
Dies ist der vierte Teil einer Beitragsreihe zum Thema semantische SEO und behandelt die Frage, ob Google wirklich die Bedeutung von Dokumenten und Suchanfragen versteht oder es doch nur statistische Analysen deutet.
Inhaltsverzeichnis
- 1 Semantisches Verständnis als Ziel von Google
- 2 Googles Weg zur semantischen Suche
- 3 Der Knowledge Graph als semantische Datenbank
- 4 Google heute – semantische Suche oder doch nur statistisches Information Retrieval?
- 5 Machine Learning bzw. Deep Learning für Skalierbarkeit
- 6 Fazit: Google ist auf dem Weg zum semantischen Verständnis
Semantisches Verständnis als Ziel von Google
Eines der wichtigsten Ziele von Google ist es seit langem, ein semantisches Verständnis hinsichtlich Suchtermen und indexierten Dokumenten zu erlangen, um relevantere Suchergebnisse anzuzeigen. Ein semantisches Verständnis ist gegeben, wenn man z.B. eine gestellte (Suchan-)Frage und die daran enthaltenen Terme eindeutig verstehen bzw. deren Bedeutung eindeutig erkennen kann. Die eindeutige Interpretation ist oft durch Mehrdeutigkeit von Begriffen, bisher unbekannte Begrifflichkeiten, unklare Formulierungen, individuelles Verständnis etc. erschwert.
Zum besseren Verständnis können die verwendeten Wörter, deren Reihenfolge oder der thematische, zeitliche bzw. geografische Kontext beitragen. Durch Machine Learning wie es z.B. bei Rankbrain zum Einsatz kommt ist Google nun in der Lage Begriffe und Entitäten in Suchanfragen und Dokumenten schnell zu erkennen und über Clusteranalysen automatisch neue Klassen von Entitätstypen zu erstellen. Auch die Schaffung neuer Vektorräume für Vektorraumanalysen ist besser möglich. Dazu in weiteren Beiträgen dieser Reihe aber mehr.
Dadurch ist ein hoher Detailgrad als auch Skalierbarkeit und Performance gewährleistet.
So führen Statistik in Kombination mit Machine Learning immer mehr zu einer semantischen Interpretation, die einem semantischen Verständnis bezogen auf Suchanfragen und Dokumenten sehr nahe kommt. Google möchte eine semantische Suche mit Hilfe von statistischen Methoden und Machine Learning „nachbauen“.
Zudem baut ein zentrales Element der heutigen Google-Suchmaschine, der Knowledge Graph, auf semantischen Strukturen auf.
Googles Weg zur semantischen Suche
Google setzt bei der semantischen Suche auf den Knowledge Graph und das 2013 eingeführte Hummingbird-Update, das die semantische Suche eingeläutet hat. Doch das Interesse von Google an der Entwicklung einer semantischen Suchmaschine reicht über 10 Jahre zurück. Bereits im Jahr 2007 äußerte sich die damalige Verantwortliche für die Suche und User Experience Marissa Mayer in einem Interview mit IDG News Service wie folgt:
„Right now, Google is really good with keywords and that’s a limitation we think the search engine should be able to overcome with time. People should be able to ask questions and we should understand their meaning, or they should be able to talk about things at a conceptual level. We see a lot of concept-based questions — not about what words will appear on the page but more like ‚what is this about?‘. A lot of people will turn to things like the semantic Web as a possible answer to that.“ Quelle: http://www.infoworld.com/article/2642023/database/google-wants-your-phonemes.html
Im selben Interview machte Marissa Mayer aber auch klar, dass Semantik alleine nicht die Grundlage für die „perfekte Suchmaschine“ ist.
„That said, I think the best algorithm for search is a mix of both brute-force computation and sheer comprehensiveness and also the qualitative human component.”
Doch der Fokus auf Semantik ist bei Google schon weit vor 2007 zu erkennen. Ein Blick in die Patent-Suche von Google lässt dieses vermuten. So hat Google schon seit dem Jahr 2000 einige Patente mit Blick auf semantische Analysen von Suchanfragen und Dokumenten gezeichnet wie z.B. Identification of semantic units from within a search query (2000) oder Document ranking based on semantic distance between terms in a document (2004).
Es ist davon auszugehen, dass Google sich schon seit der Gründung im Jahr 1998 mit der Entwicklung einer Suchmaschine mit Einflüssen aus der Semantik auseinandersetzt.
Die erste offizielle Bekanntgabe seitens Google hinsichtlich dem Einsatz von semantik-ähnlicher Technologien war 2009. Eine komplett semantische Suche war durch die fehlende Skalierbarkeit nicht möglich. Unter einer semantischen Analyse von Dokumenten würde die Usability bzw. Geschwindigkeit der Anwendung leiden. Die Ausgabe von Suchergebnisse in Echtzeit wäre nicht möglich gewesen.
Der Knowledge Graph als semantische Datenbank
2010 kaufte Google die Wissens-Datenbank Freebase, die es erlaubte Informationen zu Entitäten strukturiert zu hinterlegen. Ich bezeichne Freebase auch gerne als Spielplatz, über den Google die ersten Erfahrungen mit strukturierten Daten machen konnte. Zeitgleich entwickelte Google mit dem Knowledge Graph eine eigene semantische Datenbank.
Im Jahr 2012 führte Google dann den Knowledge Graph ein, der anfangs u.a. durch die in Freebase gesammelten Daten gespeist wurde. Das offene Projekt Freebase wurde 2014 beendet und in das geschlossene Projekt Wikidata überführt, das heute eine wichtige Informationsquelle für den Knowledge Graph ist.
Neben Wikidata bezieht Google laut eigenen Angaben auch Daten aus Wikipedia, dem CIA World Factbook, dem Crawling und Natural Language Processing von Dokumenten, Google My Business und lizensierten Daten. Dazu aber mehr in einem anderen Beitrag im Detail.
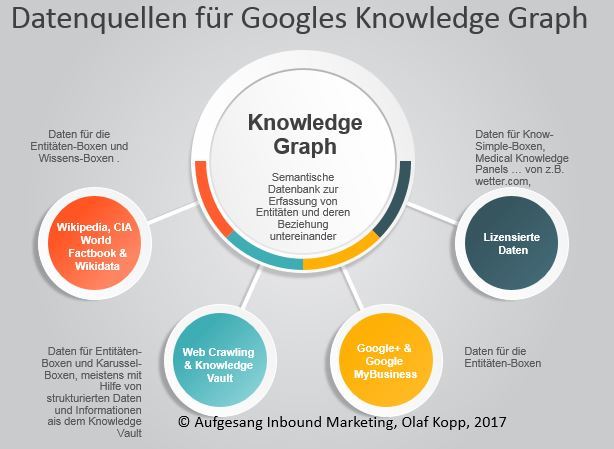
Datenquellen für den Knowledge Graph
Mehr zum Google Knowledge Graph:
Was ist der Knowledge Graph? Definition & Funkionsweise
Google heute – semantische Suche oder doch nur statistisches Information Retrieval?
Darüber, ob Google heutzutage wirklich eine semantische Suchmaschine ist oder nicht lässt sich trefflich streiten.
So, wie Google für den Nutzer heutzutage Ergebnisse ausgibt, macht es den Anschein, als ob Google schon ein semantisches Verständnis in punkto Suchanfragen und Dokumenten besitzt. Der Weg dorthin beruht in großen Teilen auf statistischen Verfahren. Nicht auf echtem semantischen Verständnis – aber aufgrund semantischer Strukturen im Zusammenspiel mit Statistik und Machine Learning kommt Google einem semantischen Verständnis nahe.
“For instance, we find that useful semantic relationships can be automatically learned from the statistics of search queries and the corresponding results or from the accumulated evidence of Web-based text patterns and formatted tables, in both cases without needing any manually annotated data.” Quelle: The Unreasonable Effectiveness of Data, IEEE Computer Society, 2009
Das Hauptproblem in der Vergangenheit war die fehlende Skalierbarkeit u.a. bei der manuellen Klassifizierung von Suchanfragen. Dazu Ex-Google VP Marissa Mayer in einem Interview aus dem Jahr 2009:
“When people talk about semantic search and the semantic Web, they usually mean something that is very manual, with maps of various associations between words and things like that. We think you can get to a much better level of understanding through pattern-matching data, building large-scale systems. That’s how the brain works. That’s why you have all these fuzzy connections, because the brain is constantly processing lots and lots of data all the time… The problem is that language changes. Web pages change. How people express themselves changes. And all those things matter in terms of how well semantic search applies. That’s why it’s better to have an approach that’s based on machine learning and that changes, iterates and responds to the data. That’s a more robust approach. That’s not to say that semantic search has no part in search. It’s just that for us, we really prefer to focus on things that can scale. If we could come up with a semantic search solution that could scale, we would be very excited about that. For now, what we’re seeing is that a lot of our methods approximate the intelligence of semantic search but do it through other means.”
Vieles von dem, was wir als semantisches Verständnis bei der Identifikation der Bedeutung einer Suchanfrage oder eines Dokuments bei Google wahrnehmen, obliegt statistischen Methoden wie z.B. Vektorraum-Analysen bzw. textstatistischen Methoden wie z.B. TF-IDF und Natural Language Processing und basiert damit nicht auf echter Semantik. Aber die Ergebnisse kommen einem semantischen Verständnis sehr nah. Gerade der vermehrte Einsatz von Machine Learning z.B. bei der Entitäten-Analyse über Natural Language Processing erleichtert durch noch detailliertere Analysen die semantische Interpretation von Suchanfragen und Dokumenten ungemein.
Machine Learning bzw. Deep Learning für Skalierbarkeit
Für semantische Systeme müssen Klassen und Labels vordefiniert sein, um Daten zu klassifizieren. Zudem ist es schwierig, ohne manuelle Hilfe neue Entitäten zu identifizieren und anzulegen. Dies war lange nur manuell bzw. in Referenz zu manuell gepflegten Datenbanken wie z.B. Wikipedia oder Wikidata möglich, was die Skalierbarkeit behindert.
Der Schritt zu einer performanten semantischen Suchmaschine führt zwangsläufig über Machine Learning bzw. neuronale Netze.
Googles Engagement in Sachen Artificial Intelligence und Machine-Learning begann im Jahr 2011 noch vor der Veröffentlichung von Hummingbird und dem Knowledge Graph mit dem Projektstart von „Google Brain“.
Ziel von Google Brain ist es eigene Neural Networks zu schaffen. Seitdem arbeitet Google mit einer selbst entwickelten Deep-Learning-Software DistBelief und dem Nachfolger namens Tensor Flow und der Google Cloud Machine Learning Engine am Ausbau der eigenen Infrastruktur für Machine- und Deep Learning.
Laut eigenen Angaben hat Google seit 2014 seine Aktivitäten in Sachen Deep Learning knapp vervierfacht, wie man aus der Folie des weiter unten aufgeführten Vortrag von Jeff Dean entnehmen kann.
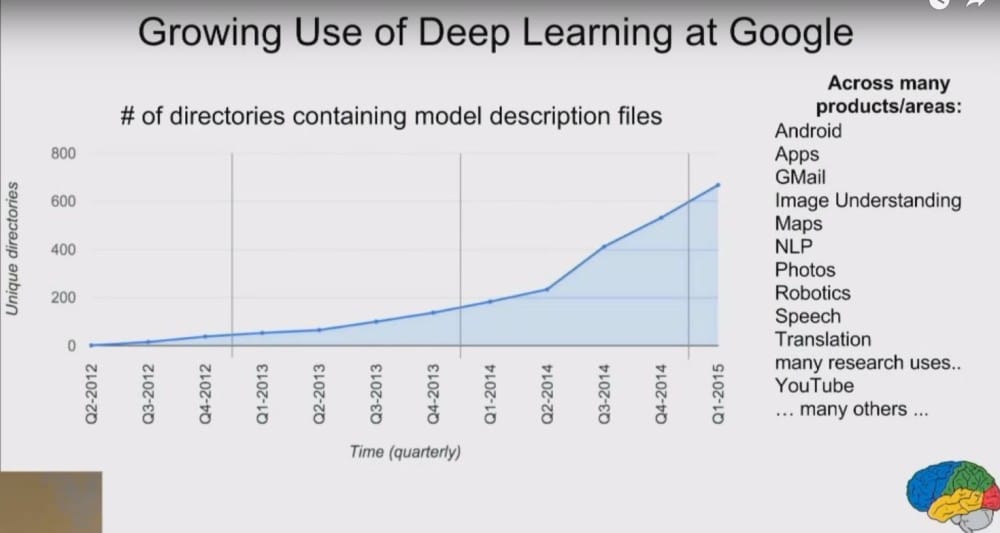
Quelle: Präsentation Jeff Dean / Google
Bisher wird Machine- bzw. Deep-Learning mit hoher Wahrscheinlichkeit bzw. laut Googles eigener Aussage bereits für folgende Fälle eingesetzt:
- Kategoriesierung bzw. Identifizierung von Suchanfragen nach Suchintention (Infomational, Transactional, Navigational …)
- Kategorisierung von Inhalten/Dokumenten nach Zweck (Information, Verkauf, Navigation …)
- Erkennung, Kategorisierung von Entitäten im Knowledge Graph
- Textanalyse via Natural Language Processing
- Erkennung, Kategorisierung und Interpretation von Bildern
- Erkennung, Kategorisierung und Interpretation von Sprache
- Erkennung, Kategorisierung und Interpretation von Videos
- Übersetzung von Sprachen
Das wirklich Neue ist dabei, dass Google diese Kategorisierung nun immer besser, da stetig dazu lernend und vor allem automatisiert durchführen kann.
Die digitalen Gatekeeper wie Google benötigen immer zuverlässigere Algorithmen, um diese Aufgaben autonom zu bewerkstelligen. Hier werden selbstlernende Algorithmen basierend auf Artificial Intelligence und Methoden des Machine Learnings eine immer wichtigere Rolle spielen. Nur so kann die Relevanz von Ergebnissen bzw. erwartungskonforme Ausgaben / Ergebnisse gewährleistet werden – und gleichzeitig Skalierbarkeit gegeben bleiben.
Gerade mit Blick auf das semantische Verständnis von Suchanfragen und Dokumenten ist Machine Learning für die Performance zwingend notwendig.
Bon daher kommt es nicht von ungefähr, dass die drei wichtigsten Einführungen der Google-Suche Knowledge-Graph, Hummingbird, Rankbrain sowie Googles deutlich intensiviertes Engagement hinsichtliche Machine Learning in einem Zeitraum von drei Jahren zeitlich sehr nah beieinander liegen.
Mehr zu Thema Machine Learning:
- Was ist Machine-Learning? Definition, Unterschied zu Artificial Intelligence, Funktionsweise …
- Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google
Fazit: Google ist auf dem Weg zum semantischen Verständnis
Durch Meilensteine wie dem Knowledge Graph, Hummingbird und Rankbrain ist Google den Schritt zu einer perfekten Suchmaschine einen gehörigen Schritt näher gekommen. Dabei spielen Statistik, semantische Theorien sowie Grundstrukturen als auch Machine Learning eine sehr wichtige Rolle.
Google wollte mit dem Knowledge Graph und dem Hummingbird Algorithmus die semantische Suche einführen. Heute wird aber klar, dass das Ziel, ein semantisches Verständnis zu entwickeln, lange an der fehlenden Skalierbarkeit gescheitert ist.
Erst im Zusammenspiel mit Machine-Learning-Systemen wird die semantische Klassifizierung von Informationen, Dokumenten und Suchanfragen in der breiten Masse an Suchanfragen und Dokumenten praxistauglich, ohne große Abstriche in der Performance machen zu müssen – auch Dank tatkräftiger Mithilfe der SEOs und Webmaster, die Informationen selbst manuell auszeichnen.
Auch die Fähigkeit, Voraussagen zu treffen, was ein Nutzer möchte, wenn er einen bisher unbekannten Suchbegriff in den Suchschlitz eingibt, ist erst durch Machine Learning möglich geworden.
Der Weg zur perfekten Suchmaschine ist wohl noch etwas zu gehen, aber die Schritte dahin werden seit 2013 deutlich größer. Aufgrund der Fortschritte, die Google in den letzten Jahren beim Deep-Learning gemacht hat ist davon auszugehen, dass das semantische Verständnis in der Zukunft sich exponentiell verbessern wird.
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























5 Kommentare
Ich denke in der Zukunft wird Google noch besser Inhalte von Webseiten erkennen. Ich glaube auch gutes Design sollte Google einschätzen können.
Sehr spannender und informativer Artikel. Da habe ich direkt ein paar gute Ideen bekommen, die ich auch sofort umsetzen kann.
In hart umkämpften Keywords scheint Google echt gut zu sein. Keine Frage. Da lernen sie viel und schnell, weil viele Leute etwas suchen und dann checken sie, welche Inhalte gut sind.
Aber alles, was über den Normalbereich hinausgeht, da ist die Maschine so dumm, das gibts fast nicht.
Neullich habe ich nach der Bilanz einer Firma im Bundesanzeiger gesucht. Die Treffer waren so schlecht wie in den 90-er Jahren.
Oder den Ex-Dividende-Tag einer Aktie zu finden, der pure Horror. Da verzweifle ich teilweise schon sehr beim Suchen.
Ja, es ist ein interessantes Thema und vermutlich wurden schon manche Fortschritte erzielt. Aber allein wenn ich an Google AdWords – oder jetzt „Google Ads“ denke, bei dem man sehr viel Geld versenken kann, dann ist zumindest mir klar, dass es nicht weit her ist mit Googles KI.
Solange man bei der Anzeigen-Schalten nicht einfach in einem Satz angeben kann, was man verkauft und die Sache dann auch läuft – Konkurrenten ausschließt und Suchende tatsächlich erreicht – steckt die Sache noch in den Kinderschuhen und ist … überbewertet.
Bei Google Ads ist Googles primäres Interesse Klicks zu verkaufen. Sprich die Qualität ist eher zweitrangig. Das ist bei der Auslieferung der Suchergebnisse deutlich anders. Dort muss die Qualität stimmen. Was Google da im Ads Bereich schon seit Jahren macht ist mehr als fragwürdig. Es war mal ein so schön optimierbares System. jetzt wird es immer mehr zur Blackbox. Dazu hatte ich vor längerer Zeit schon was geschrieben: https://www.sem-deutschland.de/blog/adwords-alternativen-google-zwingt-unternehmen-zur-ppc-diversitaet/