
In diesem Beitrag werde ich mich tiefer mit Natural Language Processing (kurz NLP) für Data Mining und speziell für den Knowledge Graph und Suchmaschinen beschäftigen. Zum Anfang möchte ich in die Grundlagen von Natural Language Processing einsteigen.
Eine ausführliche Beitragssammlung zum Thema Knowledge Graph, semantische SEO und Entitäten findest Du in der zugehörigen Artikelreihe.
Inhaltsverzeichnis
- 1 Was ist Natural Language Processing ?
- 2 Prozesse und Kernkomponenten von Natural Language Processing
- 3 Was ist die Natural Language Processing API von Google?
- 4 NLP bei der Entitätsanalyse
- 5 Word Embedding und Natural Language Processing
- 6 Einsatz von NLP in der Suche
- 7 BERT: Natural Language Processing für die Interpretation von Suchanfragen und Dokumenten
- 8 Natural Language Processing ist die wichtigste Methodik zur Identifikation von Entitäten
- 9 Natural Language Processing für den Aufbau des Knowledge Graph
- 10 Fazit: Aufbau des Knowledge Graphs über Wikipedia, Wikidata und Knowledge Vault
- 11 Tools
Was ist Natural Language Processing ?
Natural Language Processing (NLP) ist ein Prozess zur automatischen Analyse und Darstellung der menschlichen Sprache. Natural Language Processing versucht, natürliche Sprache zu erfassen und mithilfe von Regeln und Algorithmen computerbasiert zu verarbeiten. NLP setzt auf verschiedene Arten von Machine Learning Supervised Machine Learning und Unsupervised Machine Learning, um auf Basis statistischer Modelle sowie Vektorraumanalysen Inhalt und Struktur von Texten und gesprochener Sprache zu erkennen. Neuere NLP-Ansätze beschäftigen sich auch mit Methoden für die Textgenerierung und Labeling (Kennzeichnung) über Reinforcement Learning (Bestärkendes Lernen) via Semi- oder Weak Supervised Machine Learning.
In anderen Worten Natural Language Processing also NLP ist der Prozess des Analysierens von Text, des Erstellens von Beziehungen zwischen Wörtern, des Verstehens der Bedeutung dieser Wörter und des Ableitens eines besseren Verständnisses der Bedeutung der Wörter, um daraus Informationen, Wissen oder neuen Text zu generieren
Für folgende Anwendungsbreiche kann Natural Language Processing eingesetzt werden:
- Spracherkennung (text to speech & speech to text)
- Segmentierung zuvor erfasster Sprache in einzelne Wörter, Sätze und Phrasen.
- Erkennen der Grundformen der Wörter und Erfassung grammatischer Informationen
- Erkennen der Funktionen einzelner Wörter im Satz (Subjekt, Verb, Objekt, Artikel, etc.)
- Extraktion der Bedeutung von Sätzen und Satzteilen bzw. Phrasen wie Adjektivphrasen (z.B. zu langen), Präpositionalphrasen (z.B. an den Fluss) oder Nominalphrasen (z.B. der zu langen Party)
- Erkennen von Satzzusammenhängen, Satzbeziehungen und Entitäten.
Natural Language Processing kann sowohl für die linguistische Textanalyse, Stimmungs- und Meinungs-Analyse (Sentimentanalyse), Übersetzungen als auch für Sprachassistenten, Chatbots und zu Grunde liegenden Frage- & Antwort-Systemen zum Einsatz kommen.
Prozesse und Kernkomponenten von Natural Language Processing
Generell kann man die Funktionsweise von NLP gobe in die folgendenden Prozessschritte aufgliedern:
- Datenbereitstellung
- Datenvorbereitung
- Textanalyse
- Textanreicherung
Klassisch beginnt der Prozess mit der Datenbereitstellung über einen Textkorpus, welcher aus mehreren Dokumenten besteht. Diese bestehen aus mindestens einem Wort, meistens aber aus mehreren Sätzen. Ein Textkorpus wären z.B. alle relevanten Dokumente zum Thema SEO. Die einzelnen Dokumente bestehen aus Kapiteln, Absätzen und Sätzen. Die Sätze werden dann pro Satz in einzelne Tokens zerlegt. Hier ein Beispiel aus einem Glossar-Beitrag zu SEO:
Suchmaschinenoptimierung kurz SEO ist eine Methode im Online-Marketing, um die Auffindbarkeit in Suchmaschinen zu verbessern. Die Abkürzung SEO steht für Search Engine Optimization. In den letzten Jahren hat sich mit Search Experience Optimization auch eine zweite Bedeutung durchgesetzt. In der klassischen Suchmaschinenoptimierung wird zwischen Onpage-SEO und Offpage-SEO unterschieden.
Die einzelnen Tokens bleiben im Kontext der Sätze, damit die Relationen zwischen ihnen erhalten bleiben. Dadurch bleibt die semantische Beziehung der Absätze, Sätze und Tokens erhalten. In dem Prozessschritt der Datenvorbereitung werden die einzelnen Tokens noch mit Labels bzw. Annotationen versehen.
Das so kommentierte Dokument dient als Grundlage für weitere vorbereitende Maßnahmen wie Text-Embeddings oder die Erkennung und Deutung von Entitäten (Entity Recognition).
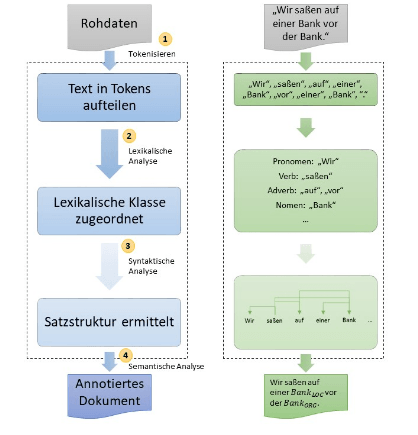
Prozess der Sprachmodellierung; Quelle: http://www.datenbanken-verstehen.de/lexikon/natural-language-processing/
Dann können im nächsten Schritt Modelle auf die vorbereiteten Dokumente angewendet werden. Diese Sprachmodelle werden auf Basis von Machine Learning bzw. Trainingsdaten erlernt. In diesem Prozessschritt werden die Trainingsdaten in Tokens aufgeteilt, einer lexikalischen Klasse zugeordnet und Satzstrukturen ermittelt. In der abschließenden semantischen Analyse werden Entitäten identifiziert und gemäß ihrer Bedeutung mit Kommentaren versehen.
Die Kernkomponenten von NLP sind Tokenization zu deutsch Tokenisierung, Kennzeichnung von Wörtern nach Wortarten (Part of Speech Tagging), Lemmatisierung, Wort-Abhängigkeiten (Dependency Parsing), Parse Labeling, Extraktion von benannten Entitäten (Named Entity Recognition), Salience-Scoring, Sentiment-Analysen, Kategorisierung, Text-Klassifizierung, Extrahierung von Content-Typen und Identifikation einer impliziten Bedeutung aufgrund der Struktur.
- Tokenisierung: Tokenisierung ist der Vorgang, bei dem ein Satz in verschiedene Begriffe unterteilt wird.
- Kennzeichnung von Wörtern nach Wortarten: Wortartenkennzeichnung klassifiziert Wörter nach Wortarten wie z.B. Subjekt, Objekt, Prädikat, Adjektiv …
- Wortabhängigkeiten: Wortabhängigkeiten schafft Beziehungen zwischen den Wörtern basierend auf Grammatikregeln. Dieser Prozess bildet auch „Sprünge“ zwischen Wörtern ab.
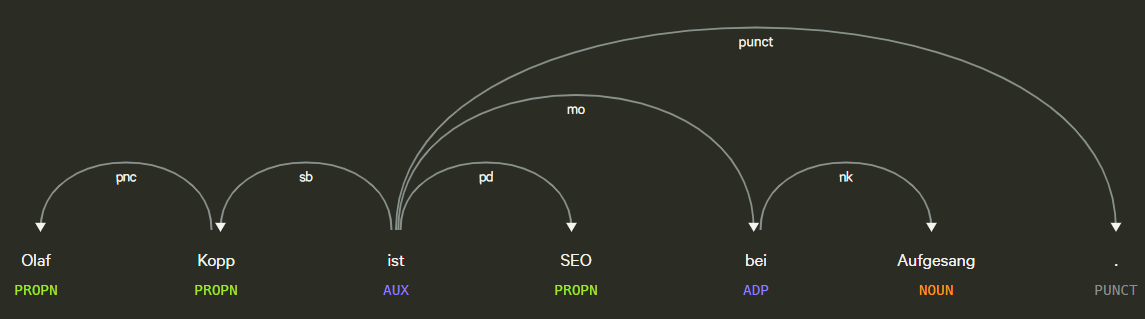
Beispiel für Part of Speech Tagging und Dependency Parsing, Quelle: Explosion.ai Demo
- Lemmatisierung: Die Lemmatisierung bestimmt, ob ein Wort verschiedene Formen hat und normalisiert Abwandlungen zur Grundform,. Zum Beispiel ist die Grundform von Tiere, Tier oder von verspielt, Spiel.
- Parsing Labels: Die Kennzeichnung klassifiziert die Abhängigkeit oder die Art der Beziehung zwischen zwei Wörtern, die über eine Abhängigkeit verbunden sind.
- Analyse und Extraktion von benannten Entitäten: Dieser Aspekt sollte uns aus den vorangegangenen Beiträgen bekannt sein. Damit wird versucht, Wörter mit einer „bekannten“ Bedeutung zu identifizieren und Klassen von Entitätstypen zuzuordnen. Im Allgemeinen sind benannte Entitäten Menschen, Orte und Dinge (Substantive). Entitäten können auch Produktnamen enthalten. Dies sind im Allgemeinen die Wörter, die ein Knowledge Panel auslösen. Aber auch Begriffe, die kein eigenes Knowledge Panel auslösen können Entität sein. Dazu mehr im Beitrag Was ist eine Entität ? Was sind Entitäten ?
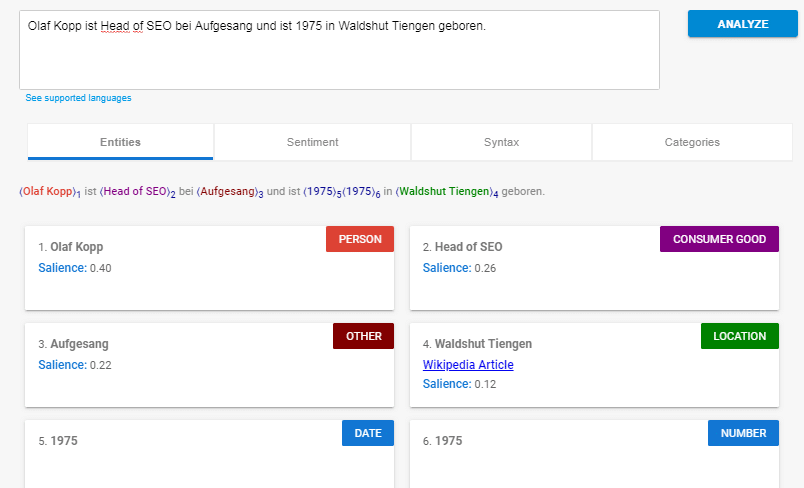
Beispiel für eine Entitäten-Analyse mit der Natural Language Processing API von Google.
- Salience-Scoring: Salience bestimmt, wie intensiv ein Text sich mit einem Thema beschäftigt. Dies wird in NLP basierend auf den sogenannten Indikatorwörtern bestimmt. Im Allgemeinen wird der Bekanntheitsgrad durch das Mitzitieren von Wörtern im Web und die Beziehungen zwischen Entitäten in Datenbanken wie Wikipedia und Freebase bestimmt. Google wendet dieses Verknüpfungsdiagramm wahrscheinlich auch auf die Entitätsextraktion in Dokumenten an, um diese Wortbeziehungen zu bestimmen. Eine ähnliches Vorgehen kennen erfahrene SEOs von der TF-IDF-Analyse.
- Sentiment-Analysen: Kurz gesagt, dies ist eine Bewertung der in einem Artikel zum Ausdruck gebrachten Meinung (Ansicht oder Haltung) zum im Text behandelten Entitäten.
- Fachkategorisierung: Auf Makroebene klassifiziert NLP Text in Betreffkategorien. Die Kategorisierung von Themen hilft dabei, allgemein zu bestimmen, worum es in dem Text geht.
- Textklassifizierung & Funktion: NLP kann noch weiter gehen und die beabsichtigte Funktion bzw. Zweck des Inhalts bestimmen.
- Extrahierung von Content-Typen: Google kann mithilfe von Strukturmustern bzw. des Kontext den Inhaltstyp eines bestimmten Texts ohne die Ausweisung mit strukturierten Daten bestimmen. Das HTML, die Formatierung des Texts und der Datentyp des Texts (Datum, Ort, URL usw.) können verwendet werden, um den Text ohne zusätzliches Markup zu verstehen Mithilfe dieses Prozesses kann Google ermitteln, ob es sich bei Text um ein Ereignis, ein Rezept, ein Produkt oder einen anderen Inhaltstyp handelt, ohne dass Markups verwendet werden müssen.
- Identifikation einer impliziten Bedeutung aufgrund der Struktur: Die Formatierung eines Textkörpers kann seine implizite Bedeutung ändern. Überschriften, Zeilenumbrüche, Listen und Nähe vermitteln ein sekundäres Verständnis des Textes. Wenn beispielsweise Text in einer HTML-sortierten Liste oder in einer Reihe von Überschriften mit Zahlen davor angezeigt wird, handelt es sich wahrscheinlich um einen Vorgang oder eine Rangfolge. Die Struktur wird nicht nur durch HTML-Tags definiert, sondern auch durch die visuelle Schriftgröße / -stärke und -nähe beim Rendern.
Einige dieser Kerneleemente von Natural Language Processing sollten Dir durch die vorhergenden Beiträge dieser Artikelreihe bekannt sein wie z.B. die Extrahierung benannter Entitäten oder Identifikation einer impliziten Bedeutung aufgrund von Struktur-Elementen.
Dass Google viele dieser Prozesse bereits beherrscht zeigt die Natural Language Processing API, auf die ich nachfolgend eingehen möchte.
Was ist die Natural Language Processing API von Google?
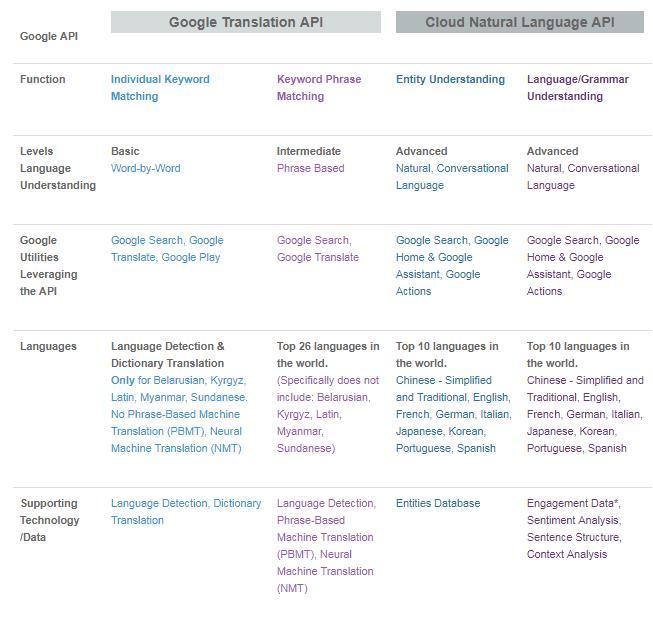
Die Natural Language Processing API ist eine Schnittstelle, die Google Entwicklern bereitstellt, um auf die Google-eigenen Datenbanken, Algorithmen bzw. Machine-Learning-Ressourcen in Sachen Natural Language Understanding kurz NLU zuzugreifen. So kann die Natural Language API von jedermann genutzt werden, um z.B. Sentiment-Analysen, Entitäten-Erkennung, Syntaxanalysen, Inhaltsklassifizierung und anderen Aufgaben der Text-Annotation durchzuführen.
Die Cloud Natural Language API extrahiert Daten aus unstrukturierten Texten. Neben der Extraktion von Informationen wie Orten, Personen und Ereignissen, kann die API auch die Stimmung in Texten (z.B. Social Media Kommentaren) erkennen und Kundenabsichten analysieren (z.B. in Chatbots). Zur Informationsgewinnung kombiniert sie mehrere Google Cloud APIs (s.u.: Cloud Speech API, Vision API und Translation API) zu einem Produkt.
Bei der Nutzung kann auf einen von Google vortrainierten Algorithmus oder selbst angelernten Algorithmus zurückgegriffen werden.
Die Nutzung der API ist je nach Aufgabe teilweise kostenlos oder wird nach Zeit oder nach Anzahl der API-Zugriffe abgerechnet.
Anhand eines Beispiels werde ich nachfolgende einige Funktionen erläutern. Da aktuell die Demo der Natural Language Processing API nicht funktioniert habe ich mir die Screenshots von den Kollegen von digitale Wunderwelt geborgt.
Syntax-Analyse über die Google NLP-API
Hier ein Beispiel der Syntax-Analyse:
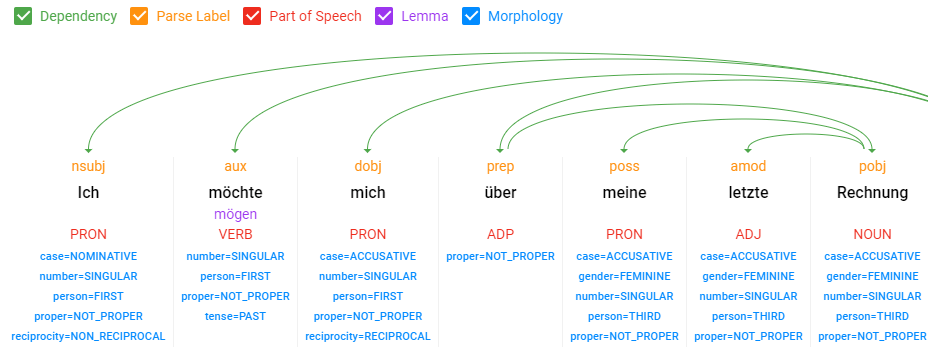
Beispiel Syntax-Analyse über die NLP-API von Google, Quelle: digitale-wunderwelt.de
Man sieht, dass Google hier die Wort-Typen, wie Nomen, Verben, Adjektive … als auch Wort-Abhängigkeiten identifiziert und die Lemmatisierung durchführt.
Entitäten-Analyse über die Google NLP-API
Hier ein Beispiel für die Entitäten-Analyse über die NLP-API von Google.
Beispiel Entitäten-Analyse über die NLP-API von Google
Hier erkennt Google Entitäten, ordnet diesen Klassen von Entitätstypen zu und vergibt einen Salience-Score, der besagt welches die Haupt-Entität bzw. das Objekt in diesem Satz ist. Head of SEO oder Wadshut-Tiengen sind Subjekte bzw. Neben-Entitäten. Insofern es einen Wikipedia-Beitrag zur Entitäten gibt wird der Link dorthin gleich mitgeliefert. Daran erkennt man, dass Google auch Entitäten erkennt, die keinen Wikipedia-Eintrag haben. Inwiefern, diese bereits Berücksichtigung im Knowledge Graph bekommen ist unklar. An der Klassifizierung von „Head of SEO“ als Consumer Good sieht man allerdings auch, dass die Zuordnung nach Klassen bzw. Entitätstypen noch fehlerhaft ist.
Sentimentanalyse über die Google NLP-API
Hier ein Beispiel für die Sentimentanalyse über die NLP-API von Google.
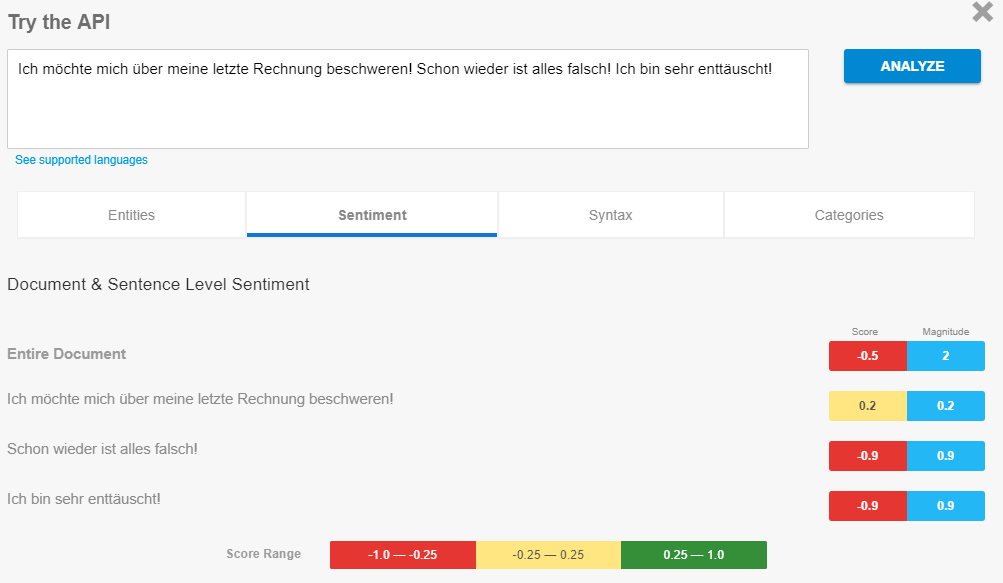
Beispiel Sentimentanalyse über die NLP-API von Google, Quelle: digitale-wunderwelt.de
Hier analysiert Google die Stimmung bzw. Meinung in dem Satz. Der Sentiment-Score gibt an, ob die Stimmung negativ oder positiv ist. Interessant ist, dass man diese Analyse auch auf Entitäten beziehen kann. Das ist von daher spannend, dass Google Kundenstimmen und Berichterstattungen rund um eine Marke, Produkt, Unternehmen … etc durchführen kann und ggf. so etwas im Ranking zu bestimmten Themen berücksichtigen könnte.
Inhaltsklassifizierung über die Google NLP-API
Hier habe ich leider keinen Screenshot, fasse deswegen kurz zusammen was die API macht. Als Ergebnis einer Inhaltsklassifizierung über die API bekommt man neben der Kategorie auch einen Confidence Score mitgeliefert, der sich zwischen 0 und 1 bewegt. Dieser sagt aus wie zutreffend die Kategorie betreffend dem Inhalt ist.
Wie ich später noch erläutere spielt die Vor-Klassifizierung von Inhalten eine wichtige Rolle effektives NLP. In welche Klassen bzw. semantische Kontexte Google Inhalte einordnet kann man hier sehen.
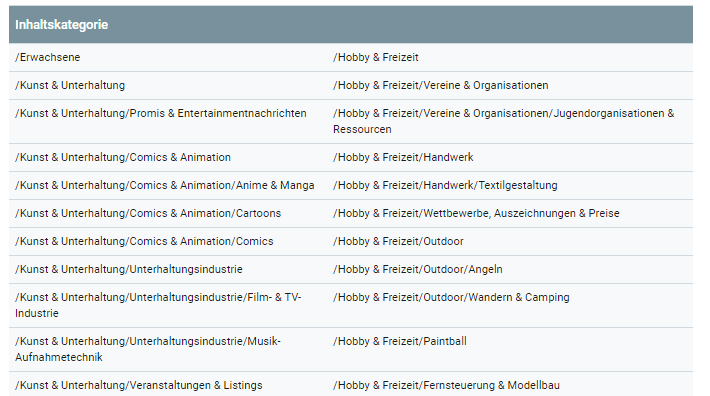
Quelle: https://cloud.google.com/natural-language/docs/categories
Die aufgeführten Inhaltskategorien werden in verschiedenen Hierarchiebenen in Haupt- und Subkategorien unterteilt. Darüber welche Sets von Eigenschaften den Kategorien zugeordnet sind habe ich nichts gefunden. Schade eigentlich 🙂
Tipp für Nerds!
Weiterführende Links zu den Anleitungen der einzelnen Features der Natural Language Processing API für Entwickler findest Du hier:
 Anleitung: Stimmung analysieren mit der Sentimentanalyse
Anleitung: Stimmung analysieren mit der Sentimentanalyse
Anleitung: Entitäten analysieren
NLP bei der Entitätsanalyse
Für Informationen zu Entitäten stehen Google Billionen von Dokumenten im eigenen Index und noch mehr Suchanfragen-Kombinationen zur Verfügung. Gerade Suchanfragen sind ideal zum Trainieren von Semantik, da sie eine Intention und einen Kontext aufweisen, welcher in sich abgeschlossen ist. ( Hier eine Beitrag dazu wie Bing diese Methodik nutzt.)
Eine Methode zur Entitätsanalyse ist Natural Language Processing angewendet auf Dokumente. Google beschreibt den Vorgang wie folgt:
Die Entitätsanalyse stellt Informationen über Entitäten im Text bereit, die sich im Allgemeinen auf benannte „Dinge“ beziehen, wie zum Beispiel berühmte Personen, Sehenswürdigkeiten, allgemeine Objekte usw.
Entitäten fallen im weitesten Sinn in zwei Kategorien: Eigennamen, die eindeutigen Entitäten zugeordnet werden wie bestimmte Personen, Orte usw. oder Gattungsnamen. Bei der Verarbeitung von Natural Language auch „Substantive“ genannt. Hier kann eine allgemeine Regel gut befolgt werden: Wenn es sich um ein Substantiv handelt, kann es als „Entität“ bezeichnet werden. Entitäten werden im Originaltext als indexierte Offsets zurückgegeben…
Die Entitätsanalyse gibt eine Gruppe der erkannten Entitäten und der mit diesen Entitäten verknüpften Parameter zurück, wie zum Beispiel Entitätstyp, Relevanz der Entität für den Gesamttext und Textstellen, die sich auf dieselbe Entität beziehen. Entitäten werden in der Reihenfolge ihrer
salience-Scores (vom höchsten bis zum niedrigsten) zurückgegeben, die ihre Relevanz für den Gesamttext wiedergeben.Quelle: https://cloud.google.com/natural-language/docs/basics#natural_language_features
Über diesen Weg lassen sich Informationen zu den in dem jeweiligen Dokument vorkommenden Entitäten sammeln und dem Knowledge Graph oder einem anderen Fact Repository zuführen. Durch häufige Kookkurrenzen von Entitäten lassen sich darüber auch Beziehungen zwischen Entitäten ermitteln.
- Die Sentimentanalyse pro Entität untersucht den gegebenen Text auf bekannte Entitäten (Eigennamen und Gattungsnamen), gibt Informationen über diese Entitäten zurück und erkennt die in der Entität vorherrschende emotionale Stimmung, insbesondere um zu erkennen, ob der Autor eine positive, negative oder neutrale Einstellung hat. Die Entitätsanalyse wird mit der Methode
analyzeEntitySentimentdurchgeführt.
Ob diese Informationen im Knowledge Graph oder woanders z.B. bei der Annotation der Inhalte im klassischen Suchindex genutzt werden ist nicht klar. Laut den offiziellen Google-Beschreibungen sehen die Antworten einer Entitätsanalyse sehr ähnlich aus wie die Ergebnisse aus den Abfragen der Knowledge Graph API. Von daher kann man davon ausgehen, dass Google die Entitätsparameter wie z.B. Entitätstyp oder Wikipedia-URL (falls vorhanden) aus dem Knowledge Graph bezieht. Ob neu gewonnenen Informationen dann wieder zurück in den Knowledge Graph gespielt werden ist unklar. Ich glaube nicht, dass die gewonnenen Informationen bisher in den Knowledge Panels erscheinen, da zu unvalide.
Neben der Entitätsanalyse nutzt Google Natural Language Processing auch für Sentimentanalysen, Syntax-Analysen und Inhaltsklassifizierungen von Dokumenten.
- Die Sentimentanalyse untersucht den gegebenen Text auf die darin vorherrschende emotionale Stimmung, insbesondere um zu erkennen, ob der Autor eine positive, negative oder neutrale Einstellung hat. Die Sentimentanalyse wird mit der Methode
analyzeSentimentdurchgeführt.- Die Syntaxanalyse extrahiert linguistische Informationen und unterteilt den gegebenen Text in eine Reihe von Sätzen und Tokens (im Allgemeinen Wortgrenzen) für eine weitere Analyse dieser Tokens. Die Syntaxanalyse wird mit der Methode
analyzeSyntaxdurchgeführt.- Die Inhaltsklassifizierung analysiert Textinhalt und gibt eine Inhaltskategorie für den Inhalt zurück. Die Inhaltsklassifizierung wird mit der Methode
classifyTextdurchgeführt.
Word Embedding und Natural Language Processing
Word Embeddings zu deutsch Worteinbettungen sind eine Möglichkeit für Google, Text zu analysieren. Über Word Embedding können unterschiedliche Inhalte sei es ein kurzer Tweet oder eine Abfrage, ein Blogbeitrag oder eine Website, und die darin enthaltenen Wörter durch ihren Kontext, also die umliegenden Wörter und Entitäten, besser verstanden werden. Durch Word Embeddings lassen sich fehlende Begriffe ergänzen bzw. umschreiben, um einen Satz oder einen Begriff verständlicher zu machen. Diese Methode wird auch für die Interpretation von Suchanfragen mittels Rankbrain durch Google eingesetzt.
Bekannte Modelle für Word-Embedding bzw. Vektorraumanalysen für die Anwendung von NLP sind zum Beispiel Word2vec in den zwei verschiedenen Anwendungen CBOW oder Skipgram und das darauf aufbauende von Facebook entwickelte Fasttext Embedding, sowie die sich daraus entwickelten Contextual Embeddings wie z.B. ULM-Fit, Elmo und BERT. Doch das Problem bei diesen Modellen ist der Fokus auf die Begrifflichkeiten.
Bei diesen Modellen wird der Kontext, in dem die Wörter genutzt werden nicht berücksichtigt. Nur über den Kontext ist es möglich Word Embeddings zu trainieren, erst die neue Technologie der Contextual Embeddings schafft es bei gleichen Wörtern zwischen unterschiedlichen Kontexten zu differenzieren. Für Word2vec ist das Wort Jaguar immer gleich, für Contextual Embeddings wie BERT wird zwischen Jaguar im Kontext Automobile und Jaguar im Kontext Tier unterschieden. Je nach Input wird somit zwischen den Bedeutungseinheiten trotz gleicher Schreibweise differenziert und beim Training eines Embeddings nur der entsprechend richtige Kontext verändert ohne das sich Bedeutungseinheiten vom Bereich Automobile mit dem Bereich Tiere näherkommen.
Die Wörter, die wir sprechen und schreiben können oft nur im semantischen Kontext verstanden werden. Erst dieser Kontext verleiht Wörtern und Sätzen die Bedeutung. Gleiches gilt für die Wörter, die wir auf einer Website verwenden.
Betrachten wir zum Beispiel diese beiden Sätze: 1) „Der Jaguar ist aus dem Zoo ausgebrochen.“ 2) „Der Jaguar des Nachbarns ist kaputt.“ Das Wort Jaguar unterscheidet sich in diesen beiden Sätzen je nach Kontext. Vernünftigerweise sollte man zwei verschiedene Vektorräume des Worts Jaguar basierend auf ihren zwei verschiedenen Bedeutungen nutzen.
Es ist daher sinnvoll einen Algorithmus so zu programmieren, dass bereits vor dem zuführen der Trainingsdaten ein Text in mögliche semantische Kontexte eingeordnet werden kann. Das kann die Effektivität bei der Verarbeitung natürlicher Sprache erhöhen.
Im obigen Jaguar-Beispiel könnte ein semantischer Kontext „Autos“ und ein anderen „Tiere“ sein. Der Ansatz hinter dieser Methode wird auch als „Frame Semantics“ bezeichnet. Der kontextuelle Rahmen wird dabei durch bestimmte Eigenschaften definiert. So könnte zu dem kontextuellen Rahmen „Autos“ Eigenschaften wie PS, Fahrer, Verbrauch, Luftverschmutzung … gehören. Ein ähnliches Vorgehen habe ich bereits in den vorangegangen Beiträgen hinsichtlich Klassifizierung nach Entitäten-Typen, Ereignissen … beschrieben. Mehr dazu in Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ? und Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest .
Das spannende an diesem Ansatz ist auch, dass Google darüber auch Inhaltsklassifizierung durchführen kann. Sprich Google legt den kontextuellen Rahmen eines Inhalts bzw. Dokuments fest und kann darüber den thematischen als auch fnktionalen Kontext ermitteln. Darüber lässt sich dann ein Übereinstimmung des Inhalts mit der Suchintention eines Suchterms ermitteln.
Eine Rolle könnte hier das Projekt der Universität Berkeley framenet sein. Das FrameNet-Projekt erstellt eine lexikalische Datenbank für Englisch, die sowohl von Menschen als auch von Maschinen gelesen werden kann. Dabei werden Beispiele für die Verwendung von Wörtern in tatsächlichen Texten mit Anmerkungen versehen. Diese Anmerkungen werden manuell gepflegt und haben deswegen einen hohen Grad an Richtigkeit.
The FrameNet project is a lexical database that contains information about words and phrases (represented as lemmas conjoined with a coarse part-of-speech tag) termed as lexical units, with a set of semantic frames that they could evoke. For each frame, there is a list of associated frame elements (or roles, henceforth), that are also distinguished as core or non-core.2 Sentences are annotated using this universal frame inventory. For example, consider the pair of sentences in Figure 1. COMMERCE BUY is a frame that can be evoked by morphological variants of the two example lexicalunits buy.V and sell.V. Buyer, Seller and Goods are some example roles for this frame.
Auf diese Datenbank und andere wie z.B. Wordnet und german.net kann Google zugreifen um verschiedene Aufgaben im Rahmen der Natural Language Processing API durchzuführen.
Zu dieser Methode gibt es ein wissenschaftliches Papier von Google namens Semantic Frame Identification with Distributed Word Representations
We present a novel technique for semantic frame identification using distributed representations of predicates and their syntactic context; this technique leverages automatic syntactic parses and a generic set of word embeddings. Given labeled data annotated with frame-semantic parses, we learn a model that projects the set of word representations for the syntactic context around a predicate to a low dimensional representation. The latter is used for semantic frame identification; with a standard argument identification method inspired by prior work, we achieve state-ofthe-art results on FrameNet-style framesemantic analysis.
In diesem Papier wird ein Konzept beschrieben wie man aufgrund von Word Embeddings automatisiert kontextuelle Klassen mit den zugehörigen repräsentierenden Eigenschaften festlegen kann. Ziel ist es den relevantesten kontextuellen Rahmen für den jeweiligen Satz oder Text festzulegen und von konkurrierenden Kontexten abzugrenzen.
Mehr Details zum Thema semantische Rahmenkontexte und Frame.net findest in den nachfolgenden zwei Videos:
Deswegen fokussieren sich moderne Deep-Learning-Modelle wie z.B. Embedding from Language Model (ELMo) beim Natural Language Proecessing mehr auf den Kontext. ELMo erzeugt verschiedene Vektorräume für dasselbe Wort in verschiedenen Sätzen. Experten raten dazu Modelle wie ELMo mit standardmäßigen Methoden wie Glove und Word2Vec zu kombinieren.
Wer sich mehr dafür interessiert empfehle ich den Beitrag Modern Deep Learning Techniques applied applied to Natural Language Processing.
Einsatz von NLP in der Suche
Ich denke, dass Natural Language Processing in Bezug auf die Google-Suche vor allem in den folgenden Bereichen genutzt wird:
- Interpretation von Suchanfragen (Rankbrain / BERT)
- Klassifizierung von Thema und Zweck von Dokumenten
- Entitäten-Analyse in Dokumenten, Suchanfragen und Social-Media-Posts
- Für Featured Snippets und Voice Search
- Interpretation von Video-Inhalten
- Ausbau und Verbesserung des Knowledge Graphs
Wie wichtig Google das Verstehen von natürlicher Sprache ist zeigen einige Aussagen zu der Veröffentlichung des BERT Updates im Oktober 2019.
At its core, Search is about understanding language. It’s our job to figure out what you’re searching for and surface helpful information from the web, no matter how you spell or combine the words in your query. While we’ve continued to improve our language understanding capabilities over the years, we sometimes still don’t quite get it right, particularly with complex or conversational queries. In fact, that’s one of the reasons why people often use “keyword-ese,” typing strings of words that they think we’ll understand, but aren’t actually how they’d naturally ask a question.
BERT: Natural Language Processing für die Interpretation von Suchanfragen und Dokumenten
Im Oktober 2019 gab Google ein neues Update namens BERT bekannt, das nach Rankbrain die wichtigste Weiterentwicklung in der Google-Suche seit einigen Jahren sein soll. Es basiert auf NLP, soll die Interpretation von Suchanfragen verbessern und 10% aller Suchanfragen betreffen.
BERT spielt nicht nur eine Rolle zur Interpretation der Suchanfrage, sondern auch für das Ranking und die Zusammenstellung von Featured Snippets, als auch die Deutung von Text-Fragementen in Dokumenten.
Well, by applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information. In fact, when it comes to ranking results, BERT will help Search better understand one in 10 searches in the U.S. in English, and we’ll bring this to more languages and locales over time.
Natural Language Processing ist die wichtigste Methodik zur Identifikation von Entitäten
Wie im Beitrag Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ? erläutert spielt Natural Language Processing bei der Identifikation von Entitäten und deren Bedeutung aktuell die wichtigste Rolle für Google.
Die Praxis zeigt allerdings, dass Google bisher nur sehr begrenzt auf unstrukturierte Informationen zurückgreift, zumindest was die Ausspielung in den Knowledge Panels angeht. Erste praktische Anwendungen für Data Mining aus unstrukturierten Daten finden wir in den Featured Snippets wieder, obwohl das eher nach dem direkten Einsatz von Natural Language Processing aussieht ohne den Knowledge Graph einzubeziehen.
Auch bei bisher nicht im Knowledge Graph erfassten Entitäten arbeitet Google aktuell nur mit NLP, um diese zu identifizieren, unabhängig vom Knowledge Graph. Für die Identifikation von Entitäten und thematische Einordnung leistet Natural Language Processing gute Dienste. Allerdings wäre dadurch nur das Kriterium der Vollständigkeit ggf. Aktualität gewährleistet. NLP alleine gewährleistet aber nicht den Anspruch auf Richtigkeit.
Ich denke, dass Google im Bereich Natural Language Processing schon recht gut ist, aber bei der Evaluation von automatisch extrahierten Informationen hinsichtlich Richtigkeit noch nicht zufriedenstellende Ergebnisse erzielt. Das wird wohl der Grund sein, warum Google hier noch vorsichtig agiert, was direkte Positionierung in den SERPs angeht.
Natural Language Processing für den Aufbau des Knowledge Graph
Wie bereits im vorangegangenen Beitrag Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ? erläutert ist das Data Mining für eine Wisses-Datenbank wie den Knowledge Graph aus unstrukturierten Daten wie z.B. Websites nicht trivial. Vor allem da neben der Vollständigkeit ist die Richtigkeit der Informationen wichtig. Die Vollständigkeit kann Google inzwischen sehr gut skalierbar über Natural Language Processing garantieren, wie die Ergebnisse der Natural Language Processing API zeigen. Nur über eine themenabdeckende Datengrundlage und den entsprechenden Kontext ist ein Salience-Scoring möglich.
Dafür werden die bereits weiter oben erläuterten Schritte aus Datenbereitstellung, Datenvorbereitung, Textanalyse und Textanreicherung durchlaufen. Sätze, Absätze und komplette Texte werden über NLP in Abschnitte zerlegt, Entitäten identifiziert und mit Kommentaren (Annotationen) ergänzt.
Dadurch ist die Extrahierung von Wissen aus unstrukturierten Daten umsetzbar. Auf dieser Grundlage können dann Beziehungen zwischen Entitäten und ein Knowledge Graph erstellt werden. Dabei hilft das „Part of Speech Tagging„. Nomen sind potentielle Entitäten und Verben stellen oft die Beziehung der Entitäten zueinander dar. Adjektive beschreiben die Entität und Adverben beschrieben die Beziehung.
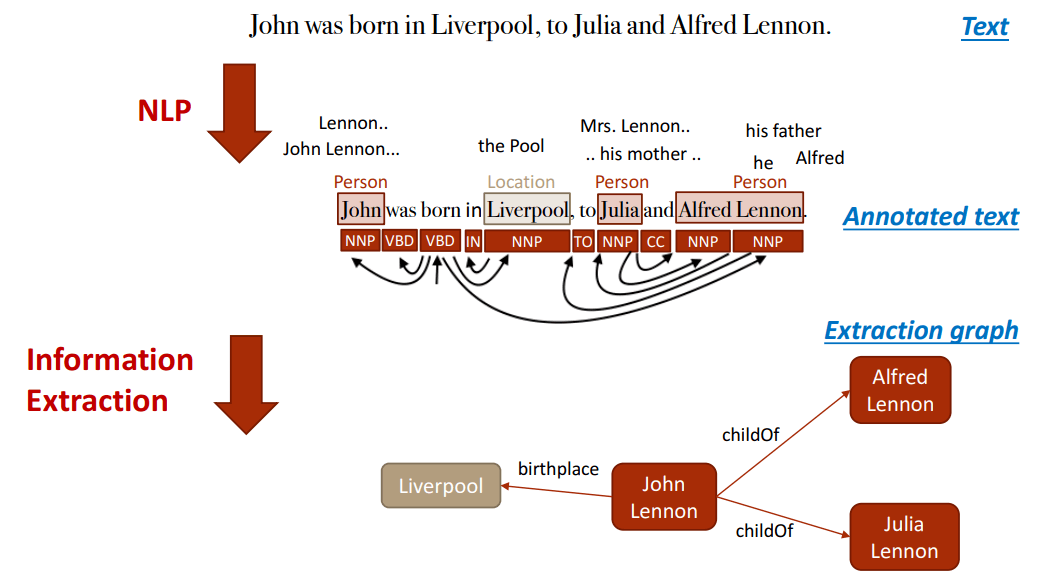
Beispiel für NLP beim Aufbau eines Knowledge Graphs; Quelle: https://kgtutorial.github.io/wsdm-slides/Part2_knowledge-extraction.pdf
Bei mehrdeutigen Begriffen oder Synonymen können aufgrund der im Kontext genannten weiteren Begriffe genauer definiert werden um welche Entität es sich jetzt handelt. Über diesen Weg lassen sich dann auch erkannte Entitäten Klassen von Entitätstypen zuordnen. So wird die Automarke Jaguar zusammen mit anderen Begriffen genannt als das Tier.
Für die Erkennung und Zuordnung von Entitäten zu Entitätstypen bedarf es eine initial von Menschen erstellte Hierarchie an Klassen inklusive bestimmter Attribute, die nach und nach mit neuen Attributen automatisiert ergänzt werden können. Selbst lernende Algorithmen wie man es aus dem Machine Learning bzw. Deep Learning kennt sind auch in der Lage neue Klassen von Entitätstypen eigenständig zu erkennen und zu ergänzen.
Bis zu diesem Schritt ist „Vollständigkeit“ als Qualitätskriterium für einen Knowledge Graph garantiert. Das zweite wichtige Qualitätskriterium ist die Richtigkeit. Während nach meiner Meinung die Vollständigkeit nahezu ohne weiteres menschliches Zutun sicher gestellt werden kann, sehe ich bei der Richtigkeit immer noch einen hohen manuellen Aufwand. Hier kann aktuell maximal auf Supervised-Machine-Learning-Ansätze zurückgegfriffen werden. Gerade ein korrektes trainiertes hierarchisches semantisches Clustering über unüberwachte Machine-Learning-Methoden stellt eine sehr große Herausforderung dar. Hier ist ungewiss wann und ob das jemals für nahezu vollständig korrekte Ergebnisse führen kann. (Mehr Informationen zu den unterschiedliche Formen von Machine Learning findest Du im Beitrag Was ist Machine-Learning? Definition, Unterschied zu Artificial Intelligence, Funktionsweise …)
Die Sicherstellung der Richtigkeit der Informationen bedarf ein Scoring bzw. Bewertung. Die Bewertung muss sowohl auf Basis der Endergebnisse als auch auf Basis der Attribute stattfinden. Zudem müssen die verantwortlichen Personen eine gewisse Themen-Expertise mitbringen.
Der Google Knowledge Vault ist der aktuelle „Informations-Lieferant“ für Daten aus unstrukturierten Quellen für den Knowledge Graph und arbeitet vollautomatisiert in den Bereichen der Entitäts-Typen als auch Erkennung und Zuordnung von Standard-Attributen. Die Fakten werden zum Teil automatisiert und zum Teil manuell geprüft und bewertet.
An dieser Stelle möchte ich nicht weiter einsteigen und hoffe, dass meine Ausführungen zu einem grundsätzlichen Verständnis des Thema Natural Language Processing gegeben haben.
Wer hier noch tiefer einsteigen möchte empfehle ich u.a. diese Slides.
Fazit: Aufbau des Knowledge Graphs über Wikipedia, Wikidata und Knowledge Vault
Mit diesem Beitrag möchte ich das Thema Data Mining für den Aufbau des Google Knowledge Graphs weitestgehend abschließen und in den noch folgenden Beiträgen auf konkreter darauf eingehen welche Rolle der Knowledge Graph und Entitäten konkret für die Suche spielen.
Es bleibt festzuhalten, dass nach meiner Meinung den größten Einfluss auf den Knowledge Graph Wikipedia, der Knowledge Vault, Wikidata und strukturierte Datenauszeichnungen haben. Bis auf die durch Webmaster manuell ausgezeichneten strukturierten Daten wird Google mehr oder weniger auf Natural Language Processing zurückgreifen.
- Wikipedia stellt viele semistrukturierte Daten bereit, die über Datenbanken wie z.B. DBpedia noch strukturierter aufbereitet werden und darüber in den Knowledge Graph direkt übernommen werden können. Für mich ist das aktuell noch die wichtigste Datenquelle für Google, da die Informationen manuell geprüft werden. Natural Language Processing spielt hier nur eine Nebenrolle.
- Der Knowledge Vault wird zukünftig immer wichtiger werden, da Google hinsichtlich Vollständigkeit dringend Informationen aus unstrukturierten Datenquellen benötigt. Diese lassen sich nur über Natural Language Processing bzw. Machine Learning für den Knowledge Graph generieren. Inwieweit es Google schafft auf manuell Hilfe verzichten zu können ist Spekulation. Um es skalierbar zu bewerkstelligen wird es aber das angestrebte Ziel sein. Laut den aktuellen oft auch fehlerhaften Ergebnissen sieht es aber so aus, als ob der Knowledge Vault noch in den Kinderschuhen steckt.
- Viele SEOs schauen gerade auf Wikidata wenn es um die Beeinflussung / Manipulation der Knowledge Panels geht. Dort lassen sich relativ einfach Einträge für Entitäten anlegen, die auch noch häufig den Weg in die SERPs finden. Bei Wikidata selbst findet man folgende Aussage:
Während Freebase die offen zugängliche Grundlage für den Knowledge Graph war, gilt das nicht ebenso für Wikidata. Wikidata ist eine bestimmte Quelle des Knowledge Graph unter vielen, hat aber nicht die gleiche Stellung, wie Freebase hatte.
Die Wichtigste Quelle für den Knowledge Graph ist tatsächlich das Internet selber. Du kannst deine eigene Webseiten erstellen mit schema.org dieses wird gelesen und verarbeitet von allen größeren Suchmaschinen.
Da es aktuell doch noch relativ einfach ist über Wikidata Knowledge Panels zu erzeugen, wie einige Tests von SEO-Kollegen gezeigt haben muss ich diese Aussage etwas relativieren. Wikidata scheint hier eine durchaus relevante Quelle zu sein. Allerdings sind die Moderatoren bei Wikidata nicht ganz so streng wie die die Wikipedianer. Von daher sehe ich es auch eher als Zwischenlösung, solange bis der Knowledge Vault nahezu fehlerfrei funktioniert.
- Die Auszeichnung von Inhalten durch strukturierte Daten scheint ein probates Mittel zur Snippet-Optimierung zu sein. Mir fehlen allerdings aktuell die (deutschen) Beispiele bei denen eine Auszeichnung mit strukturierten Daten zu einer Veränderung von Inhalten in Knowledge Panels geführt haben. Eigene Tests sind bisher ergebnislos geblieben. Mir sind bisher nur wenige Beispiele aus den USA bekannt. Wenn Du deutsche Beispiele hast kannst Du mir sie gerne schicken und ich baue sie dann gerne mit einer Erwähnung ein. Aber auch die Auszeichnung mit strukturierten Daten halte ich wie bereits beschrieben nur für eine Zwischenlösung. Gerade für die Anreicherung von Entitäten und Entitätstypen-Klassen mit Standard-Attributen spielen sie eine große Rolle in Form von menschlich verifizierten Trainingsdaten. Aber nur solange wie Google sie nicht mehr braucht, da der Algorithmus genug Daten zum lernen für die eigenen Modelle bekommen hat. Mehr dazu im Beitrag Warum strukturierte Daten für Google zukünftig überflüssig werden könnten .
Damit schließe ich das Thema Data Mining für den Knowledge Graph erst einmal ab. Hier eine Übersicht der weiteren Beiträge zu dem Thema:
-
Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index
-
Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph ?
-
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ?
Zum Abschluss noch einige Tools, die ich in diesem Zusammenhang nicht unerwähnt lassen möchte.
Tools
Nachfolgend einige weitere Tools um sich ein bisschen mit dem Thema Textanalyse über NLP auseinanderzusetzen:
Explosion.ai
Mit Explosion.ai kann man einige Dinge wie Part of Speech Tagging und Analyse der Wortabhängigkeiten tun, die man mit der Natural Language Processing API von Google auch machen kann. Ich finde die Google API aber aus SEO-Gründen spannender.
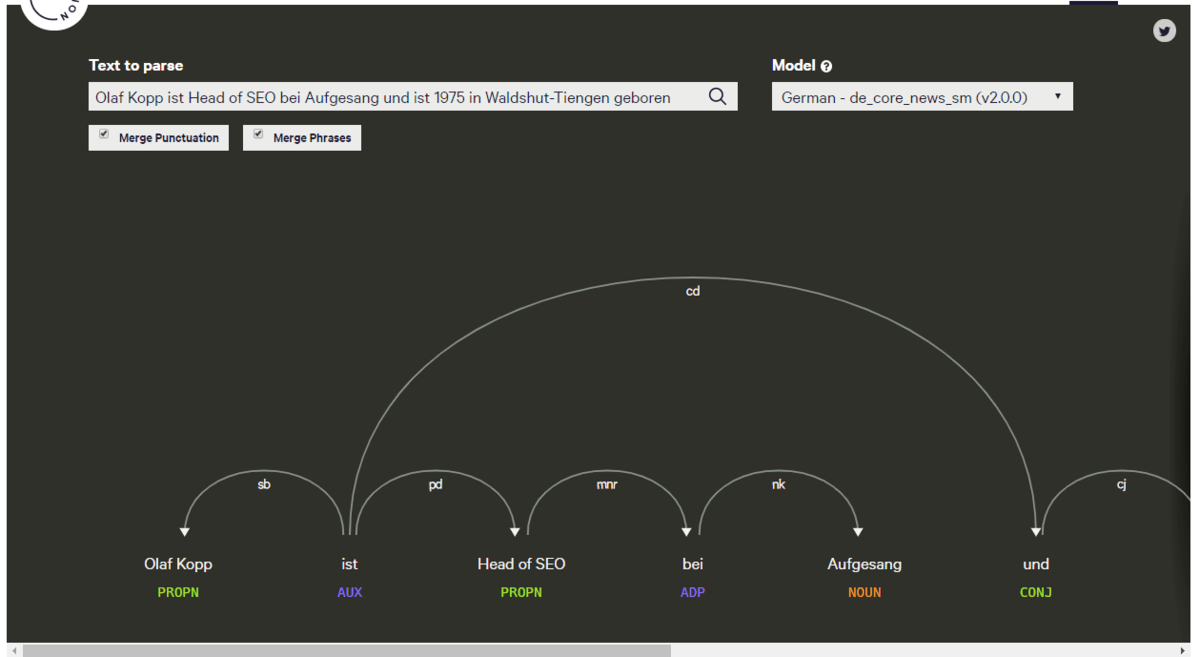
projector.tensorflow.org
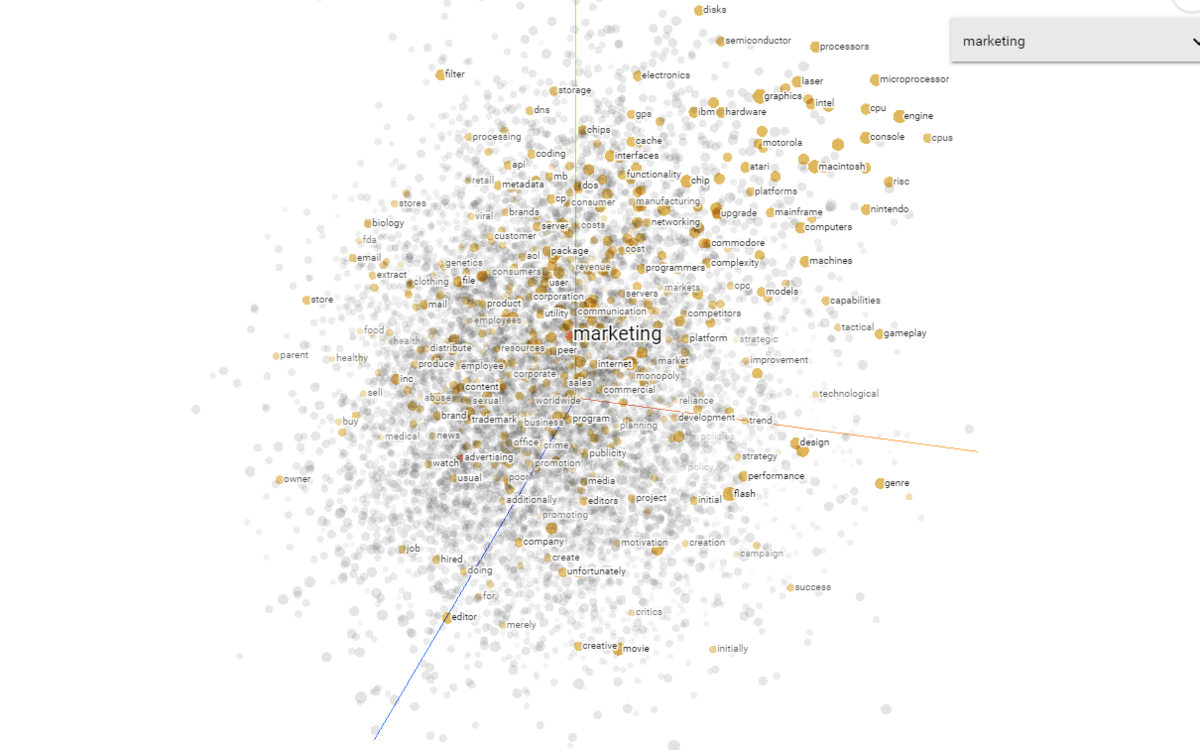
Über dieses Tool lassen sich Nähe von Begriffen zueinander analysieren. Mit Blick auf NLP, Entitäten und den Knowledge Graph könnte es interessant sein welche Begriffe bzw. Attribute in Nachbarschaft zueinander stehen. Dieses Tool basiert auf dem embedding projector von tensorboard, mit dem auch selbst trainierte Embeddings bis zu 100000 Datenpunktec visualisiert werden können.
Chrome Extension zur Entitäten-Extrahierung aus Websites
Eine Chrome Extension namens Extractor de entitades bedient sich der Natural Language Processing API um die Entitäten-Analyse durchzuführen und diese dann in den SERPs zu den jeweiligen Dokumenten auszugeben. Die Extension ist eine nette Spielerei. Die wirklich interessanten Analysen bzw. Aufgaben deckt sie allerdings nicht ab.
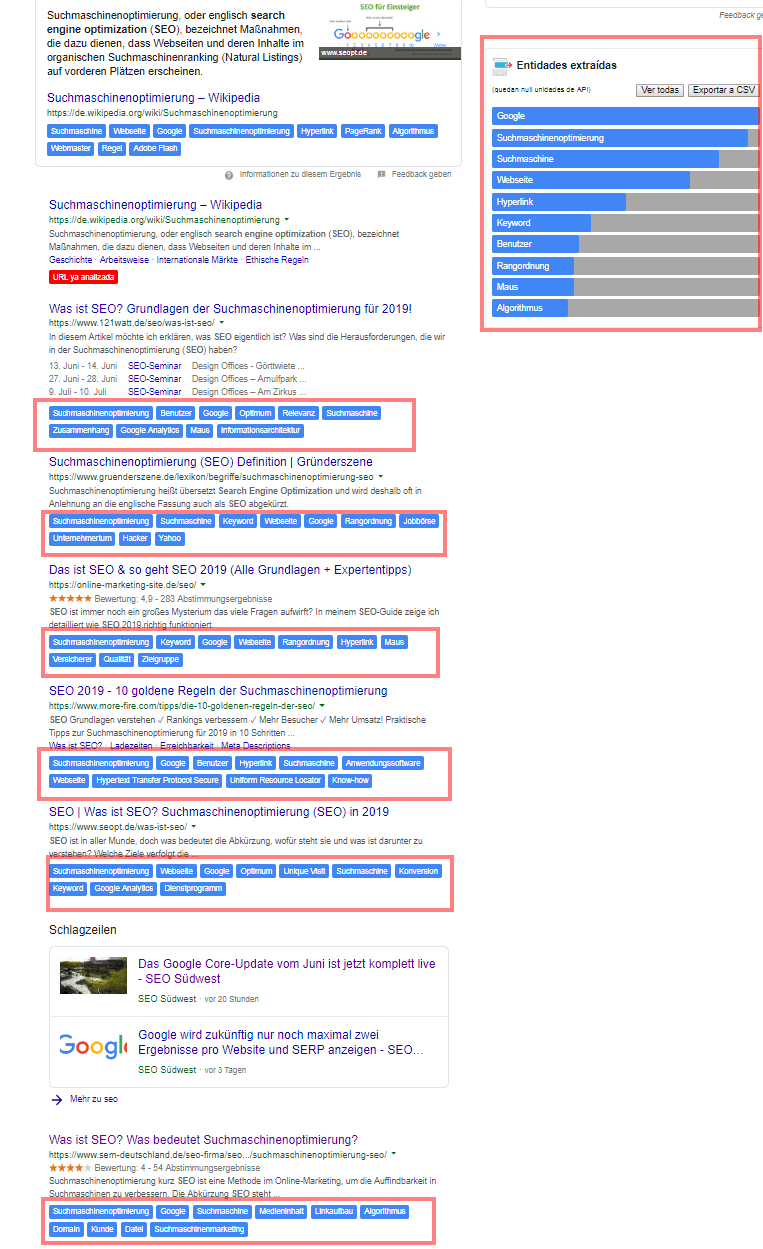
Entitäten-Mining mit der Chrome Extension Extractor de entidades am Beispiel der SERPs zum Begriff „seo“
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.