
Google wurde im Mai 2020 ein Patent erteilt, bei dem es um eine Suchmaschine geht, die Keyword-Suchen (oder das Auffinden einer Entität) in einer vertikalen Suchmaschine für Apps auf mobilen Geräten durchführen kann, die solche Funktionalitäten abdecken kann:
(i) Persönliche Inhalte wie Kontakte, Nachrichten, Anrufverlauf, Dokumente, Notizen, Kalenderereignisse oder ähnliches
(ii) Anwendungsspezifischer Inhalt, der von der Anwendung für den Verbrauch durch den Benutzer bereitgestellt wird
(iii) anwendungsspezifischer Inhalt, der von der Anwendung bereitgestellt wird und auf Benutzerinteraktion reagiert, oder
(iv) Eine Kombination davon
Das Patent sagt uns, dass es für eine solche Suchmaschine möglich ist:
…cluster application content items into one or more different groups such as a topic, task, or the like that can be provided in response to a search query
Diese Art des Clustering sehen wir bei Google News, wo Artikel tendenziell zu bestimmten Themen gebündelt werden.
Das hört sich an, als könnte es sich um eine neue vertikale Suche bei Google handeln, ähnlich wie Google die Ergebnisse in separaten vertikalen Suchen wie Karten, Nachrichten, Bilder, Videos, Finanzen, Wissenschaftler organisiert hat. Man sieht inzwischen auch, wie Google verschiedene vertikale Suchergebnisse in einer „Alle“-Kategorie kombiniert hat, wie in den Ergebnissen der Universal Search.
Google hat Suchergebnisse für verschiedene Arten der vertikalen Suche unterschiedlich eingerichtet, und dieses Patent zeigt uns, dass eine vertikale Suche für Apps auch unterschiedlich eingerichtet sein kann. Sie verfügt möglicherweise über Steuerelemente, die auf Anwendungen basieren und nach Anwendungstyp und Themen oder Aufgaben organisiert sein können, die mit jeder der nativen Apps verknüpft sind.
Im Folgenden wird im Patent beschrieben, wie eine solche vertikale Suche Ergebnisse anzeigen könnte:
The method may include actions of receiving, by a search engine implemented on a user device and for each of multiple native applications on the user device, a set of data that is generated by the native application and that includes
(i) native application content, and
(ii) context information associated with the native application content, for each set of data that is generated by the native applications, generating, by the search engine implemented on the user device, a cluster feature-vector representation based on the set of data, storing, by the search engine implemented on the user device, the cluster feature-vector representations in a search engine index on the user device, identifying, by the search engine implemented on the user device, a set of cluster feature-vector representations that are associated with a particular feature-vector representation, identifying, by the search engine implemented on the user device, one or more topics or tasks that are associated with the set of cluster feature-vector representations, and providing, for output, a user interface including a selectable control that identifies one or more of the topics or tasks.
Dieses Patent findest Du unter
Suchmaschine
Erfinder: Timo Mertens und Maxim Gubin
Bevollmächtigter: Google LLC
US-Patent: 10,650,068
Gewährt: 12. Mai 2020
Gespeichert: 9. Januar 2017
Kurzfassung:
Methods, systems, and apparatus, including computer programs encoded on a computer-storage medium, for using a search engine implemented on a user device to identify topics or tasks associated with native application content. The method may include actions of receiving a set of data that is generated by the native application and that includes (i) native application content, and (ii) context information associated with the native application content, generating a cluster feature-vector representation based on the set of data, storing the cluster feature-vector representations in a search engine index on the user device, identifying a set of cluster feature-vector representations that are associated with a particular feature-vector representation, identifying one or more tasks that are associated with the set of cluster feature-vector representations, and providing, for output, a user interface including a selectable control that identifies one or more of the tasks.
Inhaltsverzeichnis
Welche Art von Apps eine vertikale Suchmaschine abdecken kann
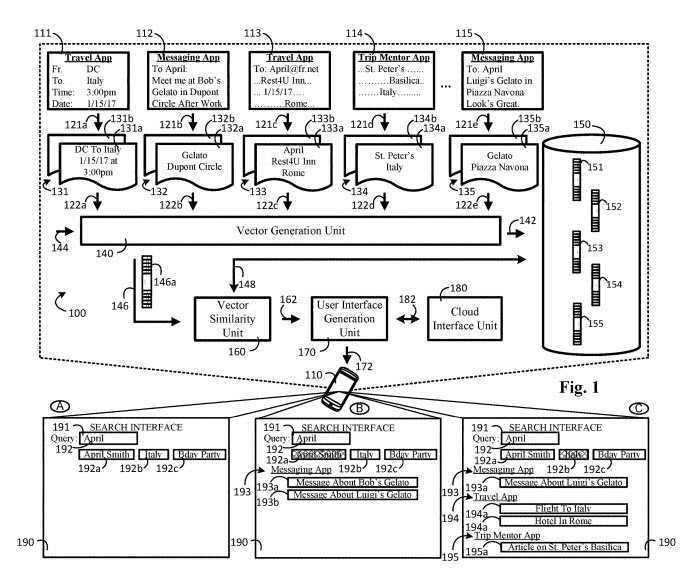
Das Patent listet eine Reihe der verschiedenen Arten von nativen Apps auf, die diese vertikale Suchmaschine abdecken könnte, darunter die folgenden mobilen Apps:
- Reise-Apps
- Messaging-Apps
- Bewerbung als Reise-Mentor
- Kalender-Apps
- Apps zur Dokumentverarbeitung
- Bewerbung der Kontakte
- Apps für Sprachanrufe
- Apps für Notizen
- Apps für eine Enzyklopädie
- Ähnliches
Daten, die eine vertikale Suche für native Apps finden kann
Das Patent weist darauf hin, dass jede native App entsprechende Datensätze erzeugt, und liefert mindestens ein detailliertes Beispiel. Diese Datensätze werden auf der Grundlage von Benutzerinteraktionen mit den nativen Apps generiert.
Dies ist ein Beispiel:
The sets of data may include native application content and context information. For example, a user may interact with the travel app to book an airline ticket from Washington, D.C. to Italy that is scheduled to depart on Jan. 15, 2017 at 3:00 pm. Based on this user interaction, the native application may generate a set of data that includes native application content such as native application content that was interacted with by the user. In this instance, the trip origin (e.g., DC), the trip destination (e.g., Italy), the trip departure date (e.g., Jan. 15, 2017), and the trip departure time (e.g., 3:00 pm) each individually, or together, are examples of one or more native application content items that were interacted with by the user, as the user-created the aforementioned application content. Other forms of user interaction with native application content items may include a user editing native application content, a user viewing native application content, a user hearing native application content, or the like. The search engine may extract one or more features from the native application content to generate a cluster feature-vector that represents the user’s interaction or consumption of one or more native application content items.
Zusätzlich zu dieser großen Menge an Daten aus Benutzerinteraktionen wird die Suchmaschine Daten aus einem Benutzerprofil für die Person, die mit der nativen Anwendung interagiert, sammeln und einbeziehen.
Dies ist ein weiteres Beispiel für die Arten von Daten, die in eine Suchmaschine für native Apps aufgenommen werden könnten (sie kann einen wirklich großen Bereich abdecken, je nachdem, was jede Anwendung tut):
Data that is indicative of a field that is associated with native application content a user interacted with may include, for example, a “To:” field of a message, a “Subject” field of a message, a “Body” field of a message, a “Destination” field of a flight reservation, a “Date” field of a hotel reservation, a “Title” field of an article, or the like. Data that is indicative of user activity with a native application may include, for example, data that is indicative of a number of interactions a user has with a native application, data that is indicative of other native applications the user interacted with while using the native application, data that is indicative of a native application the user used prior to the native application, data that is indicative of a native application the user used after the native application, data that is indicative of patterns of switching between native applications by a user of a user device, and the like.
Data that is indicative of native application content creation time may include, for example, a timestamp that indicates when a user created the application content. Data that is indicative of native application content interaction time may include, for example, data that is indicative of the time a user interacted with native application content. For example, interaction time may include a timestamp that is indicative of the time a user viewed native application content in a native application. The number of application interactions may include the number of times a user interacted with a particular native application.
The number of times a user interacted with a particular native application may include:
(i) data indicative of a particular number of total application interactions with the user,
(ii) data indicative of a particular number of total application interactions within a predetermined time period, or
(iii) a combination thereof. For example, the number of application interactions may include data that indicates a user opened the notes application 20 times, a user opened a travel application 46 times over the past week, or the like.
Verwendung verschiedener nativer Anwendungen für das gleiche Thema
Aus dem Patent geht hervor, dass manchmal mehr als eine native App die gleichen Themen oder Aufgaben abdecken kann. Sie können beinhalten:
- Eine Reihe von mehreren Nachrichten, die an denselben Empfänger gesendet wurden
- Ein Satz von mehreren Nachrichten an verschiedene Empfänger, die sich auf dasselbe Thema beziehen
- Ein Satz von mehreren unterschiedlichen Arten von App-Inhaltselementen, die sich auf dasselbe Thema beziehen
oder dergleichen
Inhalte aus mehreren nativen App-Inhalten, die sich auf dieselbe Aufgabe beziehen, können sich auf denselben Zweck, dasselbe Ziel oder ähnliches beziehen. Zum Beispiel eine Reise nach Italien. Dazu können gehören:
- Buchung einer Flugreservierung nach Italien über eine Reise-App
Buchen einer Hotelreservierung in Rom über eine Reise-App (entweder die gleiche oder eine andere Reise-App) - Überprüfung von Beschreibungen von Reisezielen mit Hilfe einer Trip Mentor App
- Suche nach Restaurants oder Fachgeschäften (z.B. ein Eiskaffee) in Rom mit Hilfe einer Suchmaschine
- Versenden von Nachrichten über Fachgeschäfte (z.B. ein Eiskaffee), die der Benutzer in Rom besuchen möchte
- der Ehepartner des Benutzers eines Messengers
Diese große Menge an Informationen kann gebündelt und dann zur Erzeugung eines Cluster-Feature-Vektors verwendet werden. Oder Cluster-Feature-Vektoren können auf der Grundlage von Entitäten generiert werden, die durch den Text des nativen App-Inhalts identifiziert werden.
Diese können Merkmale aus enthalten:
- Namen von Kontaktpersonen
- Namen von Nicht-Kontaktpersonen
- Ortsnamen
- Namen der Länder
- Namen der Städte
- Namen von Unternehmen
- Ähnliches
Es können auch Daten über die Nutzung verschiedener nativer Anwendungen und Muster, die die Nutzer einbeziehen, ermittelt werden.
Indexierung für eine vertikale Suche für Apps auf Basis von Cluster-Feature-Vektoren
Jeder im Suchmaschinenindex gespeicherte Cluster-Feature-Vektor kann zur Identifizierung eines nativen App-Inhalts-Elementen (z. B. einer Nachricht) verwendet werden, auf dem der Cluster-Feature-Vektor basiert.
Anstatt oder zusätzlich zur Durchführung einer Stichwortsuche auf der Grundlage von App-Inhaltselementen kann das Benutzergerät daher die Suchmaschine verwenden, um eine Vektorähnlichkeitssuche der im Suchmaschinenindex gespeicherten Cluster-Feature-Vektoren durchzuführen.
Wir haben gesehen, dass verschiedene vertikale Suchmaschinen unterschiedliche Signale für das Ranking und die Indexierung verwenden. Diese vertikale Suchmaschine für Apps verwendet einen Cluster-Feature-Vector-Ansatz, um Inhalte aus verschiedenen nativen Apps zu bewerten und zu indexieren.
Dieses Patent sagt uns, wie eine solche Suchmaschine funktionieren könnte und wie Daten aus diesen Cluster-Feature-Vektoren im Cache gespeichert werden oder im Hintergrund einen Stapelverarbeitungsansatz verwenden könnten. Es ist möglich, dass diese Art von Cluster-Feature-Vektor-Ansatz auf einzelnen mobilen Geräten verwendet werden kann, und eine Echtzeit-Generierung dieser Cluster-Feature-Vektoren könnte rechenintensiv sein und einen Großteil der Batterie von Telefonen und Tablets verbrauchen.
Eine Echtzeit-Generierung solcher Vektoren zum Indexieren und Einordnen von Inhalten könnte jedoch robuster und genauer sein. Sie würde Daten über die jüngsten Interaktionen mit nativen Anwendungen enthalten.
Fazit
Diese vertikale Suchmaschine für native Apps wäre eine nette Ergänzung zur bisherigen Google-Suche und könnte den Nutzern mobiler Geräte helfen, die Informationen zu durchsuchen, auf die sie in ihren Anwendungen zugegriffen haben. Ich würde es begrüßen, wenn ich Reiseinformationen und Anordnungen zu Reisen nachschlagen könnte, die ich geplant habe.
Ich erinnere mich an das, was Google in Bezug auf maschinelles Lernen für mobile Geräte beschrieben hat: Federated Learning: Collaborative Machine Learning without Centralized Training Data.
Federated Learning enables mobile phones to collaboratively learn a shared prediction model while keeping all the training data on device, decoupling the ability to do machine learning from the need to store the data in the cloud. This goes beyond the use of local models that make predictions on mobile devices (like the Mobile Vision API and On-Device Smart Reply) by bringing model training to the device as well.
Ein Problem bei einer anwendungsspezifischen vertikalen Suchmaschine besteht darin, dass die darin enthaltenen Daten so stark von der Interaktion des Benutzers mit seinen mobilen Geräten abhängen. Es ist fragwürdig, wie sehr sich die Menschen wünschen, dass diese Informationen möglicherweise von anderen Personen gesehen oder verwendet werden.
Das erinnert mich an das Patent, über das ich in meinem Beitrag über User-Specific Knowledge Graphs to Support Queries and Predictions geschrieben habe.
Google hat Zugriff auf eine Menge Daten über Personen.
Es könnte für Personen, die es nutzen, wirklich nützlich sein.
Google sammelt möglicherweise zu viele Informationen für viele potenzielle Nutzer.
Dieser Artikel wurde mit der Erlaubnis von Bill Slawski übersetzt und veröffentlicht. Der Orginal-Beitrag lautet A Native Application Vertical Search Engine at Google .

- Google-Patent beschreibt ein Machine-Learning-Modell für einen durchsuchbaren Index - 6. April 2021
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise - 15. Dezember 2020
- Personalisierte Knowledge Graphen: Dahin kann die Reise gehen! - 24. November 2020
- Wie Google Textpassagen für Featured Snippets nach dem Kontext auswählen kann - 2. November 2020
- Wie Google Ergebnisse für ein Featured Snippet auswählen kann - 29. September 2020

























Ein Kommentar