
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO beschäftigt sich damit wie Google für Suchanfragen mit Entitäten-Bezug u.a. über Natural Language Language Processing und Vektorraumanalysen passende Inhalte identifiziert und rankt. Dazu habe ich über 20 Google-Patente und weitere Quellen durchgearbeitet und den Extrakt daraus nachfolgend zusammengefasst.
Inhaltsverzeichnis
- 1 Die Rolle von Entitäten in der Suche
- 2 Die Rolle von Relevanz bei Google
- 3 Die Relevanzbestimmung von Dokumenten über Natural Language Processing
- 4 Die Relevanzbestimmung von Dokumenten über Vektorraumanalysen
- 5 Ermittlung von Entitäten-relevanten Dokumenten
- 6 Entitäten-basiertes Scoring von Dokumenten
- 7 Entitäten, Natural Language Processing und Vektorraumanalysen als zentrale Ansätze für Indexierung und Ranking
- 8 Google Patente zur Relevanzbestimmung von Content mittels Entitäten
- 8.1 Ranking search results based on entity metrics
- 8.2 Identifying topical entities
- 8.3 Automatic annotation for training and evaluation of semantic analysis engines
- 8.4 Question answering using entity references in unstructured data
- 8.5 Selecting content using entity properties
- 8.6 Automatic discovery of new entities using graph reconciliation
- 8.7 Systems and methods for re-ranking ranked search results
- 8.8 Document ranking based on entity frequency
- 8.9 Additive context model for entity resolution
- 8.10 Document ranking based on semantic distance between terms in a document
Die Rolle von Entitäten in der Suche
Um den Überblick zu bewahren möchte ich zu Beginn die möglichen Aufgaben von Entitäten in Information-Retrieval-Systemen wie Google zusammenfassen.
Die folgenden Aufgaben sind für ein auf Entitäten basierendes Information-Retrieval-System notwendig
- Interpretation von Suchanfragen
- Relevanzbestimmung auf Dokumentenebene
- Evaluation auf Domainebene / Herausgeber
- Ausgabe einer Ad-hoc-Antwort in Form eines Knowledge Panel, Featured Snippet …
Bei all diesen Aufgaben gilt es das Zusammenspiel aus Entitäten, Suchanfragen und Relevanz des Contents zu erfüllen. Im Beitrag Semantische Suche: Entitäten bei der Interpretation von Suchanfragen bin ich detailliert darauf eingegangen wie Google Suchanfragen anhand von Entitäten interpretieren kann. In diesem Beitrag geht es im Fokus um die Relevanzbestimmung eines Dokuments in Bezug auf die in einer Suchanfrage identifizierten Entitäten und/oder Suchbegriffe.
Die Rolle von Relevanz bei Google
Wie in dem Beitrag Relevanz, Pertinenz und Nützlichkeit bei Google erläutert muss grundsätzlich zwischen Relevanz (objektive Relevanz), Pertinenz (Subjektive Relevanz) und Nützlichkeit (situative Relevanz) differenziert werden. In diesem Beitrag konzentriere ich mich nur auf die objektive Relevanz eines Dokuments, da Pertinenz und Nützlichkeit eher etwas mit Personalisierung zu tun hat.
Die Relevanzbestimmung findet in zwei Schritten statt. Zuerst muss bezogen auf eine Suchanfrage eine Dokumenten-Korpus aus n Dokumenten ermittelt werden. Dies geschieht in der Regel über sehr einfache Information-Retrieval-Prozesse. Hier spielt das Vorkommen des Suchbegriffs oder von Synonymen im Dokument eine Rolle. Daraufhin können diese Dokumente auch mit Annotationen bzw. Kommentaren ähnlich wie Tags versehen werden, um diese nach Thema zu klassifizieren. Theoretische könnten diese auch mit weiteren Tags kommentiert werden, wie z.B. nach dem Zweck (verkaufen, beraten, informieren…). Dieser Prozess geschieht aber höchstwahrscheinlich bereits beim Parsen des Inhalts. Das Dokument liegt dann kommentiert im Index bereit.
Beim Auslösen einer Suchanfrage greift die Suchmaschine auf den passenden Korpus an Dokumenten inkl. Kommentaren zurück. Dabei spielt die Interpretation der Suchanfrage bzw. die Suchintention eine entscheidende Rolle. Damit haben ich mich in den Beiträgen Semantische Suche: Entitäten bei der Interpretation von Suchanfragen und Übersicht: Suchintention, Search Intent & Nutzerintention detailliert beschäftigt.
Im zweiten Schritt wird durch eine Ranking-Engine wie dem Hummingbird-Algorithmus über eine Scoring ermittelt wie relevant das jeweilige Dokument passend zur Suchanfrage ist. Neben der Relevanzbestimmung wird Google weitere Scoring-Ebenen hinsichtlich z.B. Aktualität oder Vertrauenswürdigkeit (Trust) sowie Autorität der Quelle und Expertise (E-A-T) anwenden um ein Ranking zu ermitteln. Welche dieser Scoring-Arten dann wie stark gewichtet werden wird wahrscheinlich individuell nach Branche oder sogar Keyword unterschiedlich sein. Dieses Scoring wird nur für die ersten 30-50 relevantesten Suchergebnisse in Echtzeit durchgeführt zugunsten der Geschwindigkeit.
In diesem Beitrag werde ich mich auf die Relevanzbestimmung auf Dokumentenebene konzentrieren. Mit möglichen Bewertungen hinsichtlich Trust und Autorität (E-A-T) in Bezug auf Entitäten werde ich mich in einem weiteren Beitrag auseinandersetzen.
Bei der Relevanzbestimmung für ein Dokument werden maßgeblich zwei Methoden genutzt.
- Natural Language Processing (Was ist Natural Language Processing?)
- Vektorraumanalysen (Was sind Vektorraumanalysen?)
Die Relevanzbestimmung von Dokumenten über Natural Language Processing
Dass Google bereits NLP in vielen Bereichen der Suche nutzt lässt sich über die Einführung des BERT-Updates und die Natural Language Processing API von Google erahnen. Das BERT-Update bezieht sich auf die Interpretation von Suchanfragen. Deswegen gehe ich an dieser Stelle nicht genauer darauf ein.
Im Endeffekt ist es aber egal ob man NLP auf einen Suchterm oder einen Text oder ein Text-Fragment wie z.B. einen Absatz, Satz oder Wörterfolge anwende. Der Prozess ist der Gleiche.
- Tokenisierung: Tokenisierung ist der Vorgang, bei dem ein Satz oder Text-Fragment in verschiedene Begriffe unterteilt wird.
- Kennzeichnung von Wörtern nach Wortarten: Wortartenkennzeichnung klassifiziert Wörter nach Wortarten wie z.B. Subjekt, Objekt, Prädikat, Adjektiv …
- Wortabhängigkeiten: Wortabhängigkeiten schafft Beziehungen zwischen den Wörtern basierend auf Grammatikregeln. Dieser Prozess bildet auch „Sprünge“ zwischen Wörtern ab.
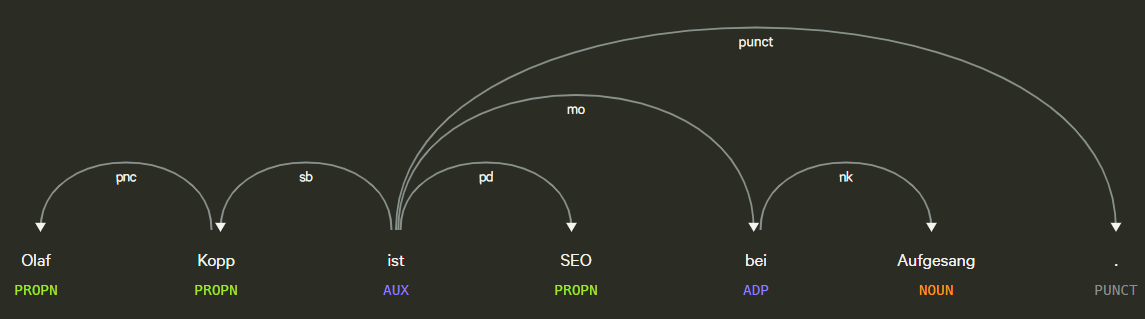
Beispiel für Part of Speech Tagging und Dependency Parsing, Quelle: Explosion.ai Demo
- Lemmatisierung: Die Lemmatisierung bestimmt, ob ein Wort verschiedene Formen hat und normalisiert Abwandlungen zur Grundform. Zum Beispiel ist die Grundform von Tiere, Tier oder von verspielt, Spiel.
- Parsing Labels: Die Kennzeichnung klassifiziert die Abhängigkeit oder die Art der Beziehung zwischen zwei Wörtern, die über eine Abhängigkeit verbunden sind.
- Analyse und Extraktion von benannten Entitäten: Dieser Aspekt sollte uns aus den vorangegangenen Beiträgen bekannt sein. Damit wird versucht, Wörter mit einer „bekannten“ Bedeutung zu identifizieren und Klassen von Entitätstypen zuzuordnen. Im Allgemeinen sind benannte Entitäten Menschen, Orte und Dinge (Substantive). Entitäten können auch Produktnamen enthalten. Dies sind im Allgemeinen die Wörter, die ein Knowledge Panel auslösen. Aber auch Begriffe, die kein eigenes Knowledge Panel auslösen können Entität sein. Dazu mehr im Beitrag Was ist eine Entität ? Was sind Entitäten ?
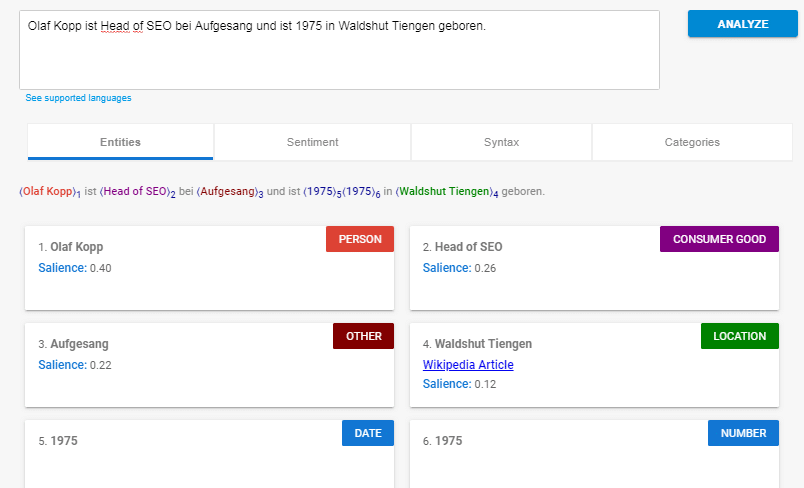
Beispiel für eine Entitäten-Analyse mit der Natural Language Processing API von Google.
- Salience-Scoring: Salience bestimmt, wie intensiv ein Text sich mit einem Thema beschäftigt. Dies wird in NLP basierend auf den sogenannten Indikatorwörtern bestimmt. Im Allgemeinen wird der Bekanntheitsgrad durch das Mitzitieren von Wörtern im Web und die Beziehungen zwischen Entitäten in Datenbanken wie Wikipedia und Freebase bestimmt. Google wendet dieses Verknüpfungsdiagramm wahrscheinlich auch auf die Entitätsextraktion in Dokumenten an, um diese Wortbeziehungen zu bestimmen. Eine ähnliches Vorgehen kennen erfahrene SEOs von der TF-IDF-Analyse.
- Sentiment-Analysen: Kurz gesagt, dies ist eine Bewertung der in einem Artikel zum Ausdruck gebrachten Meinung (Ansicht oder Haltung) zum im Text behandelten Entitäten.
- Fachkategorisierung: Auf Makroebene klassifiziert NLP Text in Betreffkategorien. Die Kategorisierung von Themen hilft dabei, allgemein zu bestimmen, worum es in dem Text geht.
- Textklassifizierung & Funktion: NLP kann noch weiter gehen und die beabsichtigte Funktion bzw. Zweck des Inhalts bestimmen.
- Extrahierung von Content-Typen: Google kann mithilfe von Strukturmustern bzw. des Kontext den Inhaltstyp eines bestimmten Texts ohne die Ausweisung mit strukturierten Daten bestimmen. Das HTML, die Formatierung des Texts und der Datentyp des Texts (Datum, Ort, URL usw.) können verwendet werden, um den Text ohne zusätzliches Markup zu verstehen Mithilfe dieses Prozesses kann Google ermitteln, ob es sich bei Text um ein Ereignis, ein Rezept, ein Produkt oder einen anderen Inhaltstyp handelt, ohne dass Markups verwendet werden müssen.
- Identifikation einer impliziten Bedeutung aufgrund der Struktur: Die Formatierung eines Textkörpers kann seine implizite Bedeutung ändern. Überschriften, Zeilenumbrüche, Listen und Nähe vermitteln ein sekundäres Verständnis des Textes. Wenn beispielsweise Text in einer HTML-sortierten Liste oder in einer Reihe von Überschriften mit Zahlen davor angezeigt wird, handelt es sich wahrscheinlich um einen Vorgang oder eine Rangfolge. Die Struktur wird nicht nur durch HTML-Tags definiert, sondern auch durch die visuelle Schriftgröße / -stärke und -nähe beim Rendern.
Natural Language Processing spielt eine große Rolle bei der Vorab-Klassifizierung und dementsprechenden Annotation von Texten. Wein Blick die Dokumentation der Natural Language Processing API von Google zeigt, dass man Texte über die API in Inhaltskategorien klassifizieren kann. Darüber ließen sich dann Dokumenten-Korpusse für den Index zusammenstellen.
Inhaltskategorien können z.B. sein
| Inhaltskategorie | |
|---|---|
| /Erwachsene | /Hobby & Freizeit |
| /Kunst & Unterhaltung | /Hobby & Freizeit/Vereine & Organisationen |
| /Kunst & Unterhaltung/Promis & Entertainmentnachrichten | /Hobby & Freizeit/Vereine & Organisationen/Jugendorganisationen & Ressourcen |
| /Kunst & Unterhaltung/Comics & Animation | /Hobby & Freizeit/Handwerk |
| /Kunst & Unterhaltung/Comics & Animation/Anime & Manga | /Hobby & Freizeit/Handwerk/Textilgestaltung |
| /Kunst & Unterhaltung/Comics & Animation/Cartoons | /Hobby & Freizeit/Wettbewerbe, Auszeichnungen & Preise |
| /Kunst & Unterhaltung/Comics & Animation/Comics | /Hobby & Freizeit/Outdoor |
| /Kunst & Unterhaltung/Unterhaltungsindustrie | /Hobby & Freizeit/Outdoor/Angeln |
| /Kunst & Unterhaltung/Unterhaltungsindustrie/Film- & TV-Industrie | /Hobby & Freizeit/Outdoor/Wandern & Camping |
| /Kunst & Unterhaltung/Unterhaltungsindustrie/Musik-Aufnahmetechnik | /Hobby & Freizeit/Paintball |
| /Kunst & Unterhaltung/Veranstaltungen & Listings | /Hobby & Freizeit/Fernsteuerung & Modellbau |
| /Kunst & Unterhaltung/Veranstaltungen & Listings/Bars, Clubs & Nachtleben | /Hobby & Freizeit/Fernsteuerung & Modellbau/Modellzüge & -eisenbahnen |
| /Kunst & Unterhaltung/Veranstaltungen & Listings/Konzerte & Musikfestivals | /Hobby & Freizeit/Besondere Anlässe |
| /Kunst & Unterhaltung/Veranstaltungen & Listings/Expos & Messen | /Hobby & Freizeit/Besondere Anlässe/Feiertage & Saisonale Veranstaltungen |
| /Kunst & Unterhaltung/Veranstaltungen & Listings/Filmfestivals | /Hobby & Freizeit/Besondere Anlässe/Hochzeiten |
| /Kunst & Unterhaltung/Veranstaltungen & Listings/Filme & Theateraufführungen | /Hobby & Freizeit/Wasseraktivitäten |
| /Kunst & Unterhaltung/Lustiges & Quizspiele | /Hobby & Freizeit/Wasseraktivitäten/Bootfahren |
| /Kunst & Unterhaltung/Spaß & Quiz/Flash-basierte Unterhaltung | /Hobby & Freizeit/Wasseraktivitäten/Surfen & Schwimmen |
| /Kunst & Unterhaltung/Spaß & Quiz/Lustige Tests & Witzige Umfragen | Heim & Garten |
| /Kunst & Unterhaltung/Humor | /Heim & Garten/Bett & Bad |
| /Kunst & Unterhaltung/Humor/Lustige Bilder & Videos | /Heim & Garten/Bett & Bad/Badezimmer |
| /Kunst & Unterhaltung/Humor/Politischer Humor | /Heim & Garten/Hausdienstleistungen |
| /Kunst & Unterhaltung/Filme | /Heim & Garten/Hausdienstleistungen/Reinigungsdienste |
| /Kunst & Unterhaltung/Musik & Audio | /Heim & Garten/Garten- & Landschaftsbau |
| /Kunst & Unterhaltung/Musik & Audio/CD & Audio | /Heim & Garten/Haushaltsführung & Innenraumgestaltung |
| /Kunst & Unterhaltung/Musik & Audio/Klassische Musik | /Heim & Garten/Haushaltsgeräte |
| /Kunst & Unterhaltung/Musik & Audio/Country-Musik | /Heim & Garten/Einrichtungsgegenstände |
| /Kunst & Unterhaltung/Musik & Audio/Tanzmusik & Elektronische Musik | /Heim & Garten/Einrichtungsgegenstände/Vorhänge & Fensterdekoration |
| /Kunst & Unterhaltung/Musik & Audio/Experimentelle Musik & Industrial | /Heim & Garten/Einrichtungsgeg |
Eine komplette Liste aller Inhaltskategorien findest Du hier.
Über die Entitäten-Analyse können die Haupt- und Neben-Entitäten eines Dokuments ermittel werden und über den Salience Score lassen sich die Neben-Entitäten in eine Reihenfolge bringen.
Die Entitätsanalyse gibt eine Gruppe der erkannten Entitäten und der mit diesen Entitäten verknüpften Parameter zurück, wie zum Beispiel Entitätstyp, Relevanz der Entität für den Gesamttext und Textstellen, die sich auf dieselbe Entität beziehen. Entitäten werden in der Reihenfolge ihrer salience-Scores (vom höchsten bis zum niedrigsten) zurückgegeben, die ihre Relevanz für den Gesamttext wiedergeben.
Der Salience-Score ist eine Gewichtung innerhalb des Texts oder des Text-Fragments. Er lässt sich nicht für eine Bewertung des Dokuments innerhalb des jeweiligen Korpus also für ein Scoring hinsichtlich des Rankings nutzen.
Die Funktionsweise der NLP-API von Google kannst Du hier über die Demo selbst testen.
Zusammengefasst kann man sagen, dass NLP in erster Linie für das Verständnis, die Klassifizierung und Organisation von Texten/Dokumenten/Inhalten nutzen kann. Vermutlich werden hier Entitäten ein immer zentralere Rolle bei der Organisation spielen wie in dem Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index erläutert.
Für die Bewertung bzw. die Gewichtung von Dokumenten / Inhalten hinsichtlich Ranking nutzt Google Vektorraumanalysen.
Die Relevanzbestimmung von Dokumenten über Vektorraumanalysen
Für die Relevanzbestimmung von Dokumenten in Bezug zu einer Suchanfrage nutzt Google sogenannte Verktorraumanalysen, die die gestellte Suchanfrage als Vektor abbilden und in Beziehung zu relevanten Dokumenten im Vektorraum stellen. Wenn bekannte Entitäten bereits im Suchterm vorkommen kann Google dieses dann in Beziehung zu Dokumenten setzen in denen diese Entitäten auch genannt sind. Dokumente können jegliche Art von Content sein wie Text, Bilder, Videos …
Über die Größe des Winkels der Vektoren kann ein Scoring auf die Dokumente angewendet werden. Es könnte auch das Klickverhalten in den SERPs eine Rolle bei der Relevanzbestimmung spielen.
Vektoren und Vektorräume lassen sich auf verschiedenen Ebenen anwenden. Egal ob Word2Vec, Phrase2Vec, Text2Vec oder Entität2Vec. Der Haupt-Vektor stellt das zentrale Element dar. Handelt es sich um eine Entität kann diese ins Verhältnis zu anderen Entitäten oder Dokumenten gestellt werden.
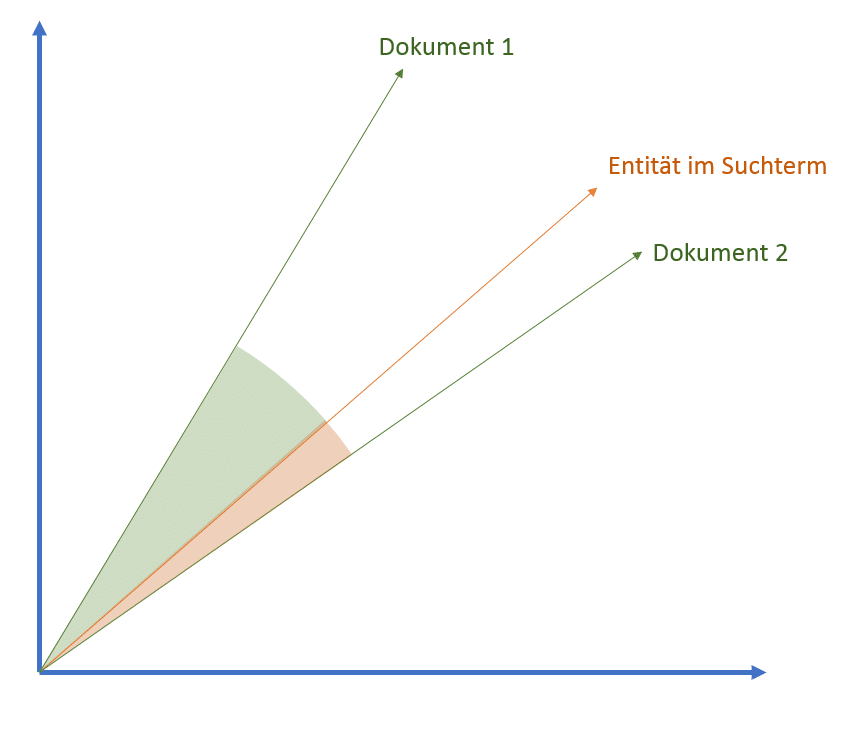
Entitäten und Dokumente im Vektorraum
Vektorraumanalysen lassen sich zum einen für das Scoring hinsichtlich Ranking nutzen, können aber auch einfach nur für die Organisation von Elementen wie z.B. semantisch sich nahestehenden Entitäten, Themen oder themenspezifische Begriffen genutzt werden. Ist der Hauptvektor ein Suchterm in Bezug zu Dokumenten kann die Größe des Winkels bzw. die Nähe für das Ranking bzw. Scoring genutzt werden.
Ermittlung von Entitäten-relevanten Dokumenten
Die Ermittlung von Dokumenten, die relevant für eine nachgefragte Entität sind lässt sich über Anntotationen bzw. das Vertaggen der relevanten Dokumente oder die Identifikation von Entitäten-Erwähnungen durchführen. Diese kann manuell durch Editoren oder automatisiert geschehen.
So können Autoren bzw. Editoren Beiträge mit Tags zu allen im Text vorkommenden benannten Entitäten wie Personen, Orte, Organisationen, Produkte, Events … und Konzepten versehen. Dadurch würde pro Entität ein relevanter Korpus an Dokumenten entstehen. Über diese Methode alleine lässt sich aber keine Gewichtung der Dokumente in Bezug auf die Entität durchführen. Es gibt nur getaggt oder nicht getaggt.
Bei Google kann man aufgrund der Vielzahl an Dokumenten von einem automatisierten Prozess ausgehen, wie im Abschnitt zum Natural Language Processing beschrieben.
Desweiteren ist es möglich, dass Google Dokumente, ähnlich der Termfrequenz, anhand der Häufigkeit der Entitäts-Nennungen gewichtet werden. Dokumente, die einen bestimmten Schwellenwert einer Term- oder Entitäten-Frequenz übersteigen werden in den Scoring-Prozess übernommen. Der Rest bleibt unbewertet und reiht sich eher zufällig ab Position 30-50 hinten an.
Die Analyse der Häufigkeit von vorkommenden Termen ist keine neue Erfindung und sollte keinem SEO fremd sein.
Ähnlich wie bei der inversen Termfrequenz TF-IDF bzw. WDF*IDF lässt sich eine inverse Entitätenfrequenz ermitteln. Hier werden die Anzahl der in einer Entitäts-Beschreibung vorkommenden Terme und andere Entitäten ins Verhältnis gesetzt und diese dann ins Verhältnis zu allen Entitäten-relevanten Dokumenten im Korpus gesetzt.
Über die Entitäten-relevanten Dokumente lassen sich im ersten Schritt Verbindungen zwischen Termen und Entitäten feststellen. Je häufiger eine Kookkurenz zwischen bestimmten Termen und einer Entität vorkommen, desto wahrscheinlicher ist eine Beziehung zueinander. Während man bei TF-IDF die Proof-Terms über den Bezug zu einem Keywords herstellt. werden die Terme hier in Bezug zur angefragten Entität ermittelt.
Die Gewichtung erfolgt zusätzlich über die Relevanz des jeweiligen Dokuments in dem die Kookkurrenz vorgekommen ist. Anders ausgedrückt die Nähe des Dokuments zur nachgefragten Entität.
Die Formel dazu lautet wie folgt:
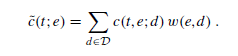
Dabei steht t für Term, e für Entität, d für Dokument.
Die Begriffe, die in unmittelbarer Umgebung der genannten Entitäten als Kookkurrenzen vorkommen können mit dieser verknüpft werden. Daraus können Attribute als auch andere „Neben-Entitäten“ zur „Haupt-Entität“ aus dem Inhalte extrahiert und im jeweiligen „Entitäten-Profil“ hinterlegt werden. Die Nähe zwischen den Begriffen und der Entität im Text als auch die Häufigkeit der vorkommenden Haupt-Entität-Attribut-Paare oder Haupt-Entität-Neben-Entität-Paare kann sowohl als Validierung als auch als Gewichtung genutzt werden.
Ein ähnliches Vorgehen setzt Google offiziell bestätigt schon lange bei der Bewertung von Verlinkungen ein. Hier wird nicht nur der Fokus auf den Ankertext des Links gelegt, sondern auch auf die umgebenden Begrifflichkeiten.
Hier sollten die beiden Verfahren Bag of Words und Contextual Bag of Words (CBOW) nicht unerwähnt bleiben.
Wie viele Wörter umfasst bzw. wie groß ein Fenster für ein Text-Fragment ist lässt sich pauschal nicht sagen. Theoretisch könnte es auch ein gesamter Text sein. Sinnvoller aber ist die Betrachtung einzelner Absätze oder Kapitel in Kombination mit einer Gesamtbetrachtung eines Texts. Das würde auch erklären warum sehr umfangreiche Inhalte für hunderte von Begriffen zusammen Top-Rankings haben können.
Entitäten-basiertes Scoring von Dokumenten
Das Scoring von Dokumenten in Bezug auf eine Entitäten-relevante Suchanfrage läuft in zwei Schritten ab. Zuerst wird nach klassischem Information Retrieval Ansätzen eine Auswahl an Top-n Dokumenten ermittelt und in eine Reihenfolge gebracht. Im zweiten Schritt wird die Relevanz dieser Dokumente in Bezug auf die nachgefragte(n) Entität(en) gewichtet und die Reihenfolge neu geordnet. Hier ist die Formel dazu:
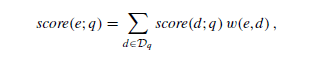
Dabei steht e für Entität, q für Suchanfrage, d für Dokument und Dq für alle Dokumente, die überhaupt für die Suchanfrage in Frage kommen. Die Performance lässt sich deutlich verbessern wenn Dq sich nur auf die Top k Dokumente beschränkt.
Das Entitäten basierte Scoring kann nach den gleichen Scoring-Algorithmen durchgeführt wie bei Term-basierten Such-Systemen nur, dass Terme gegen Entitäten getauscht werden. Um die Performance zu verbessern wäre es noch möglich die verbundenen Entitäten und deren Gewichtung pro Dokument im Dokumenten-Index zu hinterlegen. (Mehr dazu im Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index )
Diese Art des Entitäten basierten Scorings lässt sich einfach auf eine klassische Keyword-basierte Suche aufsetzen bzw. man kann beide Verfahren für sich alleine als auch kombiniert anwenden.
Entitäten, Natural Language Processing und Vektorraumanalysen als zentrale Ansätze für Indexierung und Ranking
Zum Abschluss dieses Beitrags möchte ich aus meinen Erkenntnissen aus den letzten 10 Monaten Recherche ein Zwischenfazit ziehen.
Die Fortschritte im Machine Learning und dem Quantencomputer machen Methoden wie Natural Language Processing und Vektorraumanalysen für Google immer performanter und skalierbarer in der Praxis anwendbar, was die Interpretation von Entitäten, Suchanfragen und Inhalten sowie deren Ranking immer besser möglich macht.
Ich habe mich mit den möglichen Datenquellen für den Knowledge Graph beschäftigt und den Herausforderungen, die Google beim Data Mining von Informationen für den Knowledge Graph zu bewältigen hat. Dabei ist klar geworden welche zentrale Rolle Natural Language Processing für das Data Mining aus unstrukturierten Daten für Google hat. Weiterhin bleibt hier aber das Spannungsfeld aus Vollständigkeit und Richtigkeit der Informationen bestehen. Hier die einzelnen Beiträge dazu:
https://www.sem-deutschland.de/blog/entitaeten-basiertes-indexing/
Alles was Du als SEO zu Entitätstypen, -Klassen & Attributen wissen solltest
Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph?
Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten?
Die Rolle von Natural Language Processing für Data Mining, Entitäten & Suchanfragen
Ferner habe ich mich der Funktionsweise der Knowlegde Panel und Knowledge Cards beschäftigt. Den Beitrag findest Du hier:
Desweiteren habe ich mich mit der Interpretation von Suchanfragen beschäftigt und welche Rolle Entitäten und der Knowlege Graph spielen können. Dabei ist klar geworden wie wichtig das Zusammenspiel von Knowledge Graph, Rankbrain (jetzt auch BERT), Hummingbird und Entitäten als zentrales Element dabei haben. Hier der Beitrag:
Wie versteht Google Suchanfragen durch Search Query Processing?
Das von mir entwickelte Schaubild zum möglichen Information-Prozess bei Google scheint dem Ganzen schon nahe zu kommen.
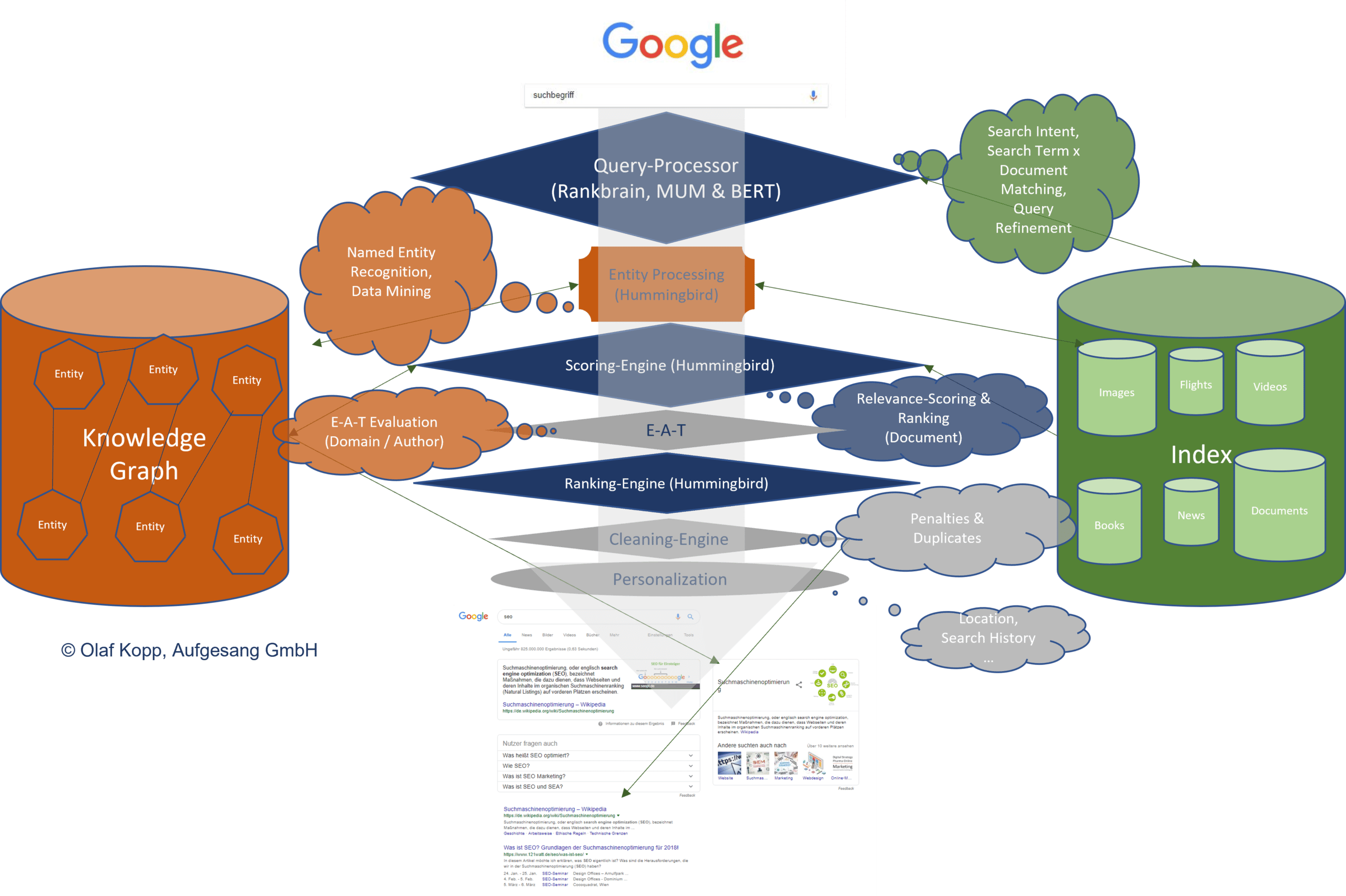
Möglicher Prozess für Query Processing, Scoring und Ranking bei Google (Zum Vergrößern auf die Grafik klicken)
Die Interpretaion der Suchterme wird über Rankbrain hinsichtlich Suchintention und BERT hinsichtlich semantisch thematischer Einordnung der Suchanfrage abgewickelt. Dabei kommen sowohl NLP (BERT) als auch Vektorraumanalysen (Rankbrain) zum Einsatz. Es ist auch entscheidend inwiefern die Suchanfrage einen Entitäten-Bezug hat oder nicht. Hierbei entscheidet sich dafür wie groß der Einfluss der Informationen aus dem Knowledge Graph sind.
Entitäten entwickeln sich immer mehr zum zentralen Organisations-Element im Google-Index. Insofern Suchanfragen einen Entitäten-Bezug haben kann Google über den Knowledge Graph schnell auf sämtliche gespeicherte Informationen zu den relevanten Entitäten und Beziehungen zu anderen Entitäten zugreifen. Suchanfragen ohne Bezug zu im Knowledge Graph erfassten Entitäten, werden wie gehabt nach klassischen Information Retrieval Regeln behandelt. Allerdings kann Google inzwischen über NLP auch Entitäten, die sich nicht im Knowledge Graph befinden identifizieren, insofern im Suchterm eine im Ansatz vorhandene grammatikalische Struktur aus Subjekt, Prädikat und Objekt (Triples) erkennbar ist.
Ich denke es findet zukünftig über eine Schnittstelle ein immer größerer Austausch zwischen dem klassischen Google-Suche-Index und dem Knowledge Graph statt. Je mehr Entitäten im Knowledge Graph erfasst sind, desto größer wird der Einfluss auf die SERPs. Wie bereits in anderen Beiträgen dieser Reihe erwähnt steht Google aber immer noch vor der große Herausforderung Vollständigkeit und Richtigkeit in Einklang zu bringen.
Für das eigentliche Scoring durch Hummingbird spielen die Entitäten auf Dokumentenebene keine große Rolle. Sie sind eher ein wichtiges Organisations-Element zur Bildung von ungewichteten Dokumenten-Korpussen auf Seite des Suche-Index. Das eigentlich Scoring der Dokumente übernimmt Hummingbird nach klassischen Information Retrieval-Regeln. Auf Domainebene sehe ich den Einfluss von Entitäten auf das Ranking aber deutlich höher. Stichwort: E-A-T- Dazu aber im nächsten Beitrag mehr…
Google Patente zur Relevanzbestimmung von Content mittels Entitäten
Nachfolgend möchte ich zum Abschluss auf einige Google-Patente eingehen, die mir bei der Recherche besonders aufgefallen sind und die oben beschrieben Ansätze untermauern. Alle aufgeführten Patente sind noch aktiv, haben noch eine Laufzeit bis mindestens 2025 und sind von Google gezeichnet.
Ranking search results based on entity metrics
Dieses Google-Patent wurde im Dezember 2017 an Google übertragen und wurde 2019 aktualisiert. Ich finde es ist mit das spannendste Patent, weil es beschreibt wie Suchergebnisse anhand von Daten aus dem Knowledge Graph in Reihenfolge gebracht werden. Es beschreibt die Brücke zwischen der Welt des Knowledge Graph und dem klassischen Suche-Index.
Im ersten Schritt werden basierend auf einer Suchanfrage die beiden relevantesten Ergebnisse aus dem Knowledge Graph ermittelt. Diese Ergebnisse können nur Entitäten sein. Zu diesen Entitäten werden eine erste Reihe von Metriken ermittelt. Diese Metriken können völlig unabhängig von Suchanfrage ermittelt werden. Wie viele Metriken von der ersten Entität und wie viele von der zweiten Entität ausgewählt werden hängt von dem Grad der Relevanz der beiden Entitäten in Bezug auch die Suchanfrage ab. Hier könnte der Relevance Score aus dem Knowledge Graph eine Rolle spielen.
Im Nächsten Schritt werden für die beiden Entitäten die jeweiligen Entitätstypen ermittelt. Aufgrund der Entitätstypen werden die Metriken gewichtet. So ist das Attribut „beruf“ für den Entitätstyp „person“ ggf. wichtiger als das Attribut „nationalität“.
Es können eine Kombination aus verschiedenen Metriken genutzt werden wie
- eine Verwandtschaftsmetrik
- eine Entitätstyp-Metrik
- eine Contribution-Metrik
- eine Preismetrik
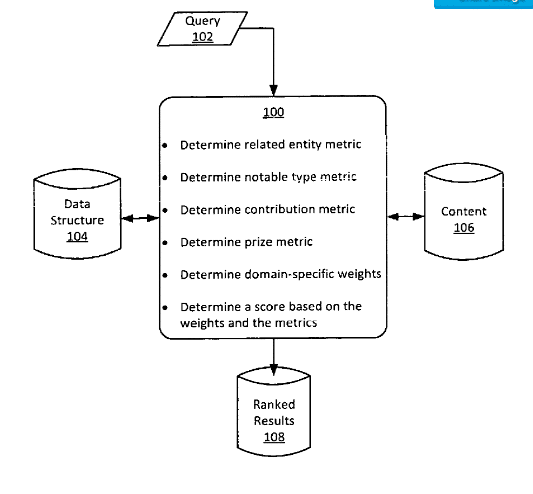
Die Verwandschaftsmetrik kann aufgrund des gleichzeitigen Auftretens eines in einer Suchanfrage enthaltenen Entität mit dem Entitätstyp der Entität auf Webseiten bestimmt werden. Ein Entitätstyp kann ein definierendes Merkmal und / oder eine Kategorisierung einer Entität sein. Wenn die Suchanfrage beispielsweise die Entität“Empire State Building“ enthält, für die als Entitätstyp „Skyscraper“ festgelegt wurde, kann dies durch das gleichzeitige Auftreten „Empire State Building“ und „Skyscraper“ in dem Inhalt einer Website die Verwandtschaftsmetrik ermittelt werden. Bei dieser Metrik spielen Kookkurrenzen, also das die parallele Nutzung bestimmter Begriffe bzw. Entitäten oder Entitätstypen eine besondere Rolle.
Die Entitätstyp-Metrik kann durch das Verhältnis einer globalen Popularitäts-Werts zum Rang eines Entitätstyps ausgedrückt werden. Darin drückt sich dann eine Wichtigkeit der Entität in Bezug auf z.B. eine Berufsgruppe, Branche … aus.
Die Contribution-Metrik ist eine Art Einfluss-Kennzahl basierend auf der Nennung in z.B. Top-Listen wie „Die besten 20 SEOs in Deutschland“ oder Bewertungen und Kritiken.
Die Preis-Metrik basiert auf gewonnenen Preisen wie z.B. Awards. Zum Beispiel kann ein Film mit einer Vielzahl von Preisen wie Oscars und Golden Globes ausgezeichnet worden sein, die jeweils einen bestimmten Wert haben.
Interessant an dem Patent ist auch der Verweis auf den Begriff Domains, der eine übergeordnete Klassifizierung verschiedener Entitätstypen beschreibt.
In some implementations, elements of a domain share common characteristics, properties, traits, categorization techniques, any other suitable parameters, or any combination thereof. In an example, domains include “Books,” “Film,” “People,” and “Places.” Entity types within the domain “Movies” may include: “Actor,” “Director,” and “Filming Location.”
Diese genannten Metriken können je nach Domain unterschiedlich gewichtet werden. Zum Beispiel kann ein Film mit einer Vielzahl von Preisen wie Oscars und Golden Globes ausgezeichnet worden sein, die jeweils einen bestimmten Wert haben.
Identifying topical entities
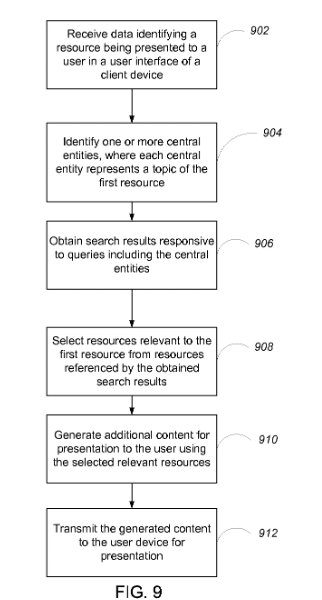 Dieses Google-Patent wurd in der neuesten Version im Oktober 2017 von Google gezeichnet und hat seit Dezember 2019 den Status „Application status is active“. Das Patent beschreibt Methoden, wie Dokumente nach dem Thema. bzw. den Themen klassifiziert werden können. Die Dokumente werden über die im Inhalte genannten weiteren Entitäten identifziert. So wird ein Beitrag über den Basketballspieler Michael Jordan immer auch verwandt Entitäten und Entitäts-Typen wie z.B. Basketball, NBA oder Chicago Bulls enthalten. Darüber kann das Dokument eindeutig der Entität Michael Jordan (Basketball-Spieler) und nicht Michael Jordan den Schriftsteller zugeordnet werden.
Dieses Google-Patent wurd in der neuesten Version im Oktober 2017 von Google gezeichnet und hat seit Dezember 2019 den Status „Application status is active“. Das Patent beschreibt Methoden, wie Dokumente nach dem Thema. bzw. den Themen klassifiziert werden können. Die Dokumente werden über die im Inhalte genannten weiteren Entitäten identifziert. So wird ein Beitrag über den Basketballspieler Michael Jordan immer auch verwandt Entitäten und Entitäts-Typen wie z.B. Basketball, NBA oder Chicago Bulls enthalten. Darüber kann das Dokument eindeutig der Entität Michael Jordan (Basketball-Spieler) und nicht Michael Jordan den Schriftsteller zugeordnet werden.
Wichtig ist hier festzuhalten, dass in dem Dokument Entitäten als Themen oder Konzepte definiert werden. Es geht hier also weniger, wie so häufig in erster Linie um benannte Entitäten, wie z.B. Personen oder Unternehmen, sondern viel mehr um Entitäten in Form von Themen.
Dieses Patent ist damit ähnlich interessant wie das bereits besprochene Google Patent“Ranking search results based on entity metrics“ da es ebenfalls eine Brücke zwischen dem Knowledge Graph und den im Suche Index befindlichen Dokumenten und Medien schlägt.
The additional content system 130 includes or can communicate with an entity graph store 140. The entity graph store 140 can be one or more data stores that store an entity graph compiled from information about entities that are associated with resources in a collection of resources. The collection of resources can be, for example, resources that have been indexed by the search engine 120. The entity graph can include a respective node for each entity that is associated with at least one resource in the collection of resources. Entities can be associated with a resource if they occur in the content of the resource, are extracted or gathered from the resource by conventional or other techniques, and so on.
Hier wird beschrieben, wie Entitäten in Beziehung zu Inhalten gesetzt werden, was die „Entity-First“- Gedanken, den ich im Beitrag Entitäten-basierte Indexierung: Vom Content-Index zum Entitäten-Index erläutert habe untermauert.
Das Patent beschreibt auch wie Entitäten im Knowledge Graph mit einer Kante verbunden werden bzw. in Beziehung gebracht werden können. Wenn in vielen Inhalten des relevanten Dokumenten-Korpus Entitäten häufig zusammen genannt werden lassen sich diese beiden Entitäten in Beziehung zueinander bringen.
If two entities are frequently associated with the same resource in the collection, the nodes corresponding to those entities in the entity graph are connected with an edge. In particular, two nodes are connected with an edge if the two entities represented by the nodes are associated with the same resource in the collection more frequently than would be expected if the two entities were unrelated or independent. For example, the nodes representing the entities “michael jordan” and “basketball” may be connected by an edge in the entity graph because the probability of both entities being associated with the same resource in the collection more than a threshold amount higher than it would be if the entity “michael jordan” did not have any relation to the entity “basketball.” The edges can be weighted so that, for example, the more times two entities are associated with the same resource, the greater the weight of the edge between the two nodes corresponding to the two entities.
Desweiteren beschreibt das Patent wie erfasste Knoten bzw. Entitäten, die keine Kanten bzw. keine oder nur schwache Beziehungen zu anderen Entitäten haben wieder aus dem Dokumenten-bezogenen Entitäten-Graphen entfernt werden können. Dadurch lassen sich die relevanten Entitäten von den irrelevanten segmentieren.
Sobald die Haupt-Entitäten eines Dokuments identifiziert wurden können diese über einen Centrality Score gewichtet werden, der auf der Anzahl der ausgehenden Verbindungen zu anderen Entitäten im Knowledge-Graph basiert. Das ist ein wichtiges Konzept auch mit Blick auf die Gewichtung einer Entität in Bezug auf ein Thema, worauf ich aber in einem anderen Betrag noch weiter eingehen werde.
Für die Ermittlung der Haupt-Entitäten, die durch ein Dokument repräsentiert werden wird ein „Centrality Score“ ermittelt, der auf der Summe der ausgehenden Kanten, also Beziehungen zu anderen Entitäten, ermittelt wird. Dies könnte der Salience Score sein, den man aus der Entitäts-Analyse der Google NLP-API kennt.
Once the central entities are identified, the additional content system 130 generates an initial centrality score for each central entity based on weights of the outgoing edges of the node representing the entity. For instance, the initial centrality score for an entity A represented by node A in the entity graph can be based on the ratio of the sum of the weights of the outgoing edges of node A to the sum of the weights of all of the edges in the entity graph. Thus, nodes that have a large number of heavily-weighted outgoing edges will have higher initial centrality scores.
Ein weiteres Signal für die Wichtigkeit einer Entität kann die Häufigkeit der Nennung innerhalb der im relevanten Korpus befindlichen Dokumente sein. Hier kann auch die Inverse Document Frequency (IDF) eine Rolle spielen.
A second signal potentially used by the additional content system 130 is how often the entity occurs in the collection of resources. The initial centrality score for an entity can be decreased based on how often the entity occurs in the collection of resources so that scores for entities that occur frequently in the collection are lower than those of entities that do not occur frequently. In some implementations, the initial centrality score for each entity is adjusted using the inverse document frequency (IDF) for the entity. The IDF for the entity can be the number of times the entity occurs in the resource divided by the number of times the entity occurs in the collection of resources. By adjusting the initial centrality score for an entity using the IDF, the additional content system 130 ensures that entities are not deemed to be highly relevant to a main topic of the resource simply because they occur frequently in other resources in the collection.
Spannend ist auch eine ergänzende Gewichtung, die auf der Häufigkeit der Suchanfragen nach den Entitäten beruht, bei denen das Dokument ausgewählt wurde, wo wir wieder bei der Klickrate wären. Ein Dokument, was in Verbindung mit einer Suche in Bezug zu einer Entität häufig ausgewählt wird, verstärkt den Zusammenhang zwischen dem Dokument und der Entität.
Another signal that can be used by additional content system 130 is whether the entity appears in a log of search queries that have resulted in requests for the resource. In particular, entities that appear in the log of search queries can have their initial centrality scores increased. In some implementations, entities appearing more frequently in the log of search queries will have their scores increased by a larger amount than scores for those that appear less frequently.
Als weiteres Signal wird auch die Nennung der Entität im Seitentitenl, der URL oder den Meta-Daten genannt.
Additional signals can relate to where the entity occurs in the resource. For example, entities that occur in the title of a resource, the URL of the resource, or in metadata associated with the resource can have their initial centrality scores increased.
Neben dem Centrality Score wird eine recht einfache Methode beschrieben um die thematische Haupt-Entität einer Quelle zu identifizieren. Stehen zwei Entitäten A und B zur Auswahl wird diese Entscheidung einfach nach dem Ranking des Dokuments in Bezug auf die Suche nach A und B bgetroffen. Rankt ein Dokument in Bezug auf A höher als in Bezug auf B ist A die thematische Haupt-Entität.
Automatic annotation for training and evaluation of semantic analysis engines
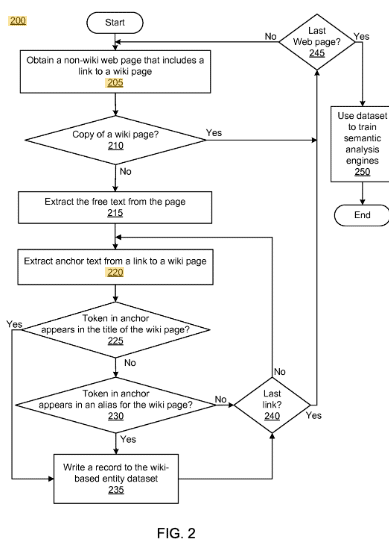
Dieses Google Patent wurde 2017 an Google übertragen. Es wird eine Methode beschrieben Dokumente semantisch zu analysieren, die einer Beziehung zu einer Autoritäts-Seite wie z.B. Wikipedia stehen. Die Beziehung ist eine Verlinkung dieser Dokumente zu der Autoritätsseite. Über diesen Weg werden diese Dokumente mit Tags bzw. Kommentierung versehen. Der Korpus von mit Anmerkungen versehener Dokumente kann für jede Webseite Erwähnungen von Entitäten, den Ort im Dokument einer Entitätserwähnung und den Ort der Autoritäts-Seite enthalten, auf die die Erwähnung verweist.
Eine solche Verlinkung könnte ein ausgehender Link mit dem Ankertext „Relevanz“ zum passenden Wikipedia-Beitrag sein. Dadurch würde dieses Dokument hier Kandidat für den Korpus zur Entität Relevanz sein.
Question answering using entity references in unstructured data
Dieses Google-Patent wurde 2017 an Google übertragen und beschreibt den Vorgang wie bei Suchanfragen mit Entitäten-Bezug Dokumente geranked und eine Knowledge Card oder ein Featured Snippet basierend auf den Suchergebnissen generiert werden könnte.
So können typische Wer-, Wo- und Was-Fragen z.B. in Form von natürlicher Sprache via Voice Search beantwortet werden. Zur Beantwortung können im Vorfeld von Nutzern gegebene Antorten als auch die ersten Suchergebnisse genutzt werden. In der Praxis sieht man eher zweiteres. Meistens stammt die Antwort in den Featured Snippets aus einem der fünf ersten Suchtreffer.
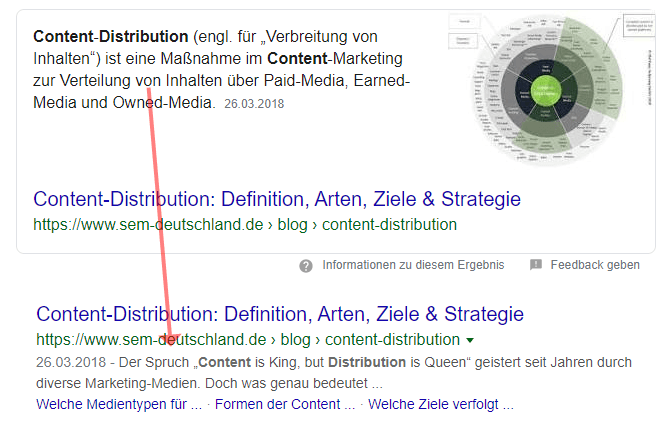
Beispiel für ein Featured Snippet aus dem ersten Suchergebnis
Spannend an diesem Patent ist auch, dass in Bezug auf das Ranking der Dokumenten mit Entitäten-Bezug in keiner Form mehr von Keywords oder Begriffen, sondern nur noch von einem Entitäten-Dokumenten-Bezug gesprochen wird. Desweiteren werden individuell pro Suchanfrage folgende mögliche Bewertungskriterien genannt ohne genauer darauf einzugehen:
- Quality Score
- Relevance Score
- Freshness Score
- …
[T]he system may retrieve entity references associated with the top ten search results. … the ranking and/or selecting is based on a quality score, a freshness score, a relevance score, on any other suitable information, or any combination thereof.
Neben diesen Scoring-Methoden werden auch die Termhäufigkeit ohne und mit Bezug zur Textlänge als Rankingsignale genannt, was dem TF-IDF-Prinzip hingegen wieder sehr nah kommen würde.
Desweiteren wird ein Topicality Score genannt, der sich z.B. aus Freshness, Alter des Dokuments, Anzahl der ausgehenden und eingehenden Links, die Häufigkeit des Vorkommens des Dokuments bei anderen anderen Suchanfragen, die Nähe der Suchanfragen zum Dokument (siehe Vektorraumanalyse ) genannt.
Einfluss auf dem Topicality Score kann auch die Art/Kontext des Contents (z.B. News-Seite oder geschichliche Dokumentation) haben.
In some implementations, a topicality score depends on a relationship between the entity reference and the content within which the entity reference appears. For example, the entity reference [George Washington] may have a higher topicality score on a history webpage than on a current news webpage. In another example, the entity reference [Barak Obama] may have a higher topicality score on a politics website than on a law school website.
Aus den 5-10 ersten Suchergebnissen können dann je nach Häufigkeit der Nennungen die für die Antwort wahrscheinlichste Entität identifiziert werden.
Zusammengefasst sieht der Prozess dann so aus:
- Ranking der relevantesten Dokumente für eine Suchanfrage/Entität.
- Identifikation der nachgefragten Entität aus den 5-10 relevantesten Dokumenten.
- Extrahierung der Antwort für das Featured Snippet bzw. die Knowledge Card.

Neben der Abfrage der relevantesten Dokumente aus dem Index kann ein paralleler Entitätenindex wie z.B. der Knowledge Graph für referenzierende Informationen zu denen im Dokument aufgeführten Entitäten herangezogen werden um eine Suchanfrage zu beantworten. Durch das Auslagern des Entitätenindex können die Abfragen auf den normalen Index und dem Entitätenindex parallel ausgeführt werden, was der Geschwindigkeit zu gute kommt.
Selecting content using entity properties
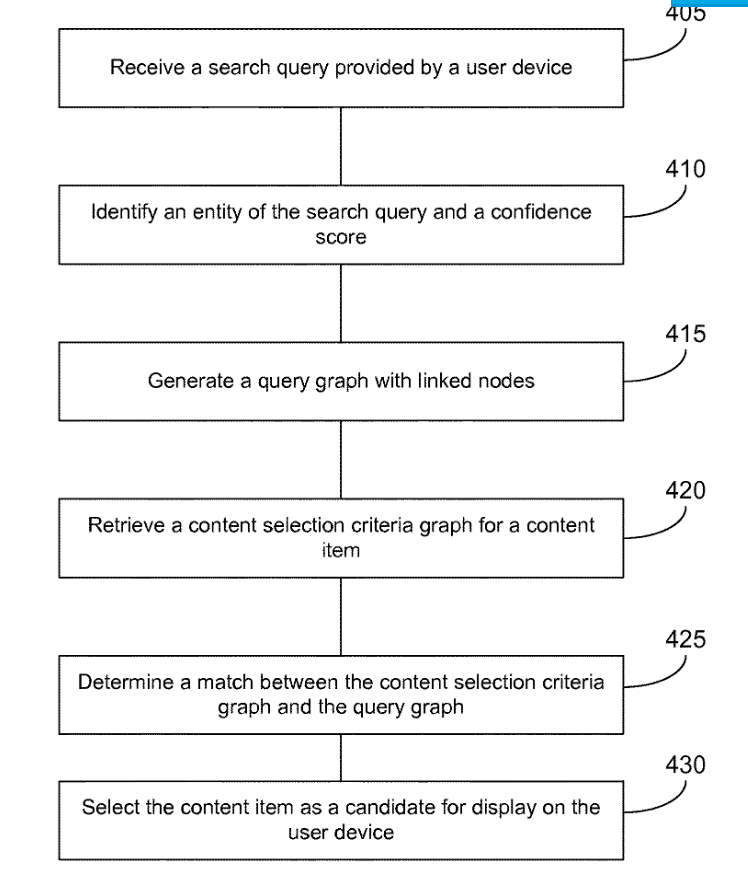 Dieses Google-Patent wurde 2014 und 2017 an Google übertragen. Es beschreibt eine Methode wie Google Dokumente zu einer Suchanfrage mit Entitäten-Bezug ermitteln könnte, um diesen in in den Suchergebnissen anzuzeigen.
Dieses Google-Patent wurde 2014 und 2017 an Google übertragen. Es beschreibt eine Methode wie Google Dokumente zu einer Suchanfrage mit Entitäten-Bezug ermitteln könnte, um diesen in in den Suchergebnissen anzuzeigen.
Spannend ist diese Aussage aus dem Patent, die wieder den Fokus von Keywords und Synonymen hin zu Entitäten und Attributen verschiebt:
The systems and methods can generate or use a form of selection criteria that is based on properties of entities mentioned in queries, rather than based on keywords and synonyms of keywords mentioned in queries.
In dem Patent wird beschrieben wie die in einer Suchanfrage vorkommenden Entitäten mit den Informationen aus einem Knowledge Graph verbunden werden. Diese Informationen werden dann mit einem zweiten Graph basierend auf den für die Suchanfrage relevanten Dokumenten abgeglichen. Dabei spielen die Beziehung unterschiedlicher Entitäten und deren Attribute die zentrale Rolle.
Je näher sich die beiden Graphen sind, desto relevanter wird das Dokument in Bezug auf die Suchanfrage. Diese Nähe wird durch einen Confidence Score abgebildet. Je ähnlicher sich also die Informationen aus dem Knowledge Graph und die Informationen im Dokument sind, desto höher der Confidence Score und desto besser das Ranking.
In some implementations, the system receives a search query input into a search engine via a user device. Using the received user search query, the system generates a replica of a subset of an entity graph corresponding to the entities mentioned in the search query, where the search query is inserted as a node in the replica. The technology then matches this replica entity graph with other entity graphs corresponding to a content provider’s content selection criteria. If the entity graph corresponding to the content provider’s content selection criteria maps onto the search query entity graph or otherwise matches the replica entity graph, then it is a match. The system may then select content items of the content provider corresponding to the matching entity graph.
In some implementations, the method includes the data processing system comparing the content selection criteria graph with the query graph. The method may include comparing the content selection criteria graph with the query graph on a node-by-node basis. In some implementations, the method includes matching a topology of the content selection criteria graph with the query graph. https://patents.google.com/patent/US9542450B1/en
Automatic discovery of new entities using graph reconciliation
Dieses Google-Patent wurde im Oktober 2017 an Google übertragen und wurde 2019 aktualisiert. In diesem Patent werden Methoden zur Erstellung eines Quellen-Daten-Graphen hinsichtlich Entitäten basierend auf einem Dokument beschrieben. In diesem Graphen werden wie im Knowledge Graph die Entitäten, deren Beziehungen udn Attribute basierend aus den Informationen im jeweiligen Dokument erfasst. Dadurch entstehen eine Reihe an Quelle-Daten-Graphen, die nach der jeweiligen Entität, einer Beziehung zu einer Nebenentität (Objekt), Art der Beziehung (Prädikat)oder Typ des Quelldokuments geclustert werden können. Cluster in denen die Dokumente ähnliche oder gleiche Aussagen zu einer Entiät enthalten gelten als vertrauenswürdiger als Cluster in denen es zu Widersprüchen zwischen den Dokumenten kommt. Über diesen Weg lassen sich dann auch neue Entitäten und Attribute für den Knowledge Graph ermitteln.
Spannen finde ich diese Aussage:
In such an implementation, the source documents may be documents associated with domain names and a particular bucket fails to meet the reliability threshold when the bucket includes fact tuples only from one domain and/or a particular bucket fails to meet the reliability threshold when the bucket includes one source data graph.
Über dieses Verfahren ließe sich auch die Glaubwürdigkeit einer Quelle ermitteln. Weicht der Quellen-Daten-Graph eines Dokuments zu weit ab von den Aussagen in anderen Dokumenten könnte Google dieses Dokument als auch die Quelle ausschließen.
Damit ließen sich Teile des Prozess auch für eine Bewertung hinsichtlich E-A-T nutzen.
Dieses Patent schließt sich damit nahtlos an das obige Patent „Selecting content using entity properties“und beschreibt einen Teilschritt von diesem.
Systems and methods for re-ranking ranked search results
Dieses Google Patent aus dem Jahr 2018 beschäftigt sich mit der Frage wie Original-Inhalte vor möglichen duplizierten Inhalten ranken. Dabei werden Quellen als Entitäten betrachtet. Dokumente von Entitäten, die bekannt dafür sind originale Inhalte zu publizieren werden bevorzugt vor Entitäten geranked, die bekannt dafür sind Inhalte zu duplizieren, auch wenn ein möglicher Relevance Score für dfas Dokument der zweiten Entität höher ist.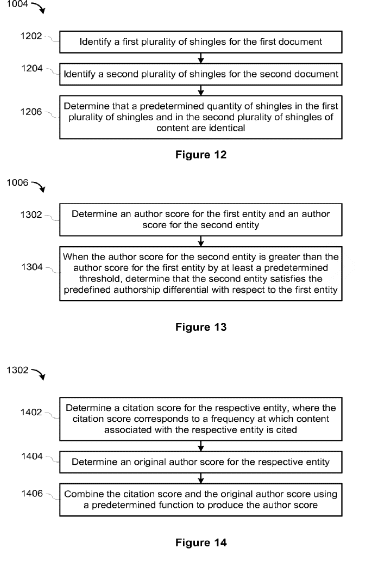
Document ranking based on entity frequency
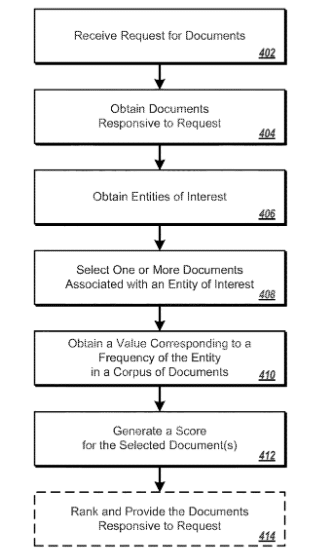 Dieses Patent wurde erstmals 2014 von Google gezeichnet und im Oktober 2017 in aktualisierter Form noch mal. In diesem Patent wird beschrieben wie einem Nutzer aufgrund seines Interesses an bestimmten Themen bzw. Entitäten Dokumente in einer bestimmten Reihenfolge angezeigt werden. Die Dokumente werden anhand der Entitäten-Frequenz gerankt. Auch eine inverse Entitäten-Frequenz analog zur Inverse Document Frequency (IDF) kann eine Rolle spielen. Den Dokumenten werden über Kommentare Themen und Entitäten zugeordnet. Da das Patent in erster Linie für Google News und Google Discover interessant ist möchte ich an dieser Stelle nicht genauer darauf eingehe.
Dieses Patent wurde erstmals 2014 von Google gezeichnet und im Oktober 2017 in aktualisierter Form noch mal. In diesem Patent wird beschrieben wie einem Nutzer aufgrund seines Interesses an bestimmten Themen bzw. Entitäten Dokumente in einer bestimmten Reihenfolge angezeigt werden. Die Dokumente werden anhand der Entitäten-Frequenz gerankt. Auch eine inverse Entitäten-Frequenz analog zur Inverse Document Frequency (IDF) kann eine Rolle spielen. Den Dokumenten werden über Kommentare Themen und Entitäten zugeordnet. Da das Patent in erster Linie für Google News und Google Discover interessant ist möchte ich an dieser Stelle nicht genauer darauf eingehe.
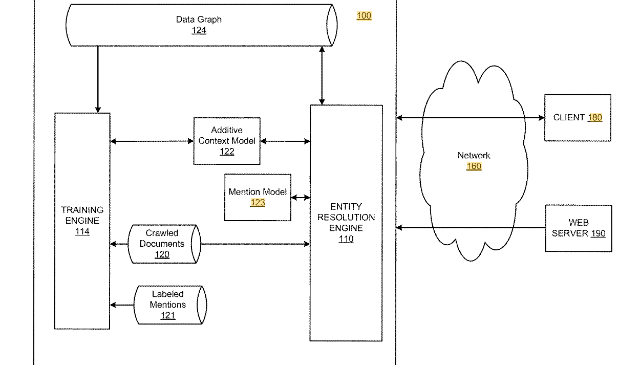
Additive context model for entity resolution
Dieses Patent wurde erstmals 2014 von Google gezeichnet und im Oktober 2017 in aktualisierter Form noch mal. In diesem Patent wird beschrieben, wie man über ein Disambiguierungs-System Entitäten in einem Text erkennt. Dieses System basiert auf einem Knowledge Graph, einer Entity Resolution Engine und einer Trainings-Engine was über semi-supervised Machine Learning dazulernt. Die Resolution-Engine setzt sich aus einem Mention-Model und einem Kontext-Model zusammen.
Über diese Methode lassen sich zum einem Dokumente identifzieren, die in einer Beziehung zu einer oder mehreren Entitäten stehen, zudem lassen sich neue Beziehungen (Kanten) zwischen Entitäten im Knowledge Graph aus diesen Dokumenten ermitteln. Zudem lässt sich ein Ranking dieser Dokumente verfeinern. Die Dokumente können mit einem Mark-Up versehen werden, um sie in Beziehung zu Entitäten im Knowledge Graph zu setzen.
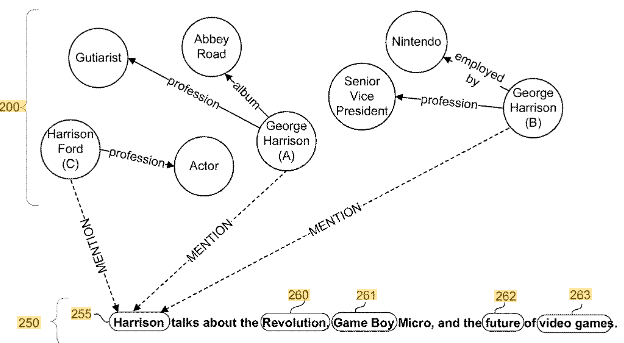
Über ein Mention Model lassen sich Dokumente identifizieren in denen es um George Harrison geht. Der Name George Harrison hat mindestens zwei Entitäten. Den Musiker und den Vize Präsidenten von Nintendo. in solchen Fällen bedarf es eines zusätzlichen Kontext-Modells, über das die Dokumente nach den beiden Entitäten segmentiert werden können. Dies geschieht über die Entitäten, Entitätstypen oder weitere Begriffe, die im Text bzw. dem Umfeld der Entitäts-Nennungen im Text vorkommen.
Über die Trainings Engine kann das System über die bereits im Knowledge Graph erfassten Informationen neue Attribute bzw. Features selbstständig entdecken bzw. Attribute erkennen, die nichts mit der Entität zu tun haben und sogar ganz neue Entitäten mit zugehörigen Kontext-Mustern erstellen.
Document ranking based on semantic distance between terms in a document
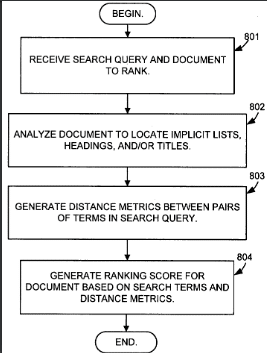 Dieses Patent wurde erstmals 2004 von Google gezeichnet und im Oktober 2017 in aktualisierter Form noch mal. Aufgrund des Alters des Patents und dass es immer noch von Google gezeichnet ist kann man davon ausgehen, dass es auch irgendwie in Anwendung ist. Das Patent beschreibt wie die Nähe von Begriffen in einem Text aufgrund einer vorliegenden semantischen Struktur ermittelt werden kann. Zudem beschreibt es eine Methode, die Dokumente basierend auf einen Distance Value oder zu deutsch Entfernungs-Wert hinsichtlich einer Suchanfrage zu ranken.
Dieses Patent wurde erstmals 2004 von Google gezeichnet und im Oktober 2017 in aktualisierter Form noch mal. Aufgrund des Alters des Patents und dass es immer noch von Google gezeichnet ist kann man davon ausgehen, dass es auch irgendwie in Anwendung ist. Das Patent beschreibt wie die Nähe von Begriffen in einem Text aufgrund einer vorliegenden semantischen Struktur ermittelt werden kann. Zudem beschreibt es eine Methode, die Dokumente basierend auf einen Distance Value oder zu deutsch Entfernungs-Wert hinsichtlich einer Suchanfrage zu ranken.
Die Entfernung kann basierend darauf gemessen werden, wie nahe Begriffe semantisch und nicht visuell beieinander liegen. Mit anderen Worten, selbst wenn Begriffe in dem gerenderten Dokument visuell weit voneinander entfernt sind, kann die gemessene Entfernung dennoch anzeigen, dass die Wörter relativ nahe beieinander liegen, wenn die semantische Struktur des Dokuments anzeigt, dass die Wörter semantisch nahe beieinander liegen.
Somit müsste ein Begriff nicht zwangsläufig in unmittelbarer Nähe zu der in der Überschrift genannten Entität genannt werden, damit er eine semantische Nähe zu ihr vorweist. Sprich die Größe des betrachteten Fensters rund um die Entität wäre flexibel auf den Satz, Absatz oder auch das Kapitel oder sogar den gesamten Text anwendbar. Viel entscheidender sind semantische Strukturen wie z.B. html-Auszeichnungen für Listen, Tabellen, Absätze , Zeilenumbrüche, Überschriften oder Formatierungen wie bold oder underlined. Desweiteren Auszeichnungen von ganzen Teilbereichen wie Footer, Sidebar, Empfehlungen, Banner oder Main Content.
Ein Page Analyzer parst die Website gemäß der semantischen Struktur in eine hierarchische Darstellung aus Titel, h1, h2, h3 … und stellt die semantische Nähe von Begriffen in den unterschiedlichen Abschnitten her. Über ein Ranking-Modul (aktuell Hummingbird) wird die Nähe der in der Suchanfrage vorkommenden Termen mit den Ergebnissen aus dem Page Analyzer abgeglichen und das Dokument mit einem Ranking-Score bezogen auf die Suchanfrage versehen.
Mapping images to search queries
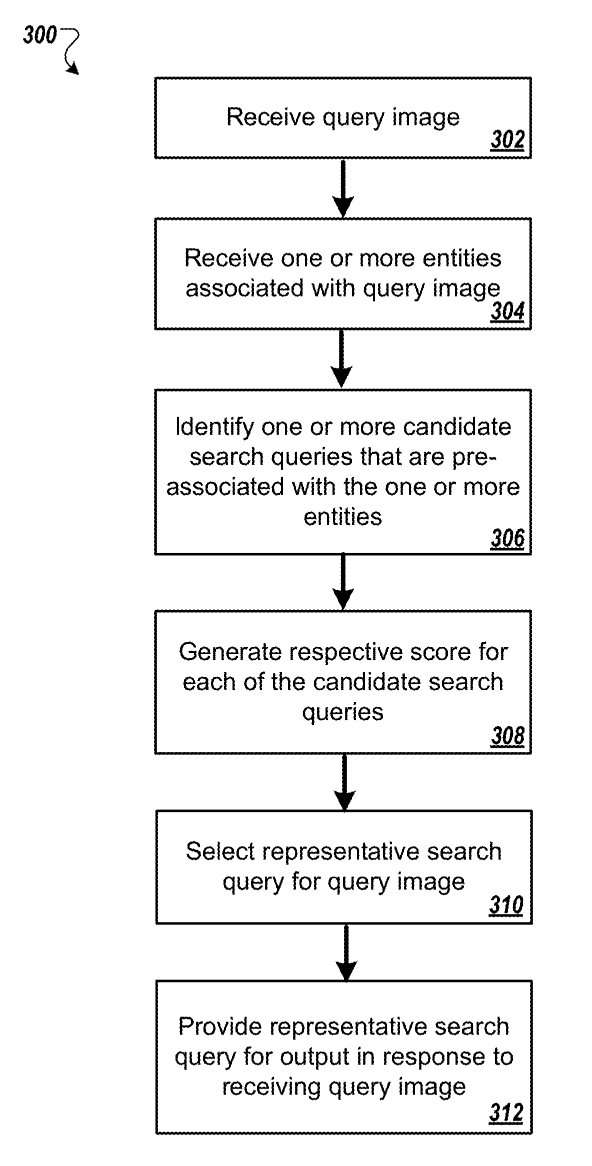 Ein weiteres Patent, das Gooogle 2016 gezeichnet und 2019 publiziert. Es beschreibt den Prozess wie Suchanfragen in Form von Bildern Entitäten zugeordnet werden und mit Informationen sowie Fragestellungen bzw. Suchanfragen angereichert werden, um entsprechende Suchergebnisse auszuliefern. Die Suchergebnisse können aus einem Knowledge Panel, klassischen Suchergebnissen, Bildern und Nutzerfragen zusammengestellt sein.
Ein weiteres Patent, das Gooogle 2016 gezeichnet und 2019 publiziert. Es beschreibt den Prozess wie Suchanfragen in Form von Bildern Entitäten zugeordnet werden und mit Informationen sowie Fragestellungen bzw. Suchanfragen angereichert werden, um entsprechende Suchergebnisse auszuliefern. Die Suchergebnisse können aus einem Knowledge Panel, klassischen Suchergebnissen, Bildern und Nutzerfragen zusammengestellt sein.
Die Bild-basierte Suchanfrage wird über einen Image-Annotator mit Labels versehen, die mit Confidence- und Relevance-Scores versehen werden, um die Relevanz und Richtigkeit des Labels für das Bild zu verifizieren. Über eine Recognition Engine werden dem Bild mögliche Entitäten zugeordnet. Die engere Auswahl kann über die Labels geschehen, die einen bestimmten Entitäts-Typ oder Entitäten-Domain repräsentieren. Über eine Knowledge Engine lassen sich dann Suchterme bezüglich der Entität oder den Entitäten ermitteln. Darauf basierend können dann Suchergebnisse ausgeliefert werden. Über die beschriebene Methode lässt sich aufgrund des gemachten Bildes der individuelle Kontext und damit die Nutzerintention bzw. Suchintention ermitteln und dementsprechende Suchergebnisse ausliefern.
Die eigentliche Suchanfrage kann neben dem Bild auch gesprochenen oder geschriebenen Text enthalten.
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























3 Kommentare