Der Google Knowledge Vault war ein Projekt von Google, das darauf abzielte, eine umfangreiche Wissensdatenbank zu erstellen, die automatisch Informationen aus dem Internet extrahiert und in eine strukturierte Form bringt. Es wurde als Nachfolger von Google Knowledge Graph gesehen, das eine ähnliche Funktion hat, aber hauptsächlich auf manuell kuratierten Datenquellen basiert.
Die Wahrheit ist, dass Google den Knowledge Vault seit 2015 nicht mehr erwähnt hat.
Wir wissen nicht, ob der KV jemals Teil der Google-Infrastruktur war oder noch ist.
Aber der ursprüngliche Ansatz und das Ziel, das der Knowledge Vault verfolgte, sind nach wie vor aktuell.
Nämlich die Extraktion und das Verständnis von unstrukturierten Daten für das Mining von Long-Tail-Wissen.

Die große Herausforderung bei der algorithmischen Zusammenstellung einer Wissensdatenbank besteht darin, den Faktoren Vollständigkeit und Genauigkeit gleichermaßen Rechnung zu tragen. Die Hauptaufgabe des Knowledge Vault ist das Data Mining über Entitäten, einschließlich Lontail-Entitäten, die nicht im Knowledge Graph erfasst sind.
Knowledge Vault sollte automatisch Fakten sammeln und die Vertrauenswürdigkeit dieser Informationen durch maschinelles Lernen und Verstehen von Text aus dem Internet bewerten. Ziel war es, eine breitere Informationsbasis zu haben, die für verschiedene Google-Dienste genutzt werden kann, etwa zur Verbesserung der Suchergebnisse oder zur Bereitstellung von Informationen für Google Assistant.
Das System sollte in der Lage sein, Fakten mit einer bestimmten Wahrscheinlichkeit als wahr oder falsch einzustufen, basierend auf der Zuverlässigkeit der Quellen und der Konsistenz der Informationen aus verschiedenen Quellen. Es ist jedoch wichtig zu beachten, dass Google regelmäßig an verschiedenen Forschungs- und Entwicklungsprojekten arbeitet und die genauen Details und der aktuelle Status von Knowledge Vault ohne aktuelle Informationen von Google selbst nicht bekannt sind.
Inhaltsverzeichnis
Was wissen wir über den Knowledge Vault?
Der Knowledge Vault wurde 2013 von Google eingeführt und ist seither ein Geheimnis. Seitdem gab es kaum weitere Informationen. Deshalb möchte ich hier alle offiziellen Informationen zusammentragen und meine eigenen Gedanken dazu beitragen.
Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion
Das Konzept und die Idee des Knowledge Vault basiert auf dem Papier „Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion“ (Ein webbasierter Ansatz zur probabilistischen Wissensfusion).
Das Dokument beschreibt die Erstellung des Knowledge Vault (KV), einer webbasierten probabilistischen Wissensdatenbank. Die Autoren, Xin Luna Dong et al., gehen auf die Grenzen bestehender großer Wissensdatenbanken wie Wikipedia, Freebase, YAGO, Microsofts Satori und Googles Knowledge Graph ein. Diese Wissensdatenbanken sind trotz ihrer Größe bei weitem nicht vollständig und leiden unter einem Mangel an Informationen über viele Entitäten und Beziehungen.
Der Knowledge Vault zielt darauf ab, die Erstellung von Wissensdatenbanken durch die automatische Extraktion von Fakten aus dem Internet zu verbessern, wobei eine Vielzahl von Quellen wie Text, Tabellendaten, Seitenstruktur und menschliche Anmerkungen verwendet werden. Es nutzt überwachte Methoden des maschinellen Lernens, um diese verschiedenen Informationsquellen zusammenzuführen. Der KV ist wesentlich größer als alle bisher veröffentlichten strukturierten Wissensspeicher und enthält 1,6 Milliarden Tripel, von denen 324 Millionen eine Konfidenz von 0,7 oder höher und 271 Millionen eine Konfidenz von 0,9 oder höher aufweisen. Dies entspricht etwa 38 Mal mehr vertrauenswürdigen Fakten als das größte vergleichbare System zu dieser Zeit.
In dem Papier werden die Herausforderungen beim Aufbau der KV erörtert, wie z. B. die Modellierung gegenseitiger Ausschlüsse zwischen Fakten und die Darstellung einer großen Vielfalt von Wissenstypen. Es wird auch das Potenzial für weitere Verbesserungen angesprochen, wie z. B. die Erweiterung des Schemas, um mehr im Web erwähnte Beziehungen zu erfassen und den langen Schwanz von Konzepten zu behandeln, die in einer festen Ontologie nur schwer zu erfassen sind. Die Autoren bieten einen detaillierten Vergleich der Qualität und des Nutzens verschiedener Informationsquellen und Extraktionsmethoden und schlagen vor, dass künftige Arbeiten Crowdsourcing-Techniken einbeziehen könnten, um Wissen mit gesundem Menschenverstand zu erwerben, das nicht im Web verfügbar ist.
Der Knowledge Vault zeichnet sich dadurch aus, dass er verrauschte Extraktionen mit Vorwissen aus bestehenden Wissensdatenbanken kombiniert und ein strukturierter, sprachunabhängiger Wissensspeicher ist. Er nutzt ein probabilistisches Inferenzsystem, um kalibrierte Wahrscheinlichkeiten für die Korrektheit von Fakten zu berechnen. Die in diesem Beitrag vorgestellte Arbeit leistet einen Beitrag zu diesem Gebiet, indem sie einen skalierbaren Ansatz für die Erstellung von Wissensdatenbanken bietet, der den Umfang des für verschiedene Anwendungen verfügbaren menschlichen Wissens erheblich erweitern kann.
Knowledge Vault und Knowlege-Based Trust
In einem sehr interessanten Vortrag von XIN Luna Don an der Stanford University im Jahr 2015 über wissensbasiertes Vertrauen wurde auch der Knowledge Vault erwähnt. Die Präsentation basiert auf dem Papier mit dem Titel „Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources“ von XIN Lunda Don und Kollegen.
In dem Papier wird ein neuartiger Ansatz zur Bewertung der Qualität von Webquellen vorgestellt. Statt sich auf externe Signale wie Hyperlinks und den Browserverlauf zu verlassen, schlagen die Autoren eine Methode vor, die sich auf die Korrektheit der von einer Quelle bereitgestellten faktischen Informationen stützt und als Knowledge-Based Trust (KBT) bezeichnet wird.
KBT bewertet die Vertrauenswürdigkeit durch die Extraktion von Fakten aus Webquellen mit Hilfe von Informationsextraktionstechniken, die typischerweise zum Aufbau von Wissensdatenbanken wie Googles Knowledge Vault (KV) verwendet werden. KV extrahiert strukturierte Informationen aus dem Internet, um mit Hilfe von 16 verschiedenen Extraktionssystemen eine umfangreiche Datenbank mit Fakten aufzubauen. Diese extrahierten Fakten sind Tripel (Subjekt, Prädikat, Objekt) und werden automatisch verarbeitet, um eine Wissensdatenbank zu bilden. Die Autoren erkennen an, dass Fehler bei der Extraktion häufiger vorkommen als sachliche Fehler auf Webseiten, und diese müssen unterschieden werden, um die Vertrauenswürdigkeit einer Quelle genau zu beurteilen.
In dem Beitrag wird ein mehrschichtiges probabilistisches Modell vorgestellt, das zwischen faktischen Fehlern in der Quelle und Fehlern im Extraktionsprozess unterscheidet. Diese Unterscheidung ist entscheidend für die zuverlässige Berechnung der Vertrauenswürdigkeit von Webquellen. Die Autoren stellen einen effizienten, skalierbaren Algorithmus zur Durchführung von Inferenz und Parameterschätzung innerhalb dieses probabilistischen Modells vor.
Die Effektivität des Modells wird durch seine Anwendung auf einen großen Datensatz demonstriert, der 2,8 Milliarden extrahierte Tripel aus dem Web umfasst und die Einschätzung der Vertrauenswürdigkeit von 119 Millionen Webseiten ermöglicht. Die Beiträge der Arbeit lassen sich wie folgt zusammenfassen:
Ein ausgeklügeltes probabilistisches Modell zur Unterscheidung zwischen faktischen und Extraktionsfehlern.
Eine adaptive Methode zur Entscheidung über die Granularität der Quellen, um die Effizienz der Berechnungen zu verbessern.
Eine groß angelegte Evaluierung, die die Wirksamkeit des Modells bei der Vorhersage der Vertrauenswürdigkeit von Webseiten zeigt.
Die Autoren diskutieren auch das Potenzial des KBT-Scores als zusätzliches Signal für Suchmaschinen, um die Qualität von Webseiten zu bewerten und die Suchergebnisse zu verbessern. Sie schlagen vor, dass dieser Ansatz über die Wissensextraktion hinaus auf andere Aufgaben der Datenintegration und Datenbereinigung ausgedehnt werden kann.
Insgesamt bietet das Papier eine innovative Lösung für die Herausforderung, die Zuverlässigkeit von Webquellen auf der Grundlage der sachlichen Korrektheit ihres Inhalts automatisch zu bestimmen, wobei die riesige Menge an im Web verfügbaren Informationen und die darin enthaltene Redundanz genutzt werden, um eine Vertrauenswürdigkeitsbewertung zu erstellen.
Wissensbasiertes Vertrauen könnte auch ein Signal im Kontext von E-E-A-T sein, wie ich in meinen Artikeln erwähnt habe E-E-A-T: More than an introduction to Experience ,Expertise, Authority, Trust und The most interesting Google patents and scientific papers on E-E-A-T.
Der heutige Knowledge Vault als Entitätsextraktions- und Validierungsprozess
Bis heute lautet der offizielle Name der semantischen Datenbank von Google Knowledge Graph. Der Begriff Knowledge Vault wurde von Google ab 2015 nicht mehr erwähnt. Als der Knowledge Vault 2013 erstmals von Google vorgestellt wurde, sollte er die zentrale Wissensdatenbank mit Daten aus dem Knowledge Graph und dem offenen Web sein.
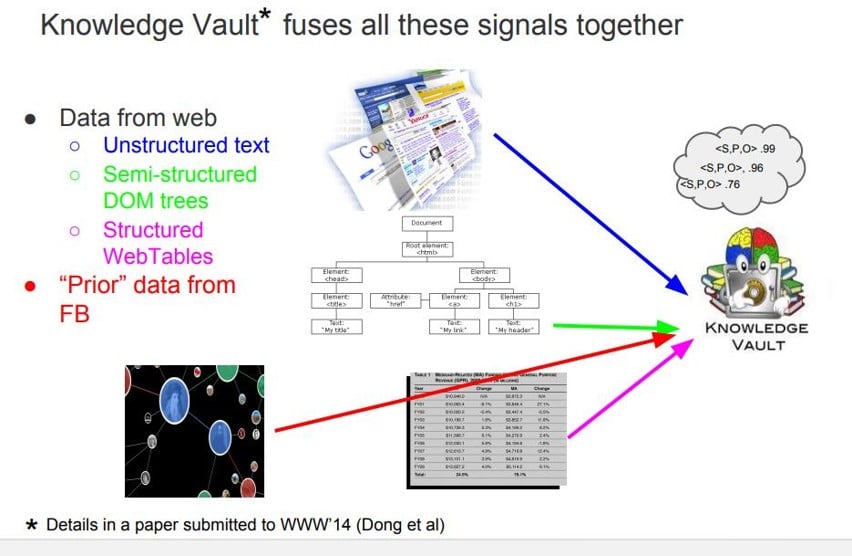
Ursprünglich sollte der Knowledge Vault den Knowledge Graph ersetzen, aber das ist bisher nicht geschehen.
Meiner Meinung nach hat der Knowledge Vault heute eher die Funktion eines vorgelagerten Wissensspeichers. Nicht validierte extrahierte Entitäten werden dort erfasst und mit Informationen über die Entitäten angereichert.
Die Gültigkeit der Entitäten, Attribute und anderer Informationen wird über Frequenzen auf Korrektheit geprüft. Sobald ein Schwellenwert erreicht ist, werden die Entitäten in den Knowledge Graph übertragen und in den SERPs mit einem eigenen Knowledge Panel angezeigt.
Der Knowledge Vault ist auch als Funktionsmodul für Named Entity Extraction, Data Mining via Natural Language Processing und Validierung zuständig.
Mehr dazu in meinen Artikeln Natural language processing to build a semantic database , All you should know as an SEO about entity types, classes & attributes, Unwrapping the Secrets of SEO: The Role of Machine Learning in Google Search.
Missverständnisse über den Knowledge Vault
Hier sind einige Missverständnisse über den Google Knowledge Vau4lt zu lesen:
Der Knowledge Vault ist ein Algorithmus
Es ist höchst unwahrscheinlich, dass die Wissensdatenbank ein einzelner Algorithmus ist. Der Knowledge Vault beschreibt einen Prozess zur Gewinnung von Wissen. Technologisch gesehen kann ein solcher Prozess mit Hilfe der natürlichen Sprachverarbeitung durchgeführt werden. Die Verarbeitung natürlicher Sprache gehört zum Bereich des maschinellen Lernens und besteht nicht nur aus einem Algorithmus, sondern ist ein mehrstufiger Prozess, der über mehrere Ebenen führt. Es ist daher nicht korrekt, vom Knowledge Vault als Algorithmus zu sprechen.
Der Knowledge Vault ist dasselbe wie der Knowledge Graph
Der Knowledge Graph ist eine semantische Datenbank, die hauptsächlich auf Informationen aus strukturierten und halbstrukturierten Datenquellen basiert. (Sie können mehr darüber in meinem Blog lesen). Der Knowledge Vault ist in erster Linie darauf ausgelegt, Informationen aus unstrukturierten Datenquellen zu extrahieren. (Mehr dazu erfahren Sie in meinem Blog). Der Knowledge Graph und der Knowledge Vault sind also miteinander verwandt, aber zwei verschiedene Dinge.
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023
Blog-Artikel zu diesem Thema
Googles Weg zur semantischen Suchmaschine
 In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
In diesem Beitrag möchte darauf eingehen welche Schritte und Innovationen Google seit 2010 näher an das Ziel des semantischen Verständnisses in der Suche gebracht haben. Es ist eine Zusammenfassung meiner Recherchen und Analysen seit 2013. Im Detail gehe ich auch auf die Rolle von Natural Languag... Artikel anzeigen
20+ Faktoren für eine E-E-A-T-Bewertung durch Google
 E-E-A-T hat sich durch die Core-Updates seit 2018 zu einem der wichtigsten Rankingeinflüsse für Google-Suchergebnisse entwickelt und wird durch die Einführung von SGE zusätzlich an Wichtigkeit gewinnen. In diesem Beitrag möchte ich auf 20+ Faktoren eingehen, die Google algorithmisch für eine E... Artikel anzeigen
E-E-A-T hat sich durch die Core-Updates seit 2018 zu einem der wichtigsten Rankingeinflüsse für Google-Suchergebnisse entwickelt und wird durch die Einführung von SGE zusätzlich an Wichtigkeit gewinnen. In diesem Beitrag möchte ich auf 20+ Faktoren eingehen, die Google algorithmisch für eine E... Artikel anzeigen
Brand-SEO: Suchmaschinenoptimierung für populäre Marken
 Populäre Marken bzw. Brands leben in erster Linie von der Popularität der eigenen Marke(n). Eine bekannte Brand zu sein ist ein großes Asset und Marktvorteil, da Brands neben der Popularität oft auch ein großes Vertrauen genießen. Das ist ein Vorteil beim Abverkauf, für den Erfolg im Performa... Artikel anzeigen
Populäre Marken bzw. Brands leben in erster Linie von der Popularität der eigenen Marke(n). Eine bekannte Brand zu sein ist ein großes Asset und Marktvorteil, da Brands neben der Popularität oft auch ein großes Vertrauen genießen. Das ist ein Vorteil beim Abverkauf, für den Erfolg im Performa... Artikel anzeigen
Alles was Du als SEO zu Entitätstypen, -Klassen & Attributen wissen solltest
 Es gibt nur wenige Informationen zu den wichtigen Elementen des Google Knowledge Graph wie Entitätstypen, -Klassen und -Attributen und Analyse der Beziehungen zwischen diesen Elementen. Ein Grund mehr im Rahmen meiner Artikelreihe zu semantischer Suchmaschinenoptimierung darauf einzugehen.
Vom Ent... Artikel anzeigen
Es gibt nur wenige Informationen zu den wichtigen Elementen des Google Knowledge Graph wie Entitätstypen, -Klassen und -Attributen und Analyse der Beziehungen zwischen diesen Elementen. Ein Grund mehr im Rahmen meiner Artikelreihe zu semantischer Suchmaschinenoptimierung darauf einzugehen.
Vom Ent... Artikel anzeigen
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
 In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum T... Artikel anzeigen
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
 Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzun... Artikel anzeigen
Entitäten & E-A-T: Die Rolle von Entitäten bei Autorität und Trust
 Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
Dieser Beitrag beschreibt den Zusammenhang zwischen Entitäten und Expertise, Autorität und Vertrauen bzw. der E-A-T-Bewertung von Autoren, Publishern und Unternehmen.
Autoren, Unternehmen und Publisher als Entitäten
Inhalte werden durch Personen wie Autoren und Organisationen wie Unternehmen, V... Artikel anzeigen
E-A-T-Optimierung: Wie optimiert man E-A-T bei Google?
 E-A-T ist seit den Core-Updates in den letzten Jahren im Fokus der Suchmaschinenoptimierung. Antworten auf die Fragen warum E-A-T so wichtig für das Ranking ist, welche möglichen Signale Google für die Bewertung nutzt und wie man darauf optimiert gibt es in diesem Beitrag.
Was ist E-A-T überhau... Artikel anzeigen
E-A-T ist seit den Core-Updates in den letzten Jahren im Fokus der Suchmaschinenoptimierung. Antworten auf die Fragen warum E-A-T so wichtig für das Ranking ist, welche möglichen Signale Google für die Bewertung nutzt und wie man darauf optimiert gibt es in diesem Beitrag.
Was ist E-A-T überhau... Artikel anzeigen
Personalisierung und Darstellung von Informationen zu einer Entität
 Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
Dieser Beitrag beschäftigt sich mit einem Google-Patent, das im Februar 2021 von Google beansprucht wurde. Es beschreibt wie Google Informationen zu Entitäten dynamisch zur Suchintention ausliefern kann. Dieser Beitrag gehört zur Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei ... Artikel anzeigen
Wie man seine Entitäten-Box/Knowledge Panel bei Google beanspruchen kann
 In diesen Beitrag möchte ich eine Entdeckung mir Dir teilen, die ich bei Google gemacht habe. Google möchte wohl zukünftig, dass man seine eigene Entitäten-Box bzw. Knowledge-Panel bearbeiten beanspruchen und bearbeiten kann.
Doch vorher muss man einen Verifizierungsprozess durchlaufen um die... Artikel anzeigen
In diesen Beitrag möchte ich eine Entdeckung mir Dir teilen, die ich bei Google gemacht habe. Google möchte wohl zukünftig, dass man seine eigene Entitäten-Box bzw. Knowledge-Panel bearbeiten beanspruchen und bearbeiten kann.
Doch vorher muss man einen Verifizierungsprozess durchlaufen um die... Artikel anzeigen




