Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf die Ranking-Faktoren und deren Gewichtung ein, sondern eher auf die Funktionsweise.
Disclaimer: Einige Annahmen in diesem Artikel basieren auf meinen eigenen Gedanken und Hypothesen, die ich aus verschiedenen Quellen entwickelt habe.
Inhaltsverzeichnis
- 1 Warum sollten sich SEOs mit der Funktionsweise von Suchmaschinen / Google beschäftigen?
- 2 Prozessschritte beim Information Retrieval, des Rankings und der Wissensentdeckung bei Google
- 3 Indexierung und Crawling
- 4 Welche Google-Indizes gibt es?
- 5 LLM, Vektor-Index und Vektor-Datenbank
- 6 Hybride Lösungen aus KGs und LLMs
- 7 Die Suche-Revolution der Vektorsuche
- 8 Die Google-Suche als Hybridsystem aus lexikalischer und semantischer Suche
- 9 Semantische Suche vs. Lexikalische Suche
- 10 Klassifizierung von neuen Inhalten und Gewährleistung eines Information Gain
- 11 Verarbeitung von Suchanfragen
- 12 Ranking von Suchergebnissen
- 13 Google-Ranking-Systeme
- 14 Deep Learning Modelle und andere Komponenten für das Ranking
- 15 Wie arbeiten die unterschiedlichen Rankingsysteme zusammen?
Warum sollten sich SEOs mit der Funktionsweise von Suchmaschinen / Google beschäftigen?
Ich halte es nicht für sinnvoll, sich nur mit Rankingfaktoren und möglichen Optimierungsaufgaben zu beschäftigen, ohne zu verstehen, wie eine moderne Suchmaschine wie Google funktioniert. Es gibt viele Mythen und Spekulationen in der SEO-Branche, denen man blind folgt, wenn man keine eigenen Ranking-Erfahrungen hat. Um Mythen im Vorfeld beurteilen zu können, ist es hilfreich, sich mit der Technologie und der grundsätzlichen Funktionsweise von Google auseinanderzusetzen. Dieser Artikel soll dabei helfen und fasst meine Gedanken zu den Aussagen von Google, den Google-Patenten und dem Kartellverfahren gegen Google sowie den Aussagen von Pandu Nayak von Google zusammen.
Prozessschritte beim Information Retrieval, des Rankings und der Wissensentdeckung bei Google
Nach dem exzellenten Vortrag „How Google works: A Google Ranking Engineer’s Story“ von Paul Haahr unterscheidet Google folgende Prozessschritte:
Vor einer Suchanfrage
- Crawlen
- Analyse der gecrawlten Seiten
- Links extrahieren
- Inhalte extrahieren
- Semantik annotieren
- …
- Indexierung
Verarbeitung von Suchanfragen
- Suchanfragen verstehen
- Retrieval und Scoring
- Anpassungen nach dem Retrieval
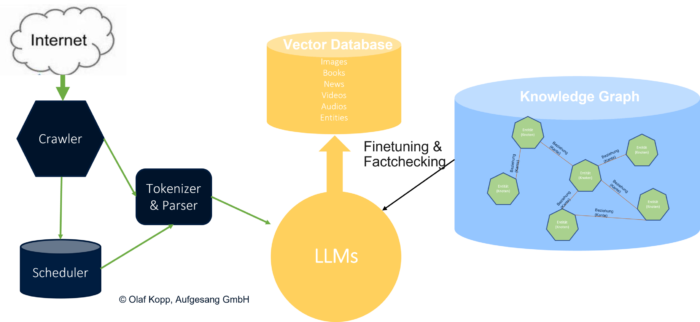
Indexierung und Crawling
Indexierung und Crawling sind die Grundvoraussetzung für das Ranking, haben aber ansonsten nichts mit dem Ranking von Inhalten zu tun.
Google durchsucht das Internet jede Sekunde mit Hilfe von Bots. Diese Bots werden auch als Crawler bezeichnet. Die Google-Bots folgen Links, um neue Dokumente/Inhalte zu finden. Aber auch URLs, die nicht im HTML-Code angezeigt werden und vielleicht! Auch URLs, die direkt in den Chrome-Browser eingegeben werden, können von Google zum Crawlen verwendet werden.
Findet der Google Bot neue Links, werden diese in einem Scheduler gesammelt, damit sie später abgearbeitet werden können.
Domains werden mit unterschiedlicher Häufigkeit und Vollständigkeit gecrawlt oder es werden Domains unterschiedliche Crawling-Budgets zugewiesen. Bisher war der PageRank ein Indikator für die Crawling-Intensität einer Domain. Neben externen Links können auch die Veröffentlichungs- und Aktualisierungshäufigkeit sowie die Art der Website eine Rolle spielen. Nachrichtenseiten, die auf Google News erscheinen, werden in der Regel häufiger gecrawlt. Laut Google gibt es bis zu einer Anzahl von ca. 10.000 URLs keine Probleme mit dem Crawling. Mit anderen Worten: Die meisten Websites können problemlos vollständig gecrawlt werden.
Die Indexierung erfolgt in zwei Schritten.
Im ersten Schritt wird der reine html-Code mit einem Parser so aufbereitet, dass er ressourcenschonend in einen Index übertragen werden kann. Mit anderen Worten: Die erste indizierte Version des Inhalts ist eine reine html-Seite, die nicht gerendert wurde. Das spart Google Zeit beim Crawlen und damit bei der Indexierung.
In einem zweiten, späteren Schritt wird die indizierte html-Version mit einem Rendering versehen.
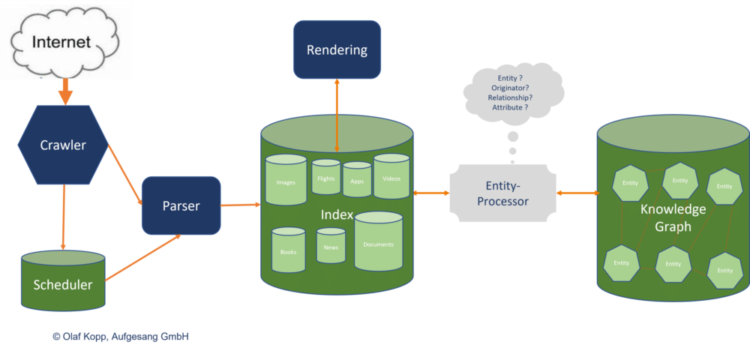
Der klassische Indexierungsprozess kann in zwei Teile unterteilt werden:
- Indexerstellung: Suchmaschinen durchforsten das Internet nach Dokumenten (Webseiten, PDFs usw.) und erstellen einen Index, eine umfangreiche Datenbank mit Wörtern, Sätzen und den dazugehörigen Dokumenten. Dieser Index ermöglicht es der Suchmaschine, Dokumente, die mit einer bestimmten Anfrage in Zusammenhang stehen, schnell aufzufinden.
- Dokument-Merkmale: Jedes Dokument im Index wird auf bestimmte Merkmale hin analysiert, wie z. B. das Vorhandensein und die Verteilung von Schlüsselwörtern, die Struktur des Dokuments (z. B. Titel, Überschriften und Links) und andere Signale, die auf seine Relevanz für bestimmte Themen oder Abfragen hinweisen könnten. Diese Merkmale können abfrageabhängig oder -unabhängig sein.
Welche Google-Indizes gibt es?
Bei Google kann grundsätzlich zwischen drei Arten von Indizes unterschieden werden.
Klassische Suchindizes
Der klassische Suchindex enthält alle Inhalte, die Google indexieren kann. Je nach Art des Inhalts unterscheidet Google auch zwischen den sogenannten vertikalen Indizes wie klassischer Dokumentenindex (Text), Bildindex, Videoindex, Flüge, Bücher, Nachrichten, Shopping, Finanzen. Der klassische Suchindex besteht aus Tausenden von Scherben, die Millionen von Websites enthalten. Aufgrund der Größe des Index ist es möglich, durch die parallele Abfrage der Websites in den einzelnen Shards sehr schnell die Top-n-Dokumente/Inhalte pro Shard zusammenzustellen.
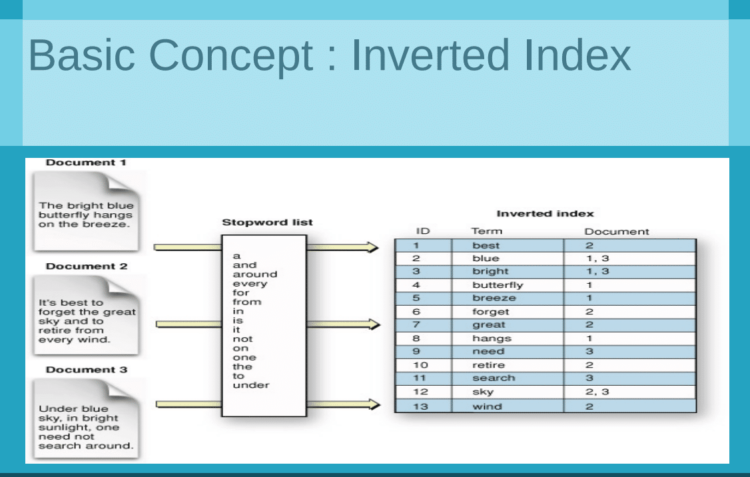
Quelle: https://datascience.stackexchange.com/questions/112544/how-does-google-indexes-text-documents
Knowledge Graph
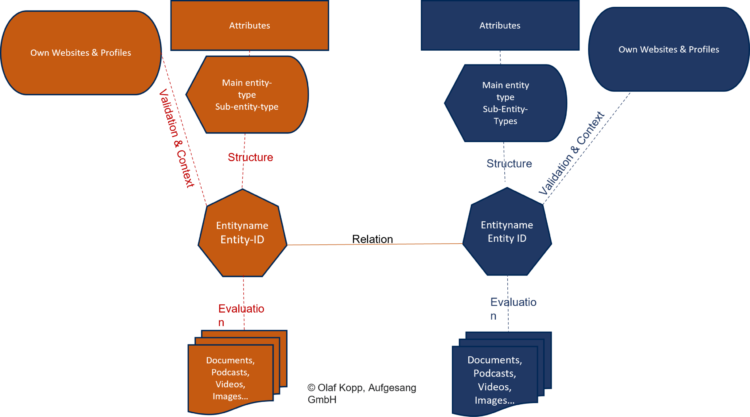
Der Knowledge Graph ist der semantische Entitätsindex von Google. Alle Informationen über Entitäten und ihre Beziehungen zueinander werden im Knowledge Graph gespeichert. Google bezieht die Informationen über die Entitäten aus verschiedenen Quellen.
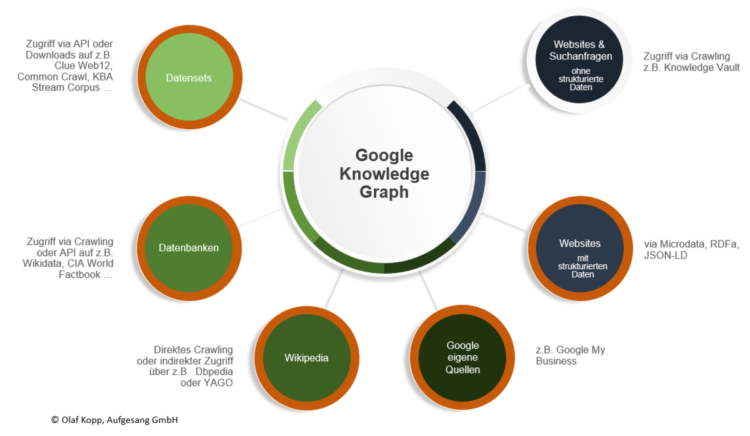
Mit Hilfe von Natural Language Processing (NLP) ist Google zunehmend in der Lage, unstrukturierte Informationen aus Suchanfragen und Online-Inhalten zu extrahieren, um Entitäten zu identifizieren oder Daten zu Entitäten zuzuordnen. Mit MUM kann Google dafür nicht nur Textquellen nutzen, sondern auch Bilder, Videos und Audios. Mehr Infos zu Natural Language Based Search hier.
LLM, Vektor-Index und Vektor-Datenbank
Die neueste Art von Index, die Google zum Speichern und Verstehen von Informationen verwendet, sind Large Language Models (LLMs) und die dazugehörigen Vektordatenbanken. Seit der Einführung von BERT im Jahr 2018 verwendet Google LLMs, um Ähnlichkeitsberechnungen in Vektorräumen durchzuführen. Seit der Einführung von Rankbrain im Jahr 2015 verwendet Google Verfahren wie Word2Vec, um Wörter und andere Elemente in Vektoren umzuwandeln.
Google wird in Zukunft verstärkt Vektordatenbanken oder Vektorindizes für die Organisation und das Ranking verwenden.
Vektordatenbanken sind spezialisierte Datenbanken, die für die effiziente Speicherung, Suche und Verwaltung von Vektoren (Darstellungen von Daten in hochdimensionalen Räumen) konzipiert sind. Diese Vektoren können eine Vielzahl von Datentypen darstellen, z. B. Bilder, Text, Audio oder andere komplexe Datentypen, die in einen Vektorraum transformiert wurden.
Im Zusammenhang mit maschinellem Lernen und künstlicher Intelligenz (KI) werden Daten oft als Vektoren dargestellt, um Ähnlichkeiten und Beziehungen zwischen verschiedenen Datenelementen zu erkennen. Vektordatenbanken machen sich diesen Ansatz zunutze, um hochdimensionale Abfragen effizient zu unterstützen. Sie sind besonders nützlich für Anwendungen wie semantische Suchen, Empfehlungssysteme, Gesichtserkennung und andere KI-gesteuerte Funktionen.
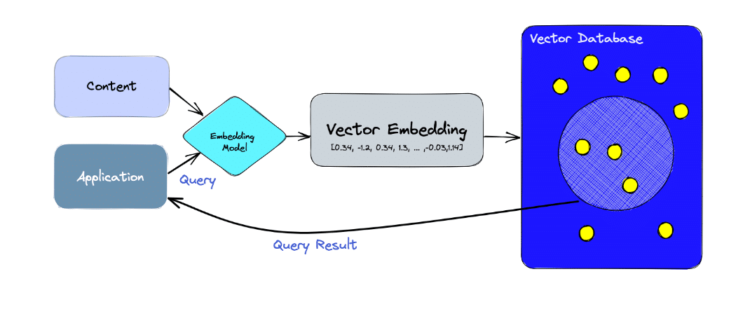
Quelle: https://www.pinecone.io/learn/vector-database/
Ein Hauptmerkmal von Vektordatenbanken ist ihre Fähigkeit, Ähnlichkeitssuchen durchzuführen. Das bedeutet, dass sie Datenelemente finden können, die einem bestimmten Beispiel oder einer Abfrage ähnlich sind, und zwar auf der Grundlage des Abstands zwischen Vektoren im hochdimensionalen Raum. Dieser Abstand kann mit verschiedenen Metriken gemessen werden, z. B. dem euklidischen Abstand oder der Kosinusähnlichkeit.
Vektordatenbanken bieten auch spezialisierte Indizierungs- und Speicherstrategien, um die Suche und den Abruf von hochdimensionalen Daten effizient zu gestalten. Sie können sowohl in der Cloud als auch vor Ort implementiert werden und unterstützen häufig skalierbare und verteilte Architekturen, um große Datensätze zu verarbeiten.
Hybride Lösungen aus KGs und LLMs
Bei der Organisation von Wissen gibt es derzeit einen Wettlauf zwischen Wissensgraphen auf der einen und großen Sprachmodellen (LLMs) auf der anderen Seite. Neuere Entwicklungen legen nahe, dass eine Kombination beider Systeme eine optimale Lösung darstellt. In Zukunft könnten Wissensvektorgraphen die Vorteile einer symbolischen semantischen Datenbank wie dem Knowledge Graph und hoch skalierbarer LLMs sein.
Die Grenzen von LLMs liegen in ihrem Mangel an Domänenwissen und führen zu veralteten oder ungenauen Antworten. Um dies zu beheben, wurde das Konzept der Retrieval-Augmented Generation (RAG) eingeführt, das LLMs mit externen Wissensdatenbanken anreichert. RAG steht jedoch vor praktischen Herausforderungen, wie der Komplexität der Datenverarbeitung und -integration.
Die vorgeschlagene Lösung beinhaltet die Verwendung von Vektordatenbanken für eine effiziente Informationsbeschaffung durch eine vektorielle Ähnlichkeitssuche. Trotz seiner Vorteile birgt dieser Ansatz eine Reihe von Herausforderungen, darunter die Nichttransitivität der Vektorähnlichkeit, die die genaue Suche nach relevanten Informationen erschwert.
Um diese Hindernisse zu überwinden, könnte das Konzept eines Wissensvektorgraphen als neuartige RAG-Architektur, die Vektordatenbanken mit Graphdatenbanken kombiniert, eine Lösung darstellen. Dieser Ansatz zielt darauf ab, eine nuanciertere und umfassendere Methode für die Verknüpfung von disparaten Wissensteilen bereitzustellen und dadurch die Fähigkeit des LLM zu verbessern, genaue und kontextbezogene Antworten zu generieren.
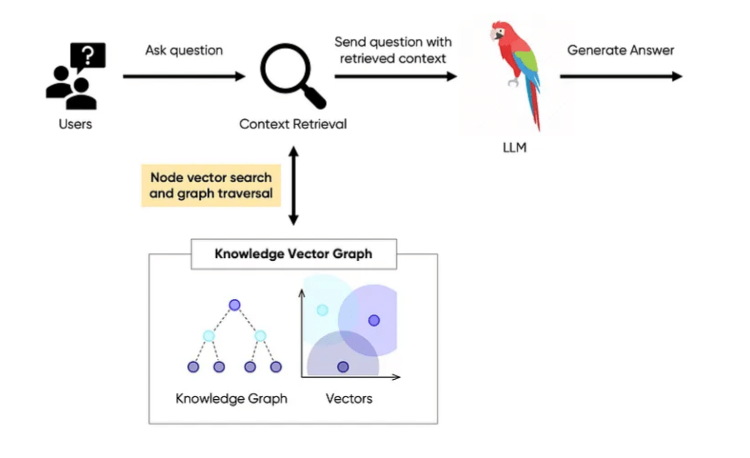
Quelle: https://medium.com/@johnson.h.kuan/from-rags-to-riches-helping-ai-connect-the-dots-with-a-knowledge-vector-graph-f9e8f91b06a4
Im Jahr 2024 stellte Google Exphormer vor: Scaling transformers for graph-structured data (Skalierung von Transformatoren für graph-strukturierte Daten), das die Welt der Graphen und Transformatoren zusammenbringt. Exphormer ist eine intelligente Lösung, mit der Transformatoren große Graphen verarbeiten können, ohne überfordert zu werden. Dies geschieht durch die Auswahl der zu berücksichtigenden Verbindungen unter Verwendung von so genannten „Expander-Graphen“. Diese sind besonders, weil sie gerade genug Verbindungen haben, um sicherzustellen, dass keine Informationen verloren gehen, aber nicht so viele, dass der Transformator ins Stocken gerät.
Das Exphormer-System bietet Skalierbarkeit durch die Einführung eines spärlichen Aufmerksamkeitsmechanismus, der speziell für Graphdaten entwickelt wurde. Es nutzt Expander-Graphen, die spärlich, aber gut verbunden sind, was eine effiziente Berechnung und Speichernutzung ermöglicht.
Die Suche-Revolution der Vektorsuche
Die Vektorsuche erfreut sich zunehmender Beliebtheit, da sie mit komplexen Objekten arbeiten kann, die als hochdimensionale Vektoren dargestellt werden.
Sie bietet einen tieferen Lernansatz, der die Semantik von Abfragen versteht, was für den Abgleich von Bedeutung und Absicht entscheidend ist. Die Vektorsuche kann verschiedene Datenformate wie Text, Bilder, Audio und Video durchsuchen, um den Kontext zu verstehen und schnell relevante Antworten zu liefern. Google könnte daher MUM im Jahr 2021 als leistungsstarkes neues Deep-Learning-System einführen.
Die Vektorsuche ermöglicht es den Nutzern, bei ihren Suchanfragen den Kontext zu berücksichtigen, so dass Relevanz und Kontext Hand in Hand gehen.
Die Nutzer können Informationen finden, die über eine spezifische Anfrage hinausgehen, und erhalten präzise und differenzierte Antworten, ohne lange Ergebnislisten durchsuchen zu müssen.
Die Implementierung der Vektorsuche kann eine Herausforderung darstellen, da sie die Integration verschiedener Komponenten wie eines großen Sprachmodells, einer Vektordatenbank und Frameworks erfordert. Die Vektorsuche bietet Google neuronale Pfade für den kognitiven Abruf und unterstützt kontextbezogene Entscheidungen.
Sie ermöglicht es Google, eine natürliche semantische Suche in Anwendungen zu integrieren, die Interaktion mit dem Nutzer zu verbessern und Informationen in Echtzeit bereitzustellen.
Embeddings
Deep Learning ist ein Bereich der Informatik, der Computern hilft, die Bedeutung von Daten auf einer tieferen Ebene zu „verstehen“, ähnlich der Funktionsweise unseres Gehirns. Deep Learning verwendet so genannte neuronale Netze, die die Funktionsweise des menschlichen Gehirns nachahmen sollen. Diese Netze bestehen aus mehreren Schichten, von der Eingabe (was Sie in den Computer eingeben) bis zur Ausgabe (was der Computer aus der Eingabe versteht oder vorhersagt).
Hier kommen die Embeddings ins Spiel. Wenn ein Computer ein Datenelement betrachtet, z.B. ein Foto eines Hundes, sieht er nicht „Hund“ wie wir. Stattdessen wandelt er das Foto in eine lange Liste von Zahlen um, die Embeddings genannt werden. Jede Zahl in dieser Liste steht für verschiedene Merkmale oder Aspekte des Fotos, z. B. ob ein Hund darauf zu sehen ist, ob der Himmel blau ist oder ob ein Baum im Hintergrund steht.
Stellen Sie sich vor, Sie würden versuchen, das Wesen eines Fotos nur mit Zahlen zu beschreiben. Genau das tun eingebettete Vektoren, aber in einer Form, die Computer verstehen und verarbeiten können. Diese Vektoren ermöglichen es Computern, verschiedene Datentypen zu vergleichen und zu durchsuchen, indem sie darauf achten, wie ähnlich sich ihre Zahlen sind, anstatt sich auf die exakten Wörter zu verlassen. Selbst wenn zwei Bilder für uns sehr unterschiedlich aussehen, kann der Computer feststellen, dass ihre Einbettungsvektoren sehr ähnlich sind, was bedeutet, dass sie viele Merkmale gemeinsam haben.
Kurz gesagt, Embeddings sind wie eine universelle Sprache für Computer, um alle Arten von Daten auf der Grundlage ihrer tatsächlichen Bedeutung zu verstehen und zu durchsuchen, und nicht nur auf der Grundlage dessen, was sie sagen oder oberflächlich betrachtet zu sein scheinen. Dies eröffnet völlig neue Möglichkeiten für die Suche und Organisation von Informationen, die bisher nicht möglich waren.
Embeddings sind eine Schlüsselkomponente beim Übergang von traditionellen lexikalischen Suchmethoden zu fortgeschrittenen semantischen Suchfunktionen, insbesondere beim Umgang mit unstrukturierten Daten wie Bildern, Videos und Audiodateien. Lexikalische Suchmaschinen wandeln strukturierten Text in durchsuchbare Begriffe um, aber dieser Ansatz reicht bei unstrukturierten Daten nicht aus, da für eine effiziente Indizierung und Abfrage ein Verständnis der den Daten innewohnenden Bedeutung erforderlich ist.
Deep Learning, ein Zweig des maschinellen Lernens, der sich auf Modelle konzentriert, die auf künstlichen neuronalen Netzen mit mehreren Verarbeitungsebenen basieren, ist entscheidend für die Extraktion der wahren Bedeutung aus unstrukturierten Daten. Diese neuronalen Netze ahmen die Struktur und Funktionsweise des menschlichen Gehirns nach und verfügen über Eingabe- und Ausgabeschichten sowie mehrere verborgene Schichten für die Datenverarbeitung.
Quelle: https://www.ibm.com/topics/neural-networks
Neuronale Netze wandeln unstrukturierte Daten in Embeddings oder Sequenzen von Gleitkommawerten um, die die Daten in einem mehrdimensionalen Raum darstellen. Während Menschen Vektoren in zwei oder drei Dimensionen leicht verstehen können, können die in neuronalen Netzen verwendeten Einbettungsvektoren Hunderte oder Tausende von Dimensionen haben, von denen jede einem Merkmal oder einer Eigenschaft der Daten entspricht.
Embeddings ermöglichen somit eine semantische Suche, indem sie das Wesen und die Merkmale unstrukturierter Daten erfassen und so präzisere und relevante Suchergebnisse auf der Grundlage der Bedeutung der Daten und nicht nur der übereinstimmenden Begriffe ermöglichen. Dieser Ansatz verbessert die Fähigkeit, große Mengen unstrukturierter Daten zu durchsuchen und zu analysieren, erheblich und ebnet den Weg für intelligentere und kontextbewusste Suchsysteme.
Die Google-Suche als Hybridsystem aus lexikalischer und semantischer Suche
Google arbeitet heute lexikalisch und entitätenbasiert. Je nachdem, wie klar Google die Verbindungen zwischen Entitäten in den Suchanfragen und Dokumenten erkennt, verwendet Google semantische oder lexikalische Ansätze zur Informationsgewinnung in Recall und Precision.
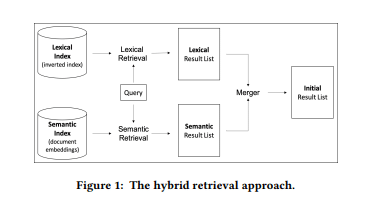
Die semantische Suche geht über den einfachen Abgleich von Schlüsselwörtern hinaus, indem sie die komplexen Beziehungen zwischen den Wörtern versteht und so die Bedeutung oder den Kontext der Anfrage und der Dokumente erfasst. Dies ist entscheidend, um relevante Dokumente zu finden, die nicht die exakten Suchbegriffe enthalten, aber im Kontext miteinander in Beziehung stehen.
Der Ansatz basiert auf der Prämisse, dass effektive semantische Modelle, insbesondere in den letzten Jahren, vor allem mit Hilfe von tiefen neuronalen Netzen entwickelt wurden. Diese Modelle sind in der Lage, die Nuancen der Sprache zu verstehen, einschließlich Synonyme, verwandte Begriffe und Kontext, die von lexikalischen Modellen oft übersehen werden.
Das semantische Retrievalmodell basiert auf tiefen neuronalen Netzen, die insbesondere Architekturen wie BERT (Bidirectional Encoder Representations from Transformers) nutzen. BERT und ähnliche Modelle werden mit großen Mengen von Textdaten trainiert, um komplexe Sprachmuster und Semantik zu verstehen.
Für den Retrievalprozess erzeugt das Modell Embeddings sowohl für Anfragen als auch für Dokumente. Diese Embeddings repräsentieren den semantischen Inhalt des Textes in einem hochdimensionalen Raum, in dem die semantische Ähnlichkeit zwischen einer Anfrage und einem Dokument gemessen werden kann, üblicherweise mit Hilfe der Kosinusähnlichkeit.
Verbesserter Recall: Durch die Erfassung der Bedeutung hinter den Wörtern kann der semantische Ansatz ein breiteres Spektrum relevanter Dokumente ausfindig machen, einschließlich solcher, die nicht genau die gleichen Schlüsselwörter wie die Suchanfrage enthalten. Dies ist besonders nützlich, um das Problem der Vokabularinkongruenz zu lösen, bei dem die Anfrage und die relevanten Dokumente unterschiedliche Begriffe zur Beschreibung desselben Konzepts verwenden.
Mehr zum semantischen Retrieval finden Sie in meiner Übersicht Most interesting Google Patents for semantic search.
Semantische Suche vs. Lexikalische Suche
Die lexikalische Suche basiert auf dem Prinzip, exakte Wörter oder Phrasen aus einer Suchanfrage mit denen in den Dokumenten zu vergleichen. Diese Methode ist einfach und schnell, hat aber mit Problemen wie Rechtschreibfehlern, Synonymen oder Polysemie (Wörtern mit mehreren Bedeutungen) zu kämpfen. Sie berücksichtigt auch nicht den Kontext oder die Bedeutung der Wörter, was zu irrelevanten Ergebnissen führen kann.
Im Gegensatz dazu verwendet die vektorbasierte semantische Ähnlichkeitssuche Techniken der natürlichen Sprachverarbeitung (Natural Language Processing, NLP), um die Bedeutung von Wörtern und ihre Beziehungen zueinander zu analysieren. Die Wörter werden als Vektoren in einem hochdimensionalen Raum dargestellt, wobei der Abstand zwischen den Vektoren ihre semantische Ähnlichkeit angibt. Diese Methode kann mit Rechtschreibfehlern, Synonymen und Mehrdeutigkeit umgehen und subtilere Wortbeziehungen wie Antonyme, Hypernyme und Meronyme erfassen, was zu genaueren und relevanteren Ergebnissen führt.
Der Einsatz der vektorbasierten semantischen Ähnlichkeitssuche ist jedoch mit Einschränkungen verbunden. Für das Training der NLP-Modelle sind große Datenmengen erforderlich, was rechenintensiv und zeitaufwändig ist. Bei kurzen Dokumenten oder Anfragen ohne ausreichenden Kontext zur Bestimmung der Wortbedeutung ist dieser Ansatz möglicherweise nicht so effektiv. In diesen Fällen könnte eine einfache lexikalische Suche geeigneter und effektiver sein.
Darüber hinaus kann der „Fluch der Dimensionalität“ die Leistung der vektorbasierten semantischen Ähnlichkeitssuche in bestimmten Szenarien beeinträchtigen. Kurze Dokumente können in einem Vektorraum für eine bestimmte Anfrage einen höheren Rang einnehmen, auch wenn sie nicht so relevant sind wie längere Dokumente. Dies liegt daran, dass kurze Dokumente in der Regel weniger Wörter enthalten, was bedeutet, dass ihre Wortvektoren im hochdimensionalen Raum näher am Abfragevektor liegen, was zu einem höheren Ähnlichkeitskoeffizienten führen kann, obwohl sie weniger Information oder Kontext enthalten.
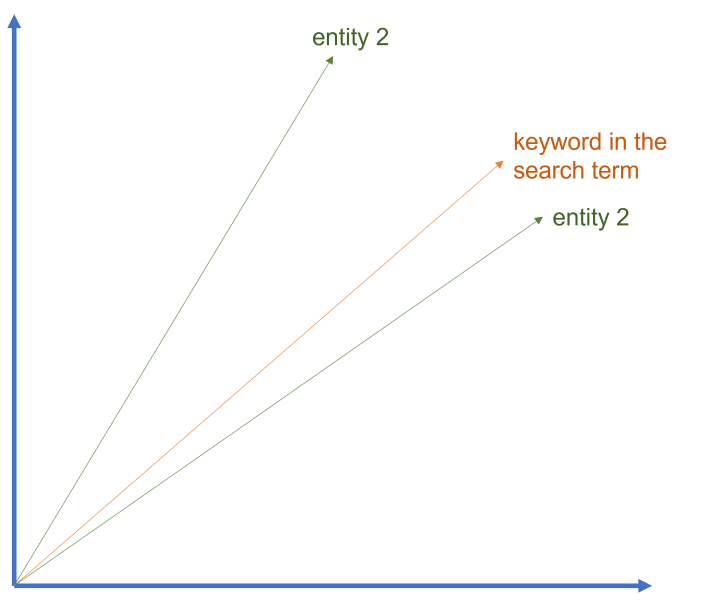
Zusammenfassend lässt sich sagen, dass sowohl die lexikalische Suche als auch die vektorielle semantische Ähnlichkeitssuche ihre Stärken und Schwächen haben. Je nach Art des Korpus, der Art der Abfragen und der verfügbaren Rechenressourcen kann der eine Ansatz besser geeignet sein als der andere. Um die besten Suchergebnisse zu erzielen, ist es entscheidend, die Unterschiede zwischen diesen beiden Methoden zu verstehen und sie mit Bedacht einzusetzen.
Klassifizierung von neuen Inhalten und Gewährleistung eines Information Gain
Wenn Google neue Inhalte entdeckt und crawlt, besteht der nächste Schritt darin, diese thematisch in einem thematischen Korpus zu klassifizieren. Dazu kann Google klassische Information-Retrieval-Methoden wie TF-IDF, semantische Methoden wie die Entity-Analyse oder Ähnlichkeitsberechnungen mittels Vektorraumanalyse verwenden. Inhalte, die einem bestimmten thematischen Muster entsprechen, können einem thematischen Korpus zugeordnet werden.
Ein häufiges Problem ergibt sich, wenn mehrere Dokumente zum gleichen Thema ähnliche Informationen enthalten. Wenn ein Benutzer beispielsweise nach Lösungen für ein Computerproblem sucht, werden ihm möglicherweise mehrere Dokumente vorgelegt, die ähnliche Schritte zur Fehlerbehebung oder Lösungen auflisten. Dies kann dazu führen, dass der Benutzer nach der Lektüre eines Dokuments in den nachfolgenden Dokumenten zum selben Thema wenig bis gar keine neuen Informationen findet. Diese Redundanz kann zu Ineffizienz und Frustration bei den Nutzern führen, die neue oder zusätzliche Informationen zu ihren Fragen oder Interessen suchen.
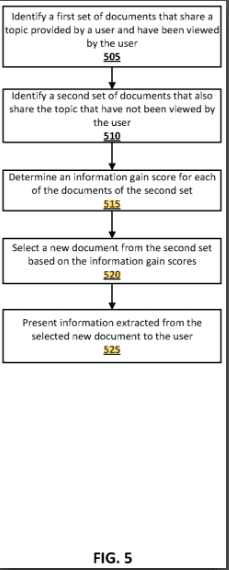 Das Google-Patent Contextual estimation of link information gain beschreibt Techniken zur Bestimmung eines Informationsgewinn-Scores für Dokumente, die für einen Nutzer von Interesse sind, und zur Präsentation von Informationen aus diesen Dokumenten auf der Grundlage ihres Informationsgewinn-Scores. Der Informationsgewinn eines Dokuments gibt an, welche zusätzlichen Informationen es enthält, die über das hinausgehen, was in den vom Nutzer zuvor angesehenen Dokumenten enthalten ist. Bei diesem Ansatz werden Modelle des maschinellen Lernens verwendet, um den Informationsgewinn von Dokumenten zu berechnen. Die Dokumente können den Nutzern dann in einer Weise zur Verfügung gestellt werden, die die potenziellen neuen Informationen widerspiegelt, die sie durch die Anzeige dieser Dokumente gewinnen könnten.
Das Google-Patent Contextual estimation of link information gain beschreibt Techniken zur Bestimmung eines Informationsgewinn-Scores für Dokumente, die für einen Nutzer von Interesse sind, und zur Präsentation von Informationen aus diesen Dokumenten auf der Grundlage ihres Informationsgewinn-Scores. Der Informationsgewinn eines Dokuments gibt an, welche zusätzlichen Informationen es enthält, die über das hinausgehen, was in den vom Nutzer zuvor angesehenen Dokumenten enthalten ist. Bei diesem Ansatz werden Modelle des maschinellen Lernens verwendet, um den Informationsgewinn von Dokumenten zu berechnen. Die Dokumente können den Nutzern dann in einer Weise zur Verfügung gestellt werden, die die potenziellen neuen Informationen widerspiegelt, die sie durch die Anzeige dieser Dokumente gewinnen könnten.
- Informationsgewinn-Score: Eine Metrik, die die neuen oder zusätzlichen Informationen quantifiziert, die ein Dokument im Vergleich zu dem liefert, was der Benutzer bereits gesehen hat. Dies hilft bei der Priorisierung der Dokumente, die dem Benutzer auf der Grundlage der Wahrscheinlichkeit, dass sie neue Erkenntnisse bieten, präsentiert werden.
- Anwendung des maschinellen Lernens: Die Verwendung von Modellen des maschinellen Lernens zur Analyse von Dokumenten und zur Berechnung ihrer Informationsgewinnwerte. Dabei wird der Inhalt neuer Dokumente mit dem früherer Dokumente verglichen, um die Neuartigkeit und Relevanz der darin enthaltenen Informationen zu bewerten.
- Benutzerzentrierte Dokumentendarstellung: Die Dokumente werden in eine Rangfolge gebracht und dem Benutzer auf der Grundlage ihrer Informationsgewinnwerte präsentiert. Auf diese Weise wird sichergestellt, dass den Nutzern mit größerer Wahrscheinlichkeit Dokumente angezeigt werden, die neue Erkenntnisse bieten, was die Effizienz und Effektivität der Informationsfindung erhöht.
- Dynamisches Ranking: Die Rangfolge der Dokumente kann aktualisiert werden, wenn der Benutzer weitere Dokumente ansieht. Diese Neueinstufung basiert auf neu berechneten Bewertungen des Informationsgewinns, wodurch sichergestellt wird, dass sich die Präsentation der Dokumente an die sich entwickelnden Informationen anpasst.
Die folgenden Faktoren können für die Bewertung des Informationsgewinns verwendet werden:
- Neuartigkeit des Inhalts: Dieser Faktor bewertet die Einzigartigkeit der Informationen in einem neuen Dokument im Vergleich zu den Informationen in den Dokumenten, die der Benutzer zuvor angesehen hat. Inhalte, die neue Konzepte, Daten oder Erkenntnisse enthalten, die der Nutzer zuvor noch nicht gelesen hat, erhalten eine höhere Punktzahl für den Informationsgewinn.
- Relevanz für die Benutzerabfrage: Die Relevanz des Inhalts eines Dokuments für die ursprüngliche Suchanfrage oder das geäußerte Interesse des Nutzers ist ein wichtiger Bewertungsfaktor. Dokumente, die den Informationsbedürfnissen oder der Suchabsicht des Nutzers am ehesten entsprechen, werden wahrscheinlich höher bewertet, da davon ausgegangen wird, dass sie dem Nutzer wertvollere Informationen bieten.
- Semantische Analyse: Der Einsatz semantischer Analysetechniken, wie z. B. die Verarbeitung natürlicher Sprache (NLP) und maschinelle Lernmodelle, ermöglicht ein tieferes Verständnis der Bedeutung und des Kontexts des Inhalts. Diese Analyse hilft bei der Identifizierung der semantischen Beziehungen zwischen dem neuen Dokument und den zuvor vom Benutzer angesehenen Dokumenten und trägt so zu einer genaueren Bewertung des Informationsgewinns bei.
- Verlauf der Benutzerinteraktion: Die Interaktionshistorie des Nutzers mit zuvor angesehenen Dokumenten, wie die mit einem Dokument verbrachte Zeit, die Beschäftigung mit dem Inhalt (z. B. Klicken auf Links, Ansehen eingebetteter Videos) und jegliches Feedback (z. B. Upvotes, Likes oder Kommentare), kann die Bewertung beeinflussen. Dokumente, die denen ähneln, mit denen der Benutzer in der Vergangenheit positiv interagiert hat, können eine höhere Punktzahl erhalten.
- Frische des Dokuments: Die Aktualität der in einem Dokument enthaltenen Informationen kann ebenfalls ein Faktor sein, insbesondere bei Themen, bei denen neue Entwicklungen häufig und bedeutend sind. Neuere Dokumente, die die neuesten Informationen oder Daten enthalten, können besser bewertet werden, da sie die aktuellsten Erkenntnisse liefern.
Informationsdichte: Die Dichte an wertvollen Informationen in einem Dokument, im Gegensatz zu Füllmaterial oder allgemein bekannten Fakten, kann sich auf die Bewertung des Informationsgewinns auswirken. Dokumente mit detaillierten Analysen, umfassenden Daten oder ausführlichen Erklärungen zu dem betreffenden Thema werden wahrscheinlich besser bewertet. - Autorität und Verlässlichkeit der Quelle: Die Glaubwürdigkeit und Autorität der Quelle eines Dokuments kann dessen Bewertung beeinflussen. Dokumente aus hoch angesehenen Quellen, die für ihre Genauigkeit und Gründlichkeit in der Materie bekannt sind, können höher bewertet werden, was den Mehrwert zuverlässiger Informationen widerspiegelt.
- Kontextbezogene und verhaltensbezogene Signale: Das System kann auch kontextbezogene Signale berücksichtigen, wie z. B. die aktuelle Aufgabe, den Standort oder die Tageszeit des Benutzers, und verhaltensbezogene Signale, wie z. B. die langfristigen Interessen oder das Informationskonsummuster des Benutzers. Diese Signale helfen dabei, den Informationsgewinn auf den spezifischen Kontext und die Präferenzen des Benutzers abzustimmen.
Verarbeitung von Suchanfragen
Die Magie der Interpretation von Suchbegriffen geschieht bei der Verarbeitung von Suchanfragen. Die folgenden Schritte sind hier wichtig:
Eingabe der Suchanfrage
- Benutzereingabe: Der Prozess beginnt, wenn ein Nutzer einen Suchbegriff oder eine Phrase in die Suchmaschine eingibt. Dies kann über eine Weboberfläche, Sprachsuche oder sogar über integrierte Suchfunktionen in anderen Anwendungen erfolgen.
- Normalisierung: Die Suchmaschine kann die Anfrage normalisieren, um eine einheitliche Verarbeitung zu gewährleisten. Dies kann die Umwandlung aller Zeichen in Kleinbuchstaben, das Entfernen unnötiger Satzzeichen und die Standardisierung von Leerzeichen beinhalten.
Verstehen von Abfragen
- Parsing: Die Suchmaschine analysiert die Anfrage, um ihre Struktur zu verstehen und die wichtigsten Schlüsselwörter, Operatoren (wie Anführungszeichen für exakte Übereinstimmungen oder Minuszeichen für Ausschlüsse) und andere Elemente zu identifizieren, die die Suche beeinflussen können.
- Erkennung von Absichten: Das Verstehen der Absicht des Nutzers ist entscheidend. Die Suchmaschine verwendet Techniken zur Verarbeitung natürlicher Sprache (NLP), um festzustellen, ob der Nutzer nach bestimmten Informationen sucht (Informationsabsicht), versucht, eine bestimmte Website zu erreichen (Navigationsabsicht), oder beabsichtigt, eine Aktion oder einen Kauf durchzuführen (Transaktionsabsicht).
- Kontextualisierung: Der Kontext der Abfrage wird ebenfalls berücksichtigt, z. B. der Standort des Nutzers, der Zeitpunkt der Abfrage, das verwendete Gerät und alle Personalisierungsfaktoren, die auf dem Suchverlauf und den Einstellungen des Nutzers basieren.
Erweiterung und Verfeinerung von Suchanfragen
- Synonymabgleich: Die Suchmaschine kann die Abfrage um Synonyme oder verwandte Begriffe erweitern, um die Suche auszuweiten und mehr potenziell relevante Dokumente zu erfassen.
Rechtschreibkorrektur und Vorschläge: Häufige Rechtschreib- oder Tippfehler werden automatisch korrigiert, und die Suchmaschine kann auch alternative Suchanfragen vorschlagen, wenn sie der Meinung ist, dass der Benutzer einen Fehler gemacht hat oder wenn es eine üblichere Formulierung für die Anfrage gibt. - Semantische Analyse: Fortgeschrittene Suchmaschinen führen eine semantische Analyse durch, um die Bedeutung hinter der Anfrage zu verstehen, nicht nur die einzelnen Begriffe. Dies beinhaltet die Erkennung von Entitäten (wie Namen von Personen, Orten oder Dingen) und deren Beziehungen, wodurch die Suchmaschine in die Lage versetzt wird, Ergebnisse abzurufen, die in einem semantischen Zusammenhang mit der Suchanfrage stehen.
- Vorhersage von Suchanfragen: Die Vorhersage, welche Suchanfragen ein Nutzer als Nächstes stellen könnte, ist für Google sowohl im Hinblick auf das Nutzererlebnis als auch auf die Effizienz bei der Bereitstellung von Suchergebnissen sehr interessant. Das Google-Patent „Identification and Issuance of Repeatable Queries“ beschreibt, wie dies funktionieren kann.
Personalisierung
- Nutzerprofil und Verlauf: Wenn der Nutzer eingeloggt ist oder die Suchmaschine Zugriff auf einen Verlauf der Interaktionen des Nutzers hat, kann sie die Verarbeitung der Suchanfrage auf der Grundlage dessen, was sie über die Vorlieben des Nutzers, frühere Suchen und angeklickte Ergebnisse weiß, anpassen.
- Lokalisierung: Die Suchmaschine berücksichtigt den Standort des Nutzers, um lokalisierte Ergebnisse zu liefern, was besonders wichtig für Suchanfragen ist, bei denen der geografische Kontext relevant ist (z. B. Restaurantsuche, Wettervorhersage).
Die Suchabsicht kann je nach Nutzer variieren und sich sogar im Laufe der Zeit ändern, während die lexikalisch-semantische Bedeutung gleich bleibt.
Bei bestimmten Suchanfragen wie offensichtlichen Rechtschreibfehlern oder Synonymen erfolgt eine automatische Verfeinerung der Anfrage im Hintergrund. Als Nutzer können Sie die Verfeinerung der Suchanfrage auch manuell auslösen, sofern Google nicht sicher ist, ob es sich um einen Tippfehler handelt. Bei der Suchanfrageverfeinerung wird eine Suchanfrage im Hintergrund umgeschrieben, um die Bedeutung besser interpretieren zu können.
Neben der Verfeinerung von Suchanfragen umfasst die Verarbeitung von Suchanfragen auch das Parsen von Suchanfragen, das es der Suchmaschine ermöglicht, die Suchanfrage besser zu verstehen. Suchanfragen werden so umgeschrieben, dass auch Suchergebnisse geliefert werden können, die nicht direkt mit der Suchanfrage selbst, sondern auch mit verwandten Suchanfragen übereinstimmen. Mehr dazu hier.
Die Verarbeitung von Suchanfragen kann nach dem klassischen schlagwortbasierten Term x Document Matching oder nach einem entitätsbasierten Ansatz erfolgen, je nachdem, ob Entitäten in der Suchanfrage vorkommen und bereits erfasst sind oder nicht.
Eine ausführliche Beschreibung der Suchanfrageverarbeitung finden Sie in dem Artikel Wie versteht Google Suchanfragen durch die Suchanfrageverarbeitung?
Ranking von Suchergebnissen
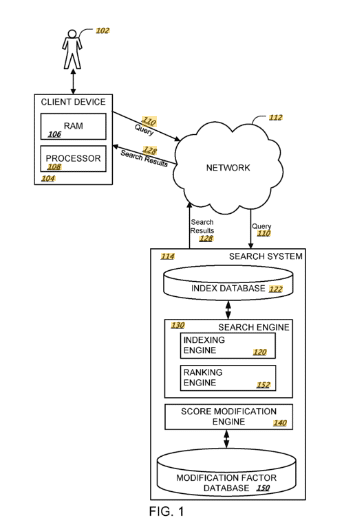
Das Google-Patent „Ranking Search Results“ gibt einige interessante Einblicke, wie Google heute Suchergebnisse bewerten könnte.
- Empfangen einer Suchanfrage: Eine Suchanfrage wird von einem Client-Gerät empfangen.
- Empfang von Suchergebnisdaten: Es werden Daten empfangen, die eine Vielzahl von Suchergebnis-Ressourcen zusammen mit den jeweiligen Anfangswerten für jede Ressource identifizieren.
- Identifizierung von Ressourcengruppen: Jede Suchergebnis-Ressource ist mit einer bestimmten Gruppe von Ressourcen verbunden.
- Bestimmen von Modifikationsfaktoren: Für jede Gruppe von Ressourcen wird ein gruppenbasierter Modifikationsfaktor bestimmt.
- Anpassen der Anfangswerte: Die Anfangsbewertung für jede Suchergebnisressource wird auf der Grundlage des gruppenspezifischen Modifikationsfaktors angepasst, um eine zweite Bewertung für jede Ressource zu generieren.
Zusätzliche Aspekte:
- Bereitstellen von Suchergebnissen: Die Suchergebnisse werden dem Client-Gerät zur Verfügung gestellt, wobei jedes Suchergebnis eine entsprechende Suchergebnis-Ressource identifiziert, die in einer Reihenfolge entsprechend der zweiten Punktezahl präsentiert wird.
- Weitere Anpassungen: Vor der Bereitstellung der Suchergebnisse an das Client-Gerät können weitere Anpassungen an den zweiten Punktwerten vorgenommen werden.
- Ressourcenspezifische Modifikationsfaktoren: Das Verfahren kann die Erzeugung eines ressourcenspezifischen Modifikationsfaktors für jede Suchergebnisressource auf der Grundlage der gruppenbasierten Modifikationsfaktoren beinhalten.
- Navigationsabfragen: Die Anpassungen der Punktzahlen können variieren, je nachdem, ob die Suchanfrage eine Navigation zu einer bestimmten Suchergebnisressource darstellt.
- Schwellenwerte: Die Methode umfasst die Erzeugung ressourcenspezifischer Modifikationsfaktoren, die darauf basieren, ob die anfänglichen Punktzahlen bestimmte Schwellenwerte überschreiten, wobei spezifische Formeln für die Berechnung dieser Faktoren bereitgestellt werden.
- Analyse wiederholter Klicks: Das Verfahren kann auch die Analyse wiederholter Klicks auf Gruppen von Ressourcen beinhalten, um den gruppenbasierten Modifikationsfaktor zu bestimmen, einschließlich der Zählung einmaliger und wiederholter Klicks und der Verwendung von Bruchteilen wiederholter Klicks bei der Berechnung der Modifikationsfaktoren.
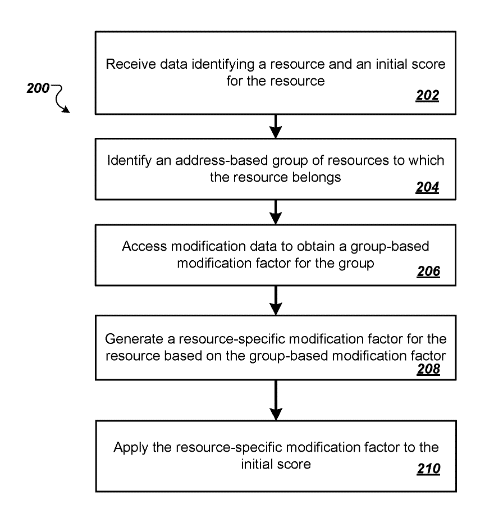
Der Prozess der Identifizierung von Ressourcengruppen und der Anwendung gruppenbasierter Modifizierungsfaktoren deutet auf einen ausgeklügelten Ansatz für das Suchranking hin, der über die Analyse einzelner Seiten hinausgeht. Durch die Berücksichtigung der kollektiven Merkmale oder Verhaltensweisen, die mit Gruppen von Ressourcen verbunden sind, kann die Suchmaschine ihr Ranking so anpassen, dass es der Absicht des Nutzers besser entspricht und das Sucherlebnis insgesamt verbessert wird. Dieser Ansatz könnte auch dazu beitragen, die Herausforderungen im Zusammenhang mit der Vielfalt der Inhalte im Internet zu bewältigen und sicherzustellen, dass qualitativ hochwertige Ressourcen für die Nutzer besser sichtbar sind.
- Auf der Grundlage der Internetadresse: Eine Methode zur Identifizierung der Ressourcengruppe, zu der die einzelnen Suchergebnisressourcen gehören, ist die Verwendung der Internetadresse (URL) der Suchergebnisressource. Dies deutet darauf hin, dass die Kategorisierung auf der Domäne, der Subdomäne, dem Pfad oder anderen URL-Komponenten basieren könnte, die auf eine Gemeinsamkeit zwischen den Ressourcen hinweisen, wie z. B. die Zugehörigkeit zur selben Website, zum selben Thema oder zum selben Inhaltstyp.
- Gruppenspezifische Merkmale: Auch wenn in den bereitgestellten Zusammenfassungen nicht explizit darauf eingegangen wird, beinhaltet die Identifizierung von Ressourcengruppen wahrscheinlich die Analyse von Merkmalen, die die Einzigartigkeit oder Gemeinsamkeit der Gruppe definieren. Dazu könnten die Art des Inhalts (z. B. Blogbeiträge, Nachrichtenartikel, wissenschaftliche Arbeiten), das Thema (z. B. Technologie, Gesundheit, Finanzen) oder andere semantische oder strukturelle Merkmale gehören.
- Zweck der Gruppenidentifizierung: Die Identifizierung von Ressourcengruppen dient dem Zweck, gruppenbasierte Modifikationsfaktoren im Rankingprozess anzuwenden. Durch die Kategorisierung von Ressourcen in Gruppen kann das System Anpassungen an den anfänglichen Bewertungen der Suchergebnisse vornehmen, die auf dem Verhalten oder den Attributen basieren, die mit jeder Gruppe verbunden sind. Dies ermöglicht eine differenziertere und kontextabhängige Einstufung der Suchergebnisse, wodurch die Relevanz und Qualität der den Nutzern präsentierten Ergebnisse verbessert werden kann.
- Verwendung von gruppenbasierten Modifikationsfaktoren: Nach der Identifizierung der Gruppen beinhaltet die Methode die Bestimmung eines entsprechenden gruppenbasierten Änderungsfaktors für jede Gruppe von Ressourcen. Dieser Faktor wird verwendet, um die anfänglichen Punktzahlen der Suchergebnisressourcen anzupassen. Der Modifikationsfaktor kann durch verschiedene Metriken beeinflusst werden, wie z.B. das Engagement der Nutzer mit den Ressourcen der Gruppe, die Glaubwürdigkeit der Quellen innerhalb der Gruppe oder andere Qualitätsindikatoren.
- Verwendung von Metriken: Zur Bestimmung der Änderungsfaktoren werden wahrscheinlich verschiedene Metriken herangezogen, die die Interaktion der Nutzer mit den Ressourcen einer bestimmten Gruppe widerspiegeln. Dazu könnten Metriken wie Klickraten, Verweildauer auf Ressourcen, Absprungraten oder wiederholte Besuchsmuster gehören. Diese Metriken helfen dabei, den Wert, die Relevanz und die Qualität der Ressourcen innerhalb jeder Gruppe zu bewerten.
- Anpassung auf der Grundlage des Nutzerverhaltens: Eine spezifische Methode zur Bestimmung von Änderungsfaktoren beinhaltet die Analyse wiederholter Klicks auf eine bestimmte Gruppe von Ressourcen. Dies beinhaltet die Bestimmung der Anzahl der einmaligen und wiederholten Klicks auf die Ressourcen einer bestimmten Gruppe, die Erstellung eines Anteils der wiederholten Klicks auf der Grundlage dieser Zählungen und die Verwendung dieses Anteils zur Bestimmung des gruppenbasierten Änderungsfaktors. Dieser Ansatz legt nahe, dass das Engagement und die Interaktionsmuster der Nutzer eine wichtige Rolle bei der Anpassung der Rangfolge der Suchergebnisse spielen.
- Anwendung der Modifikationsfaktoren: Sobald diese gruppenbasierten Modifikationsfaktoren bestimmt sind, werden sie verwendet, um die anfänglichen Punktzahlen der Suchergebnisressourcen anzupassen. Der Anpassungsprozess beinhaltet die Anwendung des Modifikationsfaktors in einer Art und Weise, die die Gesamtqualität, die Relevanz oder den Grad der Nutzerzufriedenheit der Gruppe widerspiegelt. Dies könnte bedeuten, dass die Punktzahl von Ressourcen aus Gruppen mit hoher Glaubwürdigkeit oder hohem Engagement erhöht oder die Punktzahl von Ressourcen aus Gruppen mit geringerem Engagement oder geringerer Glaubwürdigkeit verringert wird.
- Dynamische Ranking-Anpassungen: Die Verwendung von Modifikationsfaktoren ermöglicht dynamische Anpassungen der Rangfolge von Suchergebnissen auf der Grundlage von Echtzeit- oder akkumulierten Nutzerinteraktionsdaten. Dieser dynamische Ansatz trägt dazu bei, den Nutzern die relevantesten und qualitativ hochwertigsten Suchergebnisse zu präsentieren und das Sucherlebnis insgesamt zu verbessern.
- Anpassung und Personalisierung: Obwohl nicht explizit erwähnt, könnte die Methodik zur Bestimmung der Änderungsfaktoren auch eine Anpassung oder Personalisierung der Suchergebnisse auf der Grundlage von benutzerspezifischem Verhalten oder Präferenzen ermöglichen, vorausgesetzt, dass Überlegungen zum Datenschutz und zur Zustimmung der Benutzer berücksichtigt werden.
- Qualitäts- und Relevanzverbesserung: Durch die Anpassung der Suchergebnisse auf der Grundlage von gruppenbasierten Modifikationsfaktoren zielt die Suchmaschine darauf ab, qualitativ minderwertige Ressourcen herabzustufen und qualitativ hochwertigere zu fördern, um sicherzustellen, dass die Nutzer mit größerer Wahrscheinlichkeit das finden, was sie suchen, und zwar ganz oben in den Suchergebnissen.
Anpassung der Anfangswerte
- Gruppenbasierte Modifikationsfaktoren: Die Anpassung der Anfangswerte beinhaltet die Anwendung von gruppenbasierten Modifikationsfaktoren, die durch die Analyse der Merkmale und Benutzerinteraktionsmetriken, die mit jeder Gruppe von Ressourcen verbunden sind, bestimmt werden. Diese Modifikationsfaktoren ermöglichen die Verfeinerung der Suchergebnisse über die ursprüngliche Bewertung hinaus, indem sie zusätzliche Dimensionen der Relevanz und Qualität berücksichtigen, die für Gruppen von Ressourcen spezifisch sind.
- Anpassungsprozess: Der Prozess der Anpassung der anfänglichen Scores kann eine Erhöhung oder Verringerung der Scores basierend auf dem gruppenspezifischen Modifikationsfaktor beinhalten. So können beispielsweise Ressourcen, die zu einer Gruppe mit hohem Nutzerengagement und hoher Nutzerzufriedenheit gehören, eine positive Anpassung erhalten, wodurch sich ihr Ranking in den Suchergebnissen erhöht. Umgekehrt könnten Ressourcen aus Gruppen mit niedrigeren Engagement- oder Zufriedenheitsmetriken nach unten angepasst werden.
- Dynamisches und kontextabhängiges Ranking: Die Anpassung der anfänglichen Punktzahlen mit Hilfe von gruppenbasierten Modifikationsfaktoren führt ein dynamisches und kontextbezogenes Element in den Ranking-Prozess ein. Dieser Ansatz ermöglicht es der Suchmaschine, die Rangfolge der Suchergebnisse auf der Grundlage aktueller Benutzerinteraktionstrends und der kollektiven Merkmale von Ressourcengruppen anzupassen, was zu einem relevanteren und personalisierten Sucherlebnis führen kann.
Implikationen und Überlegungen
- Verbesserte Relevanz und Qualität: Durch die Anpassung der anfänglichen Punktzahlen auf der Grundlage gruppenspezifischer Modifizierungsfaktoren will die Suchmaschine die Relevanz und Qualität der den Nutzern präsentierten Suchergebnisse verbessern. Diese Methode hilft bei der Priorisierung von Ressourcen, die nicht nur individuell relevant sind, sondern auch zu Gruppen gehören, die hohe Qualitäts- oder Engagement-Metriken aufweisen.
- Komplexität und Transparenz: Der Prozess der Anpassung der anfänglichen Punktzahlen erhöht die Komplexität des Suchalgorithmus und wirft Fragen bezüglich der Transparenz und der Fähigkeit von Webmastern auf, ihre Inhalte für die Sichtbarkeit in Suchmaschinen zu optimieren. Dies unterstreicht, wie wichtig es ist, qualitativ hochwertige und ansprechende Inhalte zu erstellen, die den Bedürfnissen der Nutzer entsprechen.
- Anpassungsfähigkeit an sich änderndes Nutzerverhalten: Dieser Ansatz ermöglicht der Suchmaschine eine schnellere Anpassung an sich ändernde Nutzergewohnheiten und -präferenzen, da gruppenbasierte Modifikationsfaktoren auf der Grundlage neuer Daten aktualisiert werden können, wodurch sichergestellt wird, dass die Suchergebnisse im Laufe der Zeit relevant und nützlich bleiben.
Das Patent erklärt auch eine Methodik, die das Ranking von Websites Dritter für Navigationsanfragen verhindert:
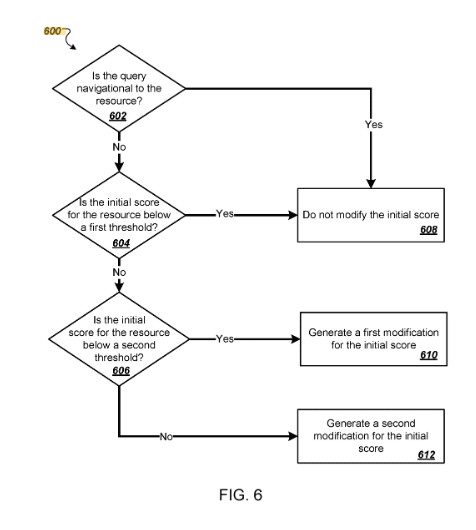
The patent also addresses the use of click data.
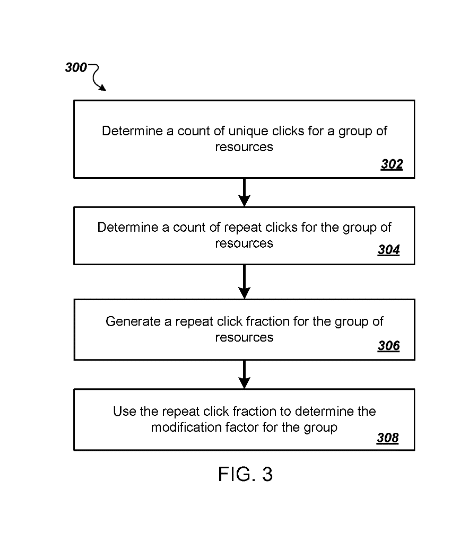
Durchführen einer Analyse der wiederholten Klicks
- Einmalige und wiederholte Klicks: Bei dieser Methode wird zwischen einmaligen Klicks und wiederholten Klicks auf Ressourcen innerhalb einer bestimmten Gruppe unterschieden. Ein einmaliger Klick ist definiert als ein Klick eines einzelnen Nutzers auf ein Suchergebnis, das eine Ressource in der Gruppe identifiziert und damit ein erstes Interesse signalisiert. Ein wiederholter Klick liegt hingegen vor, wenn derselbe Nutzer während verschiedener Suchsitzungen auf ein Suchergebnis klickt, das dieselbe Ressource oder Ressourcen innerhalb derselben Gruppe identifiziert, was auf anhaltendes Interesse oder Zufriedenheit mit der Ressource hindeutet.
- Berechnung der Repeat Click Fraction (RCF): Die Analyse der Klickwiederholung umfasst die Berechnung des Anteils der Klickwiederholung für eine bestimmte Gruppe von Ressourcen. Dieser Anteil wird durch das Verhältnis von wiederholten Klicks zu einmaligen Klicks auf die Ressourcen innerhalb der Gruppe bestimmt. Der RCF liefert ein quantitatives Maß für das Engagement und die Zufriedenheit der Nutzer, wobei davon ausgegangen wird, dass eine höhere Wiederholungsinteraktion einen höheren Wert oder eine höhere Relevanz der Ressourcen für die Nutzer anzeigt.
- Verwendung der RCF zur Bestimmung von Modifikationsfaktoren: Der Anteil der wiederholten Klicks wird dann verwendet, um den gruppenbasierten Änderungsfaktor zu bestimmen. Dieser Faktor passt die anfängliche Bewertung der Suchergebnisressourcen auf der Grundlage des durch den RCF angezeigten Grads der Benutzerinteraktion und -zufriedenheit an. Gruppen mit höheren RCFs können positive Anpassungen erhalten, was ihren höheren wahrgenommenen Wert für die Nutzer widerspiegelt, während Gruppen mit niedrigeren RCFs geringere Anpassungen erhalten können.
Auswirkungen der Analyse wiederholter Klicks
- Verbesserte Relevanz und Qualität: Durch die Einbeziehung der Analyse wiederholter Klicks in den Rankingprozess kann die Suchmaschine die Relevanz und Qualität von Ressourcen aus Nutzersicht genauer bewerten. Diese Methode ermöglicht eine dynamische Anpassung des Suchrankings auf der Grundlage des tatsächlichen Nutzerverhaltens, was zu einem zufriedenstellenderen Sucherlebnis führen kann.
- Dynamische Feedbackschleife: Durch die Analyse der wiederholten Klicks entsteht eine dynamische Feedbackschleife, in der die Interaktionen der Nutzer direkten Einfluss auf das Ranking der Ressourcen haben. Dadurch wird sichergestellt, dass die Suchmaschine auf die Bedürfnisse und Vorlieben der Nutzer eingeht und sich im Laufe der Zeit an das veränderte Nutzerverhalten anpasst.
- Balance zwischen Exploration und Nutzung: Die Methode schafft ein Gleichgewicht zwischen der Notwendigkeit der Exploration (Entdeckung neuer, relevanter Ressourcen) und der Notwendigkeit der Nutzung (Nutzung bekannter, wertvoller Ressourcen). Durch die Anpassung des Rankings auf der Grundlage wiederholter Klicks kann die Suchmaschine besser auf die unmittelbaren Bedürfnisse der Nutzer eingehen und gleichzeitig die Entdeckung neuer Inhalte fördern.
- Fairness und Vielfalt: Die Analyse wiederholter Klicks kann das Ranking hochinteressanter Ressourcen verbessern, erfordert aber auch Mechanismen, die Fairness und Vielfalt in den Suchergebnissen gewährleisten. Dies bedeutet, dass ein Gleichgewicht zwischen der Förderung häufig angeklickter Ressourcen und der Einbeziehung neuer oder weniger bekannter Ressourcen, die für die Suchanfrage ebenso relevant sein können, gefunden werden muss.
Google-Ranking-Systeme
Google unterscheidet hier zwischen den folgenden Rankingsystemen:
- KI-Ranking-Systeme
- Rankbrain
- BERT
- MUM
- Kriseninformationssysteme
- Deduplizierungssysteme
- System der exakten Übereinstimmung von Domänen
- Freshness-System
- System für hilfreiche Inhalte
- Linkanalysesysteme und PageRank
- Lokale Nachrichtensysteme
- Neuronaler Abgleich
- Systeme für ursprüngliche Inhalte
- Auf Entfernung basierende Herabstufungssysteme
- System für Seitenerfahrung
- Passage-Ranking-System
- Produktbewertungssystem
- System für verlässliche Informationen
- System für Seitenvielfalt
- Spam-Erkennungssystem
Ausgeschiedene Systeme
- Hummingbird (wurde weiter entwickelt)
- Mobile friendly ranking system (jetzt Teil des Page experience system)
- System für die Seitengeschwindigkeit (jetzt Teil des Systems für das Seitenerlebnis)
- Panda-System (Teil des Kernsystems seit 2015)
- Penguin-System (Teil des Kernsystems seit 2016)
- System für sichere Websites (jetzt Teil des Seitenerlebnissystems)
Diese Rankingsysteme werden in verschiedenen Prozessschritten der Google-Suche eingesetzt.
Deep Learning Modelle und andere Komponenten für das Ranking
Nach Aussagen von Googles Pandu Nayak im Rahmen des Kartellverfahrens 2023/2024 nutzt Google folgende Deep Learning-Modelle und -Komponenten für das Ranking.
- Rankbrain
- DeepRank
- RankEmbed BERT
- Navboost
- Tangram und Glue

Was ist Rankbrain?
Google RankBrain ist ein Algorithmus mit künstlicher Intelligenz, der Teil des Suchmaschinenalgorithmus von Google ist und Ende 2015 eingeführt wurde. Seine Hauptaufgabe besteht darin, Suchanfragen besser zu verstehen und die Suchergebnisse zu verbessern, insbesondere bei neuen, einzigartigen oder komplexen Anfragen, die Google bisher nicht kannte.
RankBrain nutzt maschinelles Lernen, um Muster in Suchanfragen zu erkennen und die Bedeutung hinter Wörtern zu verstehen. Es zielt darauf ab, die Absicht hinter einer Suchanfrage zu interpretieren, um relevantere Suchergebnisse zu liefern, selbst wenn die genauen Wörter der Anfrage nicht auf den Webseiten vorhanden sind. Dadurch ist RankBrain besonders effektiv bei der Bearbeitung vager oder mehrdeutiger Suchanfragen.
Eine interessante Eigenschaft von RankBrain ist seine Fähigkeit zur Selbstverbesserung. Es lernt kontinuierlich aus Suchanfragen und dem Klickverhalten der Nutzer, um seine Algorithmen zu verfeinern und die Genauigkeit der Suchergebnisse zu erhöhen.
Rankbrain wird nur auf die ersten 20-30 Dokumente angewandt und passt die anfänglichen Punktzahlen dieser Inhalte an. Da Rankbrain sehr teuer ist, wird es nur für eine Vorauswahl von Dokumenten mit den höchsten Anfangswerten verwendet.

Was ist Deeprank?
Google DeepRank wird oft mit RankBrain verwechselt oder in Verbindung mit RankBrain genannt, aber es ist wichtig, zwischen den beiden zu unterscheiden. Während RankBrain eine bekannte Komponente des Google-Algorithmus ist, die sich darauf konzentriert, Suchanfragen durch maschinelles Lernen zu verstehen, bezieht sich DeepRank speziell auf Googles Bemühungen, die Suchergebnisse zu verbessern, indem die Relevanz bestimmter Passagen einer Seite für eine Suchanfrage besser verstanden wird.
DeepRank ist kein separater Algorithmus, sondern vielmehr ein Teil des umfassenderen Suchalgorithmus von Google, der um das Jahr 2020 herum genauer vorgestellt wurde. Sein Schwerpunkt liegt auf der Fähigkeit, einzelne Passagen von Webseiten in den Suchergebnissen zu verstehen und zu bewerten, nicht nur die Seite als Ganzes. Das bedeutet, dass Google selbst dann, wenn ein kleiner Abschnitt einer Seite für eine Suchanfrage sehr relevant ist, diese Passage identifizieren und einstufen kann, so dass die Nutzer die beste Übereinstimmung mit ihren Suchanforderungen finden können, selbst wenn der Rest der Seite ein etwas anderes Thema behandelt.
Deeprank stärkt Rankbrain als unterstützenden Algorithmus. Während BERT das grundlegende KI-Modell ist, stützt sich Deeprank beim Ranking auf BERT.

Die Einführung dieser Technologie war ein großer Fortschritt für die Suchfunktionen von Google, da sie eine feinere Granularität beim Verständnis von Inhalten ermöglicht. Dies ist vor allem bei langen, detaillierten Seiten von Vorteil, bei denen bestimmte Passagen für eine Suchanfrage sehr relevant sein können, auch wenn die Seite ein breiteres Thema behandelt.
Was ist RankEmbed BERT?
RankEmbed BERT ist ein fortschrittlicher Algorithmus, der von Google verwendet wird, um die Relevanz und Genauigkeit von Suchergebnissen zu verbessern, indem die Sprache und der Kontext von Nutzeranfragen besser verstanden werden. Diese Technologie integriert die Fähigkeiten von BERT (Bidirectional Encoder Representations from Transformers), einem Deep-Learning-Algorithmus zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), in den Ranking-Prozess von Google, wobei der Schwerpunkt auf dem Verständnis von Anfragen und Webseiteninhalten liegt.
Innerhalb des Ranking-Systems von Google trägt RankEmbed-BERT neben anderen fortschrittlichen Deep-Learning-Modellen wie RankBrain und DeepRank dazu bei, die endgültige Rangfolge der Suchergebnisse zu bestimmen. Es funktioniert insbesondere in der Phase der Neueinstufung nach dem ersten Aufruf der Ergebnisse. Das Modell wird anhand von Klick- und Abfragedaten trainiert und mit den Erkenntnissen menschlicher Bewerter über die Informationszufriedenheit (IS) verfeinert. Im Vergleich zu einfacheren Feedforward-Modellen wie RankBrain ist das Training von RankEmbed BERT rechenintensiver, was seine hochentwickelten Fähigkeiten zur Verbesserung der Relevanz und Genauigkeit von Suchergebnissen widerspiegelt.
Rankembed BERT wurde vor BERT veröffentlicht und dann mit BERT erweitert. Rankembed BERT wird ebenfalls mit Klick- und Suchdaten trainiert.

NavBoost wurde entwickelt, um die Suchergebnisse für navigationsbezogene Suchanfragen zu verbessern. NavBoost konzentriert sich auf die Verbesserung des Nutzererlebnisses, indem es relevantere und genauere Ergebnisse für solche Suchanfragen liefert. NavBoost analysiert die Benutzerinteraktionen, einschließlich der Klicks, um die relevantesten Ergebnisse zu ermitteln. NavBoost speichert vergangene Klicks für Suchanfragen bis zu 13 Monate (18 Monate vor 2017), um seinen Entscheidungsprozess zu unterstützen.
NavBoost wird auch als „Glue“ bezeichnet, was alle Funktionen auf einer Suchmaschinenergebnisseite (SERP) umfasst, die nicht zu den Webergebnissen gehören, wie z. B. Klicks, Hover, Scrolling und Swipes. Dieses System erzeugt eine gemeinsame Metrik zum Vergleich von Suchergebnissen und Funktionen, was auf eine breitere Anwendung über reine Navigationsanfragen hinaus hindeutet. Der Algorithmus führt eine „Culling“-Funktion durch, um Suchergebnisse auf der Grundlage von Merkmalen wie Standort und Gerätetyp zu trennen und so die Relevanz der Suchergebnisse zu verbessern.
Wenn du tiefer in die Welt des maschinellen Lernens und des Rankings eintauchen möchten, lies meinen Überblick über Patente und Forschung im Bereich Deep Learning & Ranking von Marc Najork.
Wie arbeiten die unterschiedlichen Rankingsysteme zusammen?
Zunächst muss Google im Zuge einer Suchanfrage einen thematisch passenden Korpus von meist Tausenden von Dokumenten zusammenstellen. Aus diesen Tausenden von Dokumenten wählt Google dann einige Hundert Dokumente für ein spezielles Dokumentenscoring aus. Dazu verwendet Google Aktualitätssignale, Page Rank, Lokalisierungssignale…

Dann werden die Deep-Learning-Systeme für das Ranking verwendet.

Das Dokumentenscoring verwendet klassische Information-Retrieval-Signale und Faktoren wie Keywords, TF-IDF, interne und externe Links usw., um die objektive Relevanz eines Dokuments in Bezug auf die Suchanfrage zu bestimmen.
Das Ranking kann dann auf der Basis von Deep-Learning-Systemen erfolgen, die sowohl Nutzerdaten als auch Qualitätssignale oder Signale, die dem E-E-A-T-Konzept zugeordnet werden können, zum Training verwenden. Da diese Signale zur Erkennung von Relevanz-, Kompetenz-, Autoritäts- und Vertrauensmustern verwendet werden, erfolgt das Ranking mit einer zeitlichen Verzögerung.
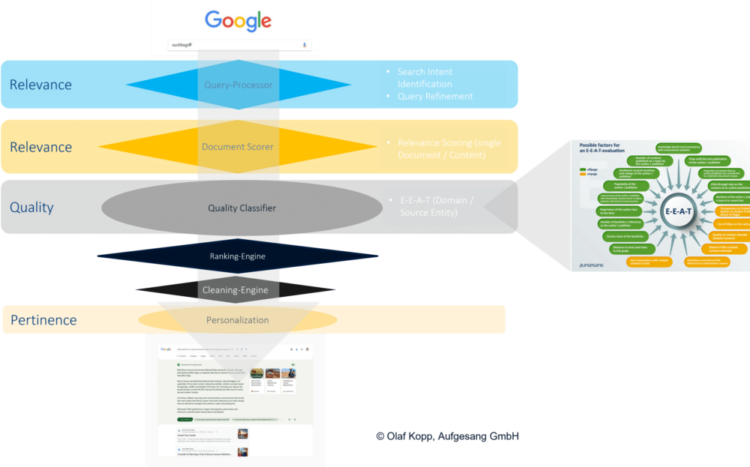
Anhand der Nutzerdaten kann festgestellt werden, welche Art von Inhalten die Nutzer bei einer Suchanfrage bevorzugen. Sind es lange, umfassende Inhalte oder eher kurze Checklisten, Anleitungen oder Definitionen? Daher ist es wichtig, die Suchintentionen nach Micro Intents zu klassifizieren. Siehe meine beiden Artikel How to use 12 micro intents for SEO and content journey mapping und Micro intents and their role in the customer journey.
Ich denke, dass ein iteratives Re-Ranking auf Basis von Nutzerdaten bereits nach wenigen Wochen möglich ist, je nachdem wie schnell Google genügend Nutzerdaten gesammelt hat. Beim Lernen aus E-E-A-T-Signalen dauert es länger, weil das Sammeln von Vertrauensmustern und das Trainieren der Algorithmen viel komplexer ist. Die Core Updates scheinen hier für das Ranking verantwortlich zu sein.
Nach meinem Verständnis bewertet Google auf drei verschiedenen Ebenen. (Mehr dazu im Artikel Die Dimensionen des Google-Rankings)
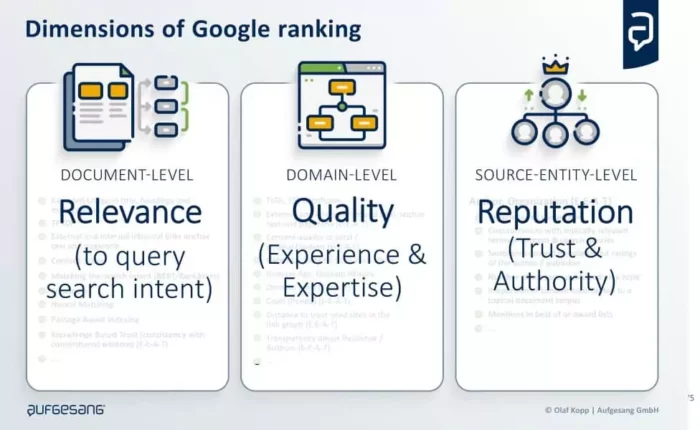
Dokumentenebene:
Auf der Dokumentebene wird der Inhalt hinsichtlich seiner Relevanz für die Suchabsicht bewertet.
Dies kann in mehreren Schritten geschehen. Zunächst wird der Inhalt anhand klassischer Information-Retrieval-Faktoren wie der Verwendung von Schlagwörtern im Fließtext, in Überschriften, Seitentiteln etc. verwendet, um ein Scoring zu erstellen. In einem zweiten Schritt wird der Inhalt auf Basis der Nutzersignale neu klassifiziert. Dazu können die Deep Learning Modelle und Komponenten verwendet werden.
Die Nutzersignale und die Eingaben der Qualitätsbewerter werden verwendet, um ein KI-Modell zu trainieren, das neue Relevanzattribute und damit Muster für das ursprüngliche Ranking identifiziert und die Reihenfolge der Ergebnisse entsprechend der Nutzersignale neu anpasst.
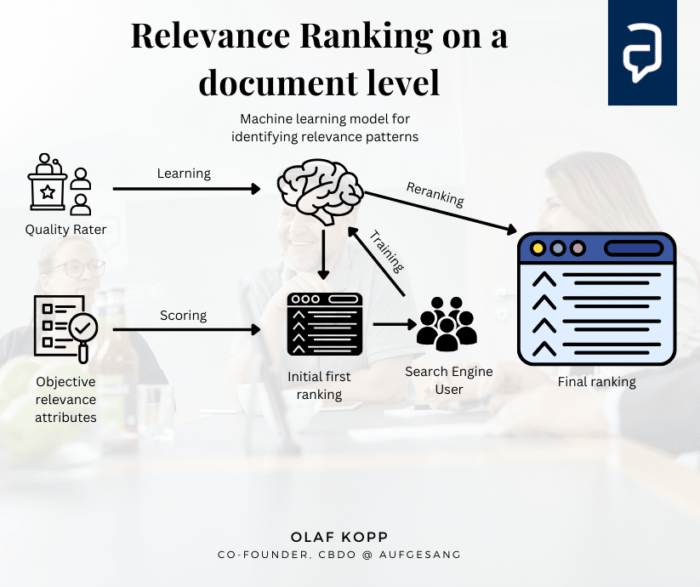
Abgleich von Suchanfrage und Dokumentmerkmalen
- Objektive, von der Suchanfrage unabhängige Bewertung der Relevanz: Dokumente werden danach bewertet, wie gut ihre Merkmale mit den Merkmalen der Suchanfrage übereinstimmen. Diese Bewertung kann komplexe Algorithmen umfassen, die die Häufigkeit und Position von Schlüsselwörtern im Dokument, die allgemeine thematische Relevanz des Dokuments und die Qualität des Inhalts berücksichtigen.
- Abfrageabhängige Ranking-Faktoren: Neben dem grundsätzlichen Matching berücksichtigt die Suchmaschine auch anfrageabhängige Faktoren wie den Standort des Nutzers, das verwendete Gerät, Personalisierungseinstellungen oder die Suchhistorie, die die Relevanz von Dokumenten für die jeweilige Anfrage beeinflussen können.
Nutzung früherer Interaktionen
- Lernen aus dem Nutzerverhalten: Verwendung von Aktionen, die mit Dokument- und Abfragemerkmalen verknüpft sind, auf der Grundlage früherer Interaktionen. Dies bedeutet, dass die Suchmaschine lernt, wie Benutzer in der Vergangenheit mit Dokumenten interagiert haben (Klickraten, Verweildauer auf einer Seite usw.), um vorherzusagen, welche Dokumente für eine bestimmte Anfrage relevanter oder nützlicher sein könnten.
- Anpassung der Rangfolge: Die Relevanzwerte und die Rangfolge der Dokumente können auf der Grundlage des gelernten Verhaltens angepasst werden, wobei Dokumente, die in der Vergangenheit ähnliche Suchanfragen beantwortet haben, bevorzugt werden.
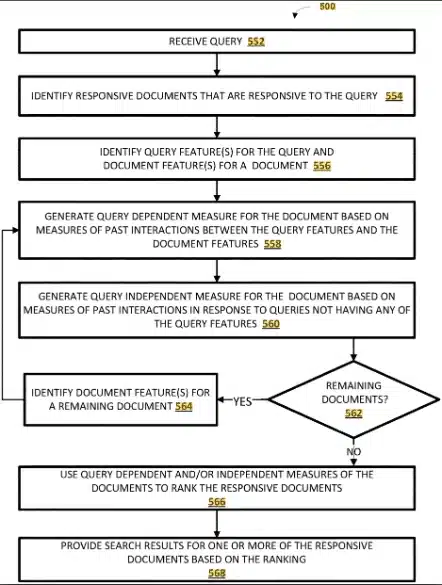
Ranking search result documents, US10970293B2
Die Signale der Nutzer, die Google erhält, werden verwendet, um die Ranking-Algorithmen zu trainieren, insbesondere die Algorithmen des maschinellen Lernens, die die Ergebnisse neu ordnen. Wie das genau funktioniert, können Sie in meiner Zusammenfassung des Patents Training a Ranking Model nachlesen.
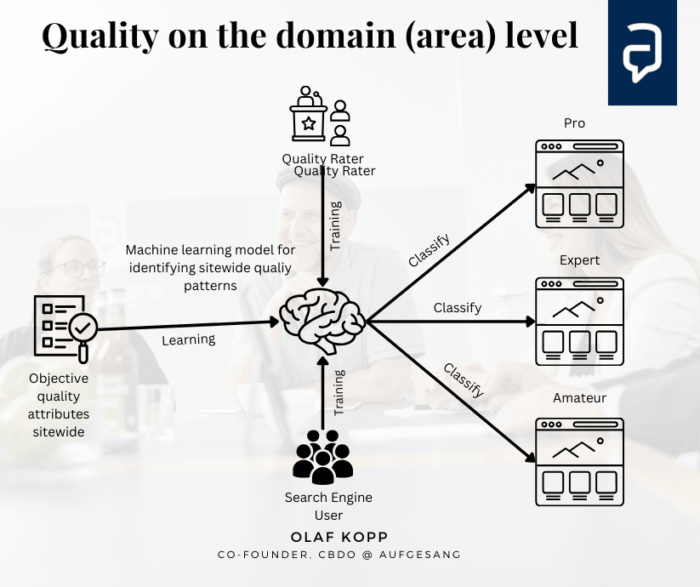
Sitewide Website-Bereich und Domain-Ebene
Auf der Domain-Ebene werden Website-Bereiche oder ganze Domains nach Erfahrung und Expertise in ihrer Qualität eingestuft. Das Help Content System, https, Page Experience … können hier eine Rolle spielen.
Wie im Patent Website Representation Vectors beschrieben, können diese Websites dann in verschiedene Kompetenzstufen in Bezug auf bestimmte Themen klassifiziert werden.
Auch hier können Deep-Learning-Modelle eingesetzt werden, um Muster für qualitativ hochwertige Autoren und thematische Autorität zu erkennen.
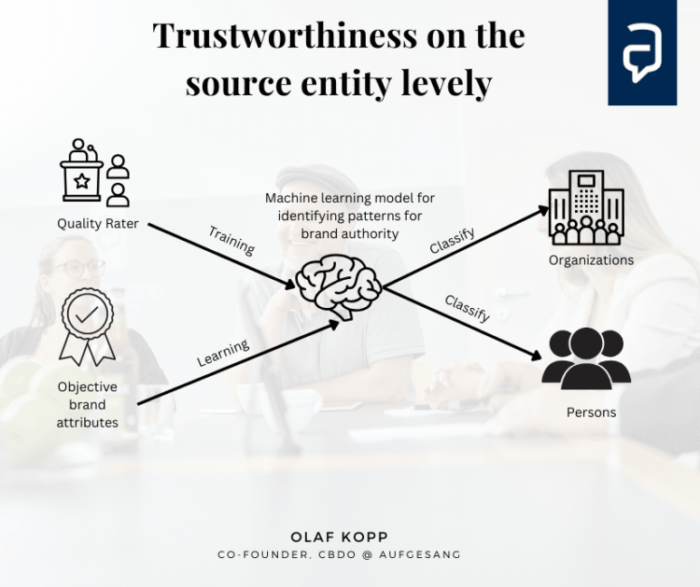
Source Entity Ebene
Auf dieser Ebene kann Google den Autor in Form von Organisationen und Autoren in Bezug auf Autorität und Reputation bewerten. In dem Artikel Die interessantesten Google-Patente und wissenschaftlichen Arbeiten auf E-E-A-T finden Sie viele fundierte Recherchen zu Patenten und wissenschaftlichen Arbeiten.
Die Eingaben der Qualitätsbewerter sowie objektive Signale für die Autorität einer Marke werden zum Lernen und Trainieren eines KI-Modells verwendet.
Eine Übersicht über mögliche Signale, insbesondere für die Auswertung auf Domänen- und Entitätsebene, finden Sie hier:
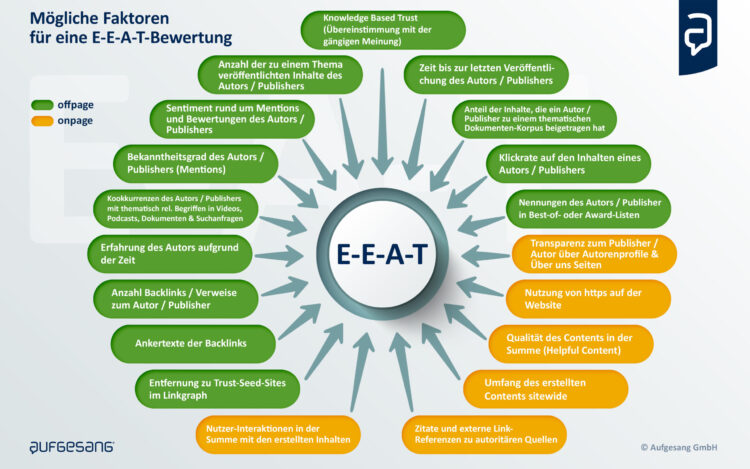
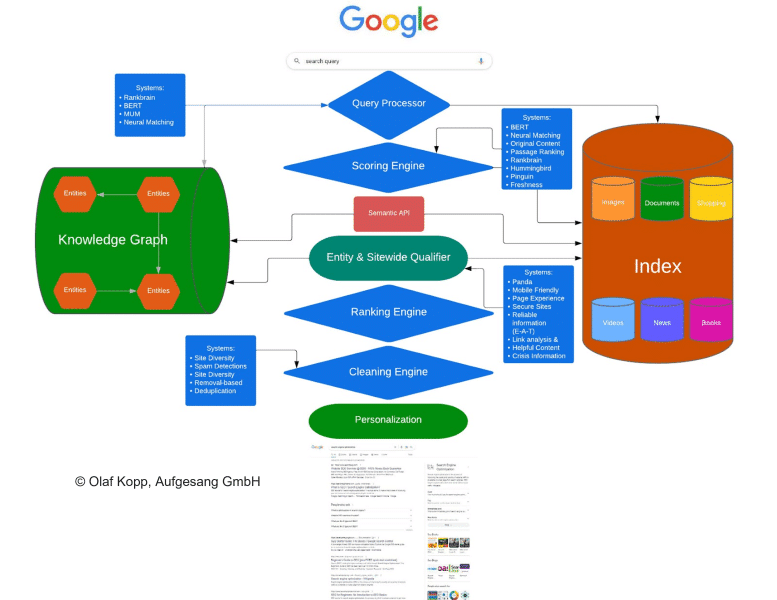
Schließlich versuche ich, die vielen Informationen von Google über die Funktionalität ihrer Suchmaschinen in ein Gesamtbild zu bringen.
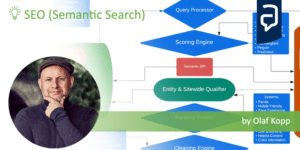
Für die Interpretation von Suchanfragen, die Identifikation von Suchintentionen, das Query Refinement, das Query Parsing und das Search Term Document Matching ist ein Query Processor zuständig.
Der Entity Processor oder Semantic API bildet die Schnittstelle zwischen dem Knowledge Graph und dem klassischen Suchindex. Diese kann für Named Entity Recognition und Data Mining für den Knowledge Graph bzw. Knowledge Vault genutzt werden, z.B. über Natural Language Processing. Mehr dazu im Artikel „Natural Language Processing to build a semantic database„.
Für das Google-Ranking sind eine Scoring Engine, ein Entity- und Sitewide Qualifier und eine Ranking Engine zuständig. Bei den Rankingfaktoren unterscheidet Google zwischen anfrageabhängigen (z.B. Keywords, Proximity, Synonyme…) und anfrageunabhängigen Rankingfaktoren (z.B. PageRank, Sprache, Page Experience…). Ich würde noch zwischen dokumentbezogenen Rankingfaktoren und domänen- bzw. entitätsbezogenen Rankingfaktoren unterscheiden.
Bei der Scoring Engine findet eine Relevanzbewertung auf Dokumentenebene in Bezug auf die Suchanfrage statt. Beim Entity- und Sitewide-Qualifier geht es um die Bewertung des Herausgebers bzw. Autors sowie die Qualität des Inhalts insgesamt in Bezug auf Themen und UX der Website (Domains).
Die Ranking Engine fasst die Punkte aus der Scoring Engine und dem Entity- und Sitewide-Qualifier zusammen und erstellt ein Ranking der Suchergebnisse.
Eine Cleaning Engine sortiert doppelte Inhalte aus und bereinigt die Suchergebnisse von Inhalten, die einen Penalty erhalten haben.
Ein Personalization Layer schließlich berücksichtigt Faktoren wie die Suchhistorie oder bei regionalen Suchintentionen den Standort oder andere lokale Rankingfaktoren.
Mehr dazu wie die Google-Suche heute funktioniert:


- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























4 Kommentare
Wow. So viele wertvolle Infos! Eine kurze, spezifische Frage zum Thema Crawling-Budget: Würde eine völlig neue Webseite, die durch einzigartige Lösungen & Content zahlreiche vertrauenswürdige Backlinks generiert, direkt von einem stärkeren Crawling-Budget genießen?
Ich freue mich auf Euer Feedback!
Hi Julius, ganz kurz und knapp- Ja!
Hallo Herr Kopp,
Ihr Artikel bietet durch seinen Umfang aber gleichzeitig verständliche Formulierungen und anschauliche Grafiken umfassende und hilfreiche Erklärungen zur Funktion der Google-Suche!
Vielen Dank für diese tieferen Einblicke.
Beste Grüße
Antonia
Lieber Olaf Kopp, euer Artikel „Die Google Suche: So funktioniert die Suchmaschine heute“ auf SEM Deutschland bietet einen tiefen Einblick in die Funktionsweise von Google und die Bedeutung von SEO. Eure detaillierte Analyse und die Zusammenführung von Informationen aus verschiedenen Quellen, einschließlich Google-Patenten, ist beeindruckend und ungemein hilfreich. Vielen Dank für das Teilen eurer Expertise und die Bereitstellung eines so wertvollen Ressourcen für alle, die im digitalen Marketing tätig sind.