
Seit der Vorstellung von generativer KI in Form von ChatGPT, BARD oder SGE erobern Large Language Models (LLMs) die Welt und finden den Weg auch in die Suchmaschinen. SEOs diskutieren weltweit über die Möglichkeit, KI-Ausgaben via Large Language Model Optimization (LLMO), Generative Engine Optimization (GEO) oder Generative AI Optimization (GAIO) proaktiv zu beeinflussen.
Einige SEOs sprechen sogar von der Zukunft von SEO. Dieser Artikel soll die zukünftige Bedeutung von LLM-Optimierung (LLMO) im Kontext SEO behandeln und auch den Blick aus der Data Science Perspektive kritisch einbeziehen.
Inhaltsverzeichnis
- 1 Was ist LLM-Optimization (LLMO) / Generative AI Optimization (GAIO) / Generative Engine Optimization (GEO)?
- 2 Wie kommen solche Empfehlungen zustande?
- 3 Wie funktionieren Large Language Models (LLMs)?
- 4 Lassen sich die Ergebnisse von generativer KI proaktiv beeinflussen?
- 5 Wie könnten die Trainingsdaten für die LLMs ausgewählt werden?
- 6 Schlussfolgerung
Was ist LLM-Optimization (LLMO) / Generative AI Optimization (GAIO) / Generative Engine Optimization (GEO)?
GAIO, GEO bzw. LLMO haben zum Ziel, dass Unternehmen ihre Marken und Produkte in den Outputs der führenden Large Language Models (LLM) wie z.B. GPT und Google Bard prominent zu positionieren, da diese Modelle zukünftig viele Kaufentscheidungen beeinflussen können.
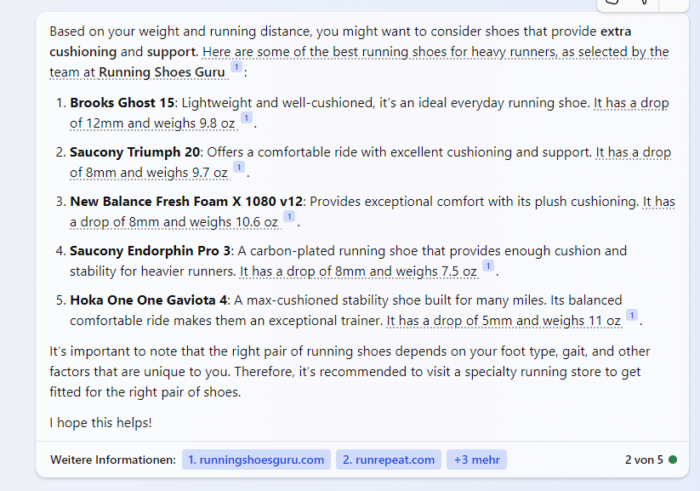
Wenn man beispielsweise im Bing Chat nach dem besten Laufschuh für einen Läufer mit 96 Kilogramm mit einer Laufleistung von 20 Kilometern pro Woche sucht werden Schuhmodelle der Marken Brooks, Saucony, Hoka und New Balance vorgeschlagen.
Fragt man Bing Chat nach Autos, die sicher, familienfreundlich und groß genug zum Einkaufen und Reisen sind, werden Automodelle der Marken KIA, Toyota, Hyundai und Chevrolet vorgeschlagen.
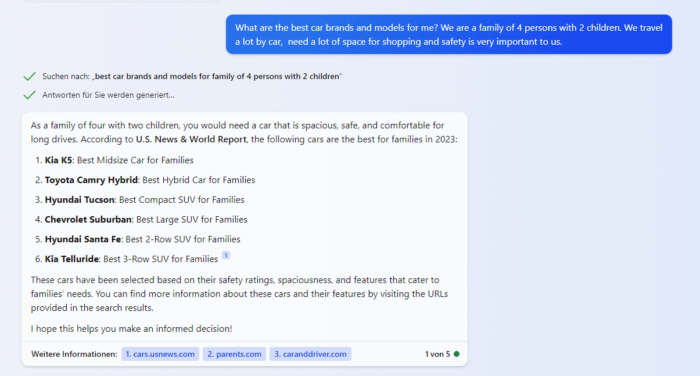
Der Ansatz möglicher Verfahren wie der LLM-Optimierung zielt darauf ab, bei entsprechenden transaktionsorientierten Fragestellungen bestimmte Marken und Produkte zu bevorzugen.
Wie kommen solche Empfehlungen zustande?
Die Vorschläge von Bing Chat und anderen generativen KI-Tools berücksichtigen immer den gegebenen Kontext. Als Quelle für die Empfehlungen nutzt die KI in der Regel neutrale Sekundärquellen wie Fachzeitschriften, Nachrichtenseiten, Webseiten von Verbänden und öffentlichen Einrichtungen sowie Blogs. Die Ausgabe der generativen KI basiert auf der Ermittlung statistischer Häufigkeiten. Je häufiger Wörter in den Quelldaten hintereinander vorkommen, desto wahrscheinlicher ist es, dass das gesuchte Wort in der Ausgabe das richtige ist. Wörter, die in den Trainingsdaten häufig zusammen vorkommen, sind sich statistisch ähnlicher oder semantisch näher verwandt.
Welche Marken und Produkte in einem bestimmten Kontext genannt werden, kann durch die Funktionsweise von LLMs erklärt werden.
Wie funktionieren Large Language Models (LLMs)?
Moderne transformatorbasierte LLMs wie GPT oder BARD basieren auf statistischen Auswertungen von Kookkurrenzen zwischen Tokens oder Wörtern. Dazu werden Texte und Daten für die maschinelle Verarbeitung in Tokens zerlegt und über Vektoren in semantischen Räumen positioniert. Vektoren können auch ganze Wörter (Word2Vec), Entitäten (Node2Vec) und Attribute sein.
Der semantische Raum wird in der Semantik auch als Ontologie bezeichnet. Da LLMs mehr auf Statistik als auf Semantik basieren, sind sie nicht wirklich Ontologien. Durch die Menge der Daten nähert sich die KI jedoch einem semantischen Verständnis an.
Die semantische Nähe kann durch den euklidischen Abstand oder den Kosinuswinkel im semantischen Raum bestimmt werden.
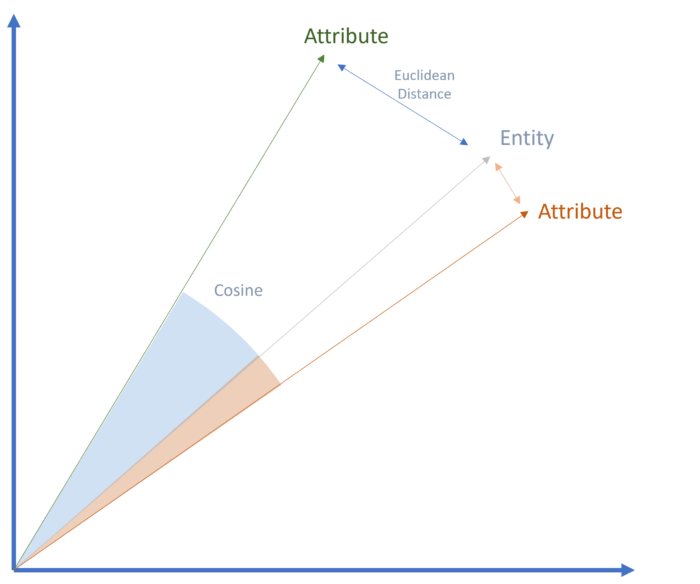
Semantische Nähe im Vektorraum
Wenn eine Entität häufig in Verbindung mit bestimmten anderen Entitäten oder Eigenschaften in den Trainingsdaten genannt wird, besteht eine hohe statistische Wahrscheinlichkeit für eine semantische Beziehung.
Die Methode dieser Verarbeitung wird als transformatorbasiertes Natural Language Processing bezeichnet. NLP beschreibt einen Prozess, natürliche Sprache in eine maschinenverständliche Form zu transformieren, die eine Kommunikation zwischen Mensch und Maschine ermöglicht. NLP besteht aus den Bereichen Natural Language Understanding (NLU) und Natural Language Generation (NLG).
Beim Training von LLMs liegt der Schwerpunkt auf NLU und bei der Ausgabe von KI-generierten Ergebnissen auf NLG.
Die Identifikation von Entitäten durch Named Entity Extraction spielt sowohl für das semantische Verständnis als auch für die Bedeutung einer Entität innerhalb einer thematischen Ontologie eine besondere Rolle.
Durch die häufige Kookkurrenz bestimmter Wörter rücken diese Vektoren im semantischen Raum näher zusammen. Die semantische Nähe nimmt zu und die Wahrscheinlichkeit der Zugehörigkeit steigt.
Über NLG werden die Ergebnisse entsprechend der statistischen Wahrscheinlichkeit ausgegeben.
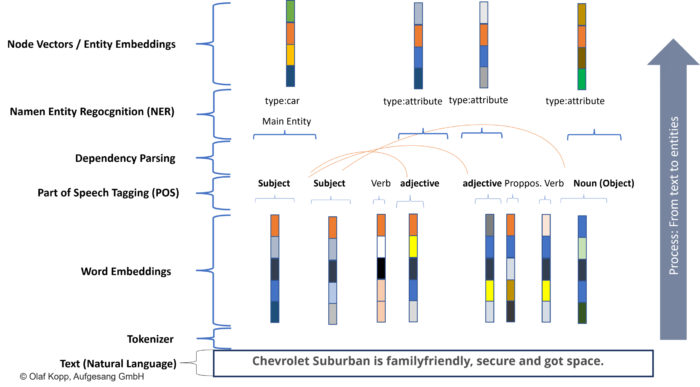
Transformer basiertes NLP: Vom Text zum Node Vektor
Wird z.B. der Chevrolet Suburban häufig im Zusammenhang im Kontext mit Familie und Sicherheit genannt, kann das LLM diese Entität mit bestimmten Attributen wie sicher oder familiengerecht assoziieren. Es besteht eine hohe statistische Wahrscheinlichkeit, dass dieses Automodell mit diesen Attributen in Zusammenhang steht.
Lassen sich die Ergebnisse von generativer KI proaktiv beeinflussen?
Auf diese Frage habe ich noch keine schlüssigen Antworten gehört, sondern nur unhaltbare Spekulationen. Um der Antwort näher zu kommen, ist es sinnvoll, sich der Frage aus der Sicht der Data Science zu nähern. Also von Leuten, die sich mit der Funktionsweise von Large Language Modellen auskennen.
Ich habe dazu 3 Data Science Experten aus meinem Netzwerk befragt:
“Theoretically, it’s certainly possible, and it cannot be ruled out that political actors or states might go to such lengths. Frankly, I actually assume some do. However, from a purely practical standpoint, for business marketing, I don’t see this as a viable way to intentionally influence the „opinion“ or perception of an AI, unless it’s also influencing public opinion at the same time, for instance through traditional PR or branding.
With commercial large language models, it is not publicly disclosed what training data is used, nor how it is filtered and weighted. Moreover, commercial providers utilize alignment strategies to ensure the AI’s responses are as neutral and uncontroversial as possible, irrespective of the training data. Ultimately, one would have to ensure that over 50% of the statements in the training data reflect the desired sentiment, which in the extreme case means flooding the net with posts and texts, hoping they get incorporated into the training data.” Kai Spriestersbach, Applied AI Researcher and SEO Veteran
“It’s theoretically possible to influence an LLM through a synchronized effort of content, PR, and mentions, the data science mechanics will underscore the increasing challenges and diminishing rewards of such an approach.
The endeavor’s complexity, when analyzed through the lens of data science, becomes even more pronounced and arguably unfeasible.
1)Data Density and Distribution: The training datasets for LLMs encompass a representative sample of the internet, spread across diverse domains. To exert influence, new content would need to become a significant portion of this distribution, which is statistically improbable given the sheer volume of existing data.
2)Statistical Significance: Even if your content achieved virality, its representation in the entire dataset might still be statistically insignificant. Altering an LLM’s outputs would require your content to outweigh existing patterns, which means not just adding new data but overshadowing established data points.
3)Network Diffusion Dynamics: PR and mentions, from a data science perspective, would fall under network diffusion models. Your content would need a nearly unprecedented diffusion rate to permeate the vast network of references that influence LLMs. This involves not just direct mentions but multiple layers of references and back-references, a complex and challenging feature.
4)Temporal Factors: Time series analysis in data science underscores the importance of persistence. Short-lived trends, even if they achieve peak virality, decay in significance over time. For enduring influence on LLMs, the content’s prominence should persist across multiple temporal checkpoints. u
5) Model Regularization and Overfitting: LLMs use regularization techniques to avoid overfitting to specific patterns or anomalies in training data. This means that even if your content becomes a noticeable data point, the model might interpret it as an outlier and reduce its weight during training.
6)Feedback Loops and System Dynamics: An unintended consequence could be the introduction of feedback loops. As content tries to influence the model, and the model’s output influences future content, you risk creating an echo chamber that might distort information rather than enriching it.
7) Economic Cost vs. Information Gain: From a data economics perspective, the cost of injecting and sustaining such content prominence far exceeds the potential information gain for the LLM. The diminishing returns on added content make the endeavor increasingly resource-intensive with limited tangible benefits.
8) Model Update Latency: LLMs aren’t continuously trained. They undergo versioned updates, and influencing one version doesn’t guarantee influence on subsequent versions. The latency between your efforts and the next model iteration could nullify or dilute your influence.”
Barbara Lampl, CEO & Lead Data Strategist
“The dynamics between LLMs and systems like ChatGPT and SEO ultimately remain the same at the end of the equation. Only the perspective of optimization will switch to another tool, that is in fact nothing more than a better interface for classical information retrieval systems.
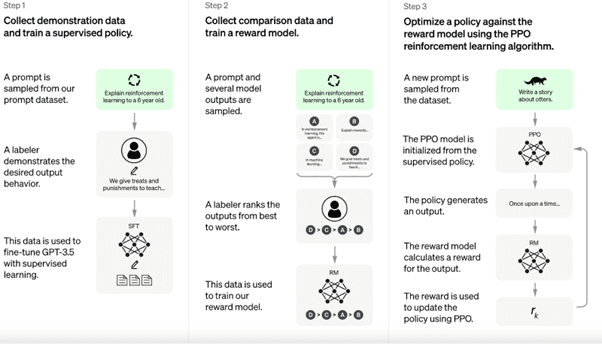
The models are trained on large crawls of the web (for example https://commoncrawl.org/). The crucial issue of these crawls is to cover as many relevant contexts for users as possible, through which the model learns to correctly assess them and provide the generative basis for the subsequent reinforcement learning layer.
ChatGPT fine-tuning process (https://openai.com/blog/chatgpt)
The reinforcement learning layer generates an appropriate response based on the learned contexts and prompt patterns. The probability that traditional information retrieval systems (e.g. google or bing) are used for additional crawls to target qualitative content and known domains like wikipedia or github are collected holistically is the only way to ensure relevance continuously from user perspective. The training of these LLMs and the use in traditional information retrieval systems like google and bing is known to all since the implementation of BERT.
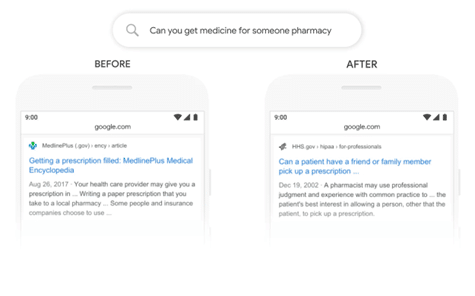
Google BERT implementation changes the way how information retrieval understands queries and contexts (https://blog.google/products/search/search-language-understanding-bert/)
With this in mind user input targets already for a longer time the needed crawling focus for LLM models to target the relevant contexts for incoming searches. The probability that the LLM model uses corresponding content from the crawl for training increases with the findability of the respective document on the web and in search engines to provide consistency and quality. LLM systems are great systems to compute similarity but not as good in provide facts or solve logical tasks. For solving logical tasks, training data in the form of prompts is needed. To provide better answers for facts and to support them with sources, the latest developments are driving to close the loop. RAG (retrieval-augmented generation) uses external data stores as context to provide better, more up-to-date answers that you can rely on because they include the appropriate relevant sources in the answer.
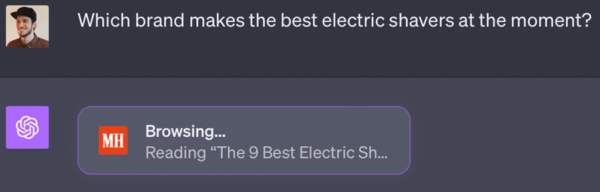
This is done with the help of search engines. Here is an example with the new ChatGPT Bing Beta feature:
Data storage sources from bing:
- https://www.menshealth.com/grooming/g21347829/best-electric-razor-men/#
- https://shavercheck.com/best-electric-razor/
- https://www.healthline.com/health/best-electric-shaver-for-men#A-quick-look-at-the-best-electric-shavers
- https://www.gq.com/story/best-electric-shavers#:~:text=The%20Longstanding%20Fan%20Favorite%3A%20Panasonic,Head
- https://www.gq-magazine.co.uk/gallery/best-electric-shavers#:~:text=What%27s%20the%20best%20electric%20shaver,sharp%20NanoTech%20blades
From my prompt, a corresponding search query was derived, which added appropriate relevant content from Bing as context, and from which ChatGPT then generated a response with appropriate summarized sources (Bing API). This leads to two optimizations, on the one hand ChatGPT and on the other in the field of SEO. On the ChatGPT side: the users prompts and the search queries and results generated from them can be used both to drive a more relevant crawl and thus train the LLM and to train the reinforcement learning layer with appropriate prompts to continuously increase the quality of the overall system as it is used. As before, the bottleneck remains the human-performed labeling and ranking of the prompts and responses for the reinforcement learning step. On the other side, we have the classic SEO mechanics: more relevant and discoverable content leads to a higher probability of being part of the crawl and LLM training to include your constructed context. How much impact your content will have on the LLM is hard to measure because the shifting data points of your tokens in the given context are calculated in contrast to all other tokens and documents in the corpus/crawl. Maybe you have luck and change a context, but alone the fact that your brand is known inside of a context and part of the vocabulary of the model is a great achievement. The RAG mechanics also lead to better ranking content being used as the basis for higher quality responses. This is exactly where optimization potential exists, as suitable targets can be identified and the content of these can be matched with the answer.
The end result is not a truly new approach to SEO, but merely a new perspective. Which search engines are in the focus and are used by systems like ChatGPt or BARD, how to include the prompt generated keywords into the keyword research process, how to target the relevant pages that are used as data storage / context and place fitting content and how content must be structured to get the best possible mention in a timely manner as a response. This leads at the end to the same optimizations as known with a light slide of the perspective and underlying discovery and research process. In the end, it’s an optimization for a hybrid metasearch engine with a natural language user interface that summarizes the results for you.”
Philip Ehring, Head of Business Intelligence


Zusammengefasst kann man folgende Punkte aus Data Science Sicht festhalten:
- Bei großen kommerziellen Sprachmodellen ist die Trainingsdatenbasis nicht öffentlich, und es werden Ausrichtungsstrategien angewendet, um neutrale und unkontroverse Antworten zu gewährleisten. Um die gewünschte Meinung in der KI zu verankern, müsste mehr als 50% der Trainingsdaten diese Meinung reflektieren, was extrem aufwendig wäre zu beeinflussen.
- Es ist sehr schwer, aufgrund der enormen Datenmenge und statistischen Signifikanz eine bedeutende Wirkung zu erzielen.
- Die Dynamik der Netzwerkverbreitung, zeitliche Faktoren, Modell-Regularisierung, Feedback-Schleifen und ökonomische Kosten stellen Hindernisse dar.
- Zudem erschwert die Verzögerung bei Modellupdates die Beeinflussung.
- Aufgrund der großen Anzahl der Kookkurrenzen, die man erzeugen müsste, ist es je nach Markt nur mit größerem Engagement in PR und Marketing möglich, die Ausgaben einer generativen KI hinsichtlich der eigenen Produkte und Marke zu beeinflussen.
- Ein weitere Herausforderung ist die Identifikation der Quellen, die als Trainingsdaten für die LLMs genutzt werden.
- Die Dynamik zwischen LLMs und Systemen wie ChatGPT bzw. BARD und SEO bleibt konsistent. Die einzige Änderung liegt in der Optimierungsperspektive, die sich auf eine bessere Schnittstelle für klassisches Information Retrieval verlagert.
- Das Finetuning von ChatGPT beinhaltet eine Verstärkungslernschicht, die Antworten auf der Grundlage gelernter Kontexte und Aufforderungen generiert.
- Traditionelle Suchmaschinen wie Google und Bing werden verwendet, um qualitativ hochwertige Inhalte und Domains wie Wikipedia oder GitHub zu finden. Die Integration von Modellen wie BERT in diese Systeme ist ein Fortschritt. Googles BERT verändert die Art und Weise, wie Information Retrieval Nutzeranfragen und Kontexte versteht.
- Prompts stehen im Mittelpunkt der Webcrawls für LLMs. Die Wahrscheinlichkeit, dass ein LLM Inhalte aus einem Crawl für das Training verwendet, wird durch die Auffindbarkeit des Dokuments im Web beeinflusst.
- Während LLMs sich durch die Berechnung von Ähnlichkeiten auszeichnen, sind sie nicht so gut darin, sachliche Antworten zu geben oder logische Aufgaben zu lösen. Um dieses Problem zu lösen, nutzt Retrieval-Augmented Generation (RAG) externe Datenspeicher, um bessere und fundiertere Antworten zu liefern.
- Die Integration von Web Crawling bietet einen doppelten Nutzen: Verbesserung der Relevanz und des Trainings von ChatGPT und Verbesserung der Suchmaschinenoptimierung. Eine Herausforderung bleibt die menschliche Kennzeichnung und Einstufung von Prompts und Antworten für das Reinforcement Learning.
- Die Bedeutung von Inhalten im LLM-Training wird durch ihre Relevanz und Auffindbarkeit beeinflusst. Die Auswirkung spezifischer Inhalte auf ein LLM ist schwer zu quantifizieren, aber die Wiedererkennung der eigenen Marke in einem bestimmten Kontext ist ein mögliches Ziel.
- Die RAG-Methodik verbessert auch die Qualität der Antworten durch die Verwendung von höher eingestuften Inhalten. Dies stellt eine Optimierungsmöglichkeit dar, indem der Inhalt auf potenzielle Antworten abgestimmt wird.
- Es geht darum, zu verstehen, welche Suchmaschinen von Systemen wie ChatGPT priorisiert werden, die von Prompts generierten Schlüsselwörter in die Recherche einzubeziehen, relevante Seiten für den Inhalt auszuwählen und den Inhalt für eine optimale Erwähnung in den Antworten zu strukturieren.
- Letztlich geht es um die Optimierung für eine hybride Metasuchmaschine mit einer natürlichsprachlichen Schnittstelle, die die Ergebnisse für die Nutzer zusammenfasst.
Wie könnten die Trainingsdaten für die LLMs ausgewählt werden?
Hier gibt es zwei mögliche Ansätze. E-E-A-T und Ranking.
Es ist davon auszugehen, dass die Anbieter der bekannten LLMs nur Quellen als Trainingsdaten verwenden, die einen gewissen Qualitätsstandard erfüllen und vertrauenswürdig sind.
Das E-E-A-T-Konzept von Google würde eine Möglichkeit bieten, diese Quellen zu selektieren. In Bezug auf die Entitäten kann Google den Knowledge Graph für das Factchecking und das Finetuning des LLM nutzen.
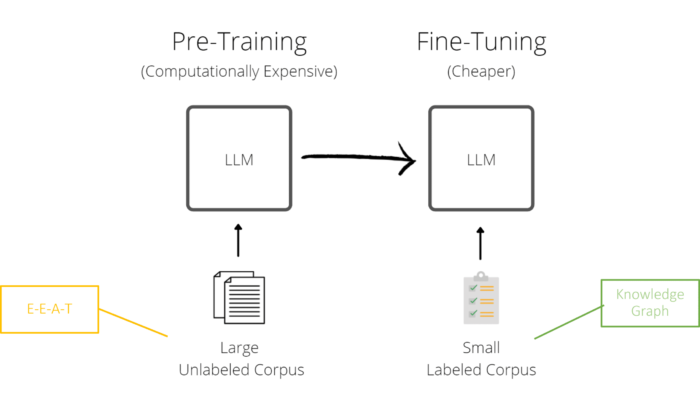
E-E-A-T und Knowledge Graph und LLMs
Der zweite Ansatz ist wie von Philip Ehring die Auswahl der Trainingsdaten anhand von Relevanz und Qualität ermittelt durch den eigentlichen Ranking-Prozess. Also vorne rankende Inhalte zu den entsprechenden Queries und Prompts werden automatisch für das Training der LLMs herangezogen. Dieser Ansatz geht davon aus, dass das Information Retrieval Rad nicht neu erfunden werden muss und Suchmaschinen auf die etablierten Bewertungs-Verfahren aufsetzen, um Trainingsdaten auszuwählen. Das würde dann neben der Relevanz-Bewertung auch E-E-A-T beinhalten. Mehr dazu in dem Beitrag Die Dimensionen des Google-Rankings
Allerdings haben Tests bei Bing Chat und SGE bisher keine klaren Korrelationen zwischen den in den KI-Antworten und den referenzierten Quellen und den Rankings aufgezeigt.
Schlussfolgerung
Ob sich LLM-Optimierung bzw. GAIO tatsächlich als legitime Strategie zur Beeinflussung von LLMs im Sinne der eigenen Ziele durchsetzen wird, steht in den Sternen.
Von Seiten der Data Science gibt es Skepsis. Einige SEOs glauben daran.
Sollte dies der Fall sein, ergeben sich folgende Ziele, die es zu erreichen gilt:
- Etablierung der eigenen Medien über E-E-A-T als Trainingsdatenquelle
- Generierung von Erwähnungen der eigenen Marke und Produkte in qualifizierten Medien
- Erzeugung von Kookkurrenzen der eigenen Marke mit anderen relevanten Entitäten und Attributen in qualifizierten Medien
- Teil des Knowledge Graph werden
Welche Maßnahmen dafür zu ergreifen sind, habe ich in dem Artikel How to improve E-A-T for websites and entities erläutert.
Die Chancen, mit LLM-Optimierung erfolgreich zu sein, steigen mit der Größe des Marktes. Je nischiger ein Markt ist, desto einfacher ist es, sich als Marke im jeweiligen thematischen Kontext zu positionieren. Dadurch sind auch weniger Kookkurrenzen in den qualifizierten Medien notwendig, um mit den relevanten Attributen und Entitäten in den LLMs assoziiert zu werden. Je größer der Markt, desto schwieriger, da viele Marktteilnehmer über große PR- und Marketingressourcen verfügen und eine lange Historie aufgebaut haben.
GAIO oder LLM-Optimierung benötigt deutlich mehr Ressourcen als klassisches SEO, um die öffentliche Wahrnehmung und damit die LLMs zu beeinflussen und muss strategisch gut durchdacht sein. An dieser Stelle möchte ich auf mein Konzept des Digital Authority Management verweisen. Mehr dazu im Artikel Digital Authority Management: Eine neue Disziplin im Zeitalter von SGE und E-E-A-T.
Sollte sich die LLM-Optimierung als sinnvolle SEO-Strategie herausstellen, werden große Marken aufgrund ihrer PR- und Marketingressourcen zukünftig deutliche Vorteile bei der Positionierung in Suchmaschinen und in den Ergebnissen von generativer KI haben.
GAIO oder LLMO sehe ich nicht als die Zukunft von SEO, aber man sollte die Entwicklungen und Möglichkeiten aufmerksam beobachten.
Eine andere Perspektive ist, dass man in der Suchmaschinenoptimierung weitermachen kann wie bisher, da gut rankende Inhalte auch gleichzeitig für das Training der LLMs genutzt werden kann. Dort sollte man dann zusätzlich auf Kookkurrenzen zwischen Marken/Produkten und Attributen bzw. anderen Entitäten achten und darauf optimieren.
Welcher dieser Ansätze die Zukunft für SEO sein wird ist nicht klar und wird sich erst zeigen wenn SGE endgültig eingeführt wird und sich abzeichnet welche Tools und Sprachmodelle sich durchsetzen werden.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.