Suchintention klar identifizieren
- Entitäten in Suchanfragen und Inhalten identifizieren und den Index um diese herum organisieren
Um diese beiden Ziele zu erreichen benötigt Google leistungsstarke Systeme und Algorithmen, die das komplette Wissen der Welt der erschließen und deuten.
Googles Schritte und Innovationen zur semantischen Suchmaschine
Dieses Ziel verfolgt Google seit dem Kauf der semantischen Datenbank Freebase, der Einführung des Knowledge Graph als semantische Datenbank im Jahr 2012 und der Einführung der neuesten Ranking-Algorithmus-Basis Hummingbird im Jahr 2013 konsequent. Die Erschließung des weltweiten Wissens bedarf eines Index, der als Graph aufgebaut ist. Während Google vor 2012 auf einen Index ähnlich einer tabellarischen Datenbank zugegriffen hat, in den Informationen ähnlich einem Verzeichnis gespeichert wurden kann ein Graphen-Index Beziehungen zwischen Informationen und Entitäten erfassen und abbilden.
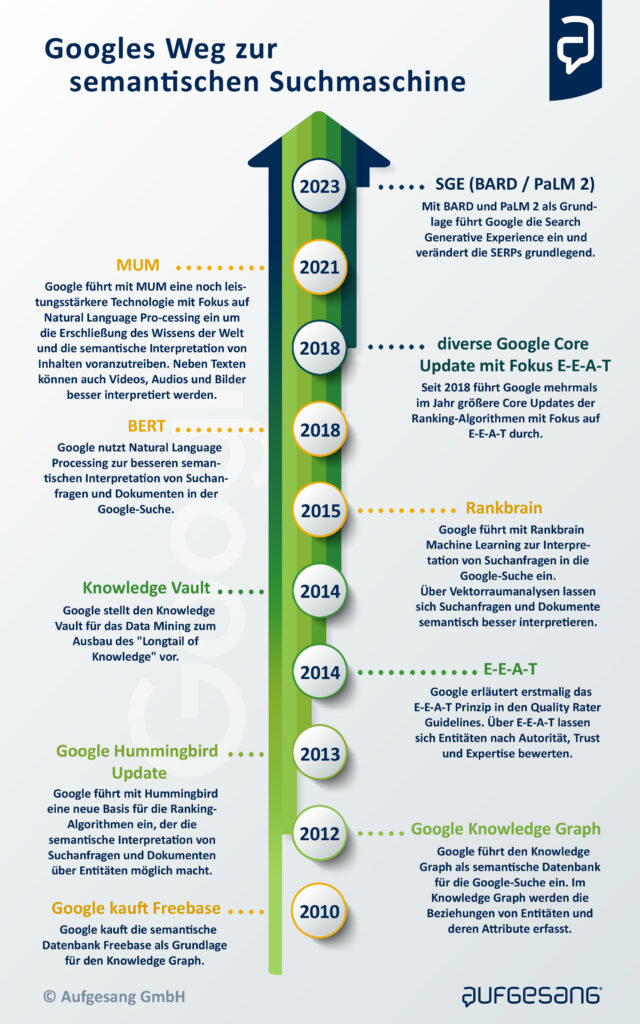
Hier eine Aufstellung der bedeutensten Innovationen, die Google seit 2010 auf dem Weg zur semantischen Suchmaschine eingeführt hat:
- 2010: Google kauft Freebase, eine vom Unternehmen Metaweb erstellte semantische Datenbank mit strukturierten maschinenlesbaren Daten zu Entitäten. Die erste Version den Knowledge Graph wurde durch Daten aus Freebase gespeist. 2014 wurde Freebase in das Projekt Wikidata übertragen. Von den ursprünglich ca. 10 Millionen Datensätzen aus Freebase wurde aber nur ein Teil übertragen. Mein eigener Datensatz zur Entität „olaf kopp„, den ich 2012 bei Freebase angelegt habe wurde z.B. nicht in Wikidata übernommen. Ich habe ihn händisch dort nachgepflegt. Dennoch werden meine Daten aus der ehemaligen Freebase-Datenbank immer noch in Form eines Knowledge Panels ausgegeben und durch weitere Informationen erweitert.

- 2012: Google führt den Knowledge Graph in Form der Knowledge Panels und Knowledge Cards in die Suche ein. Ein Knowledge Graph ist eine Wissens-Datenbank, in der Informationen so strukturierte aufgearbeitet sind, dass aus den Informationen Wissen entsteht. Ein einem Knowledge Graph werden Entitäten (Knoten) über Kanten in Beziehung zueinander gestellt, mit Attributen versehen und in thematischen Kontext bzw. Ontologien gebracht. Dazu weiter unten in diesem Beitrag mehr oder hier >>> Google Knowledge Graph einfach erklärt
- 2013: Google stellt das Hummigbird-Update als neue Generation der Ranking-Algorithmen vor. Die Einführung von Hummingbird zum 15. Geburtstag von Google im Jahr 2013 war der endgültige Startschuss der semantischen Suche für Google. Google selbst hat dieses Algorithmus-Update als das bedeutenste seit dem Caffeine Update im Jahr 2010 bezeichnet. Es soll zur Einführung ca. 90% aller Suchanfragen betroffen haben und war im Vergleich zu Caffeine ein echtes Algorithmus-Update. Es soll dabei helfen komplexere Suchanfragen besser zu deuten und noch besser die eigentliche Suchintention bzw. Fragestellung hinter einer Suchanfrage zu erkennen sowie passende Dokumente dazu anzubieten. Auch auf Dokumentenebene soll die eigentliche Intention hinter dem Content besser mit der Suchanfrage gematcht werden. Mehr dazu >>> Was ist Google Hummingbird?
- 2014: Google stellt den Knowledge Vault vor. Ein System zur Identifikation und Extraktion von Tail-Entitäten, um den Ausbau des „Long Tail of Knowledge“ voranzutreiben. Über den Knowledge Vault ist es Google möglich, Data Mining aus unstrukturierten Quellen automatisiert zu betreiben und könnte die Grundlage für die nachfolgenden Innovationen in Sachen Natural Language Processing sein.
- 2014: Google führt E-A-T zur Bewertung von Websites in den Quality Rater Guidelines ein. Auf den ersten Blick ist die Brücke zur semantischen Suche nicht zu ziehen. Indirekt bietet das Entitäten-Konzept und Graphen-Konstrukt von semantischen Datenbanken aber eine ideale Grundlage für eine themenbezogen qualitative Bewertung von Entitäten (Publisher & Autoren) und deren Content hinsichtlich Expertise, Autorität und Trust. Ein Entitäten basierter Index macht es möglich Entitäten wie Autoren, Publisher, Marken, Domains … Ganzheitlich zu betrachten. Das gelingt nicht wenn man nur einzelne URLs, Bilder … betrachtet, wie die klassischen Google Indizes es tun. Mehr zu E-A-T >>>> E-A-T (Expertise, Autorität, Trust) erklärt Mehr zu den Google Quality Rater Guidelines >>> Die Google Quality Rater Guidelines & wichtigsten Erkenntnisse für SEO
- 2015: Google führt mit Rankbrain offiziell Machine Learning in die Google-Suche ein. Über Vektorraumanalysen will die Suchmaschine Suchanfragen und generell Begrifflichkeiten besser in eine Beziehung, thematische Nähe bzw. einen Kontext verorten. Dadurch können u.a. Suchanfragen hinsichtlich der Suchintention besser interpretiert werden.
- 2018: Google stellt BERT als neue Technologie für die bessere Interpretation von Suchanfragen und Texten vor. BERT nutzt Natural Language Processing um Suchanfragen, Sätze, Fragen, Textabschnitte und generell Content besser semantisch zu verstehen. Mehr zum Thema Natural Language Processing nachfolgend in diesem Beitrag oder hier >>> Natural Language Processing(NLP) einfach erklärt
- 2021: Google stellt MUM als neue Technologie für das bessere semantische Verständnis von Suchanfragen, Fragen, Content in verschiedenen Formen (Text, Video, Audio, Bild) und dem der Erschließung des „Wissens der Welt“ vor. Mit MUM kann Google die semantische(n) Datenbank(en) wie dem Knowledge Graph noch schneller und umfänglicher mit Informationen zu Entitäten erweitern.
- 2023: Unter dem öffentlichen Druck durch die Einführung von ChatGPT und die Einführung von KI-basierten Chatbot-Funktionalitäten bei Bing stellt Google BARD, das Sprachmodell PaLM 2 und eine Beta-Version der neuen Google-Suche SGE vor. Die Google-Suche entwickelt sich von einer Suchmaschine zu einer Antwortmaschine mit KI-generierten Antworten.
Nachfolgend das Ganze noch mal als Infografik zur freien Verwendung für z.B. Social Media.
Infografik „Googles Weg zur semantischen Suchmaschine“ zum Download
Semantische Datenbanken bzw. Entitäten-Index in Graphen-Form
Die Entitäten in einer semantischen Datenbank wie dem Knowledge Graph sind als Knoten erfasst und die Beziehungen werden als Kanten abgebildet. Die Entitäten können mit Labels zu z.B. zu Entitäts-Typen-Klassen, Attributen und Informationen zu in Beziehung zur Entität stehenden Inhalten und digitalen Abbildern wie z.B. Websites, Autorenprofilen oder Profilen in sozialen Netzwerken ergänzt werden.
Nachfolgend zur Verdeutlichung ein konkretes Beispiel von Entitäten, die in Beziehung zueinanderstehen. Die Haupt-Entitäten sind Taylor Swift und ihr Freund Joe Alwyn und weitere Entitäten sind die Eltern, Geschwister und Songs mit denen sie in semantischer Verbindung stehen.
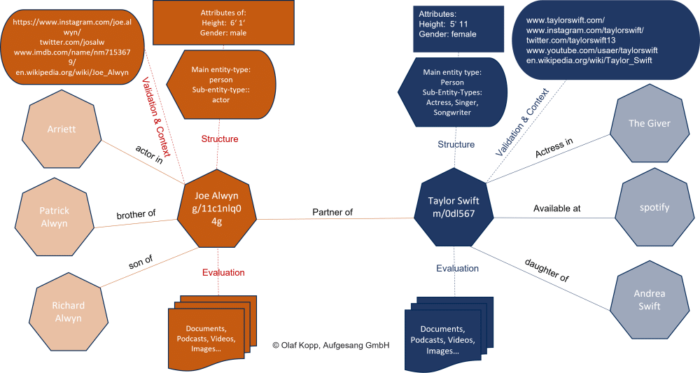
Beispiel. Beziehungen zwischen Entitäten in einem Knowledge Graph, ©Olaf Kopp
Entitäten sind nicht nur eine Aneinanderreihung von Buchstaben sondern sind Dinge mit einer eindeutig identifizierbaren Bedeutung. Der Suchterm „jaguar“ hat mehrere Bedeutungen. So kann die Automarke gemeint sein, das Tier oder der Panzer. Die reine Verwendung der Zeichenkette in Suchanfragen und/oder Inhalten reicht nicht aus um den Kontext zu verstehen. In Kombination mit anderen Attributen bzw. Entitäten wie Rover, Coventry, PS, Auto … wird die eindeutige Bedeutung klar, durch den Kontext in dem die Entität sich bewegt. Die Bedeutung von Entitäten lässt sich über den Kontext ermitteln in denen sie in Inhalten und Suchanfragen genannt bzw. benutzt werden.
Durch Vektorraumanalysen und Machine Learning zum besseren semantischen Verständnis
Durch Vektorraumanalysen lassen sich Suchanfragen und Inhalte in einen thematischen Kontext bringen. Man kann Entitäten, Inhalte oder Suchanfragen in einem Vektorraum verorten. Der Abstand der unterschiedlichen Begriffe zueinander gibt Auskunft über den thematischen Kontext in dem die Vektoren genutzt werden. Über diesen Weg lassen sich thematische Ontologien bzw. Kategorien ermitteln in dem Keywords bzw. Entitäten zu verorten sind.
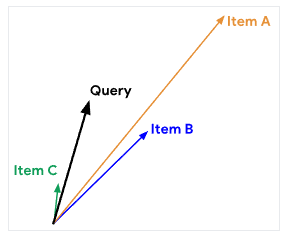
Die Methodik Wörter als Vektoren maschinenlesbar zu transformieren (Word2Vec) hat Google 2015 mit Rankbrain offziell eingeführt, um insbesondere Suchanfragen besser zu verstehen. Rankbrain wurde als Innovation für das sogenannte Query Processing, also der Vorgang zur Interpretation von Suchanfragen, vorgestellt. Mit Rankbrain wurde auch das erste mal seitens Google bestätigt, dass Machine-Learning für die Google-Suche zum Einsatz kommt.
Funktionalität und Einsatzgebiete von Natural Language Processing in modernen Suchmaschinen
Mit der Einführung von BERT im Jahr 2018 gab es die offizielle Bestätigung von Google, dass sie Natural Language Processing für die Google-Suche nutzen. Beim Natural Language Processing als Teilbereich von Machine Learning geht es darum menschliche Sprache in geschriebener und gesprochener Form besser zu verstehen und unstrukturierte Informationen in maschinen lesbare strukturierte Daten umzuwandeln. Teilaufgaben von NLP sind Übersetzung von Sprachen und die Beantwortung von Fragen. Hier wird schnell klar wie wichtig diese Technologie für moderne Suchmaschinen wie Google ist.
Generell kann man die Funktionsweise von NLP grob in die folgendenden Prozessschritte aufgliedern:
- Datenbereitstellung
- Datenvorbereitung
- Textanalyse
- Textanreicherung
Die Kernkomponenten von NLP sind Tokenization zu deutsch Tokenisierung, Kennzeichnung von Wörtern nach Wortarten (Part of Speech Tagging), Lemmatisierung, Wort-Abhängigkeiten (Dependency Parsing), Parse Labeling, Extraktion von benannten Entitäten (Named Entity Recognition), Salience-Scoring, Sentiment-Analysen, Kategorisierung, Text-Klassifizierung, Extrahierung von Content-Typen und Identifikation einer impliziten Bedeutung aufgrund der Struktur.
- Tokenisierung: Tokenisierung ist der Vorgang, bei dem ein Satz in verschiedene Begriffe unterteilt wird.
- Kennzeichnung von Wörtern nach Wortarten: Wortartenkennzeichnung klassifiziert Wörter nach Wortarten wie z.B. Subjekt, Objekt, Prädikat, Adjektiv …
- Wortabhängigkeiten: Wortabhängigkeiten schafft Beziehungen zwischen den Wörtern basierend auf Grammatikregeln. Dieser Prozess bildet auch „Sprünge“ zwischen Wörtern ab.
- Lemmatisierung: Die Lemmatisierung bestimmt, ob ein Wort verschiedene Formen hat und normalisiert Abwandlungen zur Grundform,. Zum Beispiel ist die Grundform von Tiere, Tier oder von verspielt, Spiel.
- Parsing Labels: Die Kennzeichnung klassifiziert die Abhängigkeit oder die Art der Beziehung zwischen zwei Wörtern, die über eine Abhängigkeit verbunden sind.
- Analyse und Extraktion von benannten Entitäten: Dieser Aspekt sollte uns aus den vorangegangenen Beiträgen bekannt sein. Damit wird versucht, Wörter mit einer „bekannten“ Bedeutung zu identifizieren und Klassen von Entitätstypen zuzuordnen. Im Allgemeinen sind benannte Entitäten Menschen, Orte und Dinge (Substantive). Entitäten können auch Produktnamen enthalten. Dies sind im Allgemeinen die Wörter, die ein Knowledge Panel auslösen. Aber auch Begriffe, die kein eigenes Knowledge Panel auslösen können Entität sein.
Beispiel einer Syntax-Analyse aus der NLP-API-Demo, Quelle: Google
Über Natural Language Processing können in Suchanfragen, Sätze und Textabschnitten Entitäten identifiziert sowie die einzelnen Bestandteile in sogenannte Tokens zerlegt werden und in Beziehung zueinander gesetzt werden. Auch ein grammatikalisches Verständnis kann durch NLP algorithmisch entwickelt werden.
Mit der Einführung von Natural Language Processing ist Google auch in der Lage mehr als nur die Substantive für die Interpretation von Suchanfragen, Texten und Sprache zu deuten. So sind seit BERT auch Verben, Adverbien, Adjektive für die Ermittlung des Kontext wichtig. Durch die Identifikation der Beziehungen zwischen den Tokens lassen sich Bezüge herstellen und so können auch Personalpronomen gedeutet werden.
Ein Beispiel:
„Olaf Kopp ist Head of SEO bei Aufgesang. Er beschäftigt sich seit 2005 mit Online-Marketing.“
In der Zeit vor Natural Language Processing konnte Google mit dem Personalpronomen „er“ nichts anfangen, da kein Bezug zur Entität „Olaf Kopp“ hergestellt werden konnte. Für die Indexierung und Ranking wurden nur die Begriffe Olaf Kopp, Head of SEO, Aufgesang, 2005 und Online Marketing berücksichtigt.
Über Natural Language Processing lassen sich nicht nur Entitäten in Suchanfragen und Inhalten identifizieren, sondern auch die Beziehung dieser zueinander.
Dabei wird die grammatikalische Satzstruktur, als auch Bezüge innerhalb von ganzen Absätzen und Texten berücksichtigt. Nomen bzw. Subjekt und Objekt in einem Satz können als potentielle Entitäten identifiziert werden. Über Verben lassen sich Beziehungen zwischen Entitäten herstellen. Durch Adjektive ein Sentiment (Stimmung) um eine Entität ermitteln.
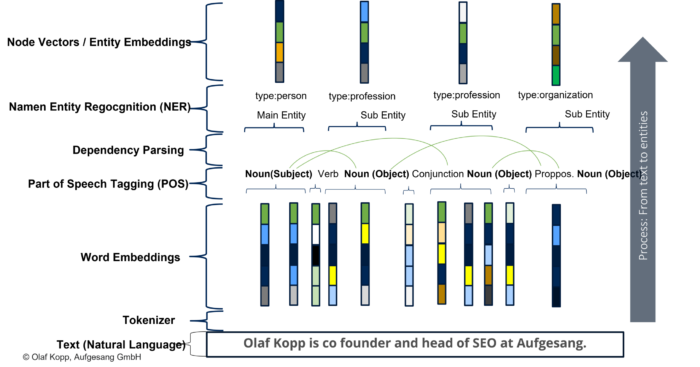
Natural Language Processing über Vektoren
Über Natural Language Processing lassen sich auch konkrete W-Fragen besser beantworten, was für die Bedienung von Voice Search eine deutliche Weiterentwicklung darstellt.
Auch für das von Google 2021 eingeführte Passage Ranking spielt Natural Language Processing eine zentrale Rolle.
Seit der Einführung von BERT im Jahr 2018 nutzt Google diese Technologie in der Google-Suche. Das 2021 eingeführt Passage-Ranking basiert auf Natural Language Processing, da Google hier einzelne Textpassagen durch die neuen Möglichkeiten besser interpretieren kann.
Natural Language Processing zum Aufbau einer semantischen Wissensdatenbank
Während bis dato Google von manuell gepflegten strukturieren und semistrukturierten Informationen bzw. Datenbanken abhängig war ist es seit BERT möglich Entitäten und deren Beziehungen aus unstrukturierten Datenquellen zu extrahieren und in einem Graphen-Index zu speichern. Ein Quanten-Sprung in Sachen Data-Mining.
Dafür kann Google die bereits verifizierten Daten aus (semi-)strukturierten Datenbanken wie dem Knowledge Graph, Wikipedia … als Trainingsdaten nutzen, um zu lernen unstrukturierte Informationen zu bestehenden Modellen bzw. Klassen zuzuordnen und neue Muster zu erkennen. Hier spielt Natural Language Processing in Form von BERT und MUM die entscheidende Rolle.
Bereits 2013 hat Google erkannt, dass der Aufbau einer semantischen Datenbank wie dem Knowledge Graph ausschließlich basierend auf strukturiertem Daten zu langsam und nicht skalierbar möglich ist, da die große Masse an sogenannten Long-Tail-Entitäten nicht in (semi-)strukturierten Datenbanken erfasst sind. Zur Erfassung dieser Longtail-Entitäten bzw. des vollständigen Wissens der Welt stellt Google 2013 den Knowledge Vault vor, der aber seitdem nicht mehr groß Erwähnung fand. Der Ansatz über eine Technologie das komplette im Internet verfügbare Wissen für eine semantische Datenbank zu nutzen wird durch Natural Language Processing Realität. Es ist davon auszugehen, dass es neben dem Knowledge Graph eine Art Zwischenpeicher gibt in dem Google das über Natural Language Processing generierte Wissen zu erfassen und zu strukturieren bzw. organisieren. Sobald ein Validitäts-Schwellenwert erreicht werden die Entitäten und Informationen in den Knowledge Graph überführt. Dieser Zwischenspeicher könnte der Knowledge Vault sein.
Übersicht Data Mining für den Google Knowledge Graph, ©Olaf Kopp
Dadurch lässt sich auch erklären warum der Knowledge Graph gerade in den letzten Jahren sehr schnell gewachsen ist.
By mid-2016, Google reported that it held 70 billion facts and answered „roughly one-third“ of the 100 billion monthly searches they handled. By March 2023, this had grown to 800 billion facts on 8 billion entities.”, Quelle: https://en.wikipedia.org/wiki/Google_Knowledge_Graph
Sprachmodelle als Alternative zum klassischen Suche-Index und Knowledge Graph
Der Aufstieg der Sprachmodelle kann für die Google-Suche einen fundamentalen Shift von klassischen Indizes zu Sprachmodellen führen, wie in der wissenschaftlichen Arbeit „Rethinking Search: Making Domain Experts out of Dilettantes“ vorgestellt. Der klassische Retrieve-and-Rank-Prozess wird verkürzt bzw. über Sprachmodelle durchgeführt. Entitäten, Inhalte, Textpassagen … können als Embeddings in einer Vektor-Datenbank gespeichert werden. Einzelne Tasks können neben einem generellen Sprachmodell in feinjustierten Sprachmodellen abgewickelt werden.
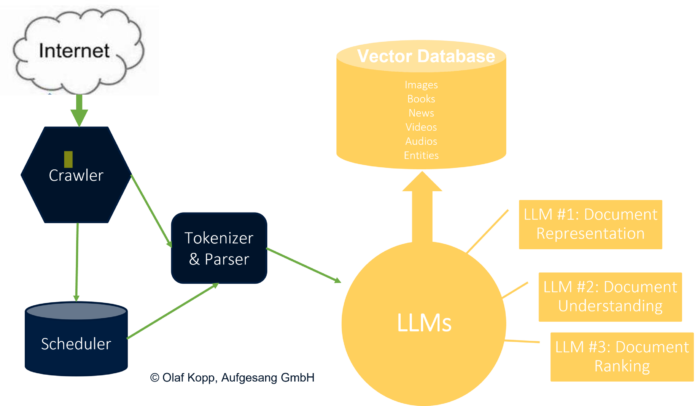
Das kann auch Auswirkungen auf die weitere Verwendung des Knowledge Graph als Entitäten-Speicher haben. Obwohl Sprachmodelle keine Wissensdatenbanken sind können sich zukünftige leistungsstärkere Sprachmodelle einem echten semantischen Verständnis und Wissen annähern. Knowledge Graphen könnten weiterhin beim Finetuning und Faktencheck unterstützen um semantische Beziehungen besser zu verstehen und das Risiko der Halluzinationen mindern.
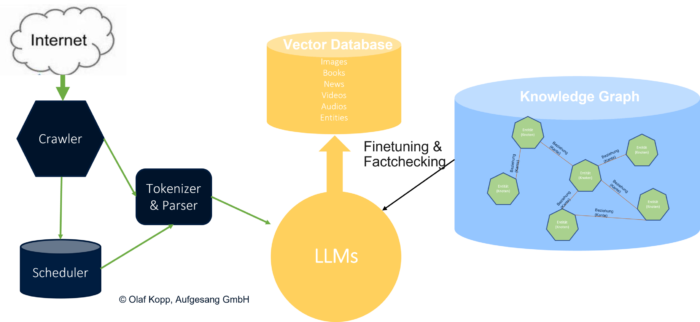
Knowledge Graph im Zusammenspiel mit LLM
Mehr Publikation zur semantischen Suche
Mehr zur semantischen Suche bei Google in diesem Video:
-

- Semantische Suche: Suchmaschinen, Definition, Funktion, Geschichte
- Google MUM Update: Was erwartet SEOs in der Zukunft?
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.