
In modernen Suchmaschinen sind Keywords nicht mehr nur ein Mittel zum Zweck um einen Dokumenten-Suchanfragen-Abgleich durchzuführen. Keywords sind vor allem dazu da ein semantisches Verständnis sowohl des Suchterms als auch eines Dokuments/Inhalts zu entwickeln. Basierend auf einem Google-Patent möchte ich eine mögliche Anwendungsfälle beleuchten wie Keywords durch semantische Suchmaschinen wie Google genutzt werden können.
Inhaltsverzeichnis
- 1 Keywords im Kontext von Wissensdomänen
- 2 Häufig vorkommende Begriffe und Phrasen in relevanten Dokumenten (TF-IDF)
- 3 LSI Keywords & Keyword-Stuffing
- 4 Keywords als Entitäten
- 5 Kanonische Keywords erkennen
- 6 Was ist die semantische Relevanz von Keywords?
- 7 Semantische Beziehungsgraphen als Abbild semantischer Beziehungen zwischen Keywords und Entitäten
- 8 Google Patent zur semantischen Relevanz von Keywords
- 9 Zusammengefasst: Keywords als kleinstes Element von semantischen Suchmaschinen
Keywords im Kontext von Wissensdomänen
Wissensdomänen oder Ontologien bzw. Themenbereiche können durch Keyword-Cluster definiert werden, die in einer bestimmten semantischen Nähe zueinander stehen. Die Nähe der Keywords zueinander definieren, ob Keywords zu einer thematischen Ontologie gehören oder nicht. Diese Ontologien können auch durch Vektoren in einem Vektorraum dargestellt werden, wobei jeder Vektor für ein Keyword steht. Über Vektorraumanalysen können in den Vektorräumen Gruppen von Keywords in Beziehung bzw. Nähe zueinander gesetzt werden. Je näher zwei oder mehrere Keywords in einem Vektorraum zusammenliegen desto enger ist die die semantische Verwandschaft.
Im Falle von Kontextvektoren können beispielsweise Domänenbegriffe (wie in Wissensdomänen), die die Bedeutung hinter einem für eine Seite gewählte Schlüsselwortbegriff oder -satz erkennen lassen, der Suchmaschine helfen zu verstehen, welche Bedeutung ein Satz, Absatz oder der Content an sich hat. Diese Methode könnte auch beim Passage Ranking eine Rolle spielen.
Wird eine Seite beispielsweise für den Begriff „Pferd“ optimiert und werden der Seite Domänenbegriffe wie „Steigbügel“, „Sattel“ oder „Vollblut“ hinzugefügt, kann die Suchmaschine die richtige Bedeutung für dieses Text erkennen.
Häufig vorkommende Begriffe und Phrasen in relevanten Dokumenten (TF-IDF)
Bei der phrasenbasierten Indexierung kann ein Keywords und Phrasen berücksichtig werden, die häufig auf anderen Seiten vorkommen, die für dieselbe Phrase oder Keyword ein hohes Ranking in der Suchmaschine haben. Dieses Prinzip kennen wir von TF-IDF- bzw. WDF-*IDF-Analysen.
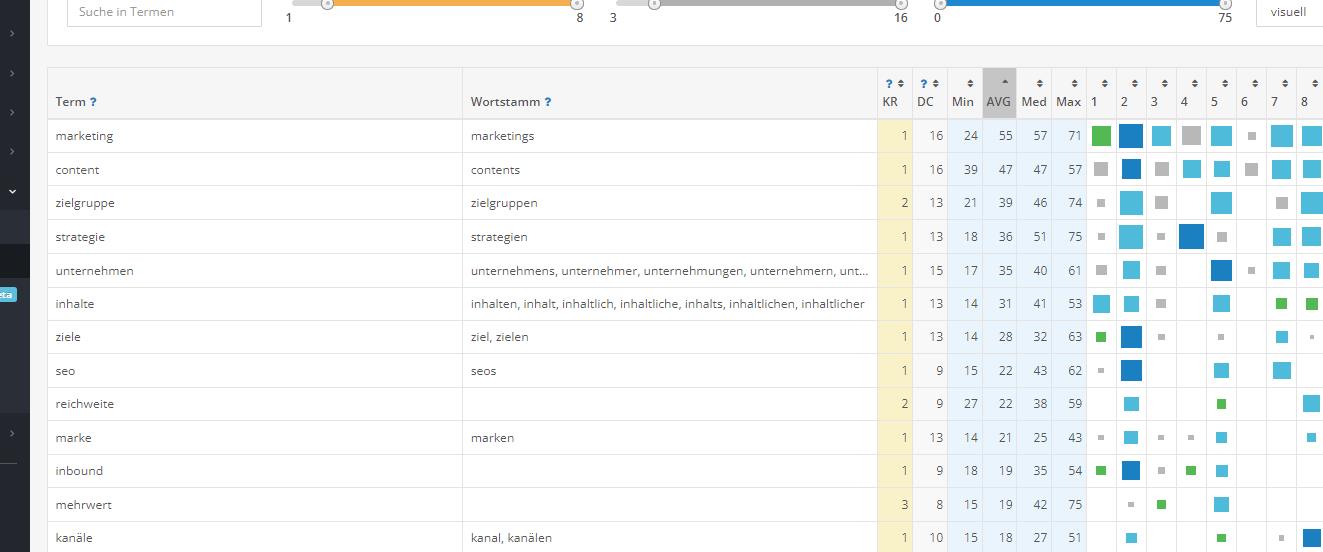
Beispiel TF-IDF-Analyse mit Termlabs.io
Eine Fokussierung auf die Begriffe, die in den Top-n rankenden Dokumenten benutzt werden ist eine gute Grundlage für die Erstellung eines Texts, aber reicht häufig alleine nicht aus, da man immer ein bisschen besser sein sollte, als das was schon an Inhalten da ist.
Google möchte in den Suchergebnissen eine gewisse Vielfältigkeit bzw. Diversität präsentieren. Deswegen macht es durchaus Sinn auch Begriffe zu nutzen, die nicht in diesen Dokumenten vorkommen, die dennoch semantischer Nachbarschaft zum Hauptbegriff liegen. Dafür kann man sich mit neuen Perspektiven beschäftigen, die man z.B. bei den Nutzern oder anderen Experten direkt erfragt. Dadurch erlangt der Inhalt eine Einzigartigkeit.
Google oder andere moderne Suchmaschinen können diese häufig vorkommenden vollständigen und aussagekräftigen Phrasen in einer Liste indexieren. Dazu auch mehr in dem Beitrag Are You Using Google Phrase-Based Indexing? vom geschätzten Kollegen Bill Slawski oder meinen Beiträgen Wie kann Google über Entitäten, NLP & Vektorraumanalysen relevante Dokumente identifizieren und ranken? und Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen.
LSI Keywords & Keyword-Stuffing
Es gibt einige SEOs, die über so genannte „LSI Keywords“ schreiben, ohne wirklich zu zeigen, was das in der Praxis bedeutet bzw. ob die Verwendung von LSI-Keywords wirklich für die Suchmaschinenoptimierung funktioniert. Oft wird dann im Kontext von LSI-Keywords auf den Google Keyword-Planner, hervorgehobene Wörter in Suchergebnissen und Google-Abfrageverfeinerungen verwiesen.
Google hat vor „Keyword-Stuffing“ gewarnt, d. h. davor, das gleiche Keyword immer wieder auf einer Seite zu wiederholen und die Seite mit diesem Keyword „vollzustopfen“. Die sogenannte Termfrequenz war in der SEO-Steinzeit ein probates Mittel um Rankings zu manipulieren hat heute aber keinen großen Einfluss mehr, sondern könnte sogar als Überoptimierung erkannt und abgewertet werden.
Keywords als Entitäten
Begriffe bzw. Keywords können über die grammatikalische Satzstruktur als Entitäten identifiziert werden. Substantive bzw. Subjekte und Objekte sind häufig Entitäten. So können semantische Suchmaschinen über sogenannte Triples aus Subjekt, Prädikat und Objekt Entitäten in Sätzen identifizieren und in Beziehung zueinander setzen. Darüber lassen sich in einem Graphen-Konstrukt wie z.B. dem Google Knowledge Graph Beziehungen zwischen Entitäten aus unstrukturierten Informationen wie Texten identifzieren. Moderne Suchmaschinen wie Google können dafür Methoden wie Natural Language Processing nutzen.
Mehr dazu auch in meiner Beitragsreihe Entitäten, NLP & Semantik bei Suchmaschinen
Kanonische Keywords erkennen
Unterschiedliche Keywords mit einer nahezu gleichen Bedeutung können über Vergleiche mit Wörterbüchern identifiziert und zusammengeführt werden. So kann z.B. die Mehrzahl eines Begriffs mit der Einzahl zusammengeführt werden. Z.B. „Schuhe“ wird kanonisiert mit „Schuh“. In Bezug auf Suchanfragen könnte dann die eigentliche Suchanfrage „schuhe“ in „schuhe“ umgeschrieben werden, bevor die Suchergebnisse ausgeliefert werden.
Was ist die semantische Relevanz von Keywords?
Die semantische Relevanz von Keywords basiert auf den semantischen Abständen zwischen den einzelnen Keywords. Wie bereits beschrieben ist dies über sogenannte Vektorraumanalysen festzustellen.
Semantische Beziehungsgraphen als Abbild semantischer Beziehungen zwischen Keywords und Entitäten
Semantische Beziehungsgraphen wie z.B. der Google Knowledge Graph oder Social Graph von Facebook bilden der Grad der Nähe zwischen Entitäten als Knoten zueinander ab. Über den Grad der Nähe lassen sich Entitäten- und Keyword-Cluster zu bestimmten thematischen Domänen bzw. Ontologien ermitteln, was auch als semantische Relevanz bezeichnet werden kann.
Ontologien können auch als Keyword-Kategorie verstanden werden. Über einen Kategorie-Affinitäts-Score lassen sich Keywords in eine Kategorie bzw. Ontologie einordnen. Ein Schwellenwert für diese Bewertung lässt sich über einen Durchschnitt einer Summe von Affinitäts-Scores der einzelnen Keywords in einem Inhalt ermitteln. Übersteigt der Wert den Schwellenwert kann ein Inhalt einer Ontologie zugeordnet werden. Liegt der Wert darunter gehört der Inhalt nicht zu der Ontologie. Über einen solche Einordnung von Inhalten kann Google die Dokumenten-Korpusse für ein Scoring nach Information-Retrieval-Gesichtspunkten zusammenstellen.
Es kann zu semantischen Konflikten zwischen den einem Inhalt zugeordneten Keyword-Kategorien kommen. Wenn die Entfernung im Beziehungsgraphen zwischen unterschiedlichen Keywords in verschiedenen dem Dokument zugeordneten Keyword-Kategorien zu groß ist kann es ein Hinweis auf einen semantischen Konflikt sein. Ist das der Fall kann eine als hierarchisch zweite Kategorie klassifizierte Ontologie ausgeschlossen werden. Somit könnte man verhindern, dass von den genutzten Begriffen her ähnliche Inhalte, aber von der Bedeutung her unterschiedliche nicht zusammen in den Suchergebnissen auftauchen.

Quelle: Google Patent, Systems and methods for measuring the semantic relevance of keywords
Die Nutzung eines Beziehungsgraphen für die Ausgabe von Suchergebnissen könnte so aussehen:
Ein Seed-Keyword wird als Suche in eine Suchmaschine eingegeben. Die Suchmaschine prüft aufgrund des Beziehungsgraphen die semantisch dem Seed-Keyword nahestehenden Keywords und gleicht diese mit denen im Inhalt(Dokument) vorkommenden Keywords ab. Besteht eine Übereinstimmung ist der Inhalt relevant für die Suchanfrage. Das in einer Ontologie befindliche Keyword-Set wird dynamisch über Machine Learning fortlaufend angepasst, wenn neue Dokumente auftauchen, die neue Keywords beinhalten. Somit kann es auch zu Verschiebungen bei der semantischen Relevanz der Keywords kommen. Somit können mit der Zeit neue Dokumente aufgenommen werden und andere verschwinden.
Google Patent zur semantischen Relevanz von Keywords
Das Google Patent Systems and methods for measuring the semantic relevance of keywords beschreibt, wie Google Keywords mit semantischer Relevanz identifizieren kann. Das Patent besagt nicht, dass Seiten für diese Begriffe und Phrasen ranken sollen oder dass man diese Begriffe und Phrasen hinzufügen sollte, damit eine Website für Begriffe besser rankt rankt. Das Patent zur semantischen Relevanz wurde ursprünglich 2016 eingereicht und beschreibt ein Datenverarbeitungssystem, das semantisch verwandte Keywords aus Informationsquellen im Web identifizieren kann. Es beantwortet wichtige Fragen zu Keywords und Semantik.
Einzelheiten zu diesem Patent folgen.
Systeme für die Datenverarbeitung für die Bestimmung der semantischen Relevanz von Keywords
Der Prozess beginnt mit einem Datenverarbeitungssystem mit mehreren Prozessoren. Es beginnt mit einem Start-Keyword von einem Nutzer, das zu einem Thema bzw. (Wissens-)Domäne gehört. Über dieses Start-Keyword lassen sich weitere semantischer Nähe befindliche Keywords identifizieren.
Das Datenverarbeitungssystem kann über einen semantischen Beziehungsgraphen Keyword-Kategorien identifizieren, einschließlich einer ersten und zweiten Keyword-Kategorie-Ebene.
Jede der Keyword-Kategorien enthält Keywords. Jedes der Keywords kann einen semantischen Abstand zum Ausgangs-Keyword aufweisen, der kleiner als ein semantischer Abstandsschwellenwert ist. Sprich Keywords, die einen Mindestabstand besitzen gehören zur thematischen Ontologie, andere nicht.
Ein zweiter Ansatz ist die Bestimmung eine Seed-Affinitätswert, der die Häufigkeit der Kookkurrenz von Begriffen zum Ursprungs-Keyword berücksichtigt. Das Datenverarbeitungssystem kann für jedes Keyword der ersten Keyword-Kategorie und der zweiten Keyword-Kategorie einen Keyword-Seed-Affinitätswert auf der Grundlage der Häufigkeit des Auftretens des Keywords zusammen mit dem Seed-Keyword in einer Informationsressource der Domänen-Entität erzeugen.
Wie die Datenverarbeitung funktionieren kann
Im Detail kann das Datenverarbeitungssystem:
- für die erste Keyword-Kategorie einen ersten Kategorie-Seed-Affinitäts-Score auf der Grundlage der Keyword-Seed-Affinitäts-Scores für jedes der Keyword in der ersten Keyword-Kategorie bestimmen
- für die zweite Keyword-Kategorie einen zweiten Kategorie-Seed-Affinitäts-Score auf der Grundlage der Keyword-Seed-Affinitäts-Scores für jedes der Keywords in der zweiten Keyword-Kategorie bestimmen.
- Vergleich der ersten Kategorie-Seed-Affinitätswerte und des zweiten Kategorie-Seed-Affinitätswertes mit einem Schwellenwert
- feststellen, dass der erste Kategorie-Seed-Affinitätswert größer als der Affinitätswert-Schwellenwert ist und der zweite Kategorie-Seed-Affinitätswert kleiner als der Schwellenwert ist
- Identifizieren eines semantischen Konflikts zwischen dem ersten und dem zweiten Keywords unter Verwendung des semantischen Beziehungsgraphen.
- Vergleichen des ersten Kategorie-Seed-Affinitäts-Punktwerts mit dem zweiten Kategorie-Seed-Punktwert, der auf die Identifizierung des semantischen Konflikts zwischen der ersten und zweiten Kategorie reagiert.
- Die erste Keyword-Kategorie kann als ausgewählt angezeigt werden und die zweite Keyword-Kategorie kann als nicht ausgewählt angezeigt werden, wenn festgestellt wird, dass der erste Kategorie-Affinitäts-Score größer ist als der zweite Kategorie-Affinitäts-Score
Das Datenverarbeitungssystem kann auch:
- Identifizieren eines semantischen Konflikts zwischen der ersten, zweiten und dritten Kategorie unter Verwendung des semantischen Beziehungsgraphen.
- Bestimmen einer ersten Kategoriegruppe und einer zweiten Kategoriegruppe, basierend auf dem semantischen Konflikt, wobei die erste Kategoriegruppe die erste Keyword-Kategorie enthält, die zweite Kategoriegruppe die zweite Keyword-Kategorie und die dritte Keyword-Kategorie enthält.
- Bestimmen eines ersten Gruppen-Seed-Affinitätswertes für die erste Kategoriegruppe und eines zweiten Gruppen-Seed-Affinitätswertes für die zweite Kategoriegruppe
- Vergleich des Ergebnisses der ersten Gruppe-Seed-Affinität mit dem Ergebnis der zweiten Gruppe-Seed-Affinitätr
- Vergleichen der Keyword-Seed-Affinitätsbewertung für jedes Keyword der ersten Keyword-Kategorie und der zweiten Keyword-Kategorie mit einer zweiten Affinitätsbewertungsschwelle
- Identifizieren einer Teilmenge von Keywords für jede der ersten Keyword-Kategorien und der zweiten Kategorien, von denen jedes einen Keyword-Seed-Affinitätswert hat, der kleiner ist als der zweite Affinitätswert-Schwellenwert.
- Berechnen eines ersten Kombinations-Scores auf der Grundlage der Keyword-Seed-Affinitäts-Scores für jedes Keyword in der ersten Keyword-Kategorie
- Berechnen eines zweiten Kombinations-Scores auf der Grundlage der Keyword-Seed-Affinitätsbewertungen für jedes der Keywords in der zweiten Keyword-Kategorie.
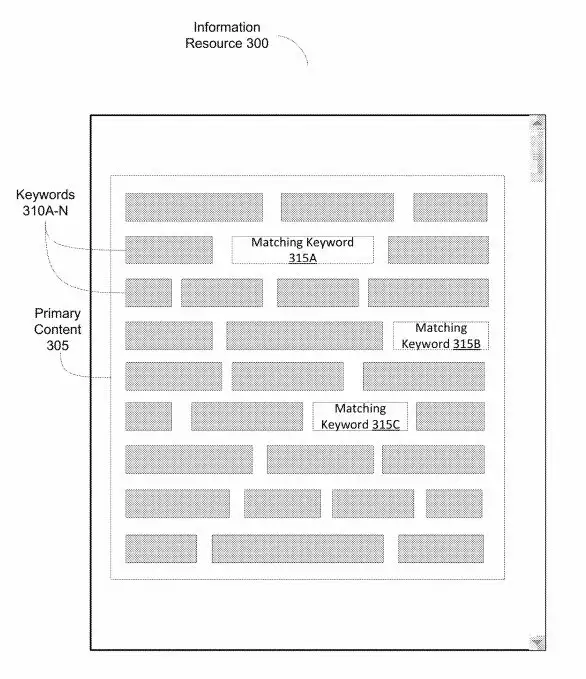
- Parsen der Informationsressource, um die Begriffe der Informationsressource zu identifizieren.
- Bestimmung, unter Verwendung des semantischen Beziehungsgraphen, für mindestens ein Keyword der ersten Keyword-Kategorie und der zweiten Keyword-Kategorie, eine erste semantische Übereinstimmung zwischen mindestens einem der Begriffe der Informationsressource und dem jeweiligen Keyword.
- Berechnen des Keyword-Seed-Affinitäts-Scores auf der Grundlage der Platzierung des entsprechenden Keywords in der Informationsressource als Reaktion auf die Bestimmung der ersten semantischen Übereinstimmung und die Bestimmung der zweiten semantischen Übereinstimmung.
- Identifizieren einer hierarchischen Tiefe der Informationsressource.
- Anpassen, für jede der Keyword-Seed-Affinitätsbewertungen der ersten Keyword-Kategorie und der zweiten Keyword-Kategorie, der Keyword-Seed-Affinitätsbewertung durch ein voreingestelltes Gewicht basierend auf der für die Informationsressource identifizierten hierarchischen Tiefe.
- Identifizieren eines Normalisierungsfaktors, der die durchschnittliche Häufigkeit des Keywords über Informationsressourcen für jedes Schlüsselwort der ersten und zweiten Schlüsselwortkategorie angibt.
- Anpassen des Keyword-Seed-Affinitäts-Scores für jede der Keyword-Seed-Affinitäts-Scores der ersten Keyword-Kategorie und der zweiten Keyword-Kategorie um den Normalisierungsfaktor
Messung der semantischen Relevanz über das Parsing von
Quelle: Google Patent, Systems and methods for measuring the semantic relevance of keywords
Über einen semantischen Beziehungsgraphen lässt sich mindestens ein Keyword aus einem Dokument einem Ursprungs-Keyword semantisch zuordnen. Für das Parsing eines Dokuments kann ein Keyword-Parser-Modul eingesetzt werden was folgende Aufgaben erfüllt:
- Parsing des Dokuments, um Keywords zu identifzieren
- Eine semantische Zuordnung von mindestens einem Keyword aus dem Dokument den beiden Keyword-Kategorien unter Berücksichtigung des semantischen Beziehungsgraphen
- Semantische Zuordnung von mindestens einem Keyword aus der ersten und/oder zweiten Keyword-Kategorie zum Ursprungs-Keyword
Quelle: Google Patent, Systems and methods for measuring the semantic relevance of keywords
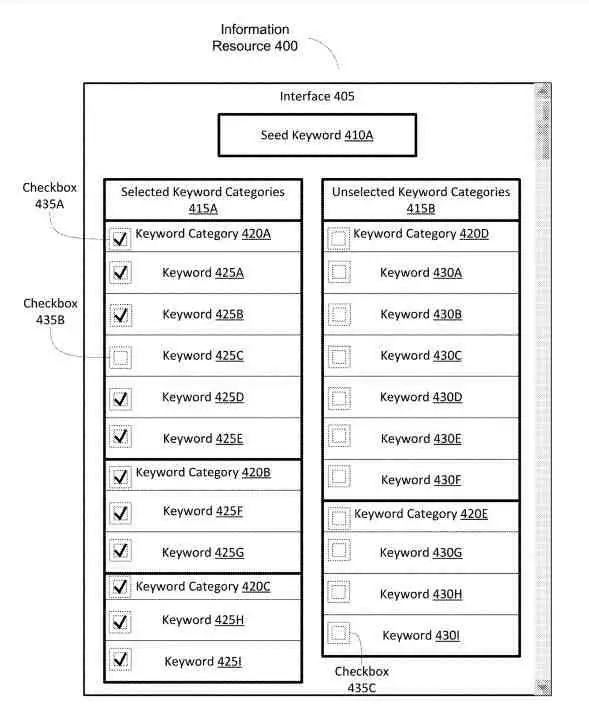
Verbindung der Knoten in einem semantischen Beziehungsgraph
Das Datenverarbeitungssystem kann die Knoten des semantischen Beziehungsgraphen verbinden, um einen Startknoten zu identifizieren, wobei ein semantischer Abstand zwischen dem Start-Keyword und dem Keyword des benachbarten Knotens besteht.

Quelle: Google Patent, Systems and methods for measuring the semantic relevance of keywords
Das Datenverarbeitungssystem kann eine Reihe von Kandidatenknoten aus den Knoten neben dem Startknoten identifizieren, die eine entsprechende Kante (Beziehung) mit einem entsprechenden semantischen Abstand zwischen einem Startknoten-Kandidatenknotenpaar von weniger als einem semantischen Abstandsschwellenwert aufweisen. Das Datenverarbeitungssystem kann Informationsressourcen / Dokumente der Domänenentität identifizieren.
Das Datenverarbeitungssystem kann die Informationsressourcen/Dokumente für jedes Kandidaten-Keyword der Kandidatenknoten analysieren, um die Häufigkeit zu bestimmen, mit der das Ursprungs-Keyword und das Kandidaten-Keyword in den Informationsressourcen / Dokumenten vorkommen.
Zusammengefasst: Keywords als kleinstes Element von semantischen Suchmaschinen
Keywords sind für moderne Suchmaschinen das kleinste und wichtigste Element. Aus Keywords lassen sich
- Entitäten aus grammatikalischen Konstrukten identifizieren
- Keyword-Kategorien bzw. Ontologien zusammensetzen
- Ganze Beziehungsgraphen bauen
Mit Blick auf semantische Suchmaschinen spielen Keywords eine zentrale Rolle weit über das klassische Matching zwischen Keywords in Suchanfragen und Keywords in Dokumenten hinaus. Über Methoden wie Machine Learning bzw. Natural Language Processing stehen Google jetzt alle Türen offen die wirkliche Bedeutung von Suchanfragen und Klassifizierung von Dokumenten auf einer performanten sowie skalierbaren Art und Weise umzusetzen. Klassische Textanalysen wie TF-IDF verlieren dadurch nicht an Bedeutung, sondern sind weiterhin ein wichtiger Bestandteil in jeder nachfrageorientierten Content-Konzeption.

- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























Kommentare sind geschlossen.