
Dieser Beitrag meiner Artikelreihe zu Semantik und Entitäten in der SEO und bei Google beschäftigt sich mit der Rolle von Entitäten bei der Interpretation von Suchanfragen. Dabei werde ich auf einige Google Patente der letzten Jahre eingehen und daraus Ableitungen für das Search Query Processing treffen.
Viel Spass beim Lesen!
Inhaltsverzeichnis
- 1 Methodik beim Search Query Processing
- 2 Google will die Bedeutung und Suchintention der Suchanfragen erkennen
- 3 Einordnung des Suchterms in eine thematische Ontologie
- 4 Rankbrain ist ein Entitäten-basierter Search Query Processor
- 5 Identifikation von Entitäten in Suchanfragen (Named Entity Recognition)
- 6 Semantische Anreicherung von Suchanfragen
- 7 Verfeinerung von Suchanfragen
- 8 Weitere spannende Google Patente rund um das Search Query Processing
- 8.1 Discovering entity actions for an entity graph
- 8.2 Identifying and ranking attributes of entities
- 8.3 Learning from User Interactions in Personal Search via Attribute Parameterization
- 8.4 Evaluating semantic interpretations of a search query
- 8.5 Query Suggestions based on entity collections of one or more past queries
- 8.6 Weitere Google-Patente für die Entitäten-basierte Interpretation von Suchanfragen
- 9 Das Zusammenspiel aus Rankbrain, BERT, MUM und Knowledge Graph
Methodik beim Search Query Processing
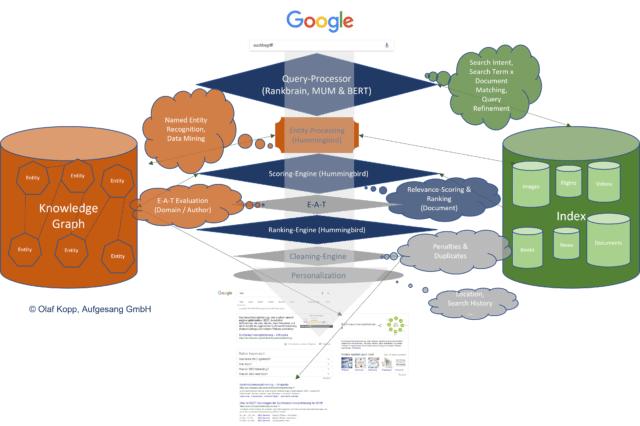
Bei semantischen Information-Retrieval-Systemen spielen Entitäten eine zentrale Rolle bei mehreren Aufgaben.
- Verstehen der Suchanfrage (Search Query Processing)
- Relevanzbestimmung auf Dokumentenebene (Scoring)
- Evaluation auf Domainebene bzw. Autoren-Ebene (E-A-T)
- Zusammenstellung der Suchergebnisse und SERP Features
Bei all diesen Aufgaben ist das Zusammenspiel aus benannten Entitäten und der Zusammensetzung der einzelnen Terme einer Suchanfrage hinsichtlich Relevanz-Bestimmung eines Inhalts der Kern im Search Query Processing.
Die Magie bei der Interpretation von Suchtermen geschieht beim Search Query Processing. Hier sind folgende Schritte wichtig:
- Identifikation der thematischen Ontologie, in der sich die Suchanfrage bewegt. Ist der thematische Kontext klar kann Google einen Inhalts-Korpus aus Text-Dokumenten, Videos, Bildern … als potentiell passende Suchergebnisse auswählen. Das ist insbesondere bei mehrdeutigen Suchtermen schwierig. Mehr dazu in meinem Beitrag KNOWLEDGE PANELS & SERPS FOR AMBIGUOUS SEARCH QUERIES.
- Identifikation von Entitäten und deren Bedeutung im Suchterm (Named entity recognition)
- Semantische Annotation der Suchanfrage
- Verfeinerung des Suchterms
- Verstehen der semantischen Bedeutung einer Suchanfrage.
- Identifikation der Suchintention
Ich habe hier bewusst zwischen 2. und 3- unterschieden, da die Suchabsicht erstens je nach Nutzer variieren und sich sogar mit der Zeit verändern kann, die semantische Bedeutung bleibt hingegen gleich.
Für bestimmte Suchanfragen wie z.B. offensichtliche Fehlschreibweisen findet automatisch im Hintergrund ein Query Refinement statt. Man kann als Nutzer die Verfeinerung der Suchanfrage aber auch manuell anstoßen, insofern Google nicht sicher ist, ob es sich um einen Tippfehler handelt. Beim Query Refinement wird eine Suchanfrage im Hintergrund umgeschrieben, um die Bedeutung besser interpretieren zu können.
Information Retrieval in der semantischen Suche
Google will die Bedeutung und Suchintention der Suchanfragen erkennen
Die Interpretation von Suchanfragen ist in Zeiten von immer komplexer werdenden Suchanfragen, insbesondere durch Voice Search, eine der größten Herausforderungen für Suchmaschinen. Für den Nutzwert einer Suchmaschine ist entscheidend zu verstehen, was der Nutzer sucht. Das ist gerade bei unklar formulierten Suchanfragen keine leichte Aufgabe. Bei modernen Information-Retrieval-Systemen geht es immer weniger um die Keywords, die ein Suchterm beinhaltet als vielmehr um die Bedeutung der Suchanfrage. Hier spielen Entitäten bei vielen Suchanfragen eine zentrale Rolle.
Nahezu jeder Suchterm basiert auf einer impliziten oder expliziten Fragestellung und einer Suchintention. Die Suchintention ist meistens implizierter Natur und für eine Maschine nicht einfach zu identifizieren. Das Erkennen der Suchintention ist sehr wichtig für den Abgleich mit dem Zweck von Dokumenten bzw. Inhalten des jeweiligen thematischen Korpus. In Zeiten von Voice Search und mobilen Endgeräten ist es für Google umso wichtiger, Suchanfragen und deren Nutzerintention bzw. deren Bedeutung so genau wie möglich zu identifizieren, um die individuell passenden Suchergebnisse auszugeben.
Zur Suchintention möchte ich hier aber nicht genauer eingehen. In diesem Beitrag möchte ich mich auf die Interpretation der Bedeutung von Suchanfragen mittels Entitäten konzentrieren. Mehr dazu findest Du im Beitrag Suchintention & Search Intent erklärt: Defintion, Arten, Micro Intents.
In einem Interview von 2009 sagte Ori Allon, damaliger technischer Leiter des Google Search Quality Teams in einem Interview mit IDG :
We’re working really hard at search quality to have a better understanding of the context of the query, of what is the query. The query isn’t the sum of all the terms. The query has a meaning behind it. For simple queries like ‚Britney Spears‘ and ‚Barack Obama‘ it’s pretty easy for us to rank the pages. But when the query is ‚What medication should I take after my eye surgery?‘, that’s much harder. We need to understand the meaning…
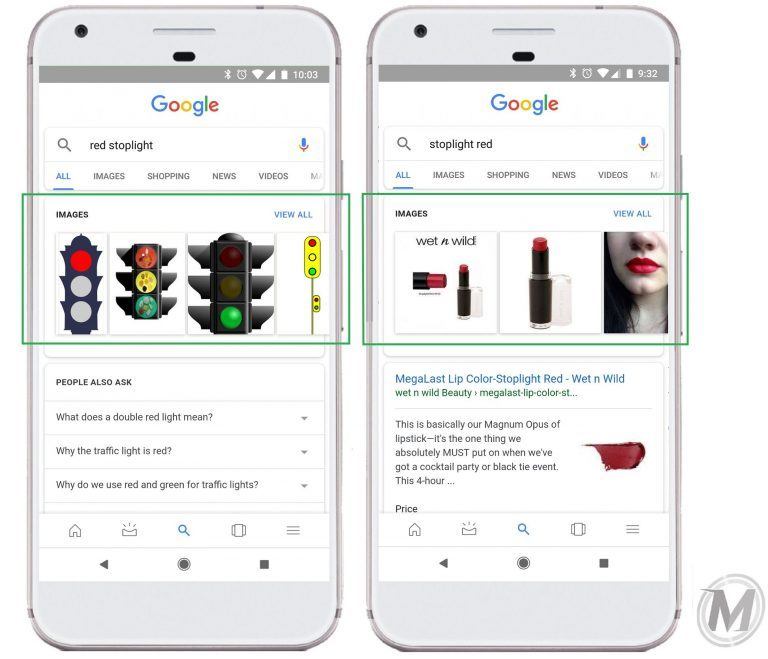
Ein Beispiel für die Effektivität von Entitäten-basierten Suchsystemen im Gegensatz zu Term-basierten zeigt dieses Beispiel.
Quelle: https://mobilemoxie.com/blog/the-entity-language-series-translation-and-language-apis-impact-on-query-understanding-entity-understanding-4-of-5/
Eine rein Term-basierte Suchmaschine würde den Unterschied in der Bedeutung der Suchanfragen „red stoplight“ und „stoplight red“ nicht erkennen, da die Terme in der Suchanfrage gleich sind, nur anders angeordnet. Je nach Anordnung ist die Bedeutung aber unterschiedlich. Eine Entitäten-basierte Suchmaschine erkennt den unterschiedlichen Kontext basierend auf der unterschiedlichen Anordnung. „stoplight red“ ist eine eigene Entität während „red stoplight“ eine Kombination aus einem Attribut und einer Entität „stoplight“ ist.
In diesem Beispiel wird klar, dass es nicht genügt über einen Term die Entität zu ermitteln. Auch die Wörter und deren Anordnung im Umfeld spielen eine wichtige Rolle, um die Bedeutung zu identifizieren. Gerade Terme mit je nach Kontext unterschiedlichen Bedeutungen sind eine Herausforderung für Google bzw. Suchmaschinen. Dazu mehr in dem Beitrag Knowledge Panel and SERPs for ambigous search queries.
Einordnung des Suchterms in eine thematische Ontologie
Die Einordnung einer Suchanfrage in einen thematischen Kontext ist der erste Schritt beim Query Processing. Basierend auf dieser Einordnung ist zum Einen die weitere Interpretation der Suchanfrage möglich, zum anderen für die Auswahl eines thematischen Korpus an relevanten Dokumenten. In klassischen nicht semantischen Suchmaschinen findet ein Abgleich zwischen den im Suchtermen verwendeten Keywords mit den einem Cluster aus Themen typischen Begriffen statt, um die thematische Zuordnung der Suchanfrage durchzuführen. Dieser Prozess ist für die meisten Suchmaschinen relativ einfach insofern die Suchanfrage aufgrund der verwendeten Terme einem thematischen Kontext zugeordnet werden können.
In semantischen Suchmaschinen wird versucht die Bedeutung hinter der Suchanfrage besser zu verstehen, um auch bei nicht eindeutigen Suchanfragen eine Einordnung durchführen zu können.
Bei neuen Termen bzw. Suchanfragen ist es schwieriger. Für die thematische Zuordnung von neuen bisher unbekannten Suchanfragen hat Google 2015 Rankbrain eingeführt.
Hier ein Google Patent dazu:
Improving semantic topic clustering for search queries with word co-occurrence and bipartite graph co-clustering
Eine wissenschaftliche Arbeit aus dem Hause Google gibt einige interessante Insights dazu, wie Google heutzutage wahrscheinlich Suchanfragen in verschiedene thematische Bereiche einteilt.
In diesem Dokument werden zwei Methoden vorgestellt, die Google nutzt, um Suchanfragen kontextuell einzuordnen. Beim Word Co-occurrence Clustering spielen sogenannte Lift Scores eine zentrale Rolle:
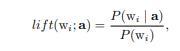
Formel für die Berechnung des Lift Score
„Wi“ steht in der Formel für alle Begriffe in engen Bezug zum Wortstamm stehen wie Fehlschreibweisen, Mehrzahl, Einzahl oder Synonyme.
„a“ kann jegliche Nutzerinteraktion wie die Suche nach einem bestimmten Suchbegriff oder der Besuch einer bestimmten Seite sein.
Wenn der Lift-Score z.B. 5 ist, ist die Wahrscheinlichkeit, dass „Wi“ gesucht wird, 5 mal so hoch als dass „Wi“ generell gesucht wird.
„A large lift score helps us to construct topics around meaningful rather than uninteresting words. In practice the probabilities can be estimated using word frequency in Google search history within a recent time window.“
Über diesen Weg lassen sich dann Begriffe bestimmten Entitäten wie z.B. Mercedes und/oder bei Suchen nach Autoersatzteilen der thematischen Kontextklasse „Auto“ zugeordnet werden. Der Kontextklasse und/oder Entität können dann weiterhin Begriffe zugeordnet werden, die oft als Kookkurrenzen zu den Suchbegriffen vorkommen. So lässt sich auf schnellem Weg eine Begriffswolke zu einem bestimmten Thema aufbauen. Die Höhe des Lift Scores bestimmt die Affinität zum Thema:
„We use lift score to rank the words by importance and then threshold it to obtain a set of words highly associated with the context.“
Diese Methode kann insbesondere dann eingesetzt werden, wenn „Wi“ bereits bekannt ist, wie z.B. bei Suchbegriffen nach bereits bekannten Marken oder Kategorien. Ist „Wi“ nicht klar zu definieren, da die Suchbegriffe des gleichen Themas zu unterschiedlich sind, könnte sich Google einer zweiten Methode bedienen – dem „Weighted bigraph clustering“.
Diese Methode beruht auf zwei Annahmen.
- Nutzer mit der gleichen Absicht formulieren ihre Suchanfragen unterschiedlich. Dennoch werden von Suchmaschinen die gleichen Suchergebnisse ausgegeben.
- Umgekehrt werden zu einer Suchanfrage auf den ersten Suchergebnissen ähnliche URLs ausgegeben.
Bei dieser Methode werden die Suchbegriffe mit den Top-rankenden URLs verglichen und Anfrage / URL-Paare gebildet, deren Beziehung zusätzlich nach den Klickraten der Nutzer und Impressionen gewichtet werden. Über diesen Weg lassen sich Ähnlichkeiten auch zwischen den Suchbegriffen herstellen, die nicht den gleichen Wortstamm besitzen und daraus semantische Cluster bilden.
Rankbrain ist ein Entitäten-basierter Search Query Processor
Als Google im Jahr 2015 die Einführung von Rankbrain für die bessere Interpretation von Suchanfragen bekannt gegeben hat gab es eine Vielzahl von Vermutungen und Meinungen aus der SEO-Branche. Es wurde z.B. von der Geburtsstunde von Machine Learning bzw. KI bei Google gesprochen. Wie in meinem Beitrag Bedeutung von Machine Learning, AI & Rankbrain für SEO & Google erläutert beschäftigt sich Google bereits seit 2011 im Rahmen des Projekts Google Brain intensiv mit Deep Learning. Rankbrain war allerdings die erste offizielle Bestätigung seitens Google, dass Machine Learning auch in der Google Suche eingesetzt wird.
Die wohl präzisesten Informationen von Google zu Rankbrain bisher gab es im Bloomberg Interview aus Oktober 2015.
Eine Aussage in dem Interview sorgte für viele Missverständnisse um Rankbrain.
RankBrain is one of the “hundreds” of signals that go into an algorithm that determines what results appear on a Google search page and where they are ranked. In the few months it has been deployed, RankBrain has become the third-most important signal contributing to the result of a search query.
Viele SEO-Medien haben die Aussage so interpretiert, dass Rankbrain einer der drei wichtigsten Rankingfaktoren ist. Aber ein Signal ist kein Faktor. Rankbrain hat einen großen Einfluss darauf wie die Suchergebnisse ausgewählt und geordnet werden ist aber kein Faktor wie z.B. bestimmte Bestandteile eines Inhalts oder Links.
In diesem Interview gibt es eine weitere interessante Aussage:
RankBrain uses artificial intelligence to embed vast amounts of written language into mathematical entities — called vectors — that the computer can understand. If RankBrain sees a word or phrase it isn’t familiar with, the machine can make a guess as to what words or phrases might have a similar meaning and filter the result accordingly, making it more effective at handling never-before-seen search queries.
Bei Rankbrain werden Entitäten in einer Suchanfrage identifiziert und mit den Fakten aus dem Knowledge Graph abgeglichen. Insofern die Begriffe mehrdeutig sind findet Google über Vektorraumanalysen heraus welche der möglichen Entitäten am besten zum Begriff passen. Dabei sind die umliegenden Wörter im Suchterm ein erstes Indiz für die Ermittlung des Kontext. Das mag auch auch ein Grund sein warum Rankbrain u.a. für Longtail-Suchanfragen zum Einsatz kommt.
Das Problem in der Pre-Rankbrain-Zeit war die fehlende Skalierbarkeit bei der Identifikation und Anlage von Entitäten im Knowledge Graph. Der Knowledge Graph basiert aktuell noch in erster Linie aus Informationen aus Wikidata, die durch Wikipedia-Entitäten verifiziert werden und Wikipedia selbst – also manuell gepflegte und dadurch eher statisches und damit nicht skalierbares System.
“Wikipedia is often used as a benchmark for entity mapping systems . As described in Subsection 3.5 this leads to sufficiently good results, and we argue it would be surprising if further effort in this area would lead to reasonable gains.”
Quelle: From Freebase to Wikidata – The Great Migration
Mehr dazu findest Du in den anderen Teilen der Beitragsreihe:
- Alles was Du zu Entitäts-Typen, -Klassen & Attributen wissen solltest
- Wie verarbeitet Google Informationen aus der Wikipedia für den Knowledge Graph ?
- Wie kann Google aus unstrukturierten Inhalten Entitäten identifizieren und deuten ?
Eine weitere sehr zu empfehlende Quelle für Informationen zur Funktionsweise der Google-Suche aus erster Hand ist der bereits in einem anderen Beitrag erwähnte Vortrag von Paul Haahr auf der SMX West 2016.
Danny Sullivan fragte Jeff in der Q&A, wie RankBrain funktionieren könnte, um die Dokumentqualität oder -autorität festzustellen. Seine Antwort:
This is all a function of the training data that it gets. It sees not just web pages but it sees queries and other signals so it can judge based on stuff like that.
Das spannende an dieser Aussage ist, dass sie implizit ausdrückt, dass Rankbrain erst nach der Auswahl eines ersten Sets an Suchergebnissen eingreift. Das ist eine wichtige Erkenntnis, da RankBrain die Suchanfrage nicht verfeinert, bevor Google nach Ergebnissen sucht, sondern erst danach.
Dann kann RankBrain die Abfrage möglicherweise verfeinern oder anders interpretieren, um die Ergebnisse für diese Abfrage auszuwählen und neu zu ordnen.
Zusammengefasst: RankBrain ist ein Algorithmus basierend auf Deep Learning, der nach der Auswahl eines ersten Subsets an Suchergebnissen zum Einsatz kommt und sich auf Textvektoren und andere Signale stützt, um komplexe Suchanfragen über Natural Language Processing besser zu verstehen.
Nachfolgend möchte ich einige Google Patente vorstellen, die für die Interpretation von Suchanfragen eine Rolle spielen können. Einige der nachfolgenden Patente könnten die grundlegende Technologie auf der Rankbrain mit seinen Maschine-Learning-Technologien aufgesetzt wird sein.
Identification of acronym expansions
Dieses Patent wurde erstmal im August 2011 von Google gezeichnet und im Oktober 2017 noch mal unter einem neuen Namen neu gezeichnet. Es ist sehr spannend, da einer der Erfinder der Deep Learning Spezialist Thomas Strohmann ist, der eine führende Rolle bei der Entwicklung von Rankbrain gespielt hat.
In diesem Patent wird nicht von Entitäten gesprochen aber es beschreibt eine weitere Methode wie Google ursprüngliche Suchanfragen basierend auf den Informationen aus einem ersten Subset von Dokumenten umschreibt bzw. verfeinert, um relevantere Suchergebnisse am Ende auszuspielen. In diesem Patent geht es zwar in erster Linie um die Deutung von Akronymen in Suchanfragen. Der beschriebene Prozess ist aber eine Blaupause für viele andere Methoden, die sich mit der Verfeinerung bzw. Umschreibung von Suchanfragen beschäftigen.
Die im Patent beschriebene Acronym- und Synonym-Engine lässt sich durch den Knowledge Graph ersetzen.
Methods, systems, and media for interpreting queries
In diesem Patent, das Google im Jahr 2015 gezeichnet hat, werden verschiedene Methoden beschrieben wie Suchmaschinen Suchanfragen interpretieren können. Es ist spannend, da es Methoden von Rankbrain mit Natural Language Processing (BERT & MUM) kombiniert.
Dieses Patent beschreibt die grundlegende Problemstellung und Lösungsansätze mit den Herausforderungen umzugehen.
For example, in response to providing the search query “action movie with tom cruise,” these search engines can provide irrelevant search results like “Last Action Hero” and “Tom and Jerry” simply because a portion of the search query is included in the title of the pieces of content. Accordingly, gaining an understanding of the search query can produce more meaningful search results.
Bei der hier beschriebenen Methode werden Suchanfragen in einzelne Teil-Begriffe zerlegt. Für diese Begriffe wird geprüft, ob sie einen Bezug zu einer bekannten Entität haben. Über einen Entiäten-Score wird festgelegt wie nah die Begriffe zu den jeweiligen Entitäten stehen. Dabei spielt auch der Kontext der Suchanfrage, also auch die Begriffe ohne direkten Entitäten-Bezug im Suchterm eine Rolle. Basierend auf der relevantesten Entität wird dann eine Suche entsprechend des Entitätstyp ausgeführt und die dementsprechenden Suchergebnisse ausgeliefert.

Dazu ein Beispiel. Eine Suchanfrage wie „Action Film mit Tom Cruise“ würde in die einzelnen Bestandteile „Action“, „Film“,“Tom“ und „Cruise“ zerlegt werden. Der Begriff Action kann eine Entität des Entitstyps Film, Genre oder Serie sein. Welcher dieser Entitätstypen am ehesten gefragt ist kann z.B. nach der vorkommenden Häufigkeit bzw. Popularität über einen Entitäten-Score bestimmt werden.
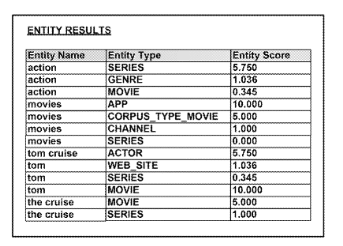
Je nach Art der Suchmaschine (Bilder-Suche, Video-Suche …) würden entsprechende Medienformate passend zu den gesuchten Entitätstyp „Action Film“ und der Entität „Tom Cruise“ ausgeliefert werden. In dem Patent wird Bezug auf unterschiedlichste Formen von Suchen genommen wie z.B. Suchanfragen in einer Bilder-Suche oder via Voice Search über einen digitalen Assistenten.
Query generation using structural similarity between documents
Dieses Patent wurde im September 2016 gezeichnet. Das spannende an diesem Patent ist, dass unter den Erfindern mit Paul Haahr und Yonhui Wu zwei bedeutende Deep-Learning-Engineers beteiligt waren. Zudem war Yonhui Wu einer führenden Köpfe bei der Rankbrain-Entwicklung.
In dem Patent wird eine Methode beschrieben wie eine Suchmaschine ergänzende Suchanfragen zu einer Entität generieren kann, um sie in einem Query Store zu speichern. Mit diesen Suchanfragen könnten dann z.B. Suchanfragen Verfeinerungen bzw. -Umschreibungen eines ursprünglichen Suchterms vorgenommen werden.
Anhand der inhaltlichen Struktur ähnlicher Dokumente können Suchanfragen-Verfeinerungen abstrahiert werden. So kann aus einem Dokument zum Autor Joseph Heller vorkommenden Satz „Joseph Heller wrote the influential novel catch 22 about americain serviceman in WW2.“ die Suchanfrage „joseph heller catch“ extrahiert werden.
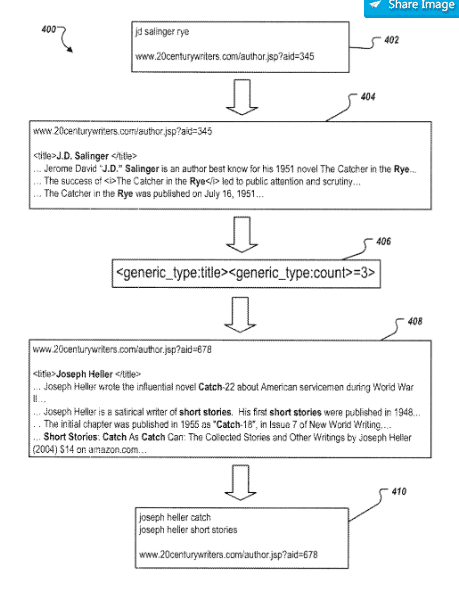
Identifikation von Entitäten in Suchanfragen (Named Entity Recognition)
Google will herauszufinden, um welche Entität es sich bei einer Frage handelt. Dieser Prozess wird auch als „Named entity recognition“ bezeichnet. Das ist gar nicht so einfach, wenn die Entität selbst im Suchterm gar nicht vorkommt. Durch im Suchterm vorkommende Entitäten und den Relationskontext zwischen Entitäten kann Google die gesuchte Entität identifizieren.
Ein Beispiel:
Die Frage „wer ist ceo bei vw“ oder die implizite Fragestellung „ceo vw“ führt zur Auslieferung der folgenden Suchergebnisse:
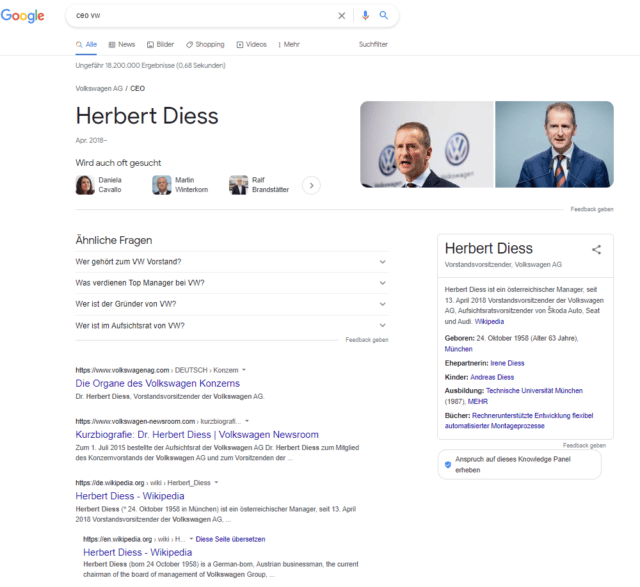
Das Knowledge Panel, die One Box, als auch die normalen Suchergebnisse sind auf die Entität Herbert Diess ausgerichtet, obwohl diese in der Suchanfrage nicht als Keyword vorkommt. Die ähnlichen Fragen haben keinen direkten Bezug zur gesuchten Entität.
In diesem Beispiel spielen zwei Entitäten und eine Verbindungsart bzw. Prädikatsphrase eine wichtige Rolle zur Beantwortung der Frage.
- VW (Entität)
- Chef (Verbindungsart)
- Herbert Diess (Entität)
Nur über die Kombination der Entität „VW“ mit der Verbindungsart „Chef“ kann Google die Frage nach der Entität „Herbert Diess“ beantworten.
Deswegen ist Google die Identifikation von Entitäten im ersten Schritt so wichtig. Als zentrale Sammelstelle für alle als Entitäten identifizierten Begriffe nutzt Google den Knowledge Graph.
Für Google ist es wichtig Entitäten in Suchtermen zu identifizieren und Verbindungen zu anderen Entitäten festzustellen. Mindestens genauso wichtig sind die Beziehungen zwischen den Entitäten. Denn nur so kann Google auch implizite Fragen nach Entitäten und somit auch konkrete Fragen nach Entitäten direkt in den SERPs beantworten. Hier noch ein Beispiel:
Die Suchanfrage „Wer ist der Gründer von Adidas?“(explizite Fragestellung) und „Gründer Adidas“ (implizite Fragestellung) führt zu den gleichen Suchergebnissen:
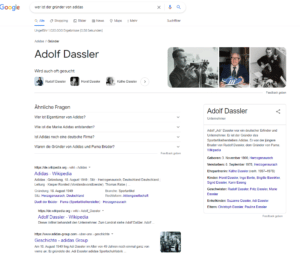
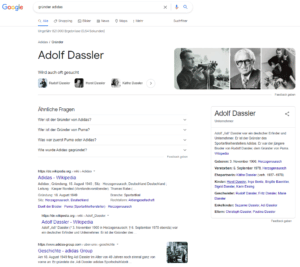
Google erkennt, dass hier nach der Entität Adolf Dassler gesucht wird, obwohl der Name in der Suchanfrage nicht vorkommt. Dabei ist es egal, ob ich eine implizite Frage in Form des Suchterms „Gründer Adidas“ stelle oder eine explizite Frage. Die Entität „Adidas“ und der Relationskontext „Gründer“ reichen dafür aus.
Nachfolgend einige Google Patente, die in Verbindung mit Named Entity Recognition stehen.
Selecting content using entity properties
Dieses Patent wurde erstmals im April 2014 und im Oktober 2017 unter einem neuen Namen von Google neu gezeichnet. Es beschreibt wie Google mit Hilfe eines Confidence Scores die Entitäten-Hierarchie in einer Suchanfrage bestimmen kann.
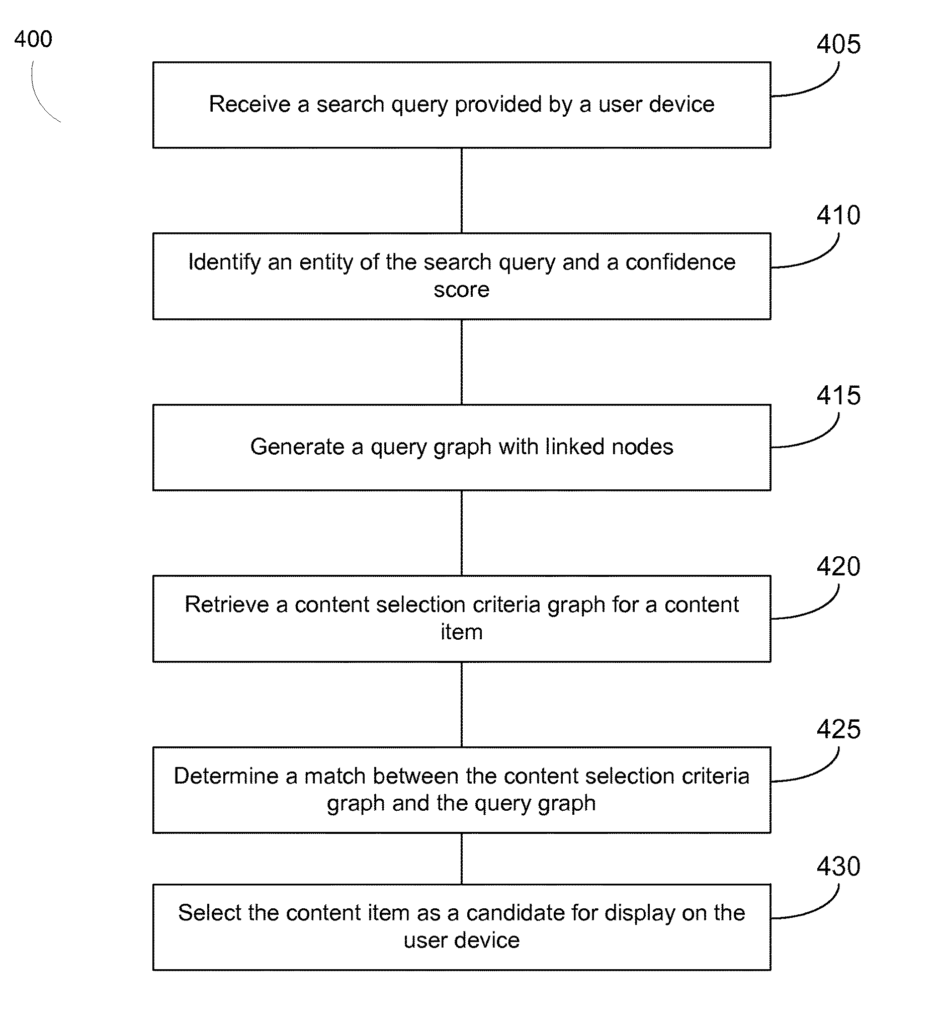
Um die Relevanz einer Entität in einer Suchanfrage zu erkennen kann Google einen Confidence Score einsetzen
The method can include identifying a property of the entity of the search query. The method can include the data processing system determining a match between a property of an entity of content selection criteria and the property of the entity of the search query. The method can include the data processing system selecting the content item as a candidate for display on the user device based on the match and the confidence score. Quelle: https://patents.google.com/patent/US9542450B1/en
Nach diesem Confidence Score wird dann entschieden welches die Hauptentität in der Suchanfrage ist und demnach werden die passenden Dokumente für die SERPs bestimmt. Dabei können sowohl über einen Query Graph als auch einen Content Selection Criteria Graph auch Entitäts-Attribute in der Auswahlprozess einbezogen werden.
Associating an entity with a search query
In diesem Patent, das 2016 Google zugesprochen wurde. geht es darum wie eine Entität in einer Suchanfrage erkannt werden kann bzw. wie Google erkennen kann, dass es sich überhaupt um eine Suchanfrage mit einer Entitäten-Referenz handelt. Zu diesem Patent gibt es auch noch eine weitere Version aus dem Jahr 2013.
Folgende Prozesschritte werden durch das Patent beschrieben:
-
- Empfangen einer Suchanfrage
- Identifizieren einer mit dem Suchterm verbundenen Entität
- Bereitstellen einer Entitätszusammenfassung, damit als Antwort auf die Suchanfrage passende Ergebnisse anzeigt werden können. Die Zusammenfassung enthält sowohl relevante Informationen zur Entität als auch optionale zusätzliche Suchanfragen.
- Identifizieren der optionalen Entitätssuchanfrage und Verknüpfung mit der ausgewählten Option. (Mehr dazu im Patent ….)
- Identifizieren von zu den Entitäten oder der Entität passenden Dokumenten
- Identifizieren von weiteren Entitäten aus den ausgewählten Dokumenten
- Verbinden der Entität(en) mit der Suchanfrage
- Ermitteln eines Rankings für die Entitäten

Providing search results based on a compositional query
 Dieses Patent wurde 2012 von Google gezeichnet und im Mai 2021 in aktualisierter Form neu publiziert. Es hat eine Laufzeit bis 2035. In dem Patent wird der Prozess für die Ausgabe von Suchergebnissen auf eine Suchanfrage mit mindestens zwei Entitäten, die in Beziehung zueinander stehen beschrieben. Eine solche Suchanfrage könnte z.B. sein „japanisches Restaurant in der Nähe einer Bank“.Die Suchintention hinter dieser Suchanfrage könnte sein, dass der Nutzer ein japanisches Restaurant besuchen und davor oder danach in einer Bank vorbeigehen möchte.
Dieses Patent wurde 2012 von Google gezeichnet und im Mai 2021 in aktualisierter Form neu publiziert. Es hat eine Laufzeit bis 2035. In dem Patent wird der Prozess für die Ausgabe von Suchergebnissen auf eine Suchanfrage mit mindestens zwei Entitäten, die in Beziehung zueinander stehen beschrieben. Eine solche Suchanfrage könnte z.B. sein „japanisches Restaurant in der Nähe einer Bank“.Die Suchintention hinter dieser Suchanfrage könnte sein, dass der Nutzer ein japanisches Restaurant besuchen und davor oder danach in einer Bank vorbeigehen möchte.
Eine weitere Suchanfrage könnte sein „Banken, die in der Wirtschaftskrise bankrott gegangen sind“. Im Gegensatz zur vorherigen Suchanfrage geht es hier um keine örtliche sondern um eine zeitliche Beziehung der Entitäten zueinander.
Die Suchanfragen können auch komplexer sein und mehr zwei Entitäten enthalten.
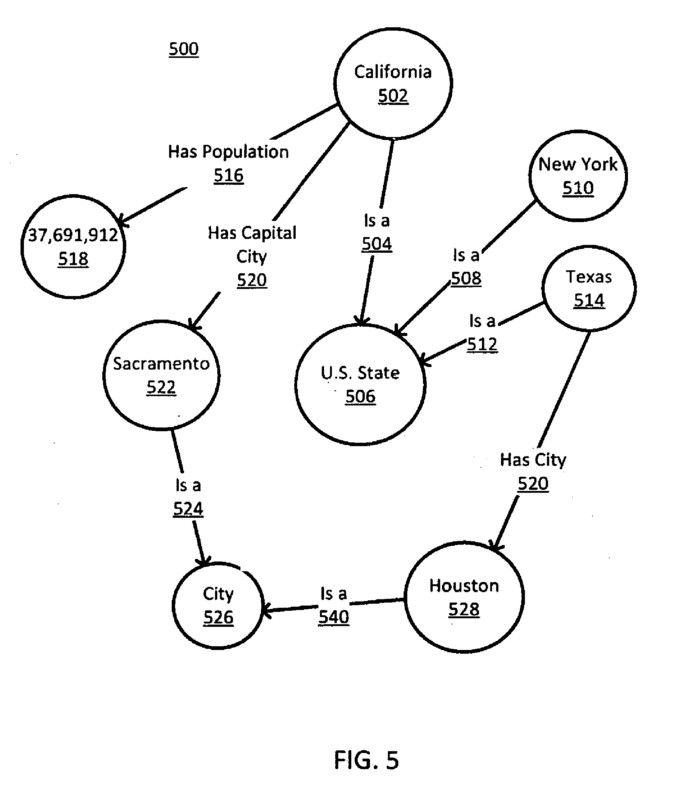
Solche komplexen Suchanfragen können nur durch Daten, die in einem Knowledge Graph erfasst sind, beantwortet werden. Über die durch die Kanten beschriebenen Beziehungsinformationen lassen sich unendlich viele Bezüge zwischen verschiedensten Entitäten herstellen. Eine klassische tabellarische Datenbank wie z.B. SQL kann solche Suchanfragen nicht sinnvoll beantworten.
Semantische Anreicherung von Suchanfragen
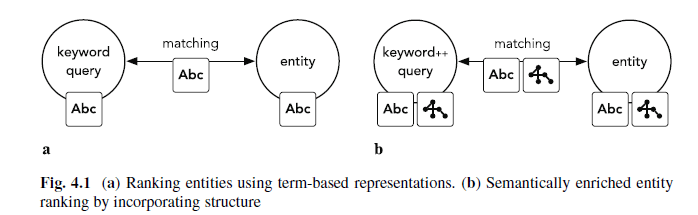
Quelle: Entity oriented Search, Krisztian Balog
Es ist für Google nicht immer einfach die relevanten Entitäten aus den Suchanfragen heraus zu interpretieren. Hier können Suchanfragen im Hintergrund automatisch mit semantischen Zusatzinformationen bzw. Annotationen angereichert werden oder per Autosuggest dem Nutzer vorgeschlagen werden. Dabei findet das Matching von der Suchanfrage und der Entität nicht mehr nur aufgrund des eingegebenen Texts statt, sondern auch unter Einbeziehung semantischer Beziehungen von Entitäten und Attributen.
Im folgenden Beispiel wird die Entität „Ann Dunham“ gesucht. Eine rein termbasierte Suchmaschine hätte Probleme die Suchanfrage nach dem „eltern von obama“ zu beantworten. Durch das Zusammenspiel aus termbasierter und entitätenbasierter Suche kann die Antwort „Ann Dunham“ als Mutter von der Suchmaschine ausgegeben werden.
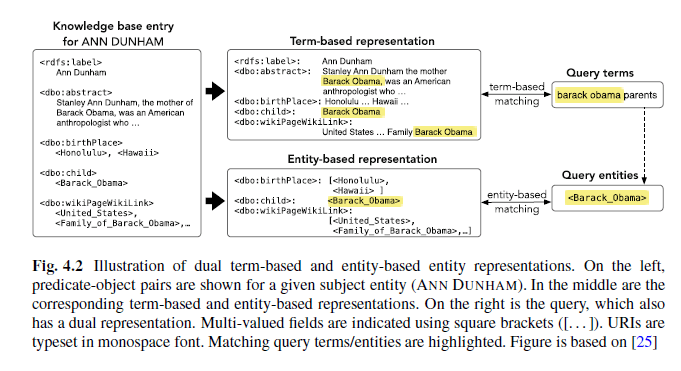
Quelle: Entity oriented Search, Krisztian Balog
In der Praxis sieht das Ergebnis dann so aus. Neben der Mutter Ann Dunham wird auch die zweite gesuchte Entität des Vaters Barack Hussein Obama Senior als auch das Knowledge Panel von Barrack Obama ausgegeben. Das Knowledge Panel von Barrack Obama wird ausgespielt, da das System auf den Term Barack Obama in der Suchanfrage reagiert. Die beiden anderen Entitäten-Boxen werden aufgrund der semantischen Zusatzinformationen aus dem Knowledge Graph ausgegeben.
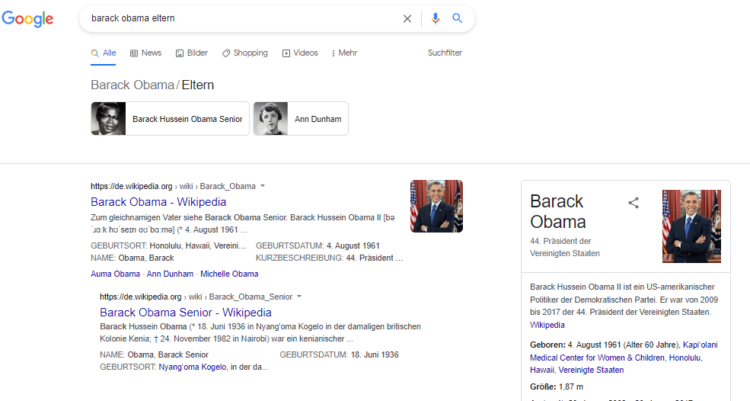
Das praktische an diesem dualen System bei der Interpretation von Suchanfragen ist, dass auch Ergebnisse ausgegeben werden können, wenn in einem Suchterm nach keiner Entität gesucht wird.
Neben der entitätenbasierten Interpretation von Suchanfragen kann die termbasierte Methode auch durch Entitäts-Typenbasierte Methoden unterstützt werden. Das ist relevant bei Suchanfragen bei denen nach mehreren Entitäten aus einer Typen-Klasse gesucht wird wie z.B. „sehenswürdigkeiten hannover“. Hier wird eine Box ausgegeben, die mehrere Entitäten auflistet.
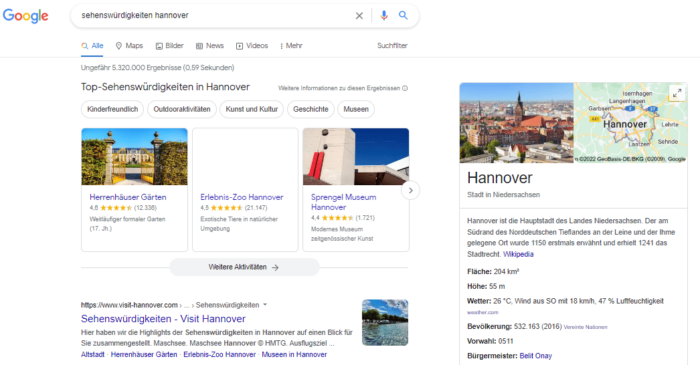
Häufig werden bei Suchanfragen bezogen auf einen Entitäts-Typ entweder die aktuell relevanteste Entität, Karussels oder die obige Art von Knowledge-Graph-Boxen ausgegeben. In solchen Boxen werden je nach Gewichtung bezogen auf die Suchanfrage die relevantesten Entitäten angezeigt. Die Nähe bzw. Relevanz der Entitäten zur Suchanfrage kann Google ähnlich wie bei Dokumenten über Vektorraumanalysen wie z.B. Word2Vec feststellen. Je kleiner der Winkel zwischen dem Suchanfragen-Vektor und dem Entitäten-Vektor desto relevanter bzw. näher sind sich Term und Entität.
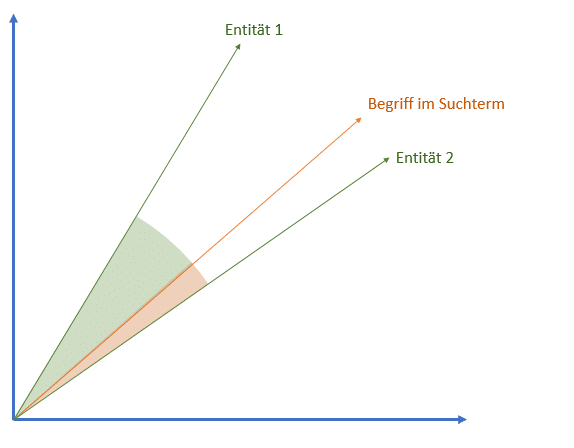
Beispiel Vektorraumanalyse Entitäten zur Suchanfrage
Verfeinerung von Suchanfragen
Über die Verfeinerung von Suchanfragen oder auch Query Refinement genannt können Suchmaschinen Suchterme umschreiben, um der Suchanfrage eine genauere Bedeutung zuzuschreiben und dementsprechende Suchergebnisse auszuliefern. Das kann im Hintergrund stattfinden, ohne dass der Nutzer davon etwas mitbekommt oder aktiv durch den Nutzer ausgelöst werden. Gerade bei Suchanfragen, die sehr generisch auf eine Entität abzielen ist oft unklar welche Informationen der Nutzer finden möchte. Bisher werden die wichtigsten Daten zu einer Entität standardisiert ausgerichtet auf jeweiligen Entitätstyp im Knowledge Panel ausgegeben. (Mehr dazu siehe meinen Beitrag Wie erstellt Google Knowledge Panel & Knowledge Cards?). Zukünftig kann der Nutzer aber auch über Buttons aktiv genauer spezifizieren welche Medienformate und Informationen er zu der Entität sehen möchte, wie Screenshots aus den amerikanischen SERPs zeigen. Dabei werden die Suchanfragen durch Klick auf den Button offensichtlich umgeschrieben.
Nachfolgend einige Google Patente, die mit dem Query Refinement, also das Verfeinern bzw. Umschreiben von Suchanfragen in Verbindung stehen.
Refining search queries
Das Erscheinungsdatum dieses Patents zeigt, dass Google sich schon sehr lange mit diesem komplexen Thema beschäftigt. Es ist eines der ersten Patente von Google zur semantischen Interpretation von Suchtermen und stammt von Ori Allon aus dem Jahr 2009.
Das Patent beschäftigt sich in erster Linie mit der Interpretation von Suchanfragen sowie deren Verfeinerung. Laut dem Patent bezieht sich die Verfeinerung der Suchanfrage auf bestimmte Entitäten, die in den zur Original-Suchanfrage oder Synonymen rankenden Dokumenten häufig zusammen vorkommen. Dadurch lassen sich Entitäten gegenseitig referenzieren und auch bisher unbekannte Entitäten lassen sich somit schnell identifizieren.
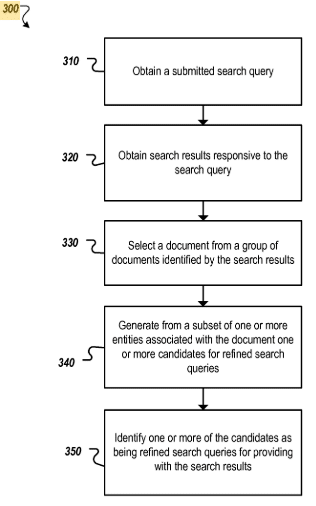
Query rewriting with entity detection
Dieses Patent wurde erstmal im September 2004 von Google gezeichnet und im Oktober 2017 noch mal unter einem neuen Namen neu gezeichnet. Es ist besonders spannend weil die Wurzeln weit vor Rankbrain, Hummingbird und Knowledge Graph zu finden sind und anscheinend heute noch relevant ist, was die Vermutung nahelegt, dass die Methodik ein fester Bestandteil der heutigen Google-Suche ist.
Die Methodik beschreibt den Prozess wie Suchanfragen mit Entitäten-Bezug bei Bedarf umgeschrieben werden oder zumindest Suggest-Vorschläge auszuspielen um relevantere Suchergebnisse zu erhalten.
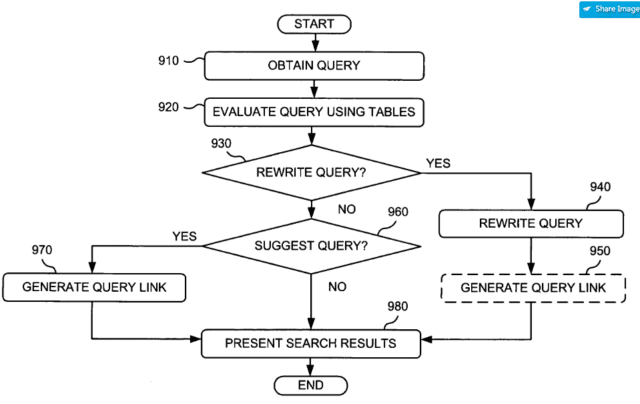
Das Patent wirkt auf den ersten Blick doch recht einfach und rudimentär, da sich die Umschreibungen der Suchanfrage in den aufgeführten Beispielen nur aus einer Ergänzung der Suchanfragen mit Suchoperatoren beziehen. So wird in einem der Beispiele die Suchanfrage „mutual funds business week“ ungeschrieben zu „mutual funds source:business week“. Spannend finde ich in dem Patent, dass in den Beispielen Entitäten-IDs über Domains vergeben werden. Das würde der Vermutung Futter geben, dass Domains eindeutige digitale Abbilder von Entitäten sind.
Zudem wird beschrieben, dass ein Umschreiben der Suchanfrage auch bei verschiedenen gleichbedeutenden Begriffen wie z.B. Synonymen oder Fehlschreibweisen durchgeführt werden kann und als Suchergebnisse Inhalte sowohl passend zur ursprünglichen als auch umgeschriebenen Suchanfrage ausgeliefert werden.
Clustering query refinements by inferred user intent
Dieses Patent hat Google im März 2016 erstmals gezeichnet und im Oktober 2017 unter einem aktualisierten Namen neu gezeichnet. Es beschreibt eine Methode wie Google Verfeinerungen von Suchanfragen erstellt um noch besser herauszufinden was der Nutzer wirklich sucht. Diese Verfeinerungen sind die verwandten Suchanfragen, die unterhalb der Suchergebnisse erscheinen.
Diese Verfeinerungen sind insbesondere bei einer unklaren Nutzer-Absicht wichtig, um relevantere Ergebnisse und verwandte Suchanfragen auszuspielen. Dafür werden alle möglichen Suchanfragen Verfeinerungen in Cluster organisiert, die die unterschiedlichen Aspekte in Bezug auf die ursprüngliche Suchanfrage abbilden. Diese Aspekte bedürfen unterschiedlichen Suchergebnissen.
Das Clustering von Suchanfragen wird über ein Graphen-Konstrukt gelöst. Dabei werden sowohl sessionabhängige Beziehungen von Suchtermen zueinander, als auch die Abfrage von bestimmten Dokumenten berücksichtigt. Der Graph berücksichtigt effektiv sowohl die inhaltsbasierte Ähnlichkeit als auch die Ähnlichkeit des gemeinsamen Auftretens von Sitzungen, die aus den Anfrageprotokollen ermittelt wurden. Sprich es werden sowohl Kookkurrenzen von aufeinanderfolgenden Suchanfragen als auch das Klickverhalten analysiert.
In dem Graph werden die ursprüngliche Suchanfrage als auch die Verfeinerungen und die dazu passenden Dokumente als Knoten dargestellt. Zusätzliche Knoten stellen die als Kookkurrenzen sessionintern vorkommenden verwandten Suchanfragen dar. Alle dieser Knoten sind über Kanten verbunden.
Cluster von Suchanfragen-Verfeinerungen und Dokumenten können über Besuchs-Wahrscheinlichkeits-Vektor gebildet werden.
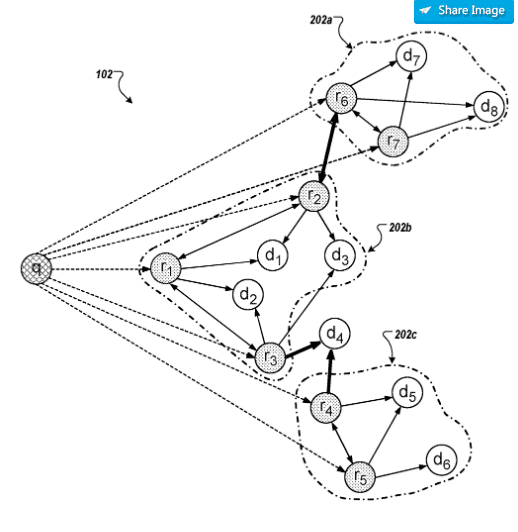
In Bezug auf die verwandten Suchanfragen findet man in dem Patent eine interessante Passage, die beschreibt wie die verwandten Suchanfragen generiert werden:
Related queries are typically mined from the query logs by finding other queries that co-occur in sessions with the original query. Specifically, query refinements, a particular kind of related queries, are obtained by finding queries that are most likely to follow the original query is a user session. For many popular queries, there may be hundreds of related queries mined from the logs using this method. However, given the limited available space on a search results page, search engines typically only choose to display a few of the related queries.
Weitere spannende Google Patente rund um das Search Query Processing
Nachfolgend weitere spannende Google-Patente, die ich im Zusammenhang mit modernen Search Query Processing entdeckt habe, aber nicht klar einem der obigen Teilschritte zugeordnet werden können.
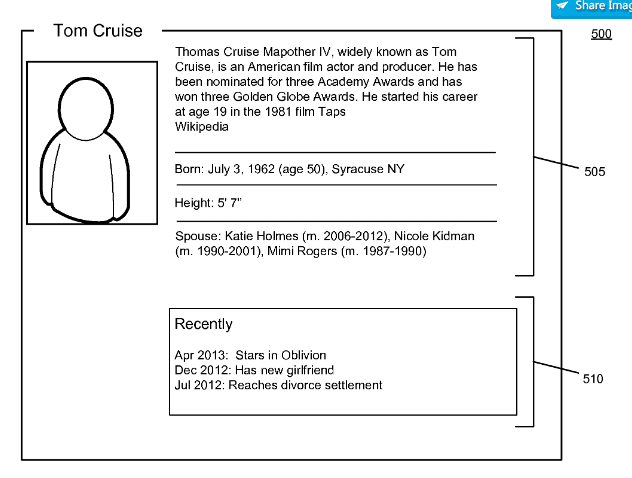
Discovering entity actions for an entity graph
Dieses Patent hat Google im Januar 2014 erstmals gezeichnet und im Oktober 2017 unter einem aktualisierten Namen neu gezeichnet. Es beschreibt wie Google basierend auf situativ bedingten kurzfristigen Schwankungen im Suchvolumen Entitäten-bezogene Aktivitäten identifiziert. Diese können dann z.B. in einem Knowledge Panel kurzfristig ergänzt werden oder es können Inhalte, die diese aktuellen Aktivitäten berücksichtigen vorübergehend in den Rankings nach oben geschoben werden. So kann Google auf situative Ereignisse rund um eine Entität reagieren und dementsprechend die SERPs anpassen.
Identifying and ranking attributes of entities
Dieses im Jahr 2015 veröffentlichte Google Patent ist wohl eins der spannendsten Patente zu diesem Thema. Es beschreibt wie Google für jeden Suchterm Suchanfrage-Daten, Entitäten-beschreibende Teile und Anhänge bestimmt. Diese Anhänge können z.B. Attribute sein. Auf diesen Weg lassen sich Suchanfragen analysieren, um festzustellen, welche Arten von Informationen Benutzer normalerweise erhalten möchten.
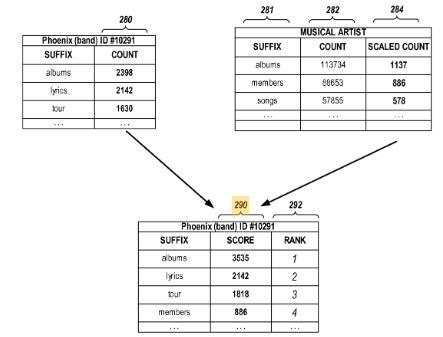
In vielen Fällen unterscheiden sich die Informationstypen, an denen ein Benutzer für eine Entität (z. B. eine Person oder ein Thema) interessiert ist. Durch die Analyse von Suchanfragen können die am häufigsten angeforderten Informationen für eine bestimmte Entität identifiziert werden. Wenn dann ein Benutzer eine Suchanfrage sendet, die sich auf die bestimmte Entität bezieht, können die am häufigsten angeforderten Informationen als Antwort auf die Abfrage bereitgestellt werden. Beispielsweise kann eine kurze Zusammenfassung der am häufigsten angeforderten Fakten für die bestimmte Entität und andere ähnliche Entitäten bereitgestellt werden wie z.B. in einem Knowledge Panel oder einer One Box.
Dabei wird berücksichtigt wie häufig bestimmte Informationen zu der Entität selbst als auch generell für den Entitätstyp gesucht werden. Wird z.B. bezogen auf die Band Phoenix häufig nach den Alben, Lyrics und Tourdaten und generell für Musiker nach Bandmitglieder und Songs ergeben sich daraus die im Knowledge Panel ausgelieferten Informationen.
Learning from User Interactions in Personal Search via Attribute Parameterization
Aus dem Jahr 2017 stammt die wissenschaftliche Abandlung „Learning from User Interactions in Personal Search via Attribute Parameterization“. Hier wird beschrieben, wie Google über die Analyse des Nutzerverhaltens mit einzelnen Dokumenten semantische Attributs-Beziehungen zwischen Suchanfragen sowie den angeklickten Dokumenten herstellen und sogar einen selbstlernenden Ranking-Algorithmus unterstützen könnte:
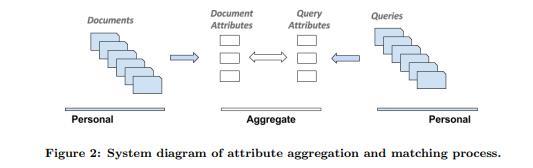
„The case in private search is different. Users usually do not share documents (e.g., emails or personal files), and therefore directly aggregating interaction history across users becomes infeasible. To address this problem, instead of directly learning from user behavior for a given [query, doc] pair like in web search, we instead choose to represent documents and queries using semantically coherent attributes that are in some way indicative of their content.
This approach is schematically described in Figure 2. Both documents and queries are projected into an aggregated attribute space, and the matching is done through that intermediate representation, rather than directly. Since we assume that the attributes are semantically meaningful, we expect that similar personal documents and queries will share many of the same aggregate attributes, making the attribute level matches a useful feature in a learning-to-rank model.“
Evaluating semantic interpretations of a search query

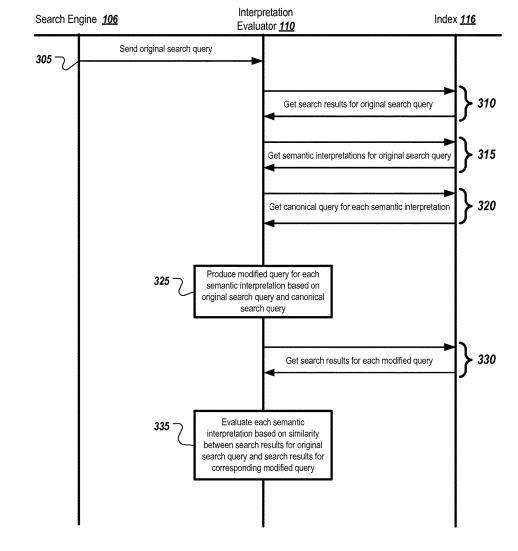
Dieses Google Patent wurde im Juli 2019 vorgestellt und kann als Weiterentwicklung oder Ergänzung von Rankbrain verstanden werden. Es beschreibt eine Methode wie unterschiedliche semantische Bedeutungen bei einer Suchanfrage ermittelt werden können. Dabei ist jede semantische Interpretation verknüpft mit einer anderen kanonischen Suchanfrage. Die aktuelle Suchanfrage wird basierend auf dieser und dem kanonischen Suchterm modifiziert.
Ähnlich dem bereits erwähnten Patent bezüglich der semantischen Annotationen sind die modifizierten Suchterme bereits mit einer semantischen Bedeutung kommentiert. Durch den Vergleich der Suchergebnisse für die ursprüngliche Suchanfrage und denen für die modifizierte können sowohl mögliche semantische Bedeutungen validiert als auch in Relation gewichtet werden. Der Grad der Ähnlichkeit der Suchergebnisse bestimmt die Nähe. Der Grad der Ähnlichkeit basiert auf der Häufigkeit des Auftretens bestimmter Keywords, die mit der bestimmten Suchanfrage in den modifizierten Suchergebnissen verknüpft sind. Eine größere Häufigkeit des Auftretens von Keywords kann beispielsweise darauf hinweisen, dass die geänderte Suchanfrage mit größerer Wahrscheinlichkeit der semantischen Bedeutung entspricht.
In einigen Fällen können andere Daten, wie z. B. die Klickrate des Benutzers, Website-Traffic-Daten oder andere Daten, verwendet werden, um eine wahrscheinliche semantische Interpretation zu interpretieren.
Query Suggestions based on entity collections of one or more past queries

Ein weiteres Google Patent aus dem Juli 2019 beschreibt eine Methode, wie Google Suggest Vorschläge aus vergangenen Suchanfragen generieren kann. Auch hier spielen Entitäten eine Rolle. Entitäten, die in Beziehung zu den in den bisherigen Suggest-Vorschlägen vorkommenden Entitäten oder in der Vergangenheit gesuchten Entitäten in Beziehung stehen sind die Basis für die Bestimmung einer Ähnlichkeits-Messzahl für die Bestimmung neuer Suggest-Vorschläge.
Weitere Google-Patente für die Entitäten-basierte Interpretation von Suchanfragen
Das Zusammenspiel aus Rankbrain, BERT, MUM und Knowledge Graph
Ich denke, es wird klar, dass Google sich immer mehr zur Ad-hoc-Antwort-Maschine entwickelt und deswegen die Bedeutung einer Suchanfrage immer wichtiger wird als die rein Keyword-basierte Interpretation von Suchanfragen.
Bisherige Information Retrieval Methoden beschränken sich auf die in der Suchanfrage vorkommenden Begriffe und gleichen diese mit Inhalten ab in denen die einzelnen Begriffe vorkommen, ohne über eine Kontextuelle Verbindung der Begriffe zueinander zu berücksichtigen und darüber die eigentliche Bedeutung festzustellen.
Durch Innovationen wie Rankbrain, BERT und MUM geht es im Kern darum gesuchte Entitäten über einen Abgleich mit einer Entitäten-Datenbank (Knowledge Graph) zu identifizieren, über die Beziehung der relevanten Entitäten zueinander einen Kontext und darüber die Bedeutung von Suchanfragen und Dokumenten zu erkennen. Zur Normalisierung und Vereinfachung werden Suchanfragen verfeinert und umgeschrieben und mit semantischen Kommentaren versehen.

Dieses Umdenken im Information Retrieval bei Google war der Grund für die Einführung des Knowledge Graph, das Hummingbird Update im Jahr 2013 und Rankbrain im Jahr 2015. Diese Reihe von Innovationen stehen im direkten Zusammenhang miteinander bzw. greifen prozessual ineinander.
- Rankbrain ist für die Interpretation von Suchanfragen hinsichtlich Synonymität, Ambiguität, Sinn (Intention) und Bedeutung (Extension) zuständig. Gerade mit Blick auf neue Suchanfragen, Long Tail Keywords, mehrdeutige Begriffe sowie Abwicklung von Prozessen im Rahmen von Voice Search und digitalen Assistenten ist Rankbrain das zentrale Element im Query Processing.
- Die im Knowledge Graph erfassten Entitäten und Fakten wie Attribute und Beziehungen der Entitäten untereinander können sowohl bei der Relevanzbestimmung von Ergebnissen als auch bei der Verarbeitung von Suchanfragen (Query Processing) genutzt werden, um z.B. Dokumente und Suchanfragen über Kommentare (Annotations) mit Fakten aus dem Knowledge Graph anzureichern. Dadurch kann die Bedeutung von Suchanfragen als auch Dokumenten bzw. von einzelnen Absätzen und Sätzen in Inhalten besser interpretiert werden.
- Der Hummingbird-Algorithmus ist für das Clustering von Inhalten je nach Bedeutung sowie Zweck in unterschiedliche Korpusse und für die Bewertung bzw. das Scoring der Ergebnisse hinsichtlich Relevanz also das Ranking zuständig.
Das verbindende Element bei allen drei Modulen sind Entitäten. Sie sind kleinste gemeinsame Nenner. Sowohl bei Rankbrain, BERT, MUM spielen Vektorraumanalysen bzw. Word Embeddings als auch Natural Language Processing eine zentrale Rolle. Durch die Fortschritte in Sachen Machine Learning kann Google diese Methoden immer performanter nutzen, um sich von einer rein textbasierten Suchmaschine zu einer semantischen Suchmaschine zu entwickeln.
Things not strings!
- Die Google Suche: So funktioniert das Ranking der Suchmaschine heute - 13. Februar 2024
- Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO - 30. November 2023
- Sind LLMO, GAIO oder GEO die Zukunft von SEO? - 4. Oktober 2023
- Googles Weg zur semantischen Suchmaschine - 29. Juni 2023
- Digital Authority Management: Eine neue Disziplin in Zeiten von SGE & E-E-A-T - 29. Juni 2023

























6 Kommentare
Hey Olaf,
meine Statistik Fächer sind mittlerweile leider schon ein wenig länger her, aber wenn ich alles richtig verstanden habe, sollte folgender Absatz
– „Wenn der Lift-Score z.B. 5 ist, ist die Wahrscheinlichkeit, dass „Wi“ gesucht wird, 5 mal so hoch als dass „Wi“ generell gesucht wird.“ –
eigentlich:
– „Wenn der Lift-Score z.B. 5 ist, ist die Wahrscheinlichkeit, dass „Wi“ geklickt wird, 5 mal so hoch als dass „Wi“ generell gesucht wird.“ –
lauten.
Danke übrigens für den starken Beitrag 🙂
Bzw. das eine Nutzerinteraktion stattfindet*
bzw: Die Wahrscheinlichkeit, dass wi gesucht wird unter der Bedingung das eine User Interaktion (z.B. ein Klick stattfindet), ist 5 mal höher als eine Suche nach wi an sich.
Whoa! Es war wirklich einfallsreich. Rankbrain könnte das Ranking ziemlich stark beeinflussen und das gesamte Level von SEO verändern. In der Tat eine großartige Informationsquelle. Danke für das Teilen.