
E-A-T ist seit den Core-Updates in den letzten Jahren im Fokus der Suchmaschinenoptimierung. Antworten auf die Fragen warum E-A-T so wichtig für das Ranking ist, welche möglichen Signale Google für die Bewertung nutzt und wie man darauf optimiert gibt es in diesem Beitrag.
Inhaltsverzeichnis
- 1 Was ist E-A-T überhaupt?
- 2 Warum ist E-A-T so wichtig?
- 3 E-A-T beeinflusst das Ranking, ist aber kein Rankingfaktor
- 4 E-A-T als Qualitäts-Konzept
- 5 E-A-T als Gatekeeper
- 6 E-A-T-Bewertung für Dokumente, Autoren und Publisher
- 7 Signale für die E-A-T-Bewertung eines Inhalts
- 8 Signale für eine E-A-T-Bewertung von Autoren und Publishern bzw. Websites
- 9 Wie kannst Du die thematische Autorität einer Website feststellen?
- 10 Wie kannst Du für E-A-T optimieren?
- 11 Beispiele für gelungene E-A-T-Optimierung
- 12 Konkrete Handlungsempfehlungen für die E-A-T-Optimierung (Checkliste)
- 13 Quellen:
Was ist E-A-T überhaupt?
E-A-T steht für die drei Begriffe Expertise, Autorität und Trust und dient als Richtlinie für die Such-Evaluatoren für die Bewertung von Suchergebnissen. Die E-A-T-Bewertung spielt insbesondere bei den Your-Money-Your-Life kurz YMYL-Seiten eine sehr wichtige Rolle. Die E-A-T-Bewertung fand in den Quality Rater Guidelines aus dem Jahr 2015 das erste mal Erwähnung. Durch das E-A-T-Konzept werden Inhalte über die Glaubwürdigkeit, Expertise und Autorität der Quelle sowie des Inhalts hinsichtlich Qualität bewertet. Die E-A-T-Bewertung bezieht sich auf den Main Content (MC), den Suplementary Content als auch den Autor, Publisher bzw. die Quelle im Allgemeinen.
Was ist Expertise?
Expertise steht für den Buchstaben E bei E-A-T. Expertise steht für das Wissen und die Erfahrung, die ein Autor oder Publisher besitzt. Expertise bezieht sich nur auf den Autor bzw. Publisher. Experte ist jemand der Spezialwissen in einem oder mehreren bestimmten Bereichen besitzt. In der deutschen Wikipedia findet man folgende Defintion:
Experte (auch Fach- oder Sachkundiger oder Spezialist) ist eine Person, die über überdurchschnittlich umfangreiches Wissen auf einem Fachgebiet oder mehreren bestimmten Sacherschließungen oder über spezielle Fähigkeiten verfügt.
Expertise bedeutet über Expertenwissen zu verfügen und kann sich laut den QRG sowohl auf einen Autor als auch den Publisher von Inhalten bezogen werden. Ich nenne es auch gerne Entitäten-Relevanz. Die Entitäten-Relevanz sorgt dafür, dass Google eine Domain / Publisher oder einen Autor als mögliche Quelle für ein bestimmtes Thema in Betracht zieht.
Was ist Autorität?
Aurotität steht für den Buchstaben A bei E-A-T. Autorität steht für die Bekanntheit eines Autors, der Website oder des Inhalts im jeweiligen Themen-Bereich. Eine Autorität ist laut Wikipedia wie folgt definiert:
„Autorität ist im weitesten Sinne eine soziale Positionierung, die einer Institution oder Person zugeschrieben wird und bewirken kann, dass sich andere Menschen in ihrem Denken und Handeln nach ihr richten.“
In anderen Worten: Eine Autorität ist als Experte anerkannt besitzt also eine gute Reputation und großen Einfluss. Eine Autorität gehört zum Relevant-Set in einer Branche oder einem Thema. Übertragen auf Google ist es eine Quelle, die man auf den ersten Suchergebnisseiten aufführen sollte, weil der Nutzer es erwartet. Gerade bei den YMYL-Themen (our Money Your Life) spielt dieses Kriterium eine große Rolle.
Was ist Trust?
Trust steht für den Buchstaben T bei E-A-T. Trust steht für die Glaubwürdigkeit eines Autors, der Website oder des Inhalts im jeweiligen Themen-Bereich. Vertrauen hängt eng mit der Reputation einer Person oder Quelle zusammen. Zu Reputation steht in der deutschen Wikipedia folgendes:
Reputation bezeichnet im heutigen Sprachgebrauch das Ansehen einer Person, einer sozialen Gruppe oder einer Organisation.
Bei der Reputation geht es um Ansehen. Das bedeutet das Wahrnehmung einer Person oder Organisation von aussen. Reputation und Vertrauen stehen in einem engen direkten Zusammenhang. Dazu in den QRG:
Reputation is an important criteria when using the High rating, and informs the E-A-T of the page. While a page can merit the High rating with no reputation, the High rating cannot be used for any website that has a convincing negative reputation. Remember that when doing research, make sure to consider the reasons behind a negative rating and not just the rating itself.
Mehr dazu im Beitrag E-A-T-Bewertung und YMYL bei Google einfach erklärt
Warum ist E-A-T so wichtig?
Für mich sind E-A-T, Relevanz der Inhalte und die Befriedigung der Suchintention die wichtigsten Punkte auf die Marketer und SEOs achten sollten.
Google steht seit einigen Jahren unter einem großen Druck, was Fehlinformationen in den Suchergebnissen angeht, was das im Februar 2019 auf der Münchener Sicherheitskonferenz vorgestellte Whitepaper „How Google fights Disinformation“ unterstreicht. Mehr dazu im Beitrag Wie Google mit E-A-T, PageRank, Fact Checkern … Fehlinformationen bekämpft .
Google möchte das eigene Suchsystem dahingehend optimieren großartige Inhalte zu den jeweiligen Suchanfragen abhängig vom Kontext des Nutzers bereitzustellen und unter Berücksichtigung der zuverlässigsten Quellen. Die Quality Rater spielen hierbei eine besondere Rolle.
„We publish publicly available rater guidelines that describe in great detail how our systems intend to surface great content… we like to say that Search is designed to return relevant results from the most reliable sources available… But notions of relevance and trustworthiness are ultimately human judgments, so to measure whether our systems are in fact understanding these correctly, we need to gather insights from people.“ Quelle: https://blog.google/products/search/raters-experiments-improve-google-search/
Die Bewertung nach E-A-T-Kriterien spielt für die Quality Rater eine zentrale Rolle.
„They evaluate whether those pages meet the information needs based on their understanding of what that query was seeking, and they consider things like how authoritative and trustworthy that source seems to be on the topic in the query. To evaluate things like expertise, authoritativeness, and trustworthiness—sometimes referred to as “E-A-T”—raters are asked to do reputational research on the sources. „Quelle: https://blog.google/products/search/raters-experiments-improve-google-search/
Für die Customer Experience bei der Nutzung der Suchmaschine steht eine hohe Qualität der Suchergebnisse für Google im Fokus. Das wird deutlich wenn man einen Blick auf Aussagen verschiedener Google-Sprecher zu einem Qualitätsfaktor auf Dokumenten- und Domain-Ebene betrachtet.
So z.B. folgende Aussagen von Paul Haahr auf der SMX West 2016 in seinem Vortrag How Google works: A Google Ranking Engineer’s Story:
“Another problem we were having was an issue with quality and this was particularly bad (we think of it as around 2008 2009 to 2011) we were getting lots of complaints about low-quality content and they were right. We were seeing the same low-quality thing but our relevance metrics kept going up and that’s because the low-quality pages can be very relevant this is basically the definition of a content form in our vision of the world so we thought we were doing great our numbers were saying we were doing great and we were delivering a terrible user experience and turned out we weren’t measuring what we needed to so what we ended up doing was defining an explicit quality metric which got directly at the issue of quality it’s not the same as relevance …. and it enabled us to develop quality related signals separate from relevant signals and really improve them independently so when the metrics missed something what ranking engineers need to do is fix the rating guidelines… or develop new metrics.”
Dieses Zitat stammt aus dem Teil des Vortrags zu den Quality Rater Guidelines und E-A-T. In diesem Vortrag erwähnt Paul auch, dass Trustworthiness der wichtigste Teil von E-A-T ist. Laut Pauls Aussagen sind die in den Quality Rater Guidelines erwähnten Kriterien für schlechte und gute Inhalte und Websites im Allgemeinen die Blaupause dafür wie der Ranking-Algorithmus funktionieren sollte.
Ebenfalls aus dem Jahr 2016 stammt folgende Aussage von John Müller aus einem Google Webmaster Hangout:
For the most part, we do try to understand the content and the context of the pages individually to show them properly in search. There are some things where we do look at a website overall though.
So for example, if you add a new page to a website and we’ve never seen that page before, we don’t know what the content and context is there, then understanding what kind of a website this is helps us to better understand where we should kind of start with this new page in search.
So that’s something where there’s a bit of both when it comes to ranking. It’s the pages individually, but also the site overall.
I think there is probably a misunderstanding that there’s this one site-wide number that Google keeps for all websites and that’s not the case. We look at lots of different factors and there’s not just this one site-wide quality score that we look at. So we try to look at a variety of different signals that come together, some of them are per page, some of them are more per site, but it’s not the case where there’s one number and it comes from these five pages on your website.
Hier betont John, dass es neben den klassischen Relevanz-Bewertungen auch Bewertungskriterien für die komplette Website gibt, die sich auf den thematischen Kontext der gesamten Website beziehen. Das bedeutet, dass es Signale gibt die Google heranzieht, um die komplette Website thematisch einzuordnen als auch zu bewerten. Die Nähe zur E-A-T-Bewertung ist offensichtlich.
Zudem bestätigte Google im April 2020 die Nähe des E-A-T-Konzepts zu den Ranking-Signalen die der Ranking-Algorithmus berücksichtigt bzw. dass Webmaster den eigenen Content gemäß E-A-T bewerten sollten.
„We’ve tried to make this mix align what human beings would agree is great content as they would assess it according to E-A-T criteria. Given this, assessing your own content in terms of E-A-T criteria may help align it conceptually with the different signals that our automated systems use to rank content.“
In den Quality Rater Guidelines findet man diese Passage, die die Wichtigkeit von E-A-T unterstreicht:
“Expertise, Authoritativeness, Trustworthiness: This is an important quality characteristic. …. Important: Lacking appropriate EAT is sufficient reason to give a page a Low quality rating.”
Auch in dem bereits erwähnten Google-Whitepaper findet man diverse Passagen zu E-A-T und den Quality Rater Guidelines:
“We continue to improve on Search every day. In 2017 alone, Google conducted more than 200,000 experiments that resulted in about 2,400 changes to Search. Each of those changes is tested to make sure it aligns with our publicly available Search Quality Rater Guidelines, which define the goals of our ranking systems and guide the external evaluators who provide ongoing assessments of our algorithms.”
“The systems do not make subjective determinations about the truthfulness of webpages, but rather focus on measurable signals that correlate with how users and other websites value the expertise, trustworthiness, or authoritativeness of a webpage on the topics it covers.”
“Ranking algorithms are an important tool in our fight against disinformation. Ranking elevates the relevant information that our algorithms determine is the most authoritative and trustworthy above information that may be less reliable. These assessments may vary for each webpage on a website and are directly related to our users’ searches. For instance, a national news outlet’s articles might be deemed authoritative in response to searches relating to current events, but less reliable for searches related to gardening.”
“Our ranking system does not identify the intent or factual accuracy of any given piece of content. However, it is specifically designed to identify sites with high indicia of expertise, authority, and trustworthiness.”
“For these “YMYL” pages, we assume that users expect us to operate with our strictest standards of trustworthiness and safety. As such, where our algorithms detect that a user’s query relates to a “YMYL” topic, we will give more weight in our ranking systems to factors like our understanding of the authoritativeness, expertise, or trustworthiness of the pages we present in response.”
Die folgende Aussage ist besonders spannend. Dort wird deutlich wie mächtig E-A-T in bestimmten Kontexten und in Bezug auf Ereignisse gegenüber über klassischen Relevanz-Faktoren sein kann.
“To reduce the visibility of this type of content, we have designed our systems to prefer authority over factors like recency or exact word matches while a crisis is developing.“
Die Auswirkungen von E-A-T konnte man in den letzten Jahren an diversen Google Core-Updates, die mit E-A-T in Verbindung gebracht wurden beobachten. Hier zwei Beispiele von Websites aus dem Thema Medizin. Also ein typisches YMYL-Thema. Die Sichtbarkeits-Verluste stehen in einem eingen Zusammenhang mit den Google Core Updates 2018 und 2019.


E-A-T beeinflusst das Ranking, ist aber kein Rankingfaktor
Google nutzt die manuellen Bewertungen der Such-Evaluatoren als Trainingsdaten für die selbst lernenden Ranking-Algorithmen (Stichwort: Supervised Machine Learning), um Muster für qualitativ hochwertige Inhalte und Quellen zu identifizieren. Damit nähert sich Google den Bewertungskriterien in den QRG an. Über diesen Weg könnte Google auch neue bzw. weitere Kriterien über die aus den Quality Rater Guidelines hinaus identifizieren. Fallen durch die Such-Evaluatoren als hochwertig bewertete Inhalte und Quellen immer wieder durch gleiche bestimmte Muster auf und erreicht die Häufigkeit dieser Muster-Eigenschaften einen Schwellenwert könnte Google dieses Kriterium/Signal zukünftig zusätzlich für das Ranking berücksichtigen.
E-A-T ist laut Google kein Rankingfaktor. Es ist als Konzept zu verstehen. E-A-T setzt sich aus diversen Signalen bzw. Kriterien zusammen, nach denen sich drei Such-Evaluatoren bei der Bewertung von Suchergebnissen richten sollen. Das Konzept E-A-T dient als eine Art Blaupause, wie Googles Ranking-Algorithmen Expertise, Autorität und Trust also Qualität ermitteln sollten. Eine Optimierung gemäß dieser Kriterien kann sich positiv auf das Ranking auswirken so Google.
E-A-T als Qualitäts-Konzept
E-A-T ist als Konzept zu verstehen, was alle Ranking-Signale zusammenfasst, die zur Bewertung von Expertise, Autorität und Trust herangezogen werden können. Bei der Klassifizierung der Signale für E-A-T müssen wir erst einmal unterscheiden zwischen Qualitäts-Signalen gemäß E-A-T und Relevanz-Signalen. Relevanz-Signale haben einen direkten Bezug zum Dokument/Suchergebnis wie z.B. Seitentitel, Überschriften, Keywords, Proof-Keywords (TF-IDF), Klickraten in den SERPs, Backlinks auf eine bestimmte URL … Dabei ist die Relevanz immer im Bezug auf die Suchintention der Suchanfrage und ggf. auf den individuellen Kontext des Nutzers zu bewerten. Mehr zum Thema Relevanz im Beitrag Relevanz, Pertinenz und Nützlichkeit bei Google.
Die Qualität von Inhalten versucht Google eher nach allgemeineren Signalen zu bewerten, die sich im Fokus auf den Urheber des Inhalts bzw. den Publisher/Autor hinsichtlich Trust und Autorität beziehen. Für die Bewertung der Expertise können aber auch allgemeingültige Signale bezogen auf das Dokument selbst zum Tragen kommen. Mehr dazu im Verlauf des Beitrags.
E-A-T als Gatekeeper
Die folgende Theorie habe ich aus meinen eigenen Erfahrungen mit diversen Projekten und Informationen seitens Google in den letzten Jahren gesammelt.
Ich gehe davon aus, dass Signale, die gemäß dem E-A-T-Konzept funktionieren eine Gatekeeper-Funktion haben.
Wird ein bestimmter Schwellenwert für E-A-T-Signale bezogen auf ein Thema nicht erreicht werden Dokumente gar nicht erst in ein Relevanz-Scoring auf Dokumentenebene in Betracht gezogen. Sprich sie werden nicht in den Top n Suchergebnissen gelistet. Google wendet ein Relevanz-Scoring nicht auf alle Inhalte eines thematischen Korpus an. Aus Performance-Gründen wird ein Relevanz-Scoring nur auf die Top-n Dokumente eines Korpus angewendet. Wie groß n ist bleibt Spekulation. Da im Falle von Penalties Suchergebnisse häufig aus den Top 30 Suchergebnissen verschwinden wäre die Vermutung, dass n = 30 ist.
Laut Googles Aussagen zu E-A-T handelt es sich nicht um einen einzelnen Wert, sondern mehrere Signale. Also muss es auch mehrere dieser Schwellenwerte je E-A-T-Signal geben.
Diese Schwellenwerte können je nach Thema und Keyword unterschiedlich hoch sein. z.B. bei typischen YMYL-Themen wie Finanzen, Shopping oder Medizin sind sie höher als bei Entertainment-Themen.
“We have very high Page Quality rating standards for YMYL pages low-quality YMYL pages could potentially negatively impact users’ happiness, health, or financial stability…. Important: For YMYL pages and other pages that require a high level of user trust, an unsatisfying amount of any of the following is a reason to give a page a Low quality rating: customer service information, contact information, or information about who is responsible for the website., Quelle: Google Search Quality Evaluator Guidelines”
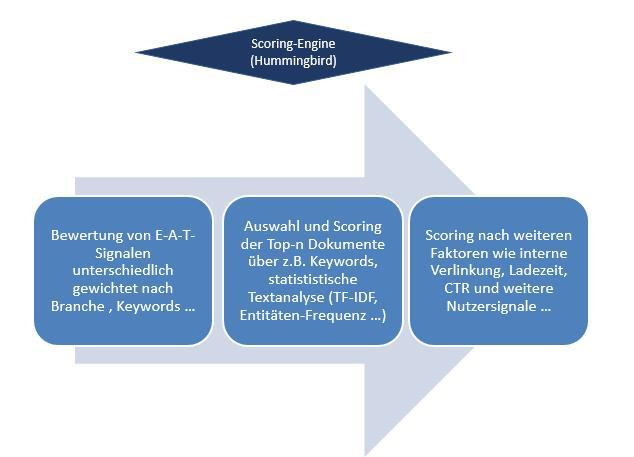
E-A-T als Gatekeeper, © Olaf Kopp
Diese Gatekeeper-Funktion könnte soweit gehen, dass bei nicht erreichen der Schwellenwerte Inhalte gar nicht erst in den Index gelangen oder zumindest nicht angezeigt werden wie Meldungen aus Februar 2020 mutmaßen lassen. Siehe dazu hier, hier, hier und hier.
E-A-T-Bewertung für Dokumente, Autoren und Publisher
Laut den Google Quality Rater Guidelines gibt es E-A-T Bewertungs-Kriterien für den Inhalt selbst als auch für die publizierende Website bzw. den Publisher und den Autor. Das entspricht auch den bereits erwähnten Aussagen seitens Google.
In den Quality Rater Guidelines werden folgende wichtige Kriterien zur Bewertung einer Website genannt:
- The Purpose of the Page
- Expertise, Authoritativeness, Trustworthiness: This is an important quality characteristic. Use your researchon the additional factors below to inform your rating.
- Main Content Quality and Amount: The rating should be based on the landing page of the task URL.
- Website Information/information about who is responsible for the MC: Find information about the website aswell as the creator of the MC.
- Website Reputation/reputation about who is responsible for the MC: Links to help with reputation researchwill be provided.
Nachfolgend trage ich Informationen aus unterschiedlichen Google-Quellen zu möglichen E-A-T-Signalen zusammen. Dabei unterscheide ich zwischen Signale, die im Zusammenhang mit dem Inhalt selbst stehen und Signale dir für die Bewertung des Publishers bzw. der Domain des Publishers und den Autors herangezogen werden können.
Signale für die E-A-T-Bewertung eines Inhalts
Wie bereits erwähnt ist es wichtig zu verstehen, dass E-A-T ein Konzept für eine Qualitätsbewertung und nicht für die Bewertung der Relevanz eines Dokuments bezogen auf einen Suchterm ist. Das bedeutet, dass für die Bewertung allgemeingültige Signale herangezogen werden müssen, die unabhängig von der Bedeutung des Suchterms angewandt werden können.
Die Signale die auf Dokumenten- oder Inhalts-Ebene für die E-A-T-Bewertung wichtig sein können beziehen sich auf dem Main Content (MC), den Supplementary Content (Neben-Content) und den Informationen zum Autor des Inhalts.
- Gut sichtbare Prüfer- und Autoren-Infos: Google empfiehlt die Informationen zum Urheber des Inhalts transparent anzugeben. Hier geht es um Transparenz. Das alleine reicht nach meiner Meinung aber nicht aus für eine gute Bewertung. Kann Google die (Entitäten-) Relevanz des Autors oder Prüfers bezogen auf das Thema des Dokuments nicht anhand weiterer Online-Quellen verifizieren reicht die alleinige Information für eine gute Bewertung nicht aus. Nur das Platzieren einer Autorenbox wird nicht zu besseren Rankings führen.
- Ein ausreichender an hochqualitativen Inhalten im Main Content: Hiermit ist nicht die reine Länge des Contents gemeint, sondern der erkennbare Aufwand, Expertise und Talent, was der Urheber in den Inhalt investiert hat. In den Google Quality Rater Guidelines schreibt Google folgendes:
“The quality of the MC is one of the most important criteria in Page Quality rating, and informs the EAT of the page. For all types of webpages, creating high quality MC takes a significant amount of at least one of the following: time, effort, expertise, and talent/skill. For news articles and information pages, high quality MC must be factually accurate for the topic and must be supported by expert consensus where such consensus exists…… Important: An unsatisfying amount of MC is a sufficient reason to give a page a Low quality rating.”
- Nicht nützlicher Neben-Content: Nicht nützlicher Neben-Content kann z.B. sein missverständliche Seitentitel, zu viele oder Anzeigen oder versteckte Anzeigen.
„Distracting/Disruptive/Misleading Titles, Ads, and Supplementary Content Some Low quality pages have adequate MC present, but it is difficult to use the MC due to disruptive, highly distracting, or misleading Ads/SC. Misleading titles can result in a very poor user experience when users click a link only to find that the page does not match their expectations. The Low rating should be used for disruptive or highly distracting Ads and SC. Quelle: Quality Rater Guidelines”
Pages that disguise Ads as MC. Actual MC may be minimal or created to encourage users to click on the Ads. For example, fake search pages (example) that have a list of links that look like a page of search results. If you click on a few of the links, you will see that the page is just a collection of Ads disguised as search engine results. A “search box” is present, but submitting a new query just gives you a different page of Ads disguised as search results.
Pages that disguise Ads as website navigation links. For example, fake directory pages (example) that look Copyright 2017 38 like a personally curated set of helpful links, possibly with unique descriptions. In reality, the links are Ads or links to other similar pages on the site. Sometimes the descriptions of the links are unrelated to the page.
Pages where the MC is not usable or visible. For example, a page that has such a large amount of Ads at the top of the page (before the MC), so that most users will not see the MC, or a page where the MC is invisible text.
- Zu viele Keywords im Main Content: Die Nutzung zu vieler Keyword-Wiederholungen im Main Content ist nicht im Sinne des Nutzers und führt zu einer schlechten Bewertung.
“Keyword Stuffed” Main Content Pages may be created to lure search engines and users by repeating keywords over and over again, sometimes in unnatural and unhelpful ways. Such pages are created using words likely to be contained in queries issued by users. Keyword stuffing can range from mildly annoying to users, to complete gibberish. Pages created with the intent of luring search engines and users, rather than providing meaningful MC to help users, should be rated Lowest.”
- Automatisch generierter Main Content: Automatisch generierter Main Content führt zu einer schlechten Bewertung.
„Automatically Generated Main Content Entire websites may be created by designing a basic template from which hundreds or thousands of pages are created, sometimes using content from freely available sources (such as an RSS feed or API). These pages are created with no or very little time, effort, or expertise, and also have no editing or manual curation. Pages and websites made up of autogenerated content with no editing or manual curation, and no original content or value added for users, should be rated Lowest.“
- Kopierter Main Content: Kopierter Main Content führt zu einer schlechten Bewertung.
“Important: The Lowest rating is appropriate if all or almost all of the MC on the page is copied with little or no time, effort, expertise, manual curation, or added value for users. Such pages should be rated Lowest, even if the page assigns credit for the content to another source.”
- Zu wenig Content above the fold: Auch die Menge des Contents, der sofort ohne zu scrollen above the fold sichtbar ist kann eine Rolle bei der Bewertung spielen. Zu viel nicht nutzerorientierter Content above the fold lässt auf einen Zweck schließen, der dem Publisher dient aber nicht dem Nutzer.
This algorithmic change does not affect sites who place ads above-the-fold to a normal degree, but affects sites that go much further to load the top of the page with ads to an excessive degree or that make it hard to find the actual original content on the page. This new algorithmic improvement tends to impact sites where there is only a small amount of visible content above-the-fold or relevant content is persistently pushed down by large blocks of ads.
If you believe that your website has been affected by the page layout algorithm change, consider how your web pages use the area above-the-fold and whether the content on the page is obscured or otherwise hard for users to discern quickly. You can use our Browser Size tool, among many others, to see how your website would look under different screen resolutions. Google
- Page Rank / Links: Der PageRank und damit Links ist das einzige bisher bestätigte Signal im Kontext E-A-T. So lässt sich in dem Whitepaper „How Google fights Disinformation“ folgendes nachlesen.
“Google’s algorithms identify signals about pages that correlate with trustworthiness and authoritativeness. The best known of these signals is PageRank, which uses links on the web to understand authoritativeness.”
Inwiefern neben dem PageRank auch weitere linkbezogene Signale wie Anzahl der Backlinks, Traffic über den Link … hier mit reinfallen ist Spekulation. Der PageRank selbst hat sowohl einen Dokumenten-Bezug und durch die Vererbungs-Theorie einen Einfluss auf Teile der Website oder auf die komplette Domain. Domains, die häufig durch autoritäre Quellen in Form von Verlinkungen referenziert werden profitieren von der Nähe zu diesen. Ein ehemaliger Search Engineer von Google namens Jonathan Tang hatte 2016 erklärt, dass Google das Konzept des klassischen PageRanks schon länger nicht mehr nutzt und durch einen neuen Algorithmus ersetzt hat.
„They replaced it in 2006 with an algorithm that gives approximately-similar results but is significantly faster to compute. The replacement algorithm is the number that’s been reported in the toolbar, and what Google claims as PageRank (it even has a similar name, and so Google’s claim isn’t technically incorrect). Both algorithms are O(N log N) but the replacement has a much smaller constant on the log N factor, because it does away with the need to iterate until the algorithm converges. That’s fairly important as the web grew from ~1-10M pages to 150B+. „
Die weiterentwickelte Form des PageRank-Konzepts basiert weniger auf der Anzahl der eingehenden Links, sondern viel mehr auf der Nähe der angelinkten Dokumente zu Autoritäts- bzw. Seed-Websites.
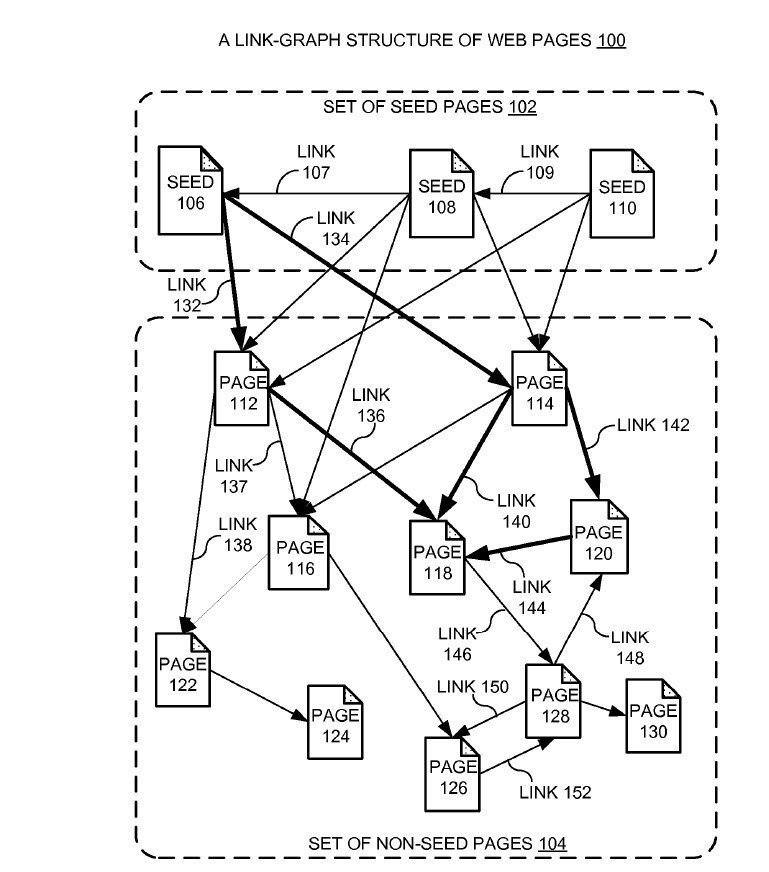
Quelle: Google Patent „Producing a ranking for pages using distances in a web-link graph“
Dieses Konzept kann man sowohl auf das zu rankende Dokument selbst, aber auch auf den Publisher bzw. Domain oder Autor im Allgemeinen beziehen. Ein Publisher oder Autor, der häufig direkt von Seed-Websites referenziert wird bekommt eine höhere Autorität für den Themenbereich und semantische verwandten Keywords aus dem dieser verlinkt wird.
Ein weiteres Link-basiertes Signal kann eine Art Trust-Rank sein, wie dem Dokument Combating Web Spam with TrustRank von Yahoo erläutert.
We first select a small set of seed pages to be evaluated by an expert. Once we manually identify the reputable seed pages, we use the link structure of the web to discover other pages that are likely to be good. In this paper we discuss possible ways to implement the seed selection and the discovery of good pages.
Signale für eine E-A-T-Bewertung von Autoren und Publishern bzw. Websites
Laut den Angaben zu E-A-T in den Quality-Rater-Guidelines findet ein nicht unwesentlicher Teil der Bewertung in Bezug auf die den Urheber, also Autoren und Publisher bzw. die Website im Allgemeinen statt. Folgende Signale können hier eine Rolle spielen.
- Spam-Aktivitäten des Publishers: Fällt eine Website/Publisher häufiger durch Spam-Aktivitäten wie Linkkauf, Cloaking, Doorway-Pages … auf könnte sich das negativ auf die Reputaion bzw. den Trust der Website auswirken. Google schreibt in den Quality Rater Guidelines:
- Viele Fehlermeldungen oder keinen bzw. wenig Main Content: Eine offensichtliche ungepflegte Website mit anteilig vielen 404-Fehlern oder viel Thin Content könnte ein Negativ-Signal sein.
“Some pages are temporarily broken pages on otherwise functioning websites, while some pages have an explicit error (or custom 404) message. In some cases, pages are missing MC as well. Please think about whether the page offers help for users—did the webmaster spend time, effort, and care on the page?”
- Transparenz in Bezug auf die Autoren, Publisher bzw. Website-Betreiber: Eine fehlende Transparenz über Autoren und Website-Betreiber könnte ein Negativ-Signal sein. Wer betreibt die Website? wer sind die Autoren? In den Quality Rater Guidelines findet man dazu folgenden Absatz:
„Important: For YMYL pages and other pages that require a high level of user trust, an unsatisfying amount of any of the following is a reason to give a page a Low quality rating: customer service information, contact information, or information about who is responsible for the website. „
- Zweck der Website und der Inhalte sollte Nutzer-Fokus haben: Wie bereits weist Google die Such-Evaluatoren darauf hin, dass der Purpose also Zweck der Website klar sein muss und hierbei der Nutzen für den Konsumenten im Vordergrund stehen sollte.
- Meinungen und Stimmen zum Publisher /zur Website: In den Quality Rater Guidelines werden die Such-Evaluatoren dazu motiviert offpage nach Nutzer- und Experten-Meinungen zu suchen, die einen Aufschluss über die Reputation geben.
Use reputation research to find out what real users, as well as experts, think about a website. Look for reviews, references, recommendations by experts, news articles, and other credible information created/written by individuals about the website…. When interpreting customer reviews, try to find as many as possible. Any store or website can get a few negative reviews. This is completely normal and expected. Large stores and companies have thousands of reviews and most receive some negative ones.
Fehlen solche Informationen sollte dies als neutral bewertet werden bzw. nicht negativ ausgelegt werden.
Note that different locales may have their own specific standards and requirements for what information should be available on the website. You should expect to find reputation information for large businesses and websites of large organizations. Frequently, you will find little or no information about the reputation of a website for a small organization. This is not indicative of positive or negative reputation. Many small, local businesses or community organizations have a small “web presence” and rely on word of mouth, not online reviews. For these smaller businesses and organizations, lack of reputation should not be considered an indication of low page quality.
Sind solche externen Informationen vorhanden und unterscheiden sie sich von den Angaben auf der Website sind diese Offpage-Informationen mehr Vertrauen entgegenzubringen.
“For Page Quality rating, you must also look for outside, independent reputation information about the website. When the website says one thing about itself, but reputable external sources disagree with what the website says, trust the external sources.”
Für solche Analysen kann Google auch Sentiment-Analysen im Rahmen von Natural Language Processing nutzen.
„Bei der Sentimentanalyse pro Entität wird die Entitätsanalyse mit der Sentimentanalyse kombiniert und es wird versucht, die (positive oder negative) Einstellung zu erkennen, die in den Entitäten des Texts zum Ausdruck kommt. Jede Entitätsstimmung wird durch numerische Score- und Magnitude-Werte dargestellt und für jede Erwähnung einer Entität bestimmt. Diese Punktzahlen werden dann in eine allgemeine Sentimentpunktzahl (Score und Magnitude) für eine Entität zusammengefasst…“ Quelle: Dokumentation Google NLP-API
Mehr dazu im Beitrag Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
Weitere Hinweise zu möglichen E-A-T-Bewertungskriterien und -Signalen für Publisher und Autoren findet man in der Google-Dokumentation, den Hilfe-Seiten, diversen Google-Patenten und Google-Stimmen:
- Bekanntheit / Bedeutung: Google hat in seiner Anleitung zu lokalen Rankingfaktoren erwähnt, dass der Bekanntheitsgrad eines Unternehmens direkter Rankingfaktor ist. Dies gilt meiner Meinung nach nicht nur für lokale Rankings.
„Bekanntheit/Bedeutung: Damit ist der Bekanntheitsgrad eines Unternehmens gemeint. Manche Orte oder Dinge sind bekannter als andere. Dies wird im Ranking der lokalen Suchergebnisse berücksichtigt. So erscheinen beispielsweise berühmte Museen, Hotels oder Handelsmarken, die vielen Nutzern ein Begriff sind, auch in den lokalen Suchergebnissen sehr wahrscheinlich an herausragender Stelle. Die Bekanntheit bzw. Bedeutung ergibt sich darüber hinaus aus Informationen, die wir aus dem Web – beispielsweise über Links, aus Artikeln oder aus Verzeichnissen – über ein Unternehmen beziehen.“
- Brand-Mentions: Gary Illyes von Google betonte den möglichen Effekt von Brand Mentions und anderen Erwähnungen auf Rankings bei seiner Keynote auf der Brighton SEO 2017.
“If you publish high-quality content that is highly cited on the internet — and I’m not talking about just links, but also mentions on social networks and people talking about your branding, crap like that. Then you are doing great.”
- Zugehörigkeit zu einer Branche oder Business-Kategorie: Über die Google NLP-API lassen sich Texte einer Business-Kategorie zuordnen (siehe dazu hier). Werden auf einer Website häufig Texte/Inhalte zu einer bestimmten Kategorie veröffentlichen. Die Intensität und Häufigkeit der Publikation zu bestimmten Branchen- und Themen-Kategorien lässt einen Rückschluss für die Zugehörigkeit zu Branchen und Expertise des Publishers in den jeweligen Themen zu.
Im Google Patent Business Category Classification aus dem Jahr 2015 wird beschrieben wie Dokumente und Entitäten einer Branche bzw. Geschäftskategorie zugeordnet werden können. Im ersten Schritt werden Dokumente einer Entität zugeordnet. Über die Nennungen möglicher Geschäftsfelder bzw. -kategorien kann die Entität dieser bzw. diesen zugeordnet werden. Desweiteren kann für eine Entität eine Relevanz-Bewertung in Bezug auf eine Branche durchgeführt. Diese kann aufgrund
-
- der Häufigkeit den Entitäten-Nennungen in Verbindung mit der Kategorie je Dokument
- die Menge an Dokumenten, die diese Kookkurrenzen beinhalten
- im Verhältnis zu der allgemeinen Nennungen der Kategorie
erstellt werden. Erreicht dieser Bewertung einen Schwellenwert wird die Entität einer Kategorie zugeordnet. Die Relevanzbewertungen werden für eine oder mehrere Geschäftskategorien in Bezug auf eine Entität berechnet und liefern ein Maß für die Relevanz zwischen einer bestimmten Geschäftsklassifizierung und der Geschäftseinheit.
In some aspects, the method further comprises steps for calculating a relevance score for each of the plurality of business categories, wherein the relevance score for each business category is based on the term frequency, the document frequency and the global frequency for each of the category phrases associated with that business category and associating one or more of the plurality of business categories with the business entity based on the relevance score calculated for each of the one or more of the plurality of business categories.
Zu den der Entität zugeordneten Dokumenten gehören beispielsweise Webseiten, auf denen eine oder mehrere Geschäftseinheiten erwähnt werden, Ankertexte von Hyperlinks zu einer oder mehreren Unternehmenswebsites, Webdokumente, Anzeigen und / oder Feeds mit Geschäftsberichten usw.
Im Beitrag Entitäten & E-A-T: Die Rolle von Entitäten bei Autorität und Trust bin ich auf weitere Signale eingegangen, die man diversen Google-Patenten entnehmen kann. Deswegen fasse ich sie nachfolgend nur kurz zusammen:
- Backlinks mit semantisch passenden Ankertexten bzw. im semantisch passenden Umfeld
- Linkbasierte Nähe zu autoritären Seed-Sites
- Vererbung eines Trust-Ranks über Links
- Aufbauen einer Bekanntheit (Suchvolumen, Links, Anzahl der Nennungen in Fremdmedien, sozialen Netzwerken …)
- Generelle Nutzer-Signale wie CTR bei Dokumenten des Publishers / Autors
- Nennungen des Autors / Publishers in Best-Of-Listen
- Preise und Awards, die der Autor / Publisher gewonnen hat
- Kookkurrenzen des Autors / Publishers in Zusammenhang mit Begriffen aus dem Themen-Umfeld
- Nähe zu anderen Autoritäts-Dokumenten auf Basis von Text, Bildern, Bestandteile des Contents wie z.B. Links und eine Kombination aus diesen
- Richtigkeit der veröffentlichten Informationen im Abgleich mit der „gängigen Meinung“ bzw. wissenschaftlichen Erkenntnissen (KBT)
- Anzahl der Verweise auf die Inhaltes eines Autors insgesamt
- Anteil der Dokumente, die ein Autor zu einem thematischen Korpus beigesteuert hat.
- wie lange der Autor bereits nachweislich Content in einem Themenbereich produziert
- Bekanntheitsgrad des Autors
- Bewertungen der veröffentlichten Inhalte durch Nutzer
- Wenn Inhalte des Autors von einem anderen Publisher mit überdurchschnittlichen Bewertungen veröffentlicht werden
- Die Anzahl der durch den Autor veröffentlichten Inhalte
- Wie lange die letzte Veröffentlichung des Autors her ist
- Die Bewertungen bisheriger Veröffentlichungen ähnlichen Themen des Autors
- Anzahl der Verweise auf die Inhaltes eines Autors insgesamt
- Anteil der Dokumente, die ein Autor zu einem thematischen Korpus beigesteuert hat.
- Entitäten Frequenz statt Termfrequenz in Dokumenten (EF-IDF)
- Nähe des Dokumenten-Graph zum Knowledge-Graph/Knowledge Vault. Je näher sich die Graphen sind desto höher ein Confidence Score. Dieser Confidence Score kann auch als Messung der Glaubwürdigkeit genutzt werden.
Wie kannst Du die thematische Autorität einer Website feststellen?
Wenn ich von einer thematischen Autorität spreche meine ich ein Quelle, die Google in den Top n-Dokumenten aus einem thematischen Korpus für das Scoring heranziehen muss, da sie zu einer Art Relevant-Set gehört, die Nutzer bei einer Suchanfrage erwarten.
Über häufige Kookkurrenzen aus Entitäten bzw. Autoren oder Publishern / Marken und thematischen Begriffen kann Google feststellen mit welchen Themen diese im thematischen Kontext stehen. Je häufiger dieser Kookkurrenzen vorkommen, desto größer ist die Wahrscheinlichkeit, dass ein semantischer Zusammenhang besteht. Diese Kookkurrenzen können über strukturierte und unstrukturierte Informationen aus Website-Inhalten, als auch über vorkommende Suchterme ermittelt werden. (Mehr dazu auch in den Beiträgen Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph ?, Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ? und Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen. )
Wird die Entität „Zalando“ häufig zusammen mit dem Entitätstyp „Shop“ oder „Schuhe“ genannt liegt eine Verwandschaft bzw. Beziehung vor. So kann Google bereits beim Indexieren von Inhalten oder der Verarbeitung einer Suchanfrage die Beziehung zwischen Entitäten untereinander und Entitätstypen, Themen, Keywords … feststellen. Den Grad der Verwandschaft kann Google über die durchschnittliche Nähe in den Texten und/oder die Häufigkeit der vorkommenden Kookkurrenzen in Texten und Suchanfragen ermitteln.
So kann Google eine thematische Autorität je Themen-Gebiet ermitteln.
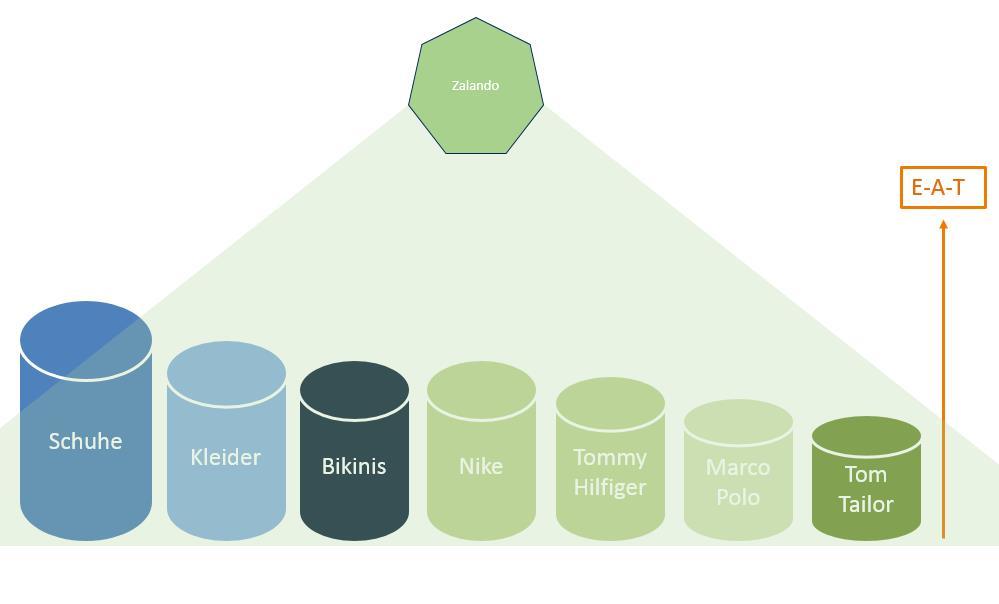
Thematische Autorität am Beispiel der Entität Zalando
Wenn man im Keyword-Planer über die Funktion „mit einer Website beginnen“ Keyword-Vorschläge abruft ergibt sich am Beispiel von zalando.de folgendes Bild:
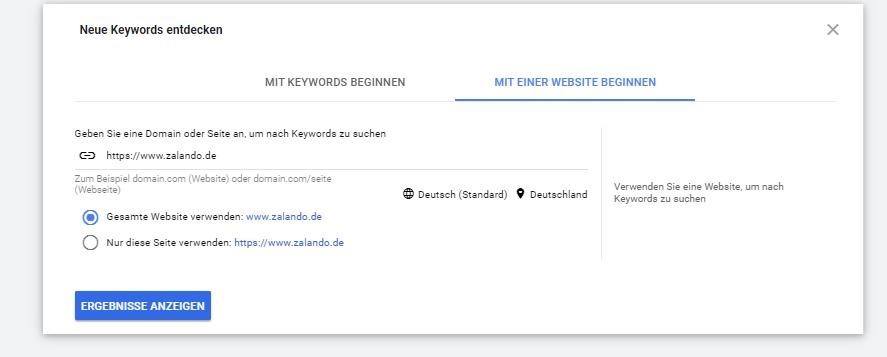
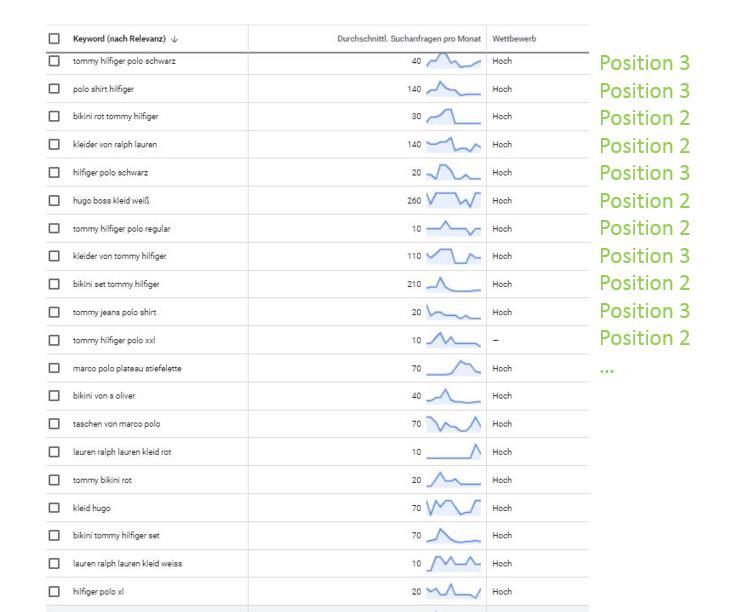
Die Keyword sind nach einer durch Google undefinierten Relevanz sortiert. Überprüft man die ausgegebenen Keywords hinsichtlich dem Ranking wird klar, dass nahezu für alle dieser Keywords Zalando auf Top-Positionen rankt. Hier scheint eine thematische Autorität bzw. große Nähe zu bestimmten Themen und anderen Entitäten vorzuliegen.
Wie kannst Du für E-A-T optimieren?
Zum Schluss bleibt die für SEOs und Marketer spannendste Frage zu beantworten. Wie kann man hinsichtlich E-A-T optimieren? Die Antwort kann man auf zwei Ebenen geben. Ich beginne mit der etwas unkonkreteren allgemeinen Aussage. Viele der oben genannten Signale haben etwas gemeinsam. Es geht um Kookkurrenzen.
Kookkurrenz bezeichnet in der Allgemeinen Linguistik das gemeinsame Auftreten zweier lexikalischer Einheiten (z. B. Wörter) in einer übergeordneten Einheit, wie in einem Satz oder einem Dokument. Quelle: Wikipedia
Insbesondere geht es um Kookkurrenzen des Namens des Unternehmens, des Publishers, des Autors und der Domain in Verbindung mit thematisch relevanten Begriffen. Je häufiger diese Kookkurrenzen auftauchen desto wahrscheinlicher haben die Haupt-Entitäten etwas mit dem Thema und dem zugehörigen Keyword-Cluster zu tun. Diese Kookkurrenzen müssen durch Google identifizierbar bzw. crawlbar sein. Nur dann können Sie von Google erkannt und in das Konzept E-A-T einfließen lassen. Neben den Kookkurrenzen in Online-Texten sind auch Kookkurrenzen in Suchanfragen eine Quelle für Google.
Im Endeffekt versucht Google damit nur die Methodik von „thematischer Marken-Positionierung“ zu adaptieren, die Marketer schon seit Jahrhunderten nutzen um Marken in Kombination mit Botschaften in Köpfen von Menschen zu etablieren. Je häufiger ein Mensch eine Person und/oder einen Anbieter in einem bestimmten thematischen Kontext wahrnimmt, desto mehr Vertrauen wird er dem Produkt, dem Dienstleister, dem Medium … zusprechen. Wenn zudem diese Entität häufiger in den thematischen Kontexten genannt wird als andere Marktbegleiter und zudem von anderen glaubwürdigen und autoritären Quellen positiv referenziert wird steigt die Autorität. Durch diese Wiederholungen wird ein neuronales Netz im Hirn neu angelernt und wir werden als Marke wahrgenommen, die eine thematische Autorität und Vertrauenswürdigkeit besitzt.
Für die E-A-T-Optimierung ist es daher wichtig durch Google erfassbare Kookkurrenzen entlang der Customer-Journey zu erzeugen. Dadurch lernt auch Googles neuronales Netz wer eine Autorität und damit vertrauenswürdig für ein oder mehrere Themen ist. Das gilt insbesondere für Kookkurrenzen in Awareness-, Consideration- und Preference-Phase
Je weiter man sich für Themen weiter vorne in der Customer-Journey positioniert, desto breiter wird auch das Keyword-Cluster mit dem mich Google in Verbindung bringt. Ist diese Verknüpfung gezogen gehört man mit den eigenen Inhalten zum Relevant-Set.
Diese Kookkurrenzen können z.B. über
- passenden Onpage-Content
- passende Interne Verlinkung
- passender Offpage-Content
- externe eingehende Verlinkungen, Ankertexte und Umfeld des Links
- Beeinflussung von Suchmustern
erzeugt werden.
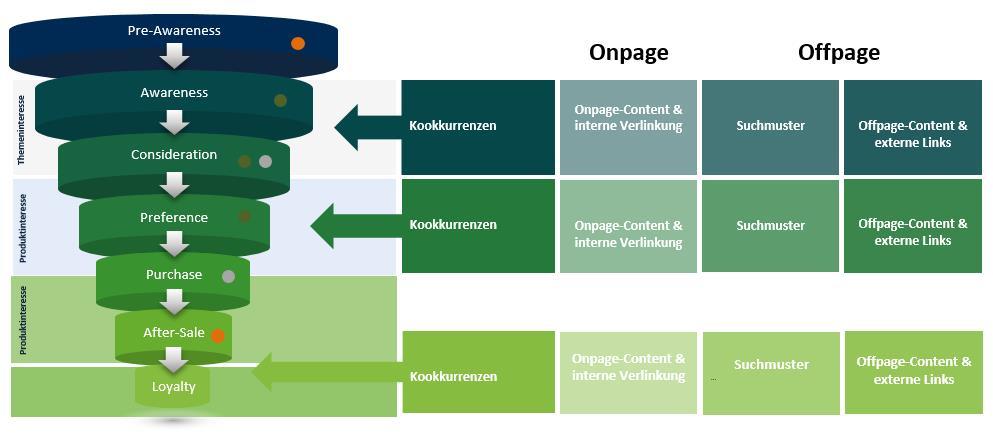
Kookkurrenzen entlang der Customer Journey
Gerade bei den Offpage-Signalen hat man einen großen kreativen Spielraum. Aber es sind auch keine typischen SEO-Maßnahmen, die hier für Kookkurrenzen sorgen. Mal vom klassischen Linkaufbau abgesehen. SEO-Verantwortliche werden dadurch immer mehr zur Schnittstellen-Position zwischen Technik, Redaktion, Marketing und PR.
Beispiele für gelungene E-A-T-Optimierung
Unternehmen wie z.B. Footlocker oder home2go zeigen wie es geht:
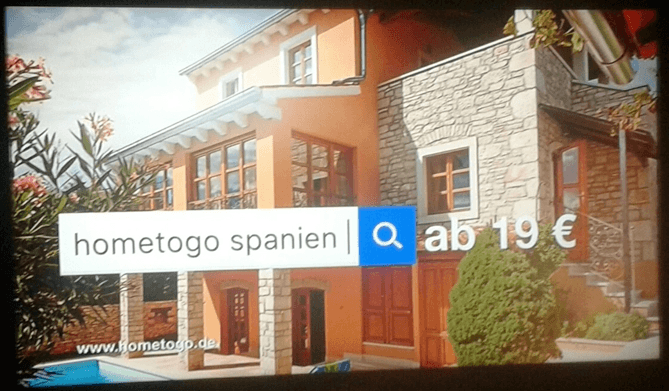
So schaltet Home2go Fernsehwerbung um Suchmuster zu beeinflussen, indem sie indirekt vorgeben nach welchen Brand + Themen -Suchtermen der Nutzer googlen soll.
Footlocker kreiert selbst und lässt viel Content durch Nutzer kreieren, um die Marke immer wieder in Kontext mit bestimmten Produkt-Keywords zu positionieren. Zudem macht Footlocker häufig exklusive Produkt-Kooperationen z.B. mit adidas für eine Jacke. Menschen suchen dann z.B. nach „adidas jacke footlocker“ oder andere Medien berichten über diese exklusiven Produkte, was alles zusammen wieder Signalel an Google sendet.
Videos im Footlocker-Youtube-Kanal
Unboxing Videos von Foolocker-Kunden und Partnern
Youtube-Video im Kanal des Lifestyle-Magazins Complex zu einer exklusiven Produktvariante eine Sneakers
Beide Unternehmen gehören zu den Sichtbarkeits-Gewinnern der letzten zwei Jahre.

Sichtbarkeits-Entwicklung footlocker.de
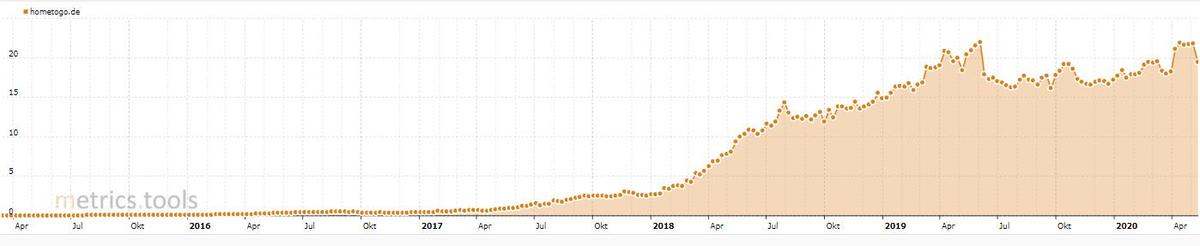
Sichtbarkeits-Entwicklung home2go.de
Konkrete Handlungsempfehlungen für die E-A-T-Optimierung (Checkliste)
Zum Abschluss möchte ich noch konkrete Handlungsempfehlungen ableiten, die es auch als Checkliste zum Download oder an die Wand hängen gibt.
- Ausreichende Menge an themenrelevanten Content auf der eigenen Website: Sorge für Expertise, indem Du regelmäßig hochwertige Inhalte zu den Themen, für die du gefunden werden willst. Damit zeigst Du Google, dass Du eine gewisse Expertise als Publisher hast. Achte dabei, aber auch auf Keyword-Kannibalisierung.
- Mach es Google einfach Deinen Onpage-Content richtig einzuordnen.
- Schreib in einfachen Satzkonstrukten und nicht in Schachtelsätzen.
- Versuch auf Personalpronomen in Sätzen zu verzichten.
- Nutze Adjektive und Adverbien nur wenn unbedingt notwendig für das Verständnis des Satzes.
- Verzichte auf Geschwafel und bla, bla, bla … Reduziere Dich beim Schreiben auf das Wesentliche.
- Strukturiere Inhalte mit logischen Absätzen und Zwischenüberschriften. Diese sollten auch ohne den Kontext des Umfelds einen klaren Themen-Bezug haben. Also nicht nur „Quellen“ sondern „Quellen zum Thema x“.
- Nutze TF-IDF-Analysen und integriere die relevanten Begriffe im Text, um den semantischen Kontext des Inhalts zu verbessern.
- Nutze verständliche Formulierung und zur Suchanfrage passende Medienformate und Anwendungen: Beschäftige Dich mit der Zielgruppe des Contents. Finde heraus, wie der Wissensstand einer Person, für die der Content bestimmt ist und formuliere entsprechend. Finde heraus welche Medienformate und Anwendungen gewünscht sind und antizipiere welche Medienformate so z.B. Übersichtsgrafiken, Infografiken, Anleitungen in visueller Form oder audiovisueller Form … oder interaktive Anwendungen wie z.B. Konfiguratoren einen Mehwert bezogen auf die Suchanfrage bieten.
- Verlinke die Inhalte semantisch passend miteinander, aus dem Main Content (MC) heraus. Dabei kannst Du auch eine mögliche Users-Journey berücksichtigen. Was interessiert den Konsument als nächstes oder zusätzlich?
- Sorg für Transparenz was Autoren, Website-Betreiber und Zweck der Website angeht
- Impressum ist auch schon aus rechtlicher Sicht Pflicht.
- Eine aussagekräftige „Über uns-Seite“.
- Autoren-Profile bzw. Informationen zu den Autoren
- Arbeite mit anerkannten Experten als Autoren, Prüfer, Ko-Autoren, Mitwirkende und Influencer zusammen. Anerkannt bedeutet, dass diese bereits online als Experten durch Google erkennbar sind z.B. durch Online-Publikationen, Amazon-Autoren-Profile, eigene Blogs und Websites, Social-Media-Profile, Profile auf Universitätsseiten … Wichtig hierbei ist, dass die Autoren bereits durch Google crawlbare Referenzen im jeweiligen thematischen Kontext vorweisen.
- Verweise (Verlinke) auf andere autoritäre Quellen. Dadurch bringst Du Dich in Beziehung zu einem autoritären Umfeld.
- Mach es Google einfach Deine Entität und die digitalen Abbilder und Profile zu erkennen.
- Verknüpfe/Verlinke die Repräsentanzen Deiner Entität wie z.B. Domains, Apps, Youtube-Kanäle, Wikipedia-Einträge, Wikidata-Einträge, Social Media Profile … miteinander.
- Sorge für konsistente Informationen über Deine Person bzw. Dein Unternehmen in Profilen im Netz.
- Verlinke Deine Repräsentanzen mit Autoren-Profilen auf z.B. Amazon und zurück (wenn vorhanden)
- Nutze Linktexte mit Deinem Entitätsnamen, um auf Deine Repräsentanzen zu verlinken
- Ggf. Nutzung von sameAs schema.org-Auszeichnung
- Verzichte auf zu viel Werbe-Banner und Recommendation Ads (Outbrain, Taboola …)
- Google wertet Seiten mit zu viel nicht nutzerorientierten Supplementary-Content wie z.B. Werbung, Affliate-Links … ab.
- Schaffe regelmäßig Kookurrenzen ausserhalb der eigenen Website durch Marketing und Kommunikation und positioniere Dich Dadurch als Marke erkennbar für Google.
-
- Verlinke Deine themenrelevanten Fachpublikationen von der eigenen Website, damit Google diese schneller Euch zuordnen kann.
- Teile den Content über die eigenen Social Media Profile, damit Google diese schneller Euch zuordnen kann.
- Baut Links aus semantisch passenden Umfeldern auf.
- Mach Offline-Werbung, die Suchmuster bei Google beeinflusst bzw. passenden Kookkurrenzen in Suchanfragen erzeugt (TV-Werbung, Flyer, Anzeigen …). Keine reine Image-Werbung, sondern Werbung, die zur Positionierung in einem Themenbereich beiträgt.
- Schreib thematische passende Gastbeiträge und Verlinke diese Inhalte mit der eigenen Website und den eigenen Social-Media-Profilen.
- Geb Interviews
- Halte Vorträge auf Fach-Events
- Gib Webinare
- Organisiere Kooperationen (z.B. mit Lieferanten, Partnern … ), die für passende Kookkurrenzen sorgen
- Mach PR, die passende Kookkurrenzen erzeugt. Keine reine Image-PR.
- Sorg für Buzz in sozialen Netzwerken rund um Deine Entität.
-
- Verbessere die Nutzersignale auf den eigenen Publikationen auf der eigenen Website und darüber hinaus
- Snippet-Optimierung
- Suchintentions-Analysen je Hauptkeyword. Der Zweck des Inhalts sollte immer der Suchintention entsprechen.
Quellen:
Die Erkenntnisse zu diesem Beitrag habe ich aus folgenden Quellen abgeleitet:

- Google Quality Rater Guidelines
- Whitepaper „How Google fights Disinformation“
- Google Patente aus dem Beitrag Entitäten & E-A-T: Die Rolle von Entitäten bei Autorität und Trust
- Vortrag How Google works von Paul Haahr bei Youtube
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.