
Wie im letzten Beitrag Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph? erläutert gibt es bei Wissens-Datenbanken wie dem Knowledge Graph die herausfordernde Aufgabe Vollständigkeit und Richtigkeit der Informationen in Balance zu halten. Eine notwendige Voraussetzung für die Vollständigkeit ist, dass Google in der Lage ist Informationen in unstrukturierten Datenquellen zu identifizieren, zu deuten und zu extrahieren. Dazu mehr in diesem Beitrag.
Inhaltsverzeichnis
- 1 Googles Reise zum semantischen Verständnis
- 2 Das Problem mit Wissens-Datenbanken wie Wikipedia und Wikidata
- 3 Geschlossene vs. Offene Extrahierung von Informationen
- 4 Erkennung von Tail-Entitäten
- 5 Named Entity Recognition
- 6 Extrahierung von Ereignissen
- 7 Machine Learning als zentrale Technologie für die Verarbeitung unstrukturierter Daten
- 8 Zuordnung neuer Entitäten zu Klassen und Typen via Unsupervised Machine Learning
- 9 Methoden zur Gewährleistung der Aktualität
- 10 Der Knowledge Vault als Knowledge Graph 2.0
- 11 Fazit: Google steht bei der Extrahierung von unstrukturierten Informationen erst am Anfang
Googles Reise zum semantischen Verständnis
Das Anliegen semantische Informationen zu Objekten bzw. Entitäten aus unstrukturierten Dokumenten zu extrahieren beschäftigt Google schon seit Ende der 90er Jahre. So findet man ein Google Patent von 1999 mit dem Titel Extracting Patterns and Relations from Scattered Databases Such as the World Wide Web (pdf). Es ist eins der ersten Google Patente zu semantischen Fragestellungen überhaupt.
Mehr dazu im Beitrag Wie schlau ist Google? Echtes semantisches Verständnis oder nur Statistik? .
Der erste Schritt in den ersten Jahren des Knowledge Graph war die die Extrahierung strukturierter und semistrukturierter Daten. Hier ist Google bereits ziemlich gut darin Informationen aus z.B. Wikipedia oder Wikidata zu extrahieren und zu verarbeiten. Mehr dazu in den Beiträgen Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph ? und Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest .
Doch das kann nur der Anfang gewesen sein, da die Grenzen eines solchen Methodik offensichtlich sind.
Das Problem mit Wissens-Datenbanken wie Wikipedia und Wikidata
Da Wikidata und Wikipedia nur einen Bruchteil aller Entitäten der realen Welt erfasst haben ist für Google die schwierigste Aufgabe Informationen zu Entitäten und Entitäts-Typen aus anderen Websites neben den oben genannten zu extrahieren. Die meisten Websites und Dokumente sind alle unterschiedliche aufgebaut und weisen i.d.R. keine einheitliche Struktur auf. Von daher hat Google hier noch eine große Aufgabe vor sich, um den Knowledge Graph weiter auszubauen.
Strukturierte und semistrukturierte Informationen aus manuell gepflegten Datenquellen wie z.B. Wikipedia oder Wikidata sind oft geprüft und so aufbereitet, dass Google diese einfach extrahieren und in den Knowledge Graph übernehmen kann. Doch diese Websites und Datenbanken sind auch nicht perfekt.
Das Problem von manuell gepflegte Datenbanken und semistrukturierten Websites wie Wikipedia ist die nicht vorhandene Vollständigkeit, die Validität und Aktualität der Daten.
- Vollständigkeit bedeutet zum einen bezogen auf die in einer Datenbank erfassten Entitäten an sich, als auch bezüglich derer Attribute und zugeordneten Entitäts-Typen.
- Validität bezieht sich auf die Richtigkeit der erfassten Attribute, Aussagen bzw. Fakten
- Aktualität bezieht sich auf die Attribute der erfassten Entitäten
Gerade die Validität und Vollständigkeit stehen in einem Spannungsfeld zueinander. Wenn Google sich nur auf die Wikipedia verlässt ist die Validität der Informationen aufgrund der strengen Prüfung der eifrigen Wikipedianer sehr hoch. Bei der Aktualität wird es schon schwieriger und bei der Vollständigkeit reichen die Informationen einfach nicht aus, da die Wikipedia nur einen Bruchteil des Wissens der Welt abbildet.
Um das Ziel einer annähernden Vollständigkeit zu erreichen muss Google in der Lage sein unstrukturierte Daten aus Websites zu extrahieren und dabei gleichzeitig auf Validität und Aktualität achten. Zum Beispiel stellen Artikel in Google News eine sehr interessante Quelle für Informationen dar, um die Aktualität bereits im Knowledge Graph erfasster Entitäten zu gewährleisten.
Google stehen über die Billionen von indexierten Inhalten bzw. Dokumenten ein riesiger Wissen-Fundus zur Verfügung. Das können News-Seiten, Blogs, Magazine, Reviews, , Shops, Glossare, Wörterbücher … sein.
Doch nicht jede Informationsquelle ist valide genug als Informationsquelle sinnvoll zu sein. Deswegen muss im ersten Schritt die richtige Domain als Quelle identifizert werden.
Über die Identifikation der Nennungen von bereits im Knowledge Graph gespeicherten Entitäten können im ersten Schritt Entitäten-relevante Dokumente identifiziert werden.
Die Begriffe, die in unmittelbarer Umgebung der genannten Entitäten als Kookkurrenz vorkommen können mit dieser verknüpft werden. Daraus können Attribute als auch andere Entitäten zur Haupt-Entität aus dem Inhalte extrahiert und im jeweiligen Entitäten-Profil hinterlegt werden. Die Nähe zwischen den Begriffen und der Entität im Text als auch die Häufigkeit der vorkommenden Haupt-Entität-Attribut-Paare oder Haupt-Entität-Neben-Entität-Paare kann sowohl als Validierung als auch als Gewichtung genutzt werden.
Somit kann Google die Entitäten im Knowledge Graph stetig mit neuen Informationen anreichern.
Nachfolgend habe ich in Google Patenten und andere Quellen recherchiert, um Ansätze zu finden, um Vollständigkeit (Recall), Validität und Aktualität gerecht zu werden.
Geschlossene vs. Offene Extrahierung von Informationen
Bevor ich in die konkrete Ansätze einsteige möchte ich kurz auf die beiden groben Arten der Extrahierung eingehen. Offene und Geschlossene Extrahierung. Bei der geschlossenen Extrahierung ist die Voraussetzung, dass die Entitäten mit einer URI bereits erfasst sind und diese hinsichtlich neuer Attribute und Beziehungen zu anderen Entitäten vervollständigt oder aktualisiert werden. Bei der offenen Extrahierung geht es zusätzlich um die Identifikation und Erfassung bisher unbekannter bzw. nicht erfassten Entitäten und derer Attributen. Das betrifft die Vollständigkeit der gesamten Wissens-Datenbanken nicht nur die Vollständigkeit der Attribute und Beziehungen je Entität.
Beispiel-Prozess für eine geschlossene Extrahierung von Fakten/Informationen
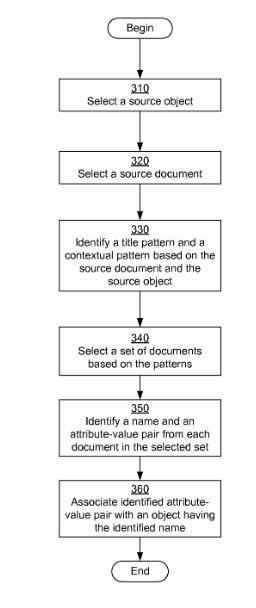
Quelle: Google Patent US8812435B1
Im Google Patent Learning objects and facts from documents wird ein Prozess erläutert wie Google neue Informationen zu bereits erfassten Entitäten/Objekten ohne menschliches zutun erfassen kann.
Abstract
A system, method, and computer program product for learning objects and facts from documents. A source object and a source document are selected and a title pattern and a contextual pattern are identified based on the source object and the source document. A set of documents matching the title pattern and the contextual pattern are selected. For each document in the selected set, a name and one or more facts are identified by applying the title pattern and the contextual pattern to the document. Objects are identified or created based on the identified names and associated with the identified facts.
In diesem Prozess werden Dokumente aus einem Index ermittelt, bei denen der Entitäts-Name bzw. die Objektbezeichnung im Titel genannt wird und ein bereits erfasstes Attribut und Attributs-Wert Paar vorkommt. Das könnte z.B. eine Beitrag zu Angela Merkel sein, in dem Ihr Beruf Bundesklanzler Erwähnung findet. Im nächsten Schritt wird das Dokument ein kontextuellen Muster zugeordnet. Das könnte z.B. sein „Politiker-Treffen“. Nun werden weitere Dokumente mit dem gleichen kontextuellen Muster und Titel-Merkmalen ergänzt. Aus diesem Dokumenten können nun neue Objekte/Entitäten mit entsprechenden Attribut-Attribut-Werten-Paaren extrahiert werden (siehe Flowchart links).
Vorraussetzung ist hier, dass bereits eine Entität in einem Fact-Respository bzw. Knowledge Graph aus einem bestimmten Kontext erfasst ist. Sprich es ist keine ganz offene Form der Extrahierung.
Am spannendsten sind die Methoden, die sich der offenen Extrahierung beschäftigen. Die Entitäten Konzepte die auf Websites wie Wikipedia bereist erfasst sind bildet Google bereits gut über Knowledge Panel in den SERPs ab. Viel interessanter ist daher die Frage, wie Google zukünftig mit weniger relevanten Entitäten sogenannten Tail-Entitäten umgehen kann.
Erkennung von Tail-Entitäten
Im Grunde gibt es drei Möglichkeiten wie Google Tail-Entitäten erkennen und erfassen kann. Den bisherigen Weg über strukturierte Daten z.B. aus Wikidata oder die Extrahierung aus Online-Content diverser Blogs, Websites, sozialer Netzwerke … oder manuell via Json-ld oder Mikrodaten ausgezeichneten strukturierten Daten.
Ich denke, dass es damals Googles Plan war über Google+ und den Authorship-Mark-Ups den Knowledge Graph hinsichtlich Tail-Entitäten zu erweitern. Wie das geendet ist wissen wir spätestens mit dem Abschalten von Google+ im April 2019.
Aktuell versuchen bereits viele SEOs ihre eigenen Entitäten-Profile anzulegen, wie ich selbst auch. Teilweise gelingt es so auch schon erste Knowledge Panel Infos in die SERPs zu bekommen.
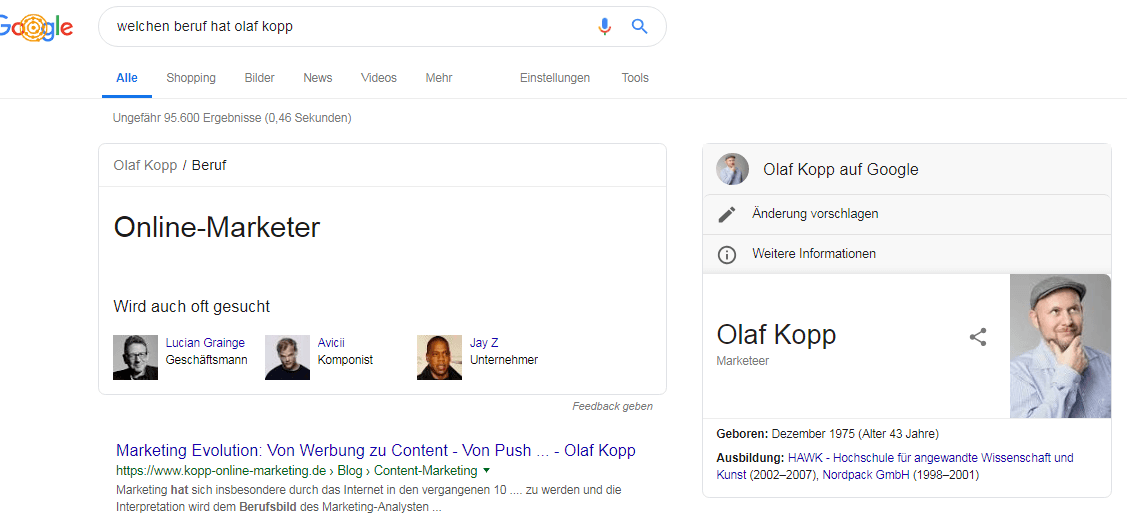
Knowledge Panel Olaf Kopp
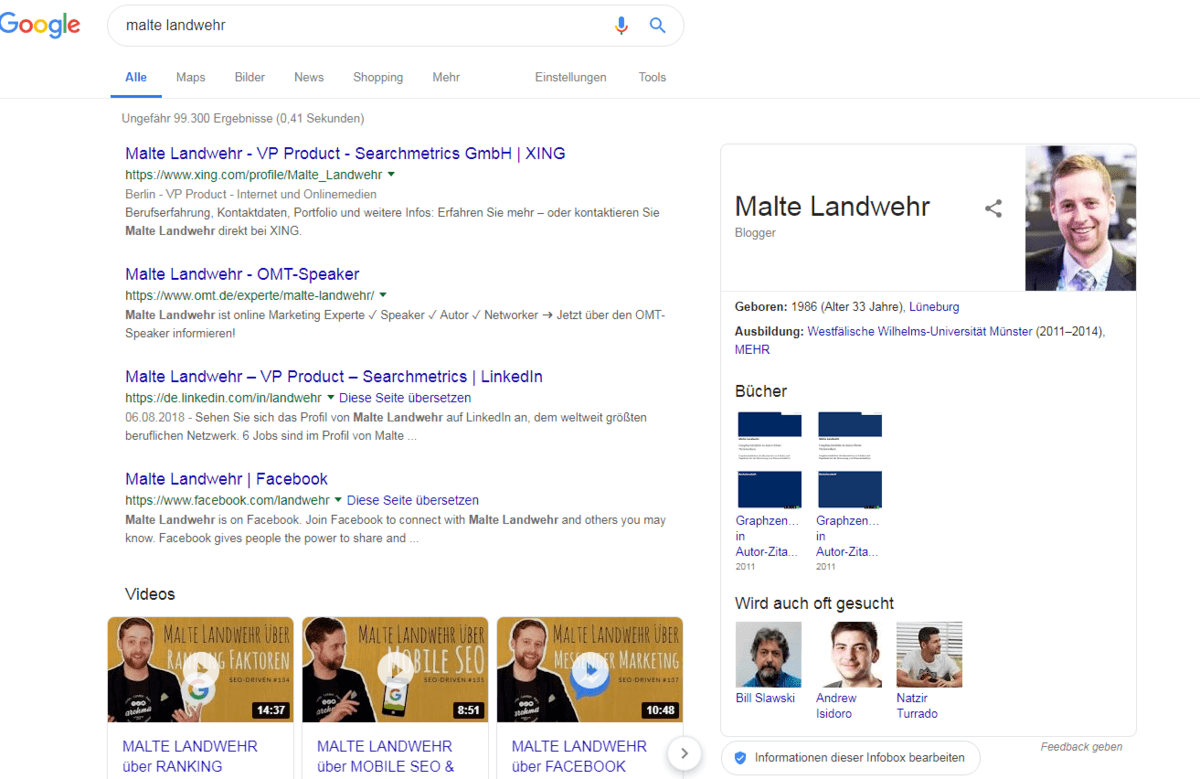
Knowledge Panel Malte Landwehr
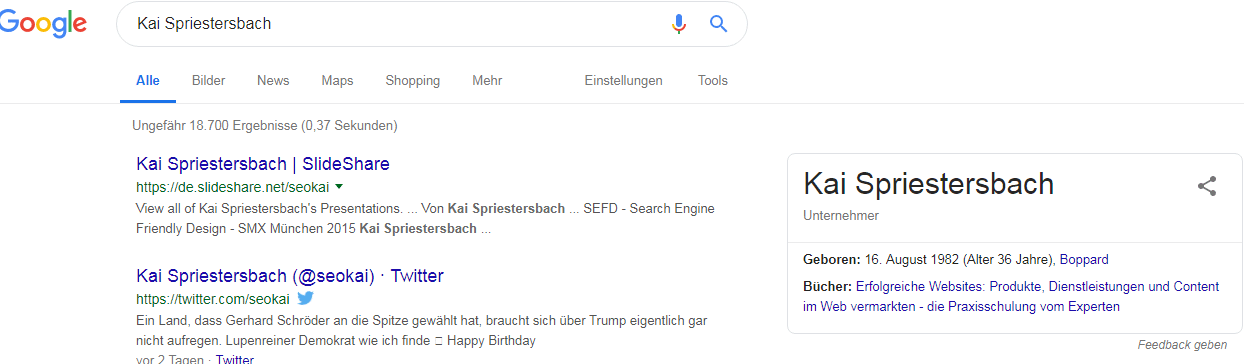
Knowledge Panel Kai Spriestersbach
Ich halte diese Wege aber nur für eine Zwischenlösung, da die Anlage und die Prüfung weiterhin manuell geschehen muss. Damit ist es keine skalierbare Lösung, die Google vorziehen wird. Google versucht in den letzten Jahren die Auszeichnung mit strukturierten Daten durch Webmaster und SEOs voranzutreiben. Das hat für mich nur einen Grund: Sie wollen ihren Machine Learning Algorithmen so viele von Menschen validierte strukturierte Daten als Trainingsdaten zur Verfügung stellen wie nur möglich. Ziel ist es strukturierte Daten irgendwann nicht mehr zu benötigen. Mehr dazu in meinem Beitrag Warum strukturierte Daten für Google zukünftig überflüssig werden könnten.
Ein Weg für Google für die Zukunft muss sein neue Entitäten automatisch aus frei verfügbaren Dokumenten heraus zu identifizieren, zu deuten und im Knowledge Graph anzulegen. Folgende Schritte könnten hierfür durchlaufen werden:
- Identifikation potentieller Entitäten (Named Entity Recognition)
- Extrahierung von Klassen und Typen: Zuordnung der Entität in eine oder mehrere semantische Klassen und Typen basierend auf dem Kontext in dem die Entität immer wieder genannt wird. Dadurch könnten erste Attributs-Sets hinterlegt werden, die nach und nach mit Werten vervollständigt werden.
Tipp für Nerds!
 Hier eine Anleitung für eine einfach Umsetzung via Python zum selber bauen:
Hier eine Anleitung für eine einfach Umsetzung via Python zum selber bauen:
Training spaCy’s Statistical Models
Beispiel für numerische Patterns zum selber bauen in Python:
- Extrahierung von Beziehungen: Herstellung von Beziehungen zu anderen bereits erfassten Entitäten mit ähnlichen oder gleichen Mustern bzw. in ähnlichen Kontexten Nennung finden.
Tipp für Nerds!
Für Python kundige Nerds gibt es hier eine Anleitung, die Umsetzung auf Basis der Embedding-Technologie von Google:
How to Develop Word Embeddings in Python with Gensim
In einigen Google-Patenten findet man Anhaltspunkte wie Google dieses Problem zukünftig lösen könnte. So gibt das Patent Computerized Systems and Methods for Extracting and Storing Information regarding Entities folgenden Ansatz, um neue Entitäten inkl. Attributen und zugehörigen Entitäts-Klassen aus Dokumenten zu extrahieren.
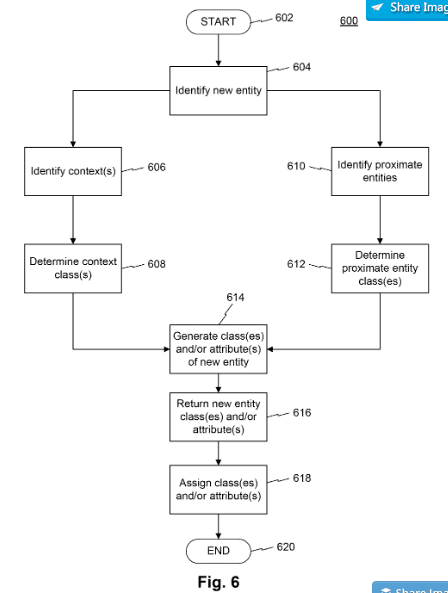
Quelle: Google Patent US10198491B1
Im ersten Schritt wird geprüft, ob ein Dokument eine oder mehrere bereits bekannte oder neue Entitäten beinhaltet. Sind die Entitäten bereits bekannt wird geprüft, ob der Inhalt bisher nicht mit der Entität verknüpfte Attribute aufführt. Werden diese als passend angesehen wird die bereits gespeicherte Entität mit den neuen Attributen aktualisiert.
Werden potentielle neue Entitäten entdeckt, werden diese in Kontext des Inhalts gesetzt. Um die bisher unbekannte Entität in eine oder mehrere Entitäts-Klassen einzuordnen werden im Inhalt bereits bekannte Entitäten gesucht, die ähnliche Attribute besitzen bzw. benachbart erscheinen. Über den Kontext und die Entitäts-Klassen bzw. deren Attribute entsteht ein klareres Bild des semantischen Kontexts der neuen Entität.
Über einen Beziehungs-Scoring kann eine hierarchische Klassen-Zugehörigkeit ermittelt werden.
Diese kann dann inkl. erster Attribute, Beziehung zu anderen Entitäten und Entitäts-Klassen bzw. – Typen im Graph gespeichert werden.
Das Patent wurde im Februar 2019 aktualisiert und hat eine Laufzeit bis 2037, was dafür spricht, dass Google damit arbeitet.
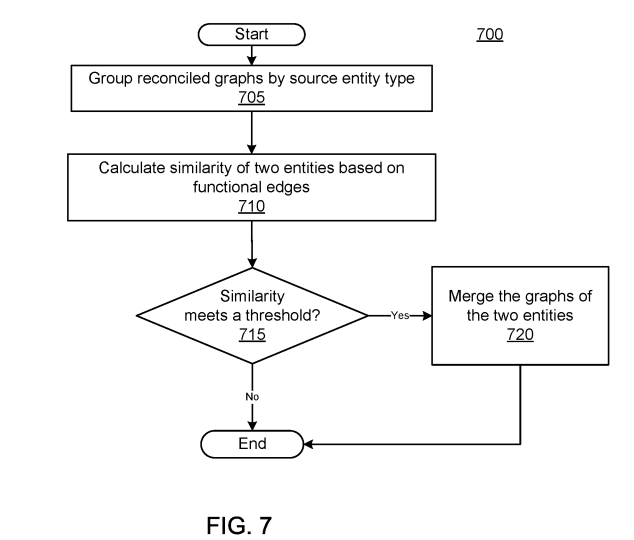
Quelle: Google Patent – Automatic discovery of new entities using graph reconciliation, US10331706
Ein weiteres Google Patent aus dem Jahr 2019 mit dem Titel „Automatic Discovery of new Entities using Graph Reconciliation“ beschreibt eine weitere Methode, um neue Entitäten inklusive Attributen und Beziehungsarten aus unstrukturierten Online-Quellen zu extrahieren und zu verifizieren.
Die Methode beschreibt wie Google aus Website-Inhalten entdeckten Tuples aus Subjekt-Entitäten, Objekt-Entitäten und Prädikatsphrasen einzelne Entitätsgraphen extrahieren könnte. Diese Einzelgraphen werden nach Entitätstypen gruppiert, damit sie besser mit verglichen werden können.
Über einen Abgleich der unterschiedlichen Entitätsgraphen lassen sich Fakten verifizieren. Tuples bzw. Fakten, die häufig in den einzelnen Graphen vorkommen sind glaubwürdiger als Fakten, die nur vereinzelt vorkommen. Sobald die Anzahl der gleich lautenden Nennungen einen Schwellenwert übersteigen werden sie als korrekt verifiziert. Alle so verifizierten Fakten zu der jeweiligen Entität werden in einem neuen Entitätsgraph zusammengeführt und im Knowledge Graph gespeichert.
Named Entity Recognition
Die Erkennung von benannten Entitäten (mehr dazu im Beitrag Was sind Entitäten ? ) in Sätzen, Paragraphen und ganzen Texten ist der allererste Prozessschritt bei der Generierung von Informationen für einen Knowledge Graph. Die gängigste Methode dafür ist Supervised und semisupervised Machine Learning. Über das manuell unterstützende maschinelle Lernen können hinsichtlich des Recalls bzw. Grad der Vollständigkeit der Entitäten in einem Knowledge Graph gemessen an der Gesamtheit aller Entitäten ein passabler Wert erzielt werden. Je besser Trainingsdaten für Entitäten einer bestimmten Ontologie wie z.B. Personen, Organisationen, Events … kommentiert bzw. getaggt sind desto besser das Ergebnis. Diese Auszeichnung ist die manuelle Unterstützung des Algorithmus. Wissenschaftliche Experimente haben gezeigt, dass eine Seed-Set von nur 10 manuell eingepflegten Fakten bei einem Korpus von mehreren Millionen Dokumenten zu einer Precision bzw. Richtigkeit von 88% führen kann.
Für die Erkennung benannter Entitäten können typische Merkmale wie z.B. Wortart (Nomen, Objekt, Subjekt) oder Kookkurrenzen mit bestimmten Informationen helfen.
Tipp für Nerds!
Hier einige Anleitungen für die einfache Umsetzung via Python:
.
So wird eine Entität aus der Klasse Schauspieler häufig im Zusammenhang mit Formulierungen wie hat den Golde Globe gewonnen, ist ein Movie Star, ist nominiert für die Goldene Kamera, hat in Film xy mitgespielt … genannt. Auch Worteigenschaften wie die Zeichenart sowie Anzahl oder Wortendung können zumindest Hinweise auf eine Entitäten-Klasse, einen Entitäts-Typ oder einen Attribut-Wert sein. So enden Sprachen meistens mit „isch“ oder Jahreszahlen bestehen aus 4 Zahlen.
Weitere Merkmale können über einen Abgleich mit in Wörterbüchern vorkommenden Nomen oder die Kookkurrenz mit bestimmten Begriffen sein. So weist eine unmittelbare Kookkurrenz mit dem Begriff GmbH daraufhin, dass es sich um ein Unternehmen handeln könnte. Die Termkombination „FC + Stadt“ lässt die Vermutung zu, dass es sich um einen Fußballclub handelt.
Dabei ist eine Eigenschaft für sich alleine gestellt oft kein Indiz oder sogar Beweis. Erst die Kombination aus verschiedenen Merkmalen gibt Gewissheit.
Zur Erklärung ein Beispiel-Satz:
Olaf Kopp ist Head of SEO bei Aufgesang und ist 1975 in Waldshut Tiengen geboren.
Folgende Informationen sind bekannt:
- Head of SEO (Entitäts-Klasse Beruf)
- Waldshut Tiengen (Entität der Entitäts-Typ Ort)
- geboren (zum Wortstamm Geburt zugehörig)
Nur basierend auf diesen Informationen können u.a. folgende Dinge ziemlich valide abgeleitet werden:
- Olaf Kopp ist eine Entität mit dem Entitäts-Typ Person
- Aufgesang ist eine Entität des Typs Organisation, die sich wohl mit SEO beschäftigt
- Geburtsort von Olaf Kopp ist Waldshut Tiengen
- Geburtsjahr von Olaf Kopp ist 1975
- …
Wenn man diesen Satz mit der Natural Language API analysiert kommt folgendes bei heraus:
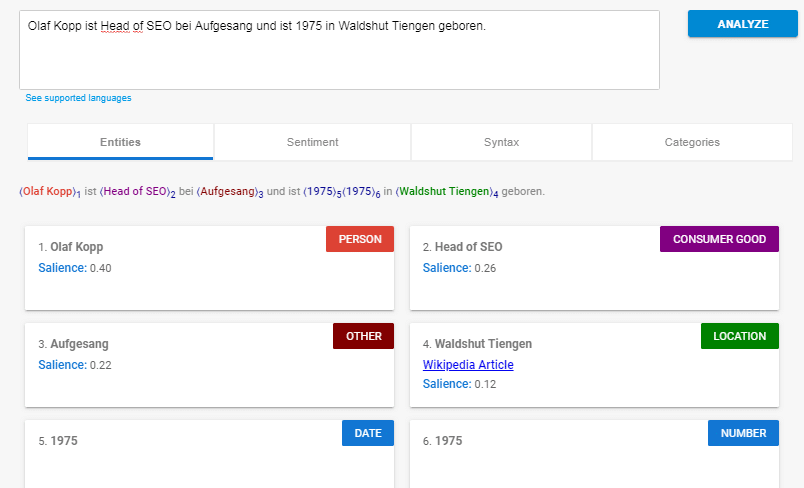
Quelle: https://cloud.google.com/natural-language/
Google erkennt als Entitäten:
- Olaf Kopp (Person)
- Head of SEO (Consumer Good)
- Aufgesang (Other)
- Waldshut Tiengen (Location)
- 1975 (Datum / Number)
Was sagt uns das?
Aufgrund der Semantik in diesem Satz kann Google diverse Entitäten extrahieren. Diese Entitäten sind nur zum Teil im Knowledge Graph erfasst. So zeigt eine Abfrage der Knowledge Graph API zur Entität, dass „aufgesang“ nicht als Entität erfasst ist.
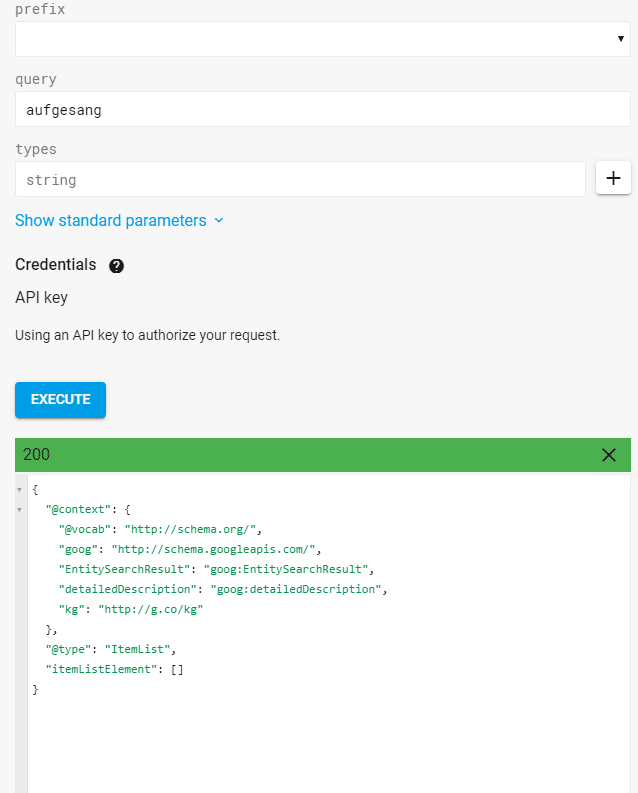
Ergebnis Abfrage für die Entität „aufgesang“ über die Knowledge Graph API
Google erkennt die Entitäten nur über Natural Language Processing (NLP) anhand des Satzbaus, ohne auf einen Knowledge Graph zuzugreifen. Ersetze ich z.B. die Entität Aufgesang oder Olaf Kopp mit einem Phantasie-Begriff erkennt Google diese trotzdem als Entitäten, was diese These untermauert. Die Phantasie-Begriffe „kribi knopp“ und „phalomi“ sind Begriffe ohne Bedeutung und ebenfalls nicht im Knowledge Graph erfasst.
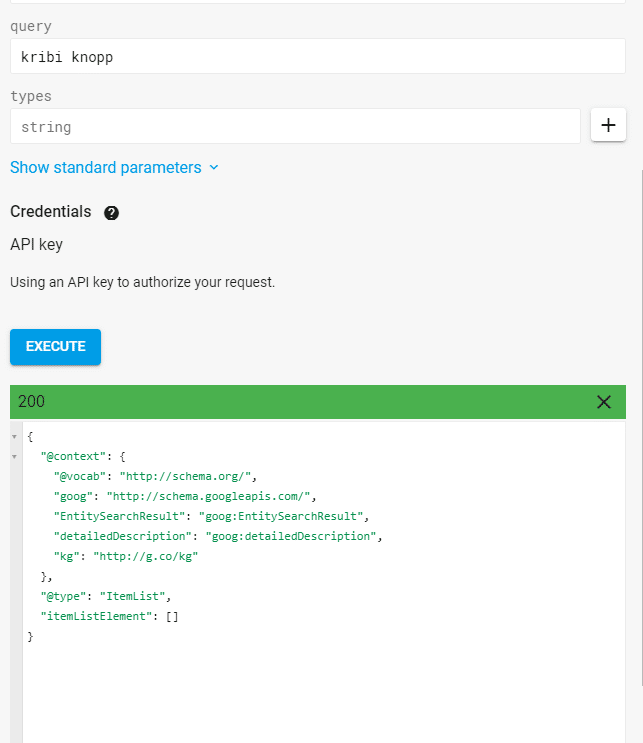
ErgebnisAbfrage für die Entität kribi knopp“ über die Knowledge Graph API
Google erkennt sie nur aufgrund des Satzbaus als Entitäten:
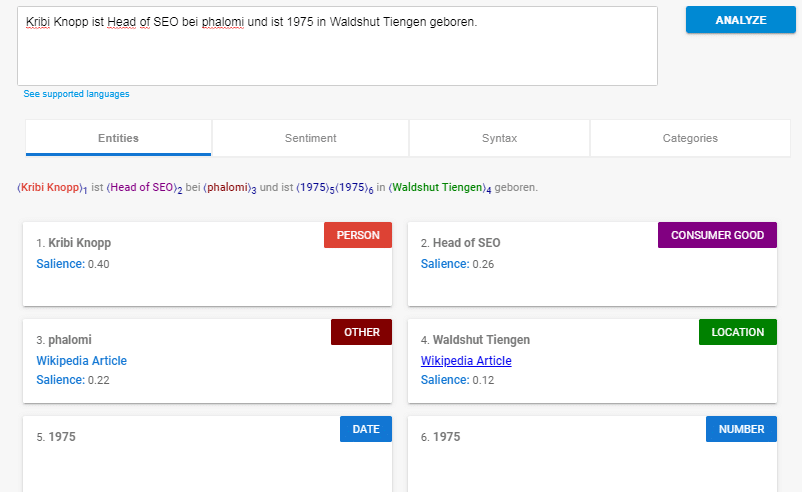
Natural Language Processing ist eine wichtige Methodik zur Erkennung potentieller Entitäten. Auch grobe Entitäts-Typen oder -Klassen lassen sich der Entität über NLP zuordnen. Mehr zu diesem Thema und der Natural Language API von Google allerdings im nächsten Beitrag dieser Reihe.
Extrahierung von Ereignissen
Bei der Extrahierung von Ereignissen geht es darum aktuelle Ereignisse und deren Bedeutung zu identifizieren. Gerade für Google News und deren Ausspielung in den normalen SERPs als auch bei der Erkennung von saisonalen Events spielt das eine große Rolle.
Aktuelle Ereignisse kann Google zum einen über eine plötzlich steigende Anzahl an Suchanfragen zu einer Entität und/oder eine Kombination aus Entitäten und Event-Trigger-Begriffen erkennen. Oder Google erkennt ein Ereignis über Kookkurrenzen dieser Merkmale in aktuellen Berichten in Nachrichten-Magazinen, Blogs …
Ereignisse und Entitäten sind eng miteinander verbunden. Entitäten sind oft Schauspieler oder Teilnehmer an Veranstaltungen bzw. Ereignissen und Ereignisse ohne Entitäten sind ungewöhnlich. Die Interpretation von Ereignissen und Entitäten ist stark kontextabhängig. Deswegen orientieren sich moderne Methoden für die Interpretation von Ereignissen immer an den unmittelbar genannten Entitäten und Event typischen Trigger-Begriffen. Solche Trigger-Begriffe können z.B. sein „Feuer“, „Bomben“, „Tote“, „Attacke“, „Sieg“, „gewonnen“, Erdbeben“, „Katastrophe“ …
Hier habe ich ein Beispiel eines Ereignisses in Bezug auf die Entität Facebook bei Google gefunden:
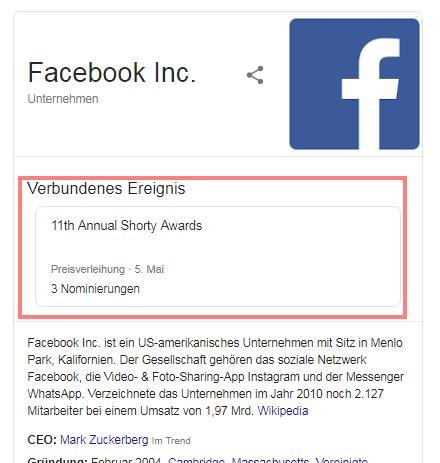
Machine Learning als zentrale Technologie für die Verarbeitung unstrukturierter Daten
Eine zentrale Technologie für die Extrahierung von Informationen und Natural Language Processing ist Machine Learning in den verschiedenen Ausprägungen. Mehr dazu im Beitrag Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google .
Zu den Hauptaufgaben bei der Verarbeitung unstrukturierter Datenquellen gehören u.a.
- Extrahierung von Informationen aus Websites
- Erkennung benannter Entitäten (Named Entity Recognition)
- Extrahierung von Beziehungen (Relation Extraction)
- Extrahierung von Events (Event Extraction)
- Erkennung und Extrahierung von Typen & Klassen und Zuordnung der Entitäten
Um die Zuordnung und das Training zu verfeinern werden Verfahren wie z.B. Lemmatisierung und und Komposita Zerlegung angewandt.
Zuordnung neuer Entitäten zu Klassen und Typen via Unsupervised Machine Learning
Eine Methode bisher unbekannte Entitäten in einen Kontext zu bringen bzw. Entitäts-Klassen oder Entitäts-Typen zuzuordnen ist das Clustering. Dies kann über Unsupervised Machine Learning Algorithmen durchgeführt werden.
Dabei werden in einem Text als potentielle Entitäten erkannte Begriffe hinsichtlich des mittelbaren oder unmittelbaren Begriffs-Umfeld in denen sie genannt werden Typen bzw. Klassen zugeordnet. Dies geschieht über den Abgleich mit Kookkurrenz-Mustern, die der Algorithmus aus der Analyse für bestimmte Klassen ausgemacht hat. Hierfür können auch Vektorraumanalysen zum Einsatz kommen, bei denen der Winkel der Vektoren abhängig von der Nähe der Begrifflichkeiten zur gesuchten Entität bestimmt wird.
Über diese Methode können auch bisher nicht erfasste Entitäten identifiziert werden. So könnte man z.B. aus einen Feed aus Nachrichten wie z.B. Google News die Kookkurrenzen von bereits erfassten benannten Entitäten mit bisher unbekannten potentiellen Entitäten in einen thematischen Kontext bringen und Typen und Klassen automatisch zuweisen.
Das komplexe hierbei ist das Finden eines passenden Thresholds (Schwellenwertes), ab wann eine Entiät einer anderen so sehr ähnelt bzw. ihr so nahekommt (z.B. innerhalb eines Vektorraums -> Word Embeddings) bis sie von Google als zugehörig angesehen wird. Das ein generalistischer Schwellenwert verwendet wird ist ebenfalls eher unwahrscheinlich, ggf. sind sie sogar so granular wie Entitäten. Philip Ehring, Data Engineer / Data Scientist im Text Mining Team der Otto Business Intelligence.
Wenn z.B. eine bisher unbekannte neue Automarke immer wieder in Nachrichten zusammen mit bekannten Entitäten wie VW, Mercedes und Toyota genannt wird liegt es nah, dass diese der Entitäts-Klasse oder Typ Autohersteller zuzuordnen ist und damit diese neue Entität mit den für diese Klasse gängigen Attributen in Verbindung gebracht werden kann. Dadurch können sich ggf. auch die Muster für die Validierung neuer Entitäten und die Schwellenwerte verändern.
Methoden zur Gewährleistung der Aktualität
Zu bestimmten Entitäten und Konzepten ist Aktualität kein großes Problem, da sich die Fakten bzw. Attribute seit Jahrzehnten oder Jahrhunderten nicht verändern wie z.B. bei Bauwerken, Events aus der Vergangenheit, historische Persönlichkeiten … Doch es gibt Entitäten, die sich im stetigen Wandel befinden wie z.B. aktuell lebende Personen, politische Ämter …
Hier können sogenannte Knowledge Base Acceleration Systeme kurz KBA-Systeme eine zeitnahe Aktualisierung der Datensätze ermöglichen.
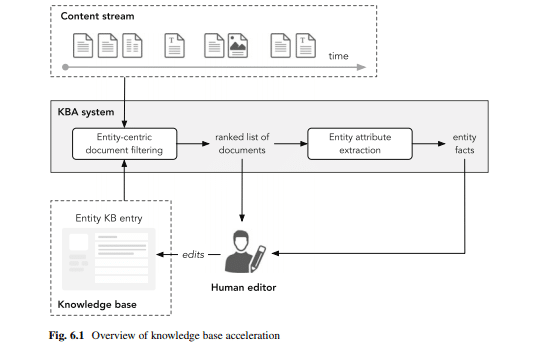
Quelle: Entity Oriented Search von Krisztian Balog
Aus einem stetigen Content-Stream aus neu veröffentlichten referenzwürdigen Inhalten wie z.b. News-Artikeln, Blogbeiträgen oder Tweets werden in Echtzeit Entitäten-relevante Inhalte in ein KBA-System zur Analyse importiert. Diese Dokumente werden entweder den Editoren der Datenbank direkt zugespielt oder erst die Fakten extrahiert und diese dann den Editoren zugeführt.
Während die Identifikation von relevanten Dokumenten ein einfacher Information Retrieval Prozess nach Entitäts-Name inkl. Synonymen ist gestaltet sich der automatisierte Prozess der Extrahierung etwas komplexer.
Hier kann die Methodik der Closed Information Extraction genutzt werden. Bei dieser Methodik beschränkt man sich auf die Erkennung von Veränderungen bezüglich Fakten bereits erfasster Datensätze.
Bei der Closed Information Extraction kann hierarchisch von oben nach unten, also beginnend bei der semantischen Klasse bzw. Entitäts-Typ mit der Erweiterung bzw. Aktualisierung begonnen werden oder umgekehrt von unten nach oben, beginnend bei der Entität.
Im Google-Patent Extracting information from unstructured text using generalized extraction patterns wird eine Methode beschrieben wie man basierend auf aus einzelnen Sätzen extrahierten Seed-Fakten eine Datenbank stetig mit neuen Informationen aus unstrukturierten Texten erweitern kann. Das Patent wird nicht im Bezug auf Entitäten beschrieben könnte aber auch zur Vervollständigung der Attribute und Beziehungen von Entitäten genutzt werden.
Abstract
Methods, systems, and apparatus, including computer program products, for extracting information from unstructured text. Fact pairs are used to extract basic patterns from a body of text. Patterns are generalized by replacing words with classes of similar words. Generalized patterns are used to extract further fact pairs from the body of text. The process can begin with fact pairs, basic patterns, or generalized patterns.
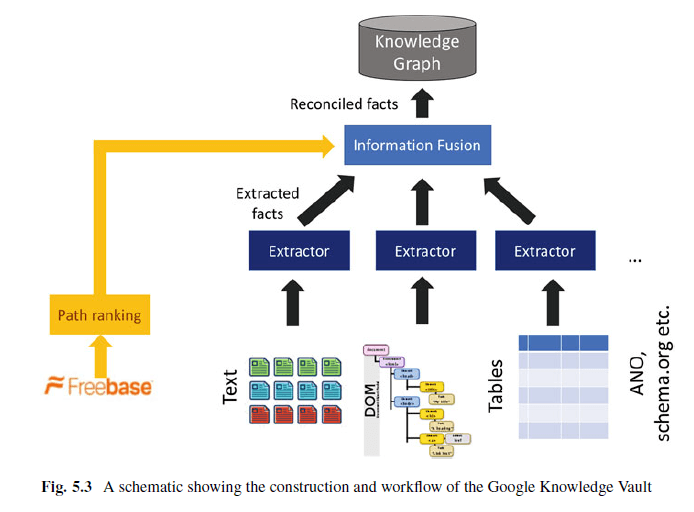
Der Knowledge Vault als Knowledge Graph 2.0
Der Knowledge Vault ist eine Wissensdatenbank, die Extrahierungen aus Webinhalten (durch Analyse von Text, Tabellendaten, Struktur und menschliche Anmerkungen z.B. via Json-LD, Microdata) und Informationen aus bestehenden Wissensdatenbanken wie Wikidata, YAGO, DBpedia … miteinander kombiniert.
In viele Beiträgen wurde darüber spekuliert, ob Googles Knowledge Vault den Knowledge Graph irgendwann ersetzen wird. Ich sehe den Knowledge Vault als Knowledge Graph 2.0.
Für die Extrahierung der Informationen nutzt der Knowledge Vault neben strukturierten Datenquellen wie Wikidata (früher Freebase), semistrukturierte Datenquellen wie Wikipedia, als auch unstrukturierten Web-Content. Über ein Fusions-Modul werden diese Daten zusammengeführt und via Supervised Machine Learning verarbeitet und in den Knowledge Graph / Knowledge Vault überführt.
Während klassische Knowlede Graphen Informationen in erster Linie nur aus strukturierten oder zumindest semistrukturierten Datenquellen beziehen, ist der Knowledge Vault in der Lage Informationen auch aus unabhängig von per Hand gepflegten Informationen skalierbar zu verarbeiten. Dazu ein Auszug aus dem wissenschaftlichen Papier Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion .
Here we introduce Knowledge Vault, a Web-scale probabilistic knowledge base that combines extractions from Web content (obtained via analysis of text, tabular data, page structure, and human annotations) with prior knowledge derived from existing knowledge repositories. We employ supervised machine learning methods for fusing these distinct information sources. The Knowledge Vault is substantially bigger than any previously published structured knowledge repository, and features a probabilistic inference system that computes calibrated probabilities of fact correctness.
Der Knowledge Vault wird entwickelt, da eine das Wachstum von menschlich gepflegten Datenquellen wie z.B. Wikipedia stagniert und neue Informationsquellen erschlossen werden müssen, um das Ziel einer nahezu vollständigen Wissens-Datenbank zu erreichen, ohne dabei auf die Validität der Informationen zu verzichten.
Therefore, we believe a new approach is necessary to further scale up knowledge base construction. Such an approach should automatically extract facts from the whole Web, to augment the knowledge we collect from human input and structured data sources. Unfortunately, standard methods for this task (cf. [44]) often produce very noisy, unreliable facts. To alleviate the amount of noise in the automatically extracted data, the new approach should automatically leverage already-cataloged knowledge to build prior models of fact correctness. Quelle: https://www.cs.ubc.ca/~murphyk/Papers/kv-kdd14.pdf
Damit folgt der Knowledge Vault dem Prinzip der offenen Extrahierung.
Tipp für Nerds!
Hier findest Du eine Anleitung für die vollautomatisierte Extrahierung ohne notwendiges manuelles Feintuning.
Über den Path-Ranking Algorithmus können typische Beziehungsmuster zwischen Entitäten in strukturierten Datenquellen wie z.B. Wikidata identifiziert werden. So sind z.B. Entitäten, die mit dem Prädikat „verheiratet mit“ in Beziehung stehen oft mit dem Bezeihungswert „Eltern von“ mit weiteren Entitäten in Beziehung und umgekehrt. Diese häufig vorkommenden Zusammenhänge können dann als Regeln erfasst werden.
Tipp für Nerds!
Hier findest Du eine Anleitung für die Implementierung auf Wort- und Token-Ebene.
Zur Evaluation der Informationen kann der Knowledge Vault über Zusammenhänge der Informationen und die Bewertung der Quelle feststellen ob eine Information richtig oder falsch ist. Zudem ist der Knowledge Vault durch die automatisierte offene Extrahierung deutlich größer als klassische Wissensdatenbanken.
Um einen Knowledge Graph dieser Größe zu schaffen, werden Fakten aus einer Vielzahl von Quellen wie Webdaten, einschließlich Freitext, HTML-DOM-Bäumen, HTML-Webtabellen und menschliche Anmerkungen zu Webseiten extrahiert. Die menschlichen Anmerkungen sind via JSon-LD, schema.org… augezeichnete Inhalte.
Der Knowledge Vault besteht aus drei Kernkomponenten:
- Extractors: Diese Komponente extrahiert die oben bereits angesprochenen RDF-Triples bzw. Statements aus Objekt, Prädikat und Subjekt aus frei verfügbaren Dokumenten, versieht diese mit einem Confidence-Score, um die Glaubhaftigkeit des Triples zu bemessen.
- Graph based priors: Diese Komponente prüft aufgrund der vorkommender Häufigkeit bestehender RDF-Triples in der Datenbank die Wahrscheinlichkeit, dass dieses Statement relevant ist.
- Knowledge Fusion: Hier wird aufgrund der Informationen aus den vorherigen Schritten geprüft, ob das Statement richtig ist und im Knowledge Graph gespeichert wird oder nicht.
Fazit: Google steht bei der Extrahierung von unstrukturierten Informationen erst am Anfang
Die in diesem Beitrag erläuterten Ansätze und Methoden zur Extrahierung von unstrukturierten Informationen für den Knowledge Graph sind bereits einsetzbar und der Knowledge Vault spielt hier die zentrale Rolle. Inwiefern diese bereits eingesetzt werden bleibt Spekulation.
Die Praxis zeigt allerdings, dass Google bisher nur sehr begrenzt auf unstrukturierte Informationen zurückgreift, zumindest was die Ausspielung in den Knowledge Panels angeht. Erste praktische Anwendungen finden wir in den Featured Snippets wieder, obwohl das eher nach dem direkten Einsatz von Natural Language Processing aussieht als nach der Nutzung des Knowledge Graph.
Auch bei bisher nicht im Knowledge Graph erfassten Entitäten arbeitet Google aktuell nur mit NLP, um diese zu identifizieren, unabhängig vom Knowledge Graph. Für die Identifikation von Entitäten und thematische Einordnung leistet Natural Language Processing gute Dienste. Allerdings wäre dadurch nur das Kriterium der Vollständigkeit ggf. Aktualität gewährleistet. NLP alleine gewährleistet aber nicht den Anspruch auf Richtigkeit.
Ich denke, dass Google im Bereich Natural Language Processing schon recht gut ist, aber bei der Evaluation von automatisch extrahierten Informationen hinsichtlich Richtigkeit noch nicht zufriedenstellende Ergebnisse erzielt. Das wird wohl der Grund sein, warum Google hier noch vorsichtig agiert, was direkte Positionierung in den SERPs angeht.
Deswegen möchte ich mich im nächsten Beitrag mehr im Detail mit den Thema NLP bzw. Natural Language Processing in der Suche auseinandersetzen.
Credits: Die Verlinkungen zu den Anleitungen zu den Nerd-Tipps stammen von Philip Ehring. Philip ist gelernter und studierter Bibliothekar und arbeitet im Fokus Semantik, Information Retrieval und Machine Learning als Data Engineer / Data Scientist im Text Mining Team der Otto Business Intelligence. Die praktisch angewandte Evaluation von Google und den einzelnen Bestandteilen der Suchmaschine mit dem Blick auf Suchmaschinenoptimierung ist seit seinem Praktikum bei Aufgesang fester Bestandteil seines Werdegangs.
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























3 Kommentare
Nochmals tolle Einblicke Olaf! Vielen Dank für Ihre Bemühungen, einen detaillierten und informativen Beitrag zu erstellen. Schreib weiter.